
 Technologie-Peripheriegeräte
KI
Midjourneys Rivale ist da! Googles StyleDrop-Ass „Customization Master' lässt den KI-Kunstkreis explodieren
Technologie-Peripheriegeräte
KI
Midjourneys Rivale ist da! Googles StyleDrop-Ass „Customization Master' lässt den KI-Kunstkreis explodieren
Midjourneys Rivale ist da! Googles StyleDrop-Ass „Customization Master' lässt den KI-Kunstkreis explodieren

Sobald Google StyleDrop herauskam, gelangte es sofort ins Internet.
Angesichts von Van Goghs Sternennacht wird KI zum Meister Van Gogh und schafft nach einem umfassenden Verständnis dieses abstrakten Stils unzählige ähnliche Gemälde.

Ein weiterer Cartoon-Stil, die Objekte, die ich zeichnen möchte, sind viel niedlicher.

Sogar die Details können genau kontrolliert und ein Logo im Originalstil entworfen werden.

Der Charme von StyleDrop besteht darin, dass Sie nur ein Bild als Referenz benötigen. Egal wie komplex der künstlerische Stil ist, Sie können ihn dekonstruieren und neu erstellen.
Netizens haben gesagt, dass es sich um die Art von KI-Tool handelt, das Designer eliminiert.
StyleDrop Hot Research ist das neueste Produkt des Google-Forschungsteams.

Papieradresse: https://arxiv.org/pdf/2306.00983.pdf
Jetzt können Sie mit Tools wie StyleDrop nicht nur kontrollierbarer zeichnen, sondern auch das fertigstellen Vorherige Arbeit Unvorstellbar detaillierte Arbeit, wie zum Beispiel das Zeichnen eines Logos.
Sogar NVIDIA-Wissenschaftler nannten es eine „phänomenale“ Leistung.

„Customization“ Master
Der Autor des Artikels stellte vor, dass die Inspiration für StyleDrop von Eyedropper (Farbabsorptions-/Farbauswahlwerkzeug) kam.
In ähnlicher Weise hofft StyleDrop auch, dass jeder schnell und mühelos einen Stil aus einem oder mehreren Referenzbildern „auswählen“ kann, um ein Bild dieses Stils zu erstellen. Ein Faultier kann 18 Stile haben: Ein Panda kann 24 Stile haben: Ein Aquarellgemälde, gezeichnet von einem Kind , Style Drop perfekte Kontrolle , Sogar die Falten des Papiers wurden wiederhergestellt.
Ich muss sagen, es ist zu stark. 
Es gibt auch StyleDrops Design englischer Buchstaben, die auf verschiedenen Stilen basieren:

Es ist auch ein Buchstabe im Van-Gogh-Stil.


Es gibt auch Strichzeichnungen. Das Zeichnen von Strichen ist ein sehr abstraktes Bild und erfordert eine sehr hohe Rationalität bei der Bildkomposition. Frühere Methoden waren schwierig.

Die Striche des Käseschattens im Originalbild werden wiederhergestellt Objekte jedes Bildes überlegen.

Siehe Android-LOGO-Erstellung.

Darüber hinaus erweiterten die Forscher auch die Möglichkeiten von StyleDrop, nicht nur um den Stil anzupassen, sondern auch um Kombinieren Sie es mit DreamBooth-Inhalten.
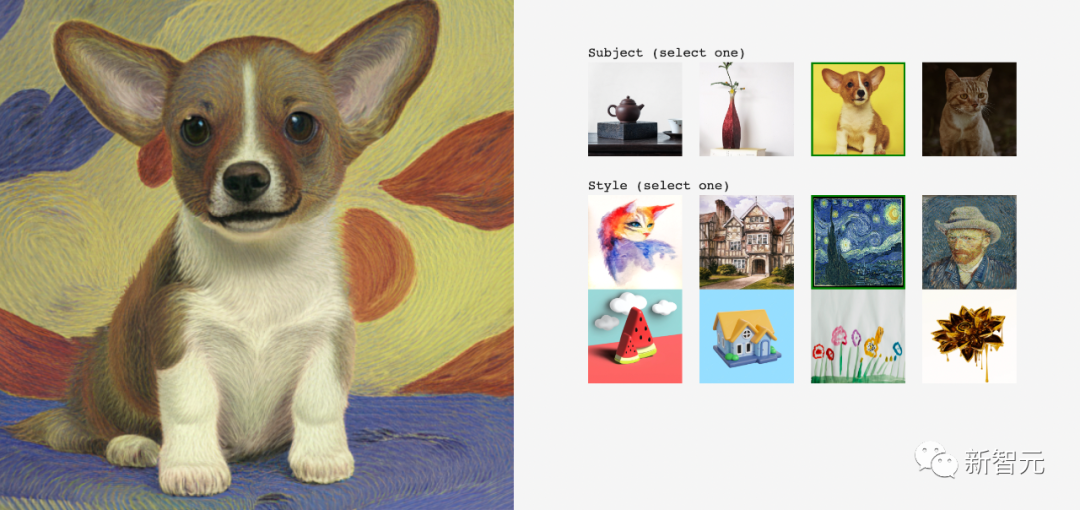
Zum Beispiel, immer noch im Van-Gogh-Stil, erstellen Sie ein ähnliches Gemälde für den kleinen Corgi:
#🎜 🎜## 🎜🎜#

Einer ist die effektive Feinabstimmung der Parameter von Der generierte visuelle Transformator. Der andere ist iteratives Training mit Feedback.
Die Forscher synthetisierten dann Bilder der beiden fein abgestimmten Modelle.
Muse ist das neueste Text-zu-Bild-Synthesemodell, das auf einem maskengenerierten Bildtransformator basiert. Es enthält zwei Synthesemodule für die Basisbilderzeugung (256 × 256) und die Superauflösung (512 × 512 oder 1024 × 1024).

T ordnet die Textaufforderung t∈T dem kontinuierlichen Einbettungsraum E zu. G verarbeitet Texteinbettungen e ∈ E, um Logarithmen visueller Tokensequenzen l ∈ L zu generieren. S extrahiert eine Folge visueller Token v ∈ V aus dem Logarithmus durch iterative Dekodierung, die mehrere Schritte der Transformatorinferenz durchführt, abhängig von der Texteinbettung e und den aus vorherigen Schritten dekodierten visuellen Token.
Schließlich ordnet D die diskrete Token-Sequenz dem Pixelraum I zu. Zusammenfassend sieht die Zusammensetzung des Bildes I bei einer gegebenen Textaufforderung t wie folgt aus:
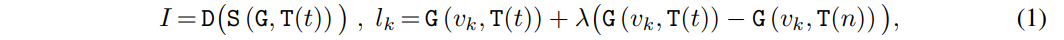
Verwenden Sie den Transformator der L-Ebene, um die in Grün angezeigte visuelle Token-Sequenz unter der Bedingung der Texteinbettung zu verarbeiten. Die erlernten Parameter θ werden verwendet, um Gewichte für die Adapterabstimmung zu konstruieren.
Um θ zu trainieren, geben Forscher in vielen Fällen möglicherweise nur Bilder als Stilreferenzen an.
Forscher müssen Textaufforderungen manuell anhängen. Sie schlugen einen einfachen, auf Vorlagen basierenden Ansatz zur Erstellung von Textaufforderungen vor, der aus einer Beschreibung des Inhalts, gefolgt von einer Phrase im Beschreibungsstil, besteht.
Zum Beispiel verwendet der Forscher „Katze“, um ein Objekt in Tabelle 1 zu beschreiben, und fügt „Aquarellmalerei“ als Stilbeschreibung hinzu.

Das Einfügen einer Beschreibung von Inhalt und Stil in eine Textaufforderung ist von entscheidender Bedeutung, da sie dabei hilft, Inhalt und Stil zu trennen, was das Hauptziel des Forschers ist.
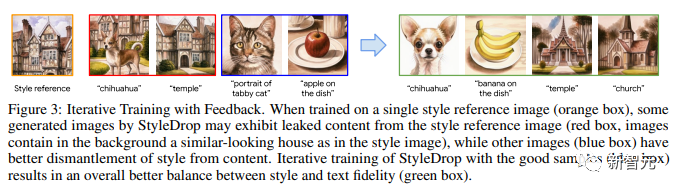
Abbildung 3 zeigt iteratives Training mit Feedback.
Beim Training mit einem einzelnen Stilreferenzbild (oranges Feld) können einige von StyleDrop generierte Bilder Inhalte aufweisen, die aus dem Stilreferenzbild (rotes Feld, der Bildhintergrund enthält ähnliche Elemente wie das Stilbild) extrahiert wurden.
Andere Bilder (blaue Kästchen) trennen den Stil besser vom Inhalt. Das iterative Training von StyleDrop an guten Beispielen (blauer Kasten) führt zu einer besseren Balance zwischen Stil und Texttreue (grüner Kasten).
Hier verwendeten die Forscher auch zwei Methoden:
-CLIP-Score
Mit dieser Methode wird die Ausrichtung von Bildern und Text gemessen. Daher kann die Qualität der generierten Bilder durch Messung des CLIP-Scores (d. h. der Kosinusähnlichkeit visueller und textueller CLIP-Einbettungen) bewertet werden.
Forscher können das CLIP-Bild mit der höchsten Punktzahl auswählen. Sie nennen diese Methode CLIP-Feedback Iterative Training (CF).
In Experimenten fanden die Forscher heraus, dass die Verwendung von CLIP-Scores zur Bewertung der Qualität synthetischer Bilder eine wirksame Möglichkeit ist, die Erinnerung (d. h. die Texttreue) ohne übermäßigen Verlust der Stiltreue zu verbessern.
Andererseits stimmen CLIP-Scores jedoch möglicherweise nicht vollständig mit der menschlichen Absicht überein und erfassen auch subtile Stilmerkmale nicht.
-HF
Human Feedback (HF) ist eine direktere Möglichkeit, die Absicht des Benutzers direkt in die Bewertung der synthetischen Bildqualität einfließen zu lassen.
Bei der LLM-Feinabstimmung für Reinforcement Learning hat HF seine Leistungsfähigkeit und Wirksamkeit unter Beweis gestellt.
HF kann verwendet werden, um die Unfähigkeit von CLIP-Scores auszugleichen, subtile Stilattribute zu erfassen.
Derzeit konzentriert sich ein großer Teil der Forschung auf das Personalisierungsproblem von Text-zu-Bild-Diffusionsmodellen, um Bilder mit mehreren persönlichen Stilen zu synthetisieren.
Forscher zeigen, wie DreamBooth und StyleDrop auf einfache Weise kombiniert werden können, um Stil und Inhalt zu personalisieren.
Dies erfolgt durch Stichprobenentnahme aus zwei modifizierten generativen Verteilungen, geleitet von θs für Stil und θc für Inhalt bzw. Adapterparametern, die unabhängig auf Stil- und Inhaltsreferenzbildern trainiert werden.
Im Gegensatz zu bestehenden Standardprodukten erfordert der Ansatz des Teams kein gemeinsames Training lernbarer Parameter für mehrere Konzepte, was zu größeren kombinatorischen Fähigkeiten führt, da die vorab trainierten Adapter individuell auf einzelne Themen und Stile trainiert werden.
Der gesamte Sampling-Prozess der Forscher folgt der iterativen Dekodierung von Gleichung (1), wobei in jedem Dekodierungsschritt eine andere Art der Logarithmen-Sampling-Methode verwendet wird.
Sei t der Text-Prompt und c der Text-Prompt ohne Stildeskriptor. Der Logarithmus wird in Schritt k wie folgt berechnet:
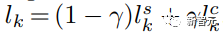
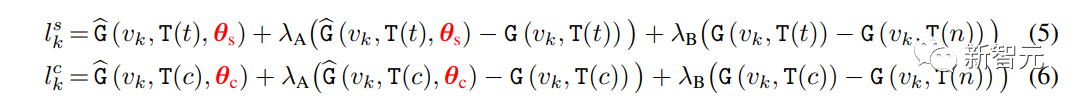
wobei: γ zum Ausgleichen von StyleDrop und DreamBooth verwendet wird – wenn γ ist 0, wir bekommen StyleDrop, wenn 1, bekommen wir DreamBooth.
Durch die entsprechende Einstellung von γ können wir ein geeignetes Bild erhalten.
Experimenteller Aufbau
Bisher gab es keine umfassende Forschung zur Stilanpassung von generativen Text-Bild-Modellen.
Deshalb schlugen die Forscher einen neuen Versuchsplan vor:
-Datensammlung
Die Forscher sammelten Dutzende Bilder verschiedener Stile, von Aquarellen und Ölgemälden, flachen Illustrationen, 3D-Renderings bis hin zu Skulpturen aus verschiedenen Materialien .
- Modellkonfiguration
Forscher verwenden Adapter, um Muse-basiertes StyleDrop abzustimmen. Für alle Experimente wurde der Adam-Optimierer verwendet, um die Adaptergewichte für 1000 Schritte mit einer Lernrate von 0,00003 zu aktualisieren. Sofern nicht anders angegeben, verwenden die Forscher StyleDrop zur Darstellung der zweiten Runde des Modells, das anhand von mehr als 10 synthetischen Bildern mit menschlichem Feedback trainiert wurde.
-Bewertung
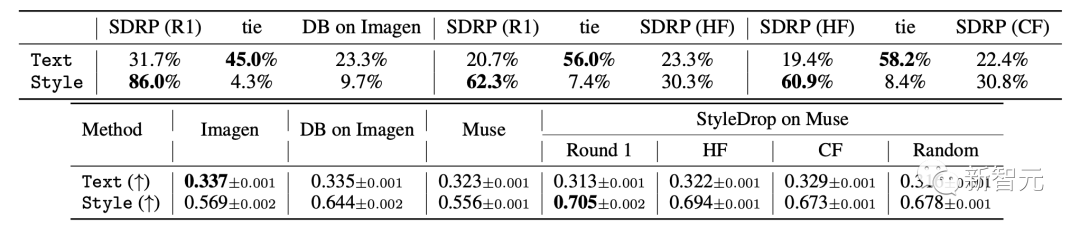
Quantitative Bewertung von Forschungsberichten basierend auf CLIP, Messung der Stilkonsistenz und Textausrichtung. Darüber hinaus führten die Forscher Studien zu Benutzerpräferenzen durch, um die Stilkonsistenz und die Textausrichtung zu bewerten.
Wie im Bild gezeigt, sind die Ergebnisse der StyleDrop-Verarbeitung von 18 Bildern verschiedener Stile, die von den Forschern gesammelt wurden.
Wie Sie sehen, ist StyleDrop in der Lage, die Nuancen von Textur, Schattierung und Struktur verschiedener Stile zu erfassen, sodass Sie den Stil besser kontrollieren können als zuvor.

Zum Vergleich stellten die Forscher auch die Ergebnisse von DreamBooth auf Imagen, die LoRA-Implementierung von DreamBooth auf Stable Diffusion und die Ergebnisse der Textinversion vor.

Die spezifischen Ergebnisse sind in der Tabelle dargestellt, die Bewertungsindikatoren für die menschliche Bewertung (oben) und die CLIP-Bewertung (unten) für die Bild-Text-Ausrichtung (Text) und die visuelle Stilausrichtung (Stil).
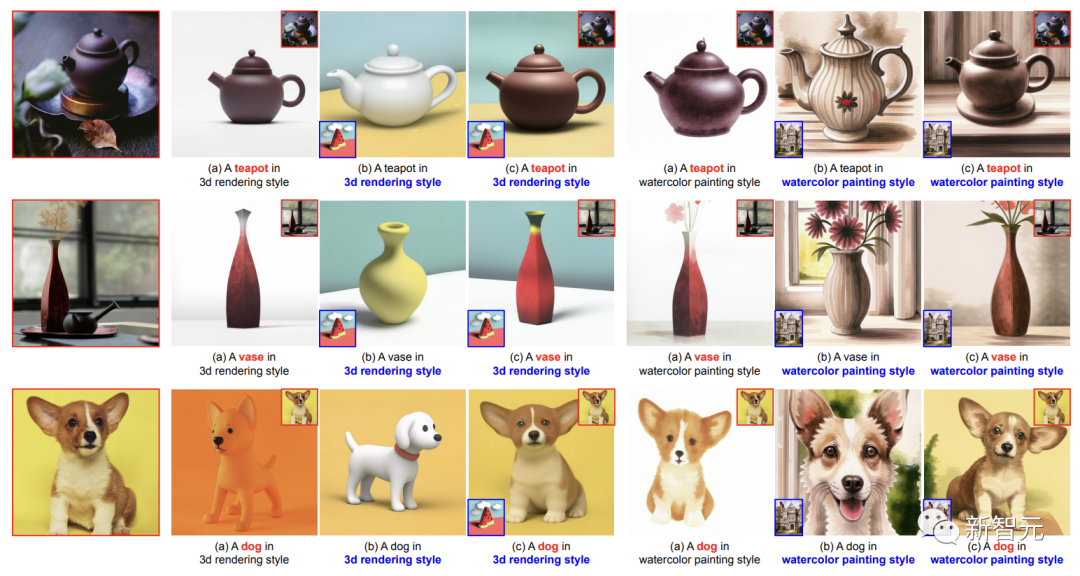
Qualitativer Vergleich von (a) DreamBooth, (b) StyleDrop und (c) DreamBooth + StyleDrop:
Hier verwendeten die Forscher die oben genannten zwei Metriken CLIP für die Partitur - Text und Stil der Partituren.
Für die Textbewertung messen Forscher die Kosinusähnlichkeit zwischen Bild- und Texteinbettungen. Für die Stilbewertung messen die Forscher die Kosinusähnlichkeit zwischen der Stilreferenz und der synthetischen Bildeinbettung.
Die Forscher generierten insgesamt 1520 Bilder für 190 Textaufforderungen. Obwohl die Forscher hofften, dass das Endergebnis höher ausfallen würde, sind die Messwerte nicht perfekt.
Und iteratives Training (IT) verbesserte die Textbewertung, was den Zielen der Forscher entspricht.
Als Kompromiss werden jedoch ihre Stilwerte für das Erstrundenmodell reduziert, da sie auf synthetischen Bildern trainiert werden und der Stil möglicherweise durch Auswahlverzerrungen verzerrt ist.
DreamBooth auf Imagen ist StyleDrop in der Stilbewertung unterlegen (0,644 vs. 0,694 für HF).
Die Forscher stellten fest, dass der Anstieg des Style-Scores von DreamBooth auf Imagen nicht offensichtlich war (0,569 → 0,644), während der Anstieg von StyleDrop auf Muse offensichtlicher war (0,556 → 0,694).
Forscher haben analysiert, dass die Stiloptimierung bei Muse effektiver ist als die bei Imagen.
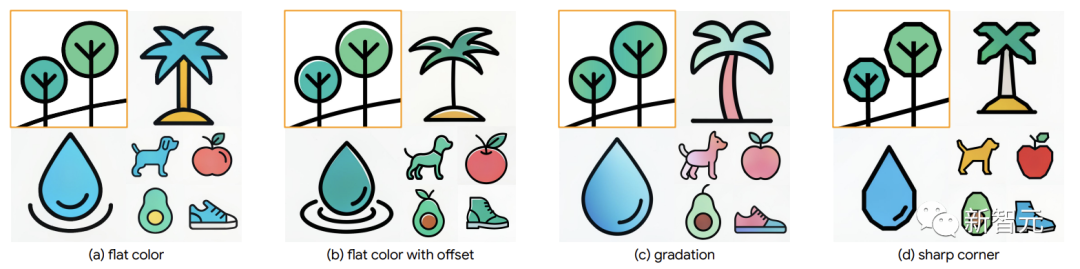
Darüber hinaus erfasst StyleDrop für eine feinkörnige Steuerung subtile Stilunterschiede wie Farbversatz, Abstufung oder scharfe Winkelsteuerung.
Heiße Kommentare von Internetnutzern
Wenn Designer StyleDrop haben, wird ihre Arbeitseffizienz zehnmal schneller sein, was bereits rasant zugenommen hat.
Eines Tages auf KI, 10 Jahre auf der Erde, entwickelt sich AIGC mit Lichtgeschwindigkeit, der Art von Lichtgeschwindigkeit, die die Augen der Menschen blendet!
Werkzeuge folgen einfach dem Trend, und diejenigen, die abgeschafft werden sollten, sind längst abgeschafft.
Dieses Tool ist zum Erstellen von Logos viel einfacher zu verwenden als Midjourney.
Das obige ist der detaillierte Inhalt vonMidjourneys Rivale ist da! Googles StyleDrop-Ass „Customization Master' lässt den KI-Kunstkreis explodieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
