
 Technologie-Peripheriegeräte
KI
Eine Frage unterscheidet Mensch und KI! „Bettlerversion' Turing-Test, schwierig für alle großen Modelle
Technologie-Peripheriegeräte
KI
Eine Frage unterscheidet Mensch und KI! „Bettlerversion' Turing-Test, schwierig für alle großen Modelle
Eine Frage unterscheidet Mensch und KI! „Bettlerversion' Turing-Test, schwierig für alle großen Modelle

Eine „ultimative Bettlerversion“ des „Turing-Tests“, die alle wichtigen Sprachmodelle übertrifft.
Menschen können den Test mühelos bestehen.
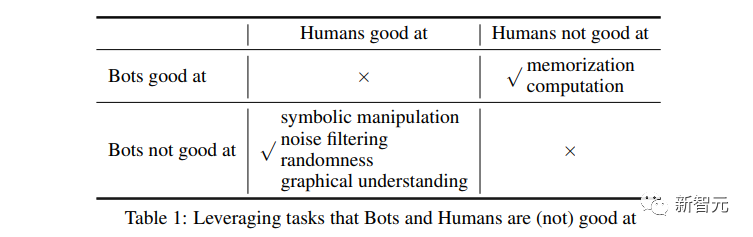
Großbuchstabentest
Die Forscher verwendeten eine sehr einfache Methode.
Mischen Sie das eigentliche Problem in einige chaotische Wörter in Großbuchstaben und übermitteln Sie es dem großen Sprachmodell.
Für große Sprachmodelle gibt es keine Möglichkeit, die tatsächlich gestellten Fragen effektiv zu identifizieren.
Menschen können die „Großbuchstaben“-Wörter leicht aus den Fragen entfernen, die echten Fragen identifizieren, die in den chaotischen Großbuchstaben verborgen sind, Antworten geben und den Test bestehen.
Die Frage im Bild selbst ist ganz einfach: Ist Wasser nass oder trocken?

Menschen antworten einfach nass und das war’s.
Aber ChatGPT hat keine Möglichkeit, die Beeinträchtigung dieser Großbuchstaben bei der Beantwortung der Frage zu beseitigen.
So wurden den Fragen viele bedeutungslose Wörter beigemischt, wodurch die Antworten sehr lang und bedeutungslos wurden.
Zusätzlich zu ChatGPT führten die Forscher auch ähnliche Tests mit GPT-3 und Metas LLaMA sowie mehreren Open-Source-Feinabstimmungsmodellen durch, und alle haben den „Großbuchstabentest“ nicht bestanden.

Das Prinzip des Tests ist eigentlich einfach: KI-Algorithmen verarbeiten Textdaten typischerweise ohne Berücksichtigung der Groß- und Kleinschreibung.
Wenn also versehentlich ein Großbuchstabe in einen Satz eingefügt wird, kann das zu Verwirrung führen.
KI weiß nicht, ob sie es als Eigennamen oder Fehler behandeln oder einfach ignorieren soll.

Damit können wir unter den Menschen, mit denen wir sprechen, leicht zwischen echten Menschen und Chatbots unterscheiden.
Wie kann man KI wissenschaftlicher aufdecken?
Um schwerwiegende illegale Aktivitäten wie Betrug mithilfe von Chatbots zu bekämpfen, die in Zukunft möglicherweise in großer Zahl auftauchen.
Zusätzlich zum oben erwähnten Großbuchstabentest versuchen Forscher, einen Weg zu finden, um in einer Online-Umgebung effizienter zwischen Menschen und Chatbots zu unterscheiden.

Papier: https://www.php.cn/link/f30a31bcad7560324b3249ba66ccf7aa
Forscher konzentrieren sich auf die Gestaltung der Schwächen großer Sprachmodelle.
Um zu verhindern, dass das große Sprachmodell den Test besteht, ergreifen Sie die „sieben Zoll“ der KI und sprengen Sie sie.
Wir haben die folgenden Testmethoden entwickelt.
Solange das große Model nicht gut darin ist, Fragen zu beantworten, werden wir sie wie verrückt ins Visier nehmen.
Zählen
Das Erste ist das Zählen, zu wissen, dass das Zählen mit großen Modellen nicht ausreicht.

Tatsächlich kann ich alle drei Buchstaben falsch zählen.
Textersetzung
Dann gibt es noch einige Textersetzungen Buchstaben ersetzen einander und lassen das große Modell ein neues Wort buchstabieren.
KI hatte lange Zeit Probleme, aber das Ausgabeergebnis war immer noch falsch.

Positionsersatz
Das ist auch nicht die Stärke von ChatGPT.
Sogar der Brieffilter-Chatbot, der von Grundschülern genau ausgefüllt werden kann, kann nicht ausgefüllt werden.

Frage: Bitte nach dem zweiten „S“ ausgeben Der 4. Buchstabe von , die richtige Antwort ist „c“ Es erfordert für Menschen fast keine Anstrengung, es zu vervollständigen, aber die KI kann immer noch nicht bestehen.
Geräuschimplantation
#🎜 🎜 # Dies ist der „Großbuchstabentest“, den wir eingangs erwähnt haben.
Dies ist der „Großbuchstabentest“, den wir eingangs erwähnt haben.
Durch das Hinzufügen verschiedener Geräusche (z. B. irrelevanter Wörter in Großbuchstaben) zur Frage kann der Chatbot die Frage nicht genau identifizieren und besteht daher den Test nicht.
# 🎜 🎜#
Und für Menschen ist es wirklich schwierig, in diesen chaotischen Großbuchstaben das eigentliche Problem zu erkennen.

Symboltext

Ein weiteres Projekt für Menschen Es gibt fast keine herausfordernden Missionen.
Aber für Chatbots wollen sie diese Symboltexte verstehen können Ohne viel Fachtraining dürfte es schwierig sein.
Nach einer Reihe „unmöglicher Aufgaben“, die von Forschern speziell für große Sprachmodelle entwickelt wurden.
Speicher und Berechnung
Durch frühes Training, große Sprache Das Modell schneidet in beiden Aspekten relativ gut ab.
Menschen sind grundsätzlich nicht in der Lage, effektiv auf große Speichermengen und 4-stellige Berechnungen zu reagieren, da sie nicht in der Lage sind, verschiedene Hilfsgeräte zu verwenden.
Menschliches vs. großes Sprachmodell
Die Forscher führten diesen „menschlichen Unterschiedstest“ an GPT3, ChatGPT und drei anderen großen Open-Source-Modellen durch: LLaMA, Alpaca und Vicuna
Dies ist aus den Ergebnissen ersichtlich Es ist deutlich zu erkennen, dass sich das große Modell nicht erfolgreich in die Menschheit integriert hat. ?
Und andere große Sprachmodelle schneiden in diesen speziell für sie entwickelten Tests sehr schlecht ab.
 Völlig unmöglich, die Prüfung zu bestehen.
Völlig unmöglich, die Prüfung zu bestehen.
Aber für Menschen ist es ganz einfach, fast zu 100 % bestanden.
Was die Probleme betrifft, in denen Menschen nicht gut sind, so sind die Menschen fast vollständig ausgelöscht und völlig besiegt.
KI ist eindeutig fähig.
Es scheint, dass die Forscher dem Testdesign tatsächlich große Aufmerksamkeit geschenkt haben.
„Lass keine KI gehen, aber tue keinem Menschen Unrecht“
Das ist eine tolle Auszeichnung!
Referenz:
https://www.php.cn/link/5e632913bf096e49880cf8b92d53c9ad
Das obige ist der detaillierte Inhalt vonEine Frage unterscheidet Mensch und KI! „Bettlerversion' Turing-Test, schwierig für alle großen Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
