
 Technologie-Peripheriegeräte
KI
Neue Forschungsergebnisse von NeRF sind da: 3D-Szenen werden ohne Objekte spurlos und haargenau entfernt
Technologie-Peripheriegeräte
KI
Neue Forschungsergebnisse von NeRF sind da: 3D-Szenen werden ohne Objekte spurlos und haargenau entfernt
Neue Forschungsergebnisse von NeRF sind da: 3D-Szenen werden ohne Objekte spurlos und haargenau entfernt

Neurale Strahlungsfelder (NeRF) sind zu einer beliebten neuen Methode zur Synthese von Sichtweisen geworden. Obwohl sich NeRF schnell auf ein breiteres Spektrum von Anwendungen und Datensätzen verallgemeinert, bleibt die direkte Bearbeitung von NeRF-Modellierungsszenarien eine große Herausforderung. Eine wichtige Aufgabe besteht darin, unerwünschte Objekte aus einer 3D-Szene zu entfernen und die Konsistenz mit der umgebenden Szene aufrechtzuerhalten. Diese Aufgabe wird als 3D-Bild-Inpainting bezeichnet. In 3D müssen Lösungen über mehrere Ansichten hinweg konsistent und geometrisch gültig sein.
In diesem Artikel schlagen Forscher von Samsung, der University of Toronto und anderen Institutionen eine neue 3D-Inpainting-Methode vor, um diese Herausforderungen zu lösen. Zunächst wird ein kleiner Satz von Posenbildern und spärliche Anmerkungen in einem einzelnen Eingabebild vorgeschlagen Erhalten Sie schnell die dreidimensionale Segmentierungsmaske des Zielobjekts, verwenden Sie die Maske und führen Sie dann eine auf Wahrnehmungsoptimierung basierende Methode ein, die die gelernten zweidimensionalen Bilder verwendet, um sie zu reparieren, ihre Informationen in den dreidimensionalen Raum zu extrahieren und gleichzeitig sicherzustellen die Ansichtskonsistenz.
Diese Studie bringt auch einen neuen Maßstab für die Bewertung von 3D-In-Scene-Inpainting-Methoden durch das Training eines anspruchsvollen realen Szenendatensatzes. Insbesondere enthält dieser Datensatz Ansichten derselben Szene mit und ohne Zielobjekte, was ein prinzipielleres Benchmarking von Inpainting-Aufgaben im 3D-Raum ermöglicht.

- Papieradresse: https://arxiv.org/pdf/2211.12254.pdf
- Papierhomepage: https://spinnerf3d.github.io/.
Das Folgende ist eine Demonstration des Effekts, der immer noch mit der umgebenden Szene übereinstimmt:

Vergleich zwischen dieser Methode und anderen Methoden, während diese Methode offensichtliche Artefakte aufweist Nicht so offensichtlich:

Einführung in die Methode
Der Autor befasst sich mit verschiedenen Herausforderungen bei 3D-Szenenbearbeitungsaufgaben durch einen integrierten Ansatz, der Mehransichtsbilder der Szene erhält und 3D-Bilder mit Benutzereingabemaske extrahiert und anpasst Das Maskenbild wird mithilfe von NeRF trainiert, sodass das Zielobjekt durch ein angemessenes dreidimensionales Erscheinungsbild und eine angemessene Geometrie ersetzt wird. Bestehende interaktive 2D-Segmentierungsmethoden berücksichtigen den 3D-Aspekt nicht, und aktuelle NeRF-basierte Methoden können mit spärlichen Annotationen keine guten Ergebnisse erzielen und erreichen keine ausreichende Genauigkeit. Während einige aktuelle NeRF-basierte Algorithmen das Entfernen von Objekten ermöglichen, versuchen sie nicht, neu generierte Raumteile bereitzustellen. Dem aktuellen Forschungsfortschritt zufolge ist diese Arbeit die erste, die gleichzeitig die interaktive Multi-View-Segmentierung und die vollständige 3D-Bildwiederherstellung in einem einzigen Framework abwickelt.
Forscher nutzen handelsübliche, 3D-freie Modelle zur Segmentierung und Bildwiederherstellung und übertragen ihre Ergebnisse auf ansichtskonsistente Weise in den 3D-Raum. Aufbauend auf Arbeiten zur interaktiven 2D-Segmentierung beginnt das von den Autoren vorgeschlagene Modell mit einer kleinen Anzahl von durch den Benutzer mit der Maus kalibrierten Bildpunkten auf einem Zielobjekt. Daraufhin initialisiert ihr Algorithmus die Maske mit einem videobasierten Modell und trainiert sie in eine kohärente 3D-Segmentierung, indem er den NeRF einer semantischen Maske anpasst. Anschließend wird die vorab trainierte 2D-Bildwiederherstellung auf den Multi-View-Bildsatz angewendet. Der NeRF-Anpassungsprozess wird verwendet, um die 3D-Bildszene zu rekonstruieren, wobei Wahrnehmungsverlust verwendet wird, um die Inkonsistenz des 2D-Bilds und der Geometrie des Normalisierten einzuschränken Maske des Tiefenbildes. Insgesamt bieten wir einen vollständigen Ansatz, von der Objektauswahl bis zur neuen Ansichtssynthese eingebetteter Szenen, in einem einheitlichen Framework mit minimaler Belastung für den Benutzer, wie in der folgenden Abbildung dargestellt.

Zusammenfassend sind die Beiträge dieser Arbeit wie folgt:
- Ein vollständiger 3D-Szenenbetriebsprozess, beginnend mit der Objektauswahl der Benutzerinteraktion und endend mit der 3D-reparierten NeRF-Szene; 🎜#Erweitern Sie das zweidimensionale Segmentierungsmodell auf Situationen mit mehreren Ansichten und stellen Sie dreidimensionale konsistente Masken aus spärlichen Anmerkungen wieder her Rationality, eine neue optimierungsbasierte 3D-Inpainting-Formulierung, die 2D-Bild-Inpainting nutzt;
- In der Studie wird zunächst insbesondere beschrieben, wie eine grobe 3D-Maske aus Einzelansichtsanmerkungen initialisiert wird. Bezeichnen Sie die kommentierte Quellcodeansicht als I_1. Geben Sie spärliche Informationen über Objekte und Quellansichten an ein interaktives Segmentierungsmodell weiter, um die anfängliche Quellobjektmaske
- zu schätzen. Die Trainingsansichten werden dann als Videosequenz behandelt, zusammen mit
- mit einem Videoinstanzsegmentierungsmodell V, um zu berechnen, wobei #🎜 🎜#
ist die erste Schätzung der Objektmaske von I_i. Die anfänglichen Masken sind in der Nähe von Grenzen häufig ungenau, da es sich bei den Trainingsansichten nicht um tatsächlich benachbarte Videobilder handelt und Videosegmentierungsmodelle häufig 3D-unbekannt sind. 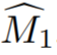
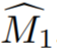
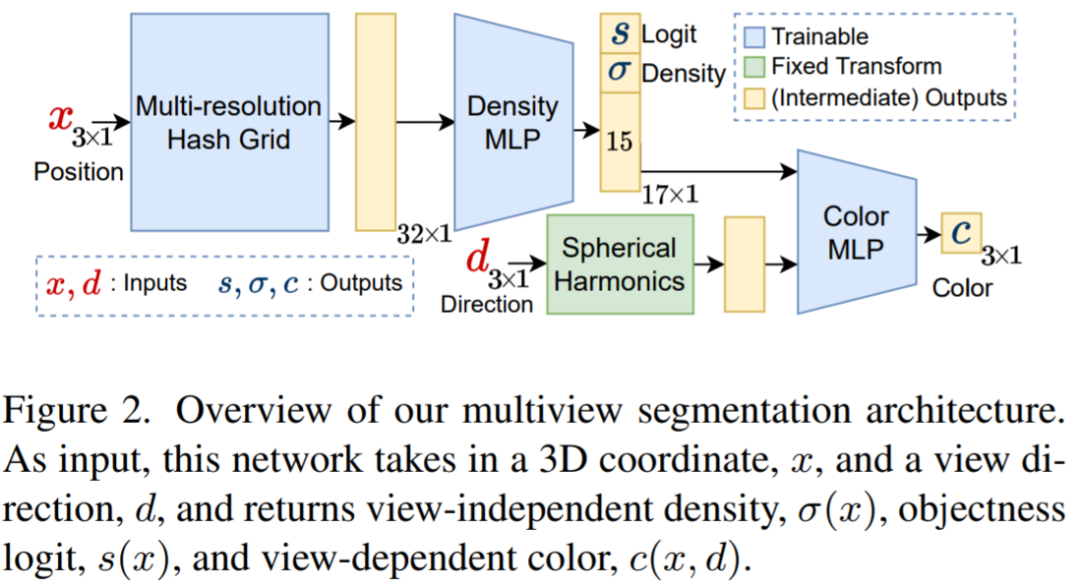
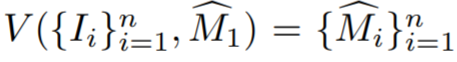 Das Multi-View-Segmentierungsmodul erhält das eingegebene RGB-Bild und das entsprechende Kamera-intrinsische und externe Parameter sowie anfängliche Masken zum Trainieren eines semantischen NeRF. Das obige Diagramm zeigt das im semantischen NeRF verwendete Netzwerk für einen Punkt x und ein Ansichtsverzeichnis d. Zusätzlich zur Dichte σ und der Farbe c gibt es einen Präsigmoid-Objekt-Logit s (x) zurück. Für die schnelle Konvergenz verwendeten die Forscher Instant-NGP als NeRF-Architektur. Die mit einem Strahl r verbundene gewünschte Objektivität erhält man, indem man in der Gleichung den Logarithmus der Punkte auf r und nicht ihre Farbe relativ zur Dichte darstellt: #
Das Multi-View-Segmentierungsmodul erhält das eingegebene RGB-Bild und das entsprechende Kamera-intrinsische und externe Parameter sowie anfängliche Masken zum Trainieren eines semantischen NeRF. Das obige Diagramm zeigt das im semantischen NeRF verwendete Netzwerk für einen Punkt x und ein Ansichtsverzeichnis d. Zusätzlich zur Dichte σ und der Farbe c gibt es einen Präsigmoid-Objekt-Logit s (x) zurück. Für die schnelle Konvergenz verwendeten die Forscher Instant-NGP als NeRF-Architektur. Die mit einem Strahl r verbundene gewünschte Objektivität erhält man, indem man in der Gleichung den Logarithmus der Punkte auf r und nicht ihre Farbe relativ zur Dichte darstellt: #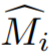 #🎜 🎜# Dann verwenden Sie den Klassifizierungsverlust zur Überwachung:
#🎜 🎜# Dann verwenden Sie den Klassifizierungsverlust zur Überwachung:
 #🎜 🎜#
#🎜 🎜#
Der verwendete Gesamtverlust Um das NeRF-basierte Multi-View-Segmentierungsmodell zu überwachen, lautet:
# 🎜🎜#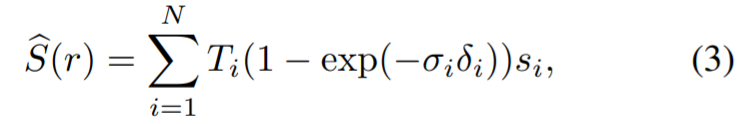
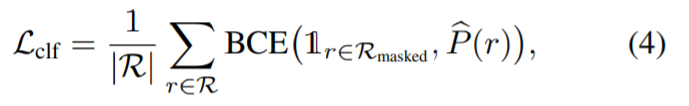 Das Bild oben zeigt eine Übersicht über die ansichtskonsistente Korrekturmethode. Da der Mangel an Daten ein direktes Training von 3D-modifizierten Inpainting-Modellen verhindert, nutzt diese Studie vorhandene 2D-Inpainting-Modelle, um Tiefen- und Erscheinungsbildprioritäten zu erhalten, und überwacht dann die Anpassung des NeRF-Renderings an die gesamte Szene. Dieses eingebettete NeRF wird mit dem folgenden Verlust trainiert:
Das Bild oben zeigt eine Übersicht über die ansichtskonsistente Korrekturmethode. Da der Mangel an Daten ein direktes Training von 3D-modifizierten Inpainting-Modellen verhindert, nutzt diese Studie vorhandene 2D-Inpainting-Modelle, um Tiefen- und Erscheinungsbildprioritäten zu erhalten, und überwacht dann die Anpassung des NeRF-Renderings an die gesamte Szene. Dieses eingebettete NeRF wird mit dem folgenden Verlust trainiert:
Diese Studie schlägt eine ansichtskonsistente Inpainting-Methode mit RGB-Eingabe vor. Zunächst überträgt die Studie Bild- und Maskenpaare an einen Image-Inpainter, um ein RGB-Bild zu erhalten. Da jede Ansicht unabhängig repariert wird, werden die reparierten Ansichten direkt zur Überwachung der Rekonstruktion von NeRF verwendet. Anstatt den mittleren quadratischen Fehler (MSE) als Verlust zum Generieren von Masken zu verwenden, schlagen die Forscher in diesem Artikel vor, den Wahrnehmungsverlust LPIPS zu verwenden, um den maskierten Teil des Bildes zu optimieren, während MSE weiterhin zur Optimierung des unmaskierten Teils verwendet wird. Dieser Verlust wird wie folgt berechnet:
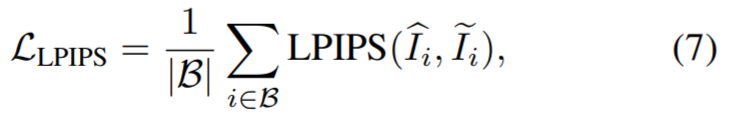
Reparieren Sie auch bei wahrgenommenem Verlust den Unterschiede zwischen ihnen können auch fälschlicherweise dazu führen, dass das Modell zu einer Geometrie mit geringerer Qualität konvergiert (z. B. können sich in der Nähe der Kamera „verschwommene“ Geometriemessungen bilden, um unterschiedliche Informationen aus jeder Ansicht zu berücksichtigen). Daher verwendeten die Forscher die generierte Tiefenkarte als zusätzliche Orientierungshilfe für das NeRF-Modell und trennten die Gewichte bei der Berechnung des Wahrnehmungsverlusts, wobei sie den Wahrnehmungsverlust nur zur Anpassung an die Farbe der Szene verwendeten. Zu diesem Zweck haben wir ein NeRF verwendet, das für Bilder mit unerwünschten Objekten optimiert ist, und gerenderte Tiefenkarten, die den Trainingsansichten entsprechen. Die Berechnungsmethode besteht darin, den Abstand zur Kamera anstelle der Farbe des Punktes zu verwenden:
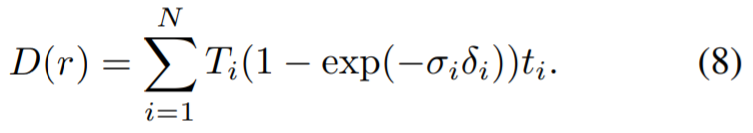
Dann wird die gerenderte Tiefe in das Fixer-Modell eingegeben, um die reparierte Tiefenkarte zu erhalten. Untersuchungen haben ergeben, dass die Verwendung von LaMa für Tiefenrendering, beispielsweise RGB, ausreichend hochwertige Ergebnisse liefern kann. Bei diesem NeRF kann es sich um dasselbe Modell handeln, das für die Segmentierung mit mehreren Ansichten verwendet wird. Wenn andere Quellen zum Erhalten der Masken verwendet werden, z. B. von Menschen kommentierte Masken, wird ein neues NeRF in der Szene installiert. Diese Tiefenkarten werden dann verwendet, um die Geometrie des eingefärbten NeRF zu überwachen, über das die gerenderte Tiefe dann in das Inpainter-Modell eingespeist wird, um die eingefärbte Tiefenkarte zu erhalten. Untersuchungen haben ergeben, dass die Verwendung von LaMa für Tiefenrendering, beispielsweise RGB, ausreichend hochwertige Ergebnisse liefern kann. Bei diesem NeRF kann es sich um dasselbe Modell handeln, das für die Segmentierung mit mehreren Ansichten verwendet wird. Wenn andere Quellen zum Erhalten der Masken verwendet werden, z. B. von Menschen kommentierte Masken, wird ein neues NeRF in der Szene installiert. Diese Tiefenkarten werden dann verwendet, um die Geometrie des eingefärbten NeRF zu überwachen, indem die Tiefe von der eingefärbten Tiefe zur eingefärbten Tiefe gerendert wird. 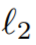 #🎜🎜 #
#🎜🎜 #
#🎜 🎜#
Multi-View-Segmentierung: Bewerten Sie zunächst das MVSeg-Modell ohne Bearbeitungskorrekturen. In diesem Experiment wird davon ausgegangen, dass spärlich besetzte Bildpunkte ein vorgefertigtes interaktives Segmentierungsmodell erhalten haben und Quellmasken verfügbar sind. Die Aufgabe besteht also darin, die Quellmaske in andere Ansichten zu übertragen. Die folgende Tabelle zeigt, dass das neue Modell die 2D- (3D-inkonsistent) und 3D-Basislinien übertrifft. Darüber hinaus trägt die von den Forschern vorgeschlagene zweistufige Optimierung dazu bei, die resultierende Maske weiter zu verbessern.
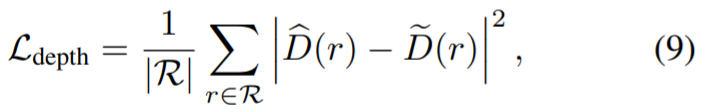
Zur qualitativen Analyse vergleicht die folgende Abbildung die Ergebnisse des Forschersegmentierungsmodells mit NVOS und Die Ergebnisse verschiedener Videosegmentierungsmethoden werden verglichen. Ihr Modell reduziert Rauschen und verbessert die Ansichtskonsistenz im Vergleich zu den dicken Kanten von 3D-Videosegmentierungsmodellen. Obwohl NVOS Scribbles anstelle der im neuen Modell der Forscher verwendeten spärlichen Punkte verwendet, ist das MVSeg des neuen Modells NVOS optisch überlegen. Da die NVOS-Codebasis nicht verfügbar ist, replizierten die Forscher veröffentlichte qualitative Ergebnisse zu NVOS (weitere Beispiele finden Sie im Zusatzdokument).
Die folgende Tabelle zeigt den Vergleich der MV-Methode mit der Basislinie. Insgesamt übertrifft die neu vorgeschlagene Methode andere 2D- und 3D-Reparaturmethoden deutlich. Die folgende Tabelle zeigt außerdem, dass das Entfernen der Führung aus geometrischen Strukturen die Qualität der reparierten Szene beeinträchtigt. Die qualitativen Ergebnisse sind in Abbildung 6 und Abbildung 7 dargestellt. Abbildung 6 zeigt, dass unsere Methode ansichtskonsistente Szenen mit detaillierten Texturen rekonstruieren kann, einschließlich kohärenter Ansichten von glänzenden und matten Oberflächen. Abbildung 7 zeigt, dass unser wahrnehmungsbezogener Ansatz die Einschränkungen bei der genauen Rekonstruktion von Maskenbereichen verringert und dadurch das Auftreten von Unschärfe bei Verwendung aller Bilder verhindert und gleichzeitig Artefakte vermeidet, die durch die Einzelansichtsüberwachung verursacht werden.
# 🎜 🎜#

Das obige ist der detaillierte Inhalt vonNeue Forschungsergebnisse von NeRF sind da: 3D-Szenen werden ohne Objekte spurlos und haargenau entfernt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.
Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
