
 Technologie-Peripheriegeräte
KI
Detaillierte Erläuterung der Transformer-Struktur und ihrer Anwendungen – GPT, BERT, MT-DNN, GPT-2
Technologie-Peripheriegeräte
KI
Detaillierte Erläuterung der Transformer-Struktur und ihrer Anwendungen – GPT, BERT, MT-DNN, GPT-2
Detaillierte Erläuterung der Transformer-Struktur und ihrer Anwendungen – GPT, BERT, MT-DNN, GPT-2

Bevor wir Transformer vorstellen, werfen wir einen Blick auf die Struktur von RNN
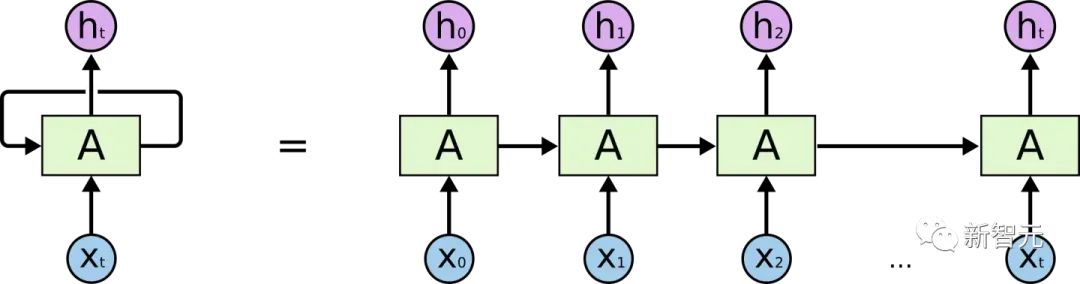
Wenn Sie ein gewisses Verständnis von RNN haben, werden Sie definitiv wissen, dass RNN zwei offensichtliche Probleme hat
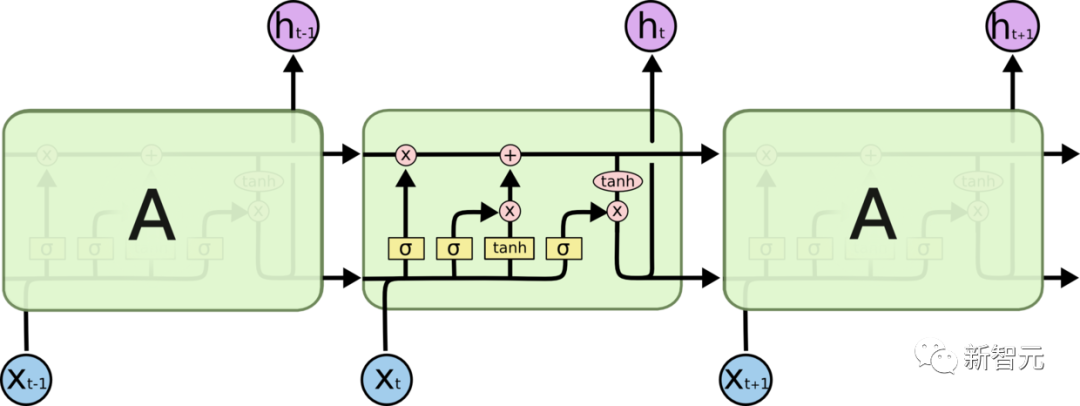
- Effizienzproblem: Es muss so sein Wort für Wort kann das nächste Wort erst verarbeitet werden, wenn der verborgene Zustand des vorherigen Wortes ausgegeben wird. Wenn der Übertragungsabstand zu lang ist, kommt es zu Gradientenverschwinden, Gradientenexplosion und Vergessensproblemen Übertragungen und Vergessensproblemen wurden verschiedene RNN-Zellen entworfen, die beiden bekanntesten sind LSTM und GRU
- LSTM (Long Short Term Memory)
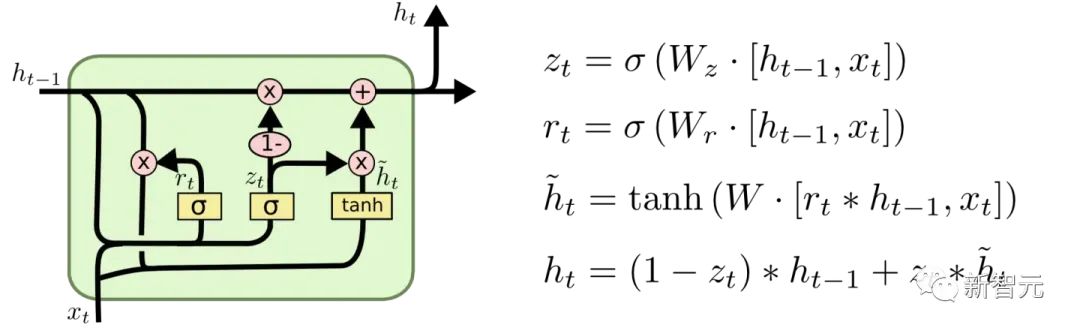
GRU (Gated Recurrent Unit)
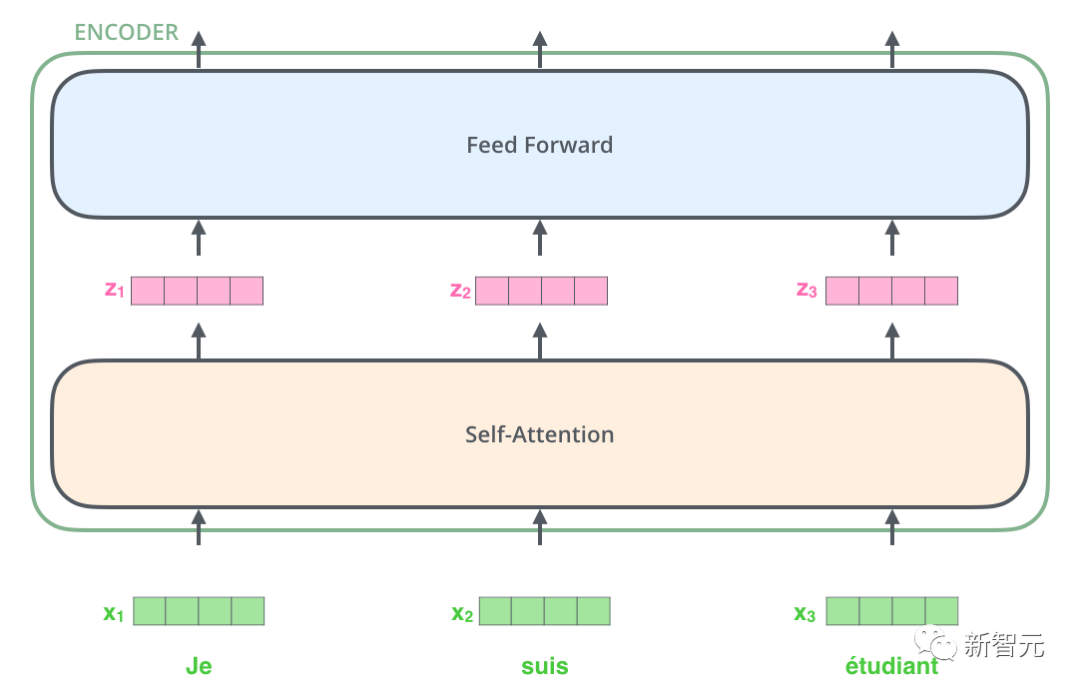
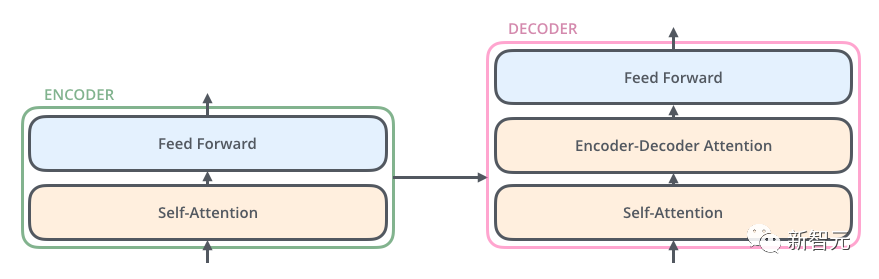
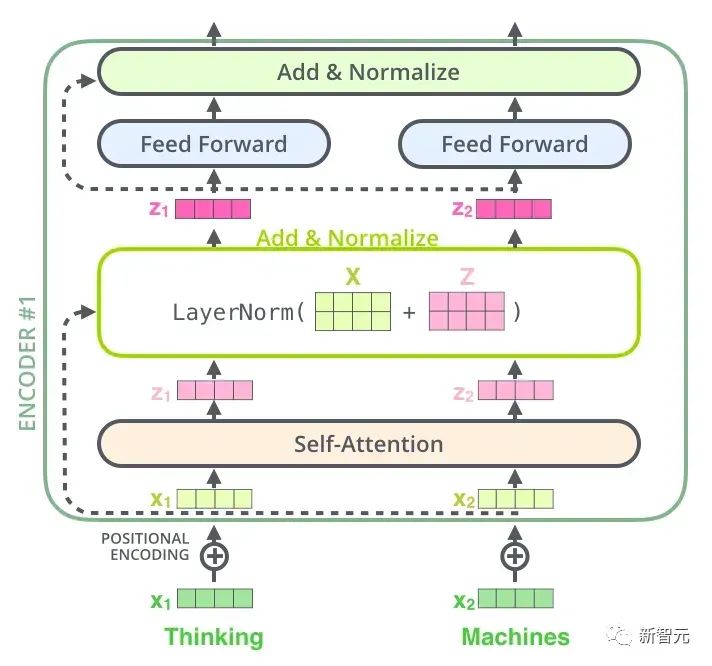
Da ist also die Kernstruktur, die wir in diesem Artikel vorstellen werden – Transformer. Transformer ist eine von Google Brain 2017 vorgeschlagene Arbeit. Es überarbeitet die Schwächen von RNN, behebt RNN-Effizienzprobleme und Übertragungsfehler und übertrifft die Leistung von RNN in vielen Punkten. Die Grundstruktur von Transformer ist in der folgenden Abbildung dargestellt. Es handelt sich um eine N-in-N-out-Struktur, das heißt, jede Transformer-Einheit entspricht einer Schicht einer RNN-Schicht als Eingabe und stellt dann jedes Wort im Satz bereit. Jedes Wort erzeugt eine Ausgabe. Im Gegensatz zu RNN kann Transformer jedoch alle Wörter im Satz gleichzeitig verarbeiten, und der Betriebsabstand zwischen zwei beliebigen Wörtern beträgt 1. Dies löst effektiv das oben erwähnte Effizienzproblem und die Entfernungsfrage von RNN.
Jede Transformer-Einheit verfügt über zwei wichtigste Unterschichten, nämlich die Self-Attention-Schicht und die Feed-Forward-Schicht. Die detaillierten Strukturen dieser beiden Schichten werden später vorgestellt. Der Artikel verwendet Transformer, um ein Seq2Seq ähnliches Sprachübersetzungsmodell zu erstellen, und entwirft zwei verschiedene Transformer-Strukturen für Encoder und Decoder.
Zuerst kodiert der Transformer den Satz in der Originalsprache, um Speicher zu erhalten. 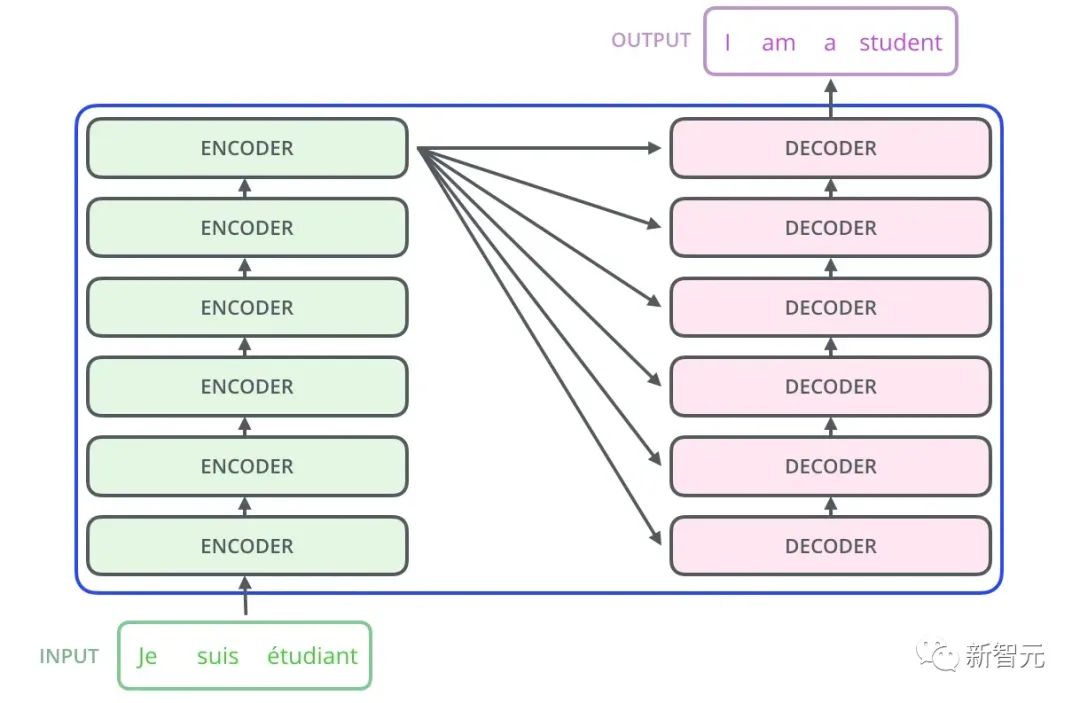
Bei der ersten Dekodierung hat die Eingabe nur ein
- Der Decoder erhält aus dieser einzigartigen Eingabe eine eindeutige Ausgabe, die zur Vorhersage des ersten Wortes des Satzes verwendet wird.
- Zum zweiten Mal dekodieren. Die Eingabe wird zu
und das erste Wort des Satzes (Grundwahrheit oder Vorhersage aus dem vorherigen Schritt). wird verwendet, um das zweite Wort des Satzes vorherzusagen. Analog dazu (der Prozess ist Seq2Seq sehr ähnlich) - Nachdem wir die allgemeine Struktur von Transformer verstanden haben und wissen, wie man damit Übersetzungsaufgaben erledigt, werfen wir einen Blick auf die detaillierte Struktur von Transformer:
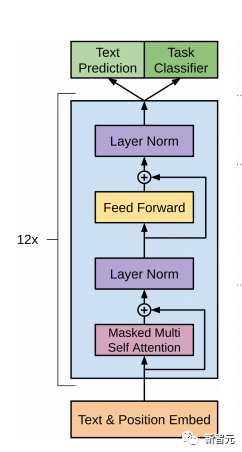
Die Kernkomponenten sind die oben erwähnten Self-Attention- und Feed-Forward-Netzwerke, aber es gibt noch viele andere Details, und dann werden wir beginnen, sie zu strukturieren einer nach dem anderen, um Transformer zu interpretieren. Selbstaufmerksamkeit Selbstaufmerksamkeit ist etwas in einem Satz Wort macht Aufmerksamkeit ein für alle Mal, Worte seiner selbst. Berechnen Sie das Gewicht jedes Wortes für dieses Wort und stellen Sie dieses Wort dann als gewichtete Summe aller Wörter dar. Jede Selbstaufmerksamkeitsoperation ähnelt einer Faltungsoperation oder einer Aggregationsoperation für jedes Wort. Die spezifische Operation ist wie folgt: Zunächst durchläuft jedes Wort eine lineare Änderung durch drei Matrizen Wq, Wk, Wv, die in drei Teile unterteilt sind, um für jedes Wort drei Vektoren zu erzeugen einer eigenen Abfrage, eines eigenen Schlüssels und eines eigenen Vektors. Wenn Sie „Selbstaufmerksamkeit“ mit einem Wort als Mittelpunkt durchführen, wird der Schlüsselvektor des Wortes verwendet, um das Skalarprodukt mit dem Abfragevektor jedes Wortes zu bilden, und dann wird die Gewichtung durch Softmax normalisiert. Verwenden Sie dann diese Gewichte, um die gewichtete Summe der Vektoren aller Wörter als Ausgabe dieses Wortes zu berechnen. Der spezifische Prozess ist in der folgenden Abbildung dargestellt Vor der Normalisierung muss er durch Division durch die Dimension dk des Vektors standardisiert werden, damit die endgültige Selbstaufmerksamkeit ermittelt werden kann ausgedrückt als Schließlich akzeptiert jede Selbstaufmerksamkeit die Eingabe von n Wortvektoren und gibt n aggregierte Vektoren aus. Wie oben erwähnt, unterscheidet sich die Selbstaufmerksamkeit im Encoder von der im Decoder. Die Werte Q, K und V im Encoder stammen alle aus der Ausgabe von die obere Schichteinheit, während nur Q des Decoders vom Ausgang der vorherigen Decodereinheit stammt und sowohl K als auch V vom Ausgang der letzten Schicht des Encoders stammen. Mit anderen Worten: Der Decoder berechnet die Gewichtung anhand des aktuellen Status und der Ausgabe des Encoders und gewichtet dann die Codierung des Encoders, um den Status der nächsten Ebene zu erhalten. #? Außerdem gibt es einen weiteren Unterschied zwischen Decoder und Encoder: Die Eingabeschicht jeder Decoder-Einheit muss zuerst eine Masked Attention-Schicht durchlaufen. Was ist also der Unterschied zwischen Masked und der gewöhnlichen Version von Attention? Encoder Da der gesamte Satz codiert werden muss, muss bei jedem Wort der Kontext berücksichtigt werden. Daher sind während des Berechnungsprozesses jedes Wortes alle Wörter im Satz sichtbar. Der Decoder ähnelt jedoch dem Decoder in Seq2Seq. Jedes Wort kann nur den Status des vorherigen Wortes sehen, es handelt sich also um eine einseitige Selbstaufmerksamkeitsstruktur. Multi-Head Aufmerksamkeit besteht darin, die oben genannte Aufmerksamkeit h-mal auszuführen und dann die h-Ausgaben zu verknüpfen, um die endgültige Ausgabe zu erhalten. Dies kann die Stabilität des Algorithmus erheblich verbessern und hat relevante Anwendungen in vielen aufmerksamkeitsbezogenen Arbeiten. Bei der Implementierung von Transformer wird W um das h-fache erweitert, um die Effizienz von Multi-Head zu verbessern, und dann werden k, q und v verschiedener Köpfe desselben Wortes für die gleichzeitige Berechnung durch Ansicht (Umformung) zusammen angeordnet ) und Transponierungsoperationen, um die Berechnung abzuschließen. Anschließend wird das Spleißen durch Umformen und Transponieren erneut abgeschlossen, was einer parallelen Verarbeitung aller Köpfe entspricht. Positionsweise Feed Forward Networks Encoder neutralisiert Decoder N Vektoren, die nach der Aufmerksamkeit ausgegeben werden (hier ist n die Anzahl der Wörter), werden jeweils in eine vollständig verbundene Schicht eingegeben, um ein Position-für-Position-Feedforward-Netzwerk zu vervollständigen. Hinzufügen & Normieren ist ein Restnetzwerk, das lediglich die Eingabe einer Schicht und deren standardisierte Ausgabe hinzufügt. Auf jede Self-Attention-Ebene und FFN-Ebene in Transformer folgt eine Add & Norm-Ebene. Positionskodierung Da es in Transformer weder RNN noch CNN gibt, werden alle Wörter im Satz gleich behandelt, sodass keine sequentielle Beziehung zwischen Wörtern besteht. Mit anderen Worten: Es weist wahrscheinlich die gleichen Mängel auf wie das Bag-of-Words-Modell. Um dieses Problem zu lösen, schlug Transformer die Positional Encoding-Lösung vor, die darin besteht, jedem Eingabewortvektor einen festen Vektor zu überlagern, um seine Position darzustellen. Die im Artikel verwendete Positionskodierung lautet wie folgt: wobei pos die Position des Wortes im Satz und i die i-te Position im Wortvektor ist Das heißt, der Wortvektor jedes Wortes ist Eine Zeile wird überlagert, und dann wird jeder Spalte eine Welle mit einer anderen Phase oder einer allmählich zunehmenden Wellenlänge überlagert, um die Position eindeutig zu unterscheiden. Transformer-Workflow Der Workflow von Transformer ist wie oben beschrieben Das Spleißen jedes Unterprozesses Post Scriptum Obwohl im Transformer-Artikel ein Übersetzungsmodell in natürlicher Sprache vorgeschlagen wird, wird dieses Modell in vielen Artikeln als Transformer bezeichnet. Aber wir neigen immer noch dazu, die Unterstruktur des Encoders oder Decoders, der Selbstaufmerksamkeit verwendet, im Artikel als Transformer zu bezeichnen. Der Text und der Quellcode enthalten auch viele andere Optimierungen wie dynamische Änderungen der Lernrate, Residual Dropout und Label Smoothing, auf die ich hier nicht näher eingehen werde. Interessierte Freunde können die entsprechenden Referenzen lesen, um mehr zu erfahren. GPT (Generative Pre-Training) ist ein von OpenAI im Jahr 2018 vorgeschlagenes Modell Verwenden Sie das Transformer-Modell, um verschiedene Probleme in natürlicher Sprache zu lösen, z. B. Modelle für Klassifizierung, Argumentation, Beantwortung von Fragen, Ähnlichkeit und andere Anwendungen. GPT verwendet den Trainingsmodus „Vortraining + Feinabstimmung“, der die Nutzung einer großen Menge unbeschrifteter Daten ermöglicht und die Wirksamkeit dieser Probleme erheblich verbessert. GPT ist einer der Versuche, Transformer zur Ausführung verschiedener Aufgaben in natürlicher Sprache zu verwenden. Es weist hauptsächlich die folgenden drei Punkte auf: #🎜🎜 ## 🎜🎜# Einweg-Transformator-Modell
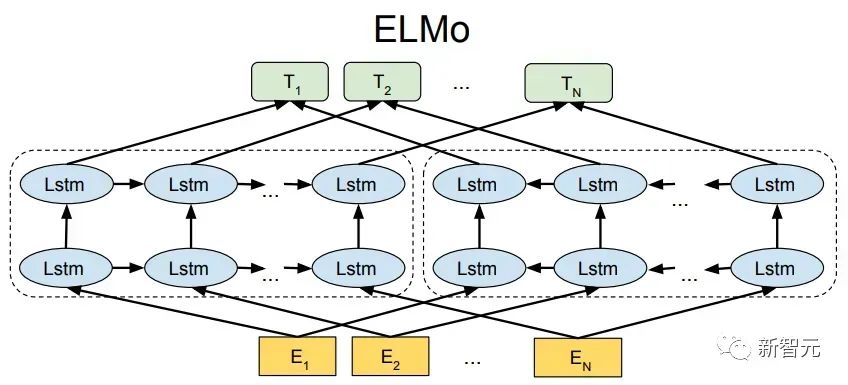
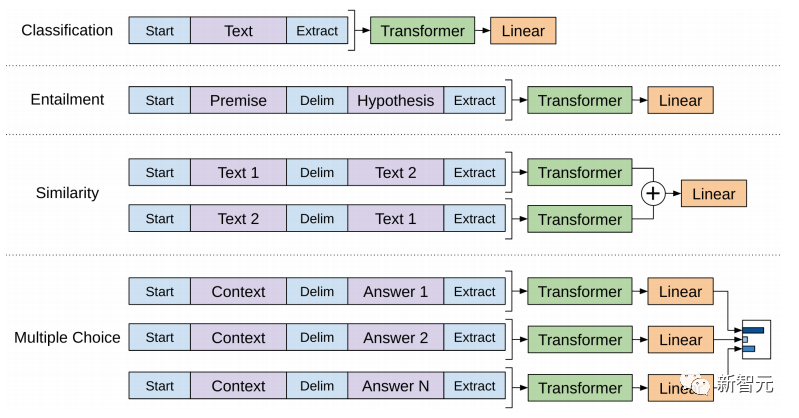
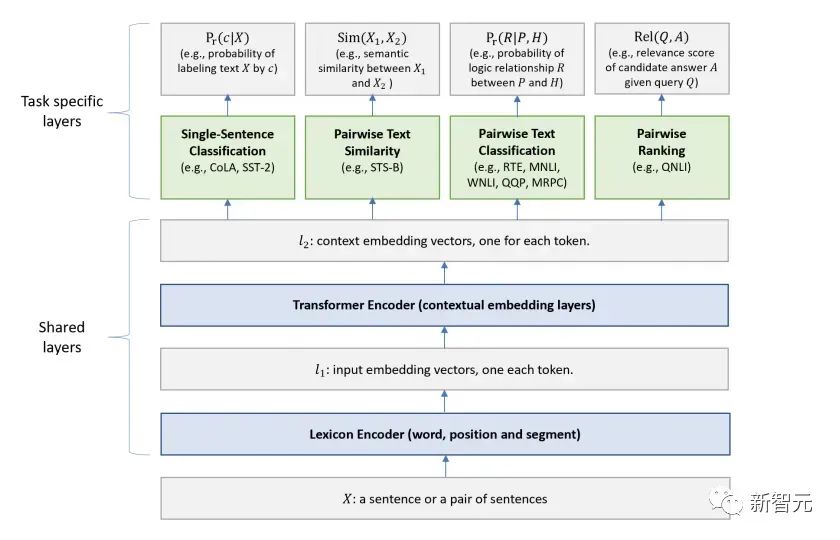
Viele maschinelle Lernaufgaben erfordern gekennzeichnete Datensätze als Eingabe. Aber um uns herum gibt es eine große Menge unbeschrifteter Daten wie Texte, Bilder, Code usw. Die Kennzeichnung dieser Daten erfordert viel Personal und Zeit, und die Geschwindigkeit der Kennzeichnung ist weitaus geringer als die Geschwindigkeit der Datengenerierung, sodass gekennzeichnete Daten oft nur einen kleinen Teil des gesamten Datensatzes einnehmen. Da die Rechenleistung immer besser wird, nimmt die Datenmenge, die Computer verarbeiten können, allmählich zu. Es wäre eine Verschwendung, wenn diese unbeschrifteten Daten nicht sinnvoll genutzt werden könnten. Daher erfreut sich das zweistufige Modell aus halbüberwachtem Lernen und Vortraining + Feinabstimmung immer größerer Beliebtheit. Die gebräuchlichste zweistufige Methode ist Word2Vec, die eine große Menge unbeschrifteten Textes verwendet, um Wortvektoren mit bestimmten semantischen Informationen zu trainieren, und diese Wortvektoren dann als Eingabe für nachgelagerte maschinelle Lernaufgaben verwendet, was die Generalisierungsfähigkeit erheblich verbessern kann Downstream-Modell. Aber es gibt ein Problem mit Word2Vec, das heißt, ein einzelnes Wort kann nur eine Einbettung haben. Auf diese Weise kann Polysemie nicht gut dargestellt werden. ELMo dachte zunächst darüber nach, Kontextinformationen für jeden Vokabularsatz in der Vortrainingsphase bereitzustellen, indem er ein auf Bi-LSTM basierendes Sprachmodell verwendete, um dem Wort kontextuelle Semantik zu verleihen Vektor. Informationen: Die obige Formel stellt den linken bzw. rechten LSTM-RNN dar und sie teilen sich die Eingabe Wortvektor Die spezifische Struktur ist in der folgenden Abbildung dargestellt: #🎜 🎜# Aber ELMo verwendet RNN, um das Vortraining abzuschließen Sprachmodell. Wie kann ich Transformer verwenden, um das Vortraining abzuschließen? Einwegtransformatorstruktur OpenAI GPT übernimmt ein- Art und Weise, wie Transformer diese Vortrainingsaufgabe abschließt. Was ist ein Einwegtransformator? Im Transformer-Artikel wird erwähnt, dass der von Encoder und Decoder verwendete Transformer-Block unterschiedlich ist. Im Decoder-Block wird maskierte Selbstaufmerksamkeit verwendet, das heißt, jedes Wort im Satz kann nur auf alle vorherigen Wörter achten, einschließlich sich selbst. Dies ist ein Einwegtransformator. Die von GPT verwendete Transformer-Struktur ersetzt die Selbstaufmerksamkeit im Encoder durch die maskierte Selbstaufmerksamkeit. Die spezifische Struktur ist in der folgenden Abbildung dargestellt: #🎜🎜 ##🎜 🎜# #🎜 🎜## 🎜🎜# Aufgrund der Verwendung von Masked Self-Attention werden die Wörter an jeder Position Folgendes nicht „sehen“. Das heißt, die „Antwort“ kann während der Vorhersage nicht gesehen werden, was die Rationalität des Modells gewährleistet. Aus diesem Grund verwendet OpenAI einen Einwegtransformator. Feinabstimmung und Änderungen in verschiedenen Eingabedatenstrukturen Der nächste Schritt besteht darin, in den zweiten Schritt des Modelltrainings einzutreten und eine kleine Menge beschrifteter Daten zur Feinabstimmung der Modellparameter zu verwenden. Wir haben die Ausgabe des letzten Wortes im vorherigen Schritt nicht verwendet. In diesem Schritt verwenden wir diese Ausgabe als Eingabe für nachgelagertes überwachtes Lernen. Um zu vermeiden, dass die Feinabstimmung dazu führt, dass das Modell in eine Überanpassung gerät, werden in dem Artikel auch Methoden für zusätzliche Trainingsziele erwähnt, ähnlich einem Multitasking-Modell oder halbüberwachtem Lernen. Die spezifische Methode besteht darin, das Vorhersageergebnis des letzten Wortes für überwachtes Lernen zu verwenden und gleichzeitig das unbeaufsichtigte Training der vorherigen Wörter fortzusetzen, sodass die endgültige Verlustfunktion wie folgt lautet: Für verschiedene Aufgaben müssen die Eingabedaten eingegeben werden geändert werden. Das Format: Post Scriptum OpenAI GPT basiert auf dem Verwendung von Transformer und der zweistufigen Trainingsmethode Es hat eine gute Erkundung gemacht und sehr gute Ergebnisse erzielt, was später den Weg für BERT ebnete. Bidirektionales zweistufiges Trainingsmodell – BERT Es ist ein Starmodell, das sofort nach seiner Einführung populär wurde. Wie GPT übernimmt BERT die Trainingsmethode „Vortraining + Feinabstimmung“ und erzielt bessere Ergebnisse bei Aufgaben wie Klassifizierung und Kennzeichnung. BERT ist GPT sehr ähnlich. Beide sind zweistufige Trainingsmodelle, die auf Transformer basieren. Beide sind in zwei Phasen unterteilt: Pre-Training und Fine-Tuning. Beide trainieren ein universelles Modell in der Pre-Training-Phase .Transformer-Modell und optimieren Sie dann die Parameter dieses Modells in der Feinabstimmungsphase, um es an verschiedene nachgelagerte Aufgaben anzupassen.
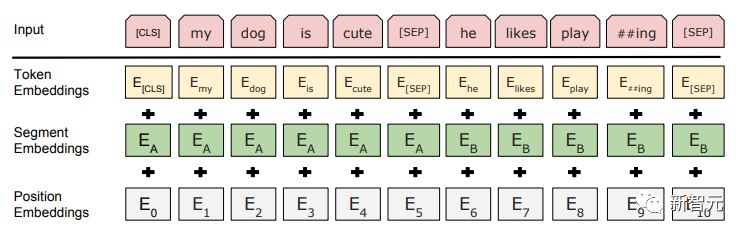
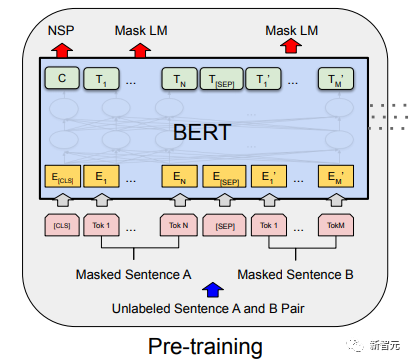
GPT verwendet einen Einwegtransformator, während BERT einen bidirektionalen Transformator verwendet, also keine Maske Bedienung ist erforderlich; Die unterschiedlichen Strukturen führen direkt zu unterschiedlichen Trainingszielen in der Vortrainingsphase; BERT verwendet einen Zwei-Wege-Transformer, um gleichzeitig Kontextinformationen zu erhalten, anstatt wie GPT vollständig auf Kontextinformationen zu verzichten. Auf diese Weise ist es jedoch nicht mehr möglich, ein normales Sprachmodell wie GPT für das Vortraining zu verwenden, da die Struktur von BERT dazu führt, dass die Ausgabe jedes Transformers den gesamten Satz anzeigt, unabhängig davon, was Sie mit dieser Ausgabe vorhersagen. Sie werden es „sehen“ „Referenzantwort, das ist die Frage „sehen Sie sich selbst“. Obwohl ELMo ein bidirektionales RNN verwendet, sind die beiden RNNs unabhängig, sodass das Problem des Selbstsehens vermieden werden kann. Vortrainingsphase Wenn BERT dann das bidirektionale Transformer-Modell verwenden möchte, muss es das in GPT als Zielfunktion vor dem Training verwendete Sprachmodell aufgeben. Stattdessen schlägt BERT eine völlig andere Pre-Training-Methode vor. In Transformer möchten wir nicht nur die oben genannten Informationen wissen, sondern auch die folgenden Informationen, aber gleichzeitig müssen wir sicherstellen, dass das Ganze Wenn das Modell die vorherzusagenden Informationen nicht kennt, teilen Sie dem Modell die Informationen über das Wort einfach nicht mit. Das heißt, BERT gräbt einige Wörter aus, die im Eingabesatz vorhergesagt werden müssen, analysiert dann den Satz anhand des Kontexts und verwendet schließlich die Ausgabe seiner entsprechenden Position, um die ausgegrabenen Wörter vorherzusagen. Es ist eigentlich so, als würde man einen Lückentext machen. Das direkte Ersetzen einer großen Anzahl von Wörtern durch 1. Wählen Sie zufällig 15 % der Wörter in den Eingabedaten für die Vorhersage aus, 2,80 % die Wörter Wenn der Vektor eingegeben wird, wird er durch ersetzt. 10 % der Wortvektoren werden bei der Eingabe durch die Wortvektoren anderer Wörter ersetzt Auf diese Weise ist es gleichbedeutend damit, dem Modell zu sagen, dass ich Ihnen möglicherweise eine Antwort geben kann, oder dass ich Ihnen möglicherweise keine Antwort gebe, oder dass ich Ihnen möglicherweise eine falsche Antwort gebe. Wo es Next Sentence Prediction (NSP) Um den Kontext zweier Sätze zu unterscheiden, fügt BERT nicht nur die Positionskodierung hinzu, sondern auch eine Segmenteinbettung, die während des Vortrainings erlernt werden muss, um die beiden Sätze zu unterscheiden. Auf diese Weise besteht die Eingabe von BERT aus der Addition von drei Teilen: Wortvektor, Positionsvektor und Segmentvektor. Zusätzlich werden die beiden Sätze durch das Tag Das schematische Diagramm des gesamten Vortrainings sieht wie folgt aus:
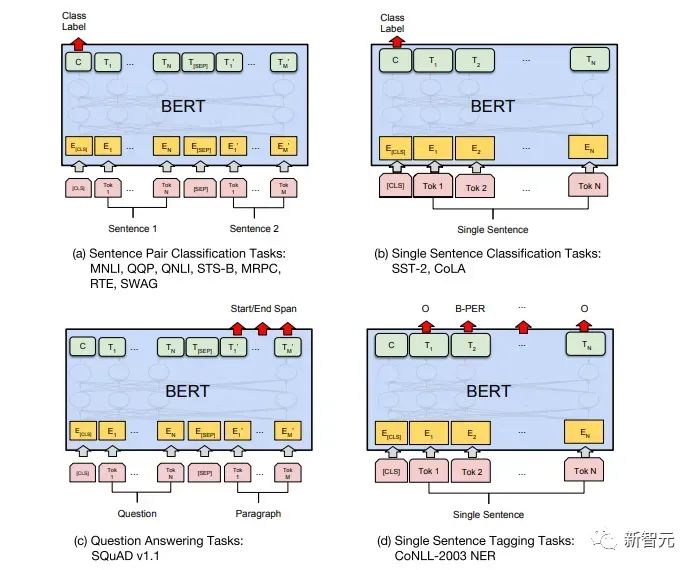
Feinabstimmungsphase BERTs Feinabstimmungsphase unterscheidet sich nicht wesentlich von GPT. Aufgrund der Verwendung eines Zwei-Wege-Transformers wird das von GPT in der Feinabstimmungsphase verwendete Hilfstrainingsziel, das Sprachmodell, aufgegeben. Darüber hinaus wird der Ausgabevektor für die Klassifizierungsvorhersage von der Ausgabeposition des letzten Wortes von GPT zur Position von GitHub-Link: https ://github .com/google-research/bert Post Scriptum Ich persönlich glaube, dass BERT nur ein Kompromiss des GPT-Modells ist. Um in beiden Phasen gleichzeitig Satzkontextinformationen zu erhalten, wird ein bidirektionales Transformer-Modell verwendet. Dafür müssen wir jedoch den Preis zahlen, das traditionelle Sprachmodell aufzugeben und stattdessen eine komplexere Methode wie MLM + NSP für das Vortraining zu verwenden. Multitask-Modell – MT-DNN MT-DNN (Multi-Task Deep Neural Networks) verwendet immer noch die zweite Stufe von BERT Trainingsmethoden und bidirektionaler Transformator. In der Vortrainingsphase ist MT-DNN fast identisch mit BERT, in der Feinabstimmungsphase verwendet MT-DNN jedoch eine Multitasking-Feinabstimmungsmethode. Gleichzeitig wird die Kontexteinbettungsausgabe von Transformer für das Training von Aufgaben wie der Klassifizierung einzelner Sätze, der Ähnlichkeit von Textpaaren, der Klassifizierung von Textpaaren sowie von Fragen und Antworten verwendet. Die gesamte Struktur ist unten dargestellt: GitHub-Link: https://github.com/ namisan/mt-dnn GPT-2 verwendet weiterhin das Original Das von GPT verwendete Einweg-Transformer-Modell. Der Zweck dieses Artikels besteht darin, den Einweg-Transformer so weit wie möglich zu nutzen, um etwas zu tun, was der von BERT verwendete Zwei-Wege-Transformer nicht kann. Das heißt, aus dem oben Gesagten den folgenden Text zu generieren. Die Idee von GPT-2 besteht darin, den Feinabstimmungsprozess vollständig aufzugeben und stattdessen eine größere Kapazität, unbeaufsichtigtes Training und ein allgemeineres Sprachmodell zur Vervollständigung zu verwenden Verschiedene Aufgaben. Wir müssen überhaupt nicht definieren, welche Aufgaben dieses Modell erfüllen soll, da die in vielen Tags enthaltenen Informationen im Korpus vorhanden sind. Genauso wie jemand, der viele Bücher liest, auf der Grundlage des gelesenen Inhalts problemlos automatisch zusammenfassen, Fragen beantworten und mit dem Schreiben von Artikeln fortfahren kann. Streng genommen ist GPT-2 möglicherweise kein Multitasking-Modell, aber es verwendet dasselbe Modell und dieselben Parameter, um verschiedene Aufgaben zu erledigen. Normalerweise trainieren wir ein dediziertes Modell für eine bestimmte Aufgabe, wir können die entsprechende Ausgabe der Aufgabe zurückgeben, also #🎜 🎜## 🎜🎜# Was hat GPT-2 also getan, um die oben genannten Anforderungen zu erfüllen? Den Datensatz erweitern und vergrößern Das erste, was wir tun müssen, ist, das Modell gut lesbar zu machen. Wie können wir dann eine Inferenz durchführen, wenn nicht genügend Trainingsbeispiele vorhanden sind? Da sich die bisherigen Arbeiten auf ein konkretes Problem konzentrierten, waren die Datensätze relativ einseitig. GPT-2 sammelt einen größeren und umfassenderen Datensatz. Gleichzeitig müssen wir die Qualität dieses Datensatzes sicherstellen und Webseiten mit qualitativ hochwertigen Inhalten vorhalten. Schließlich wurde ein 8-Millionen-Text-40G-Datensatz WebText erstellt. Netzwerkkapazität erweitern Wenn Sie zu viele Bücher haben, müssen Sie einige bei sich tragen, sonst können Sie sich die Dinge im Buch nicht merken. Um die Kapazität des Netzwerks zu erhöhen und ihm ein stärkeres Lernpotenzial zu verleihen, erhöhte GPT-2 die Anzahl der Transformer-Stack-Schichten auf 48 Schichten, die Dimension der verborgenen Schicht betrug 1600 und die Anzahl der Parameter erreichte 1,5 Milliarden. Passen Sie die Netzwerkstruktur an GPT-2 erhöht das Vokabular auf 50257, die maximale Kontextgröße (Kontextgröße) wird von GPTs 512 auf 1024 erhöht und die Stapelgröße wird von 512 auf 1024 erhöht. Darüber hinaus wurden kleine Anpassungen am Transformer vorgenommen. Vor jedem Unterblock wurde eine Normalisierungsschicht hinzugefügt, nachdem die Initialisierungsmethode der Restschicht geändert wurde. GitHub-Link: https://github.com/openai/gpt-2 Post Scriptum Tatsächlich ist das Erstaunlichste an GPT-2 seine extrem starke Generation Diese leistungsstarken Generierungsfunktionen sind hauptsächlich auf die Datenqualität und die erstaunliche Anzahl von Parametern sowie den Datenumfang zurückzuführen. Die Anzahl der Parameter von GPT-2 ist so groß, dass das für Experimente verwendete Modell immer noch in einem unzureichenden Zustand ist. Wenn es weiter trainiert wird, kann der Effekt weiter verbessert werden. Zusammenfassend zur oben genannten Entwicklung der Transformer-Arbeit habe ich auch einige persönliche Gedanken zu den Entwicklungstrends des Deep Learning zusammengestellt: 1 Überwachte Modelle entwickeln sich in Richtung halbüberwacht oder sogar unbeaufsichtigt Die Wachstumsrate des Datenumfangs übersteigt die Geschwindigkeit der Datenkennzeichnung bei weitem, was auch zur Erzeugung einer großen Menge unbeschrifteter Daten geführt hat. Diese unbeschrifteten Daten sind nicht ohne Wert. Im Gegenteil: Wenn Sie die richtige „Alchemie“ finden, können Sie aus diesen riesigen Daten einen unerwarteten Wert ziehen. Wie diese unbeschrifteten Daten zur Verbesserung der Aufgabenleistung genutzt werden können, ist zu einem immer wichtigeren Thema geworden, das nicht ignoriert werden darf. 2. Von komplexen Modellen mit einer kleinen Datenmenge bis zu einfachen Modellen mit einer großen Datenmenge Die Anpassungsfähigkeit tiefer neuronaler Netze ist sehr leistungsfähig, und ein einfaches neuronales Netzmodell reicht aus passen zu jeder Funktion. Allerdings ist es schwierig, eine einfachere Netzwerkstruktur zur Erledigung derselben Aufgabe zu verwenden, und auch die Anforderungen an das Datenvolumen sind höher. Je mehr die Datenmenge zunimmt und sich die Qualität der Daten verbessert, desto häufiger sinken die Anforderungen an das Modell. Je größer die Datenmenge, desto einfacher ist es für das Modell, Merkmale zu erfassen, die mit realen Verteilungen übereinstimmen. Word2Vec ist ein Beispiel. Die verwendete Zielfunktion ist sehr einfach, aber da eine große Textmenge verwendet wird, enthalten die trainierten Wortvektoren viele interessante Funktionen. 3. Entwicklung von spezialisierten Modellen zu allgemeinen Modellen GPT, BERT, MT-DNN und GPT-2 verwenden alle vorab trainierte allgemeine Modelle, um nachgelagerte maschinelle Lernaufgaben fortzusetzen das Modell selbst wäre erforderlich. Wenn die Ausdrucksfähigkeit eines Modells stark genug ist und die während des Trainings verwendete Datenmenge groß genug ist, ist das Modell vielseitiger und muss für bestimmte Aufgaben nicht allzu stark modifiziert werden. Der extremste Fall ist wie bei GPT-2, das ein allgemeines Multitask-Modell trainieren kann, ohne während des Trainings überhaupt zu wissen, was die nachfolgenden Downstream-Aufgaben sind. 4. Erhöhte Anforderungen an Datenumfang und -qualität Obwohl GPT, BERT, MT-DNN und GPT-2 nacheinander die Liste angeführt haben, denke ich, dass bei der Verbesserung der Leistung die Verbesserung des Datenumfangs einen größeren Anteil ausmacht als die strukturelle Anpassung. Mit der Verallgemeinerung und Vereinfachung von Modellen wird sich zur Verbesserung der Modellleistung mehr Aufmerksamkeit von der Gestaltung komplexer und spezialisierter Modelle auf die Frage verlagern, wie eine große Anzahl von Modellen mit höchster Qualität erhalten, bereinigt und verfeinert werden kann die Daten. Der Effekt der Anpassung der Datenverarbeitungsmethode wird größer sein als der Effekt der Anpassung der Modellstruktur. Zusammengefasst wird sich der DL-Wettbewerb früher oder später zu einem Wettbewerb zwischen großen Herstellern um Ressourcen und Rechenleistung entwickeln. Innerhalb weniger Jahre könnte ein neues Thema entstehen: grüne KI, kohlenstoffarme KI, nachhaltige KI usw. 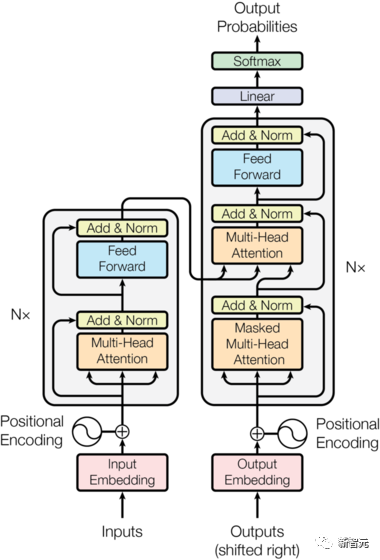
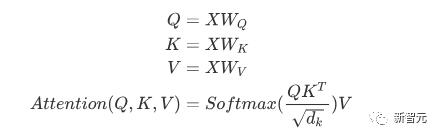
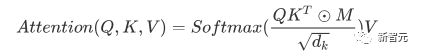
Trainingsmethode vor dem Training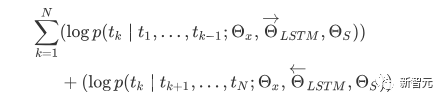
 Da ein Einweg-Transformer verwendet wird, sind nur die oben genannten Wörter zu sehen, daher lautet das Sprachmodell:
Da ein Einweg-Transformer verwendet wird, sind nur die oben genannten Wörter zu sehen, daher lautet das Sprachmodell: 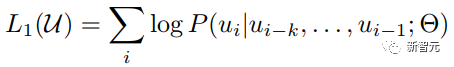
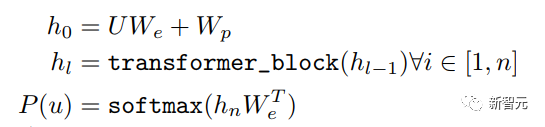
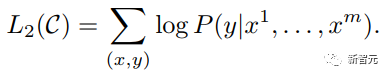
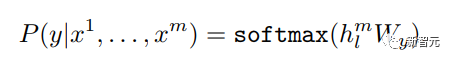
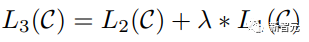
Da in GPT das Training des Sprachmodells abgeschlossen sein muss, ist ein Vortraining erforderlich, um bei der Vorhersage des nächsten Wortes nur die aktuellen und aktuellen Wörter sehen zu können Dies ist auch der Grund, warum GPT die ursprüngliche Zwei-Wege-Struktur von Transformer aufgegeben und eine Einweg-Struktur übernommen hat. 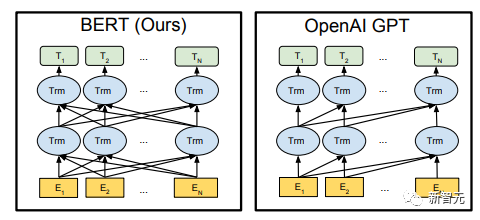
Einseitiges allgemeines Modell – – GPT-2
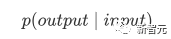
Zusammenfassung
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Transformer-Struktur und ihrer Anwendungen – GPT, BERT, MT-DNN, GPT-2. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Detaillierte Erläuterung der SQLORDSBY -Klausel: Die effiziente Sortierung der Datenreihenfolge -Klausel ist eine Schlüsselanweisung in SQL, die zur Sortierung von Abfrageergebnissen verwendet wird. Es kann in einzelnen Spalten oder mehreren Spalten in den Aufstieg (ASC) oder absteigender Reihenfolge (Desc) angeordnet werden, wodurch die Datenlesbarkeit und die Effizienz der Datenverwaltung erheblich verbessert werden. OrderBy syntax SelectColumn1, Spalte2, ... fromTable_NameOrDByColumn_Name [ASC | Desc]; Column_Name: Sortieren nach Spalte. ASC: Ascending Order Sort (Standard). Desc: Sortieren Sie in absteigender Reihenfolge. OrderBy Hauptmerkmale: Multi-Sortier-Sortierung: Unterstützt mehrere Spaltensortierungen, und die Reihenfolge der Spalten bestimmt die Priorität der Sortierung. seit
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
 So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
Mit der SQL -Insert -Anweisung wird eine Datenbanktabelle neue Zeilen hinzufügen, und ihre Syntax ist: Intable_Name (Spalte1, Spalte2, ..., Columnn) Werte (Value1, Value2, ..., Valuen);. Diese Anweisung unterstützt das Einfügen mehrerer Werte und ermöglicht es, Nullwerte in Spalten eingefügt zu werden. Es ist jedoch erforderlich, sicherzustellen, dass die eingefügten Werte mit dem Datentyp der Spalte kompatibel sind, um zu vermeiden, dass Einzigartigkeitsbeschränkungen verstoßen.
 Navicat -Verbindungs -Zeitüberschreitung: So lösen Sie sich
Apr 08, 2025 pm 11:03 PM
Navicat -Verbindungs -Zeitüberschreitung: So lösen Sie sich
Apr 08, 2025 pm 11:03 PM
Gründe für die Navicat -Verbindungszeitüberschreitung: Netzwerkinstabilität, geschäftige Datenbank, Firewall -Blockierung, Serverkonfigurationsprobleme und unsachgemäße Navicat -Einstellungen. Lösungsschritte: Überprüfen Sie die Netzwerkverbindung, den Datenbankstatus, die Firewall -Einstellungen, die Serverkonfiguration, prüfen Sie die Navicat -Einstellungen, starten Sie die Software und den Server neu und wenden Sie sich an den Administrator, um Hilfe zu erhalten.
 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
 Wie kann ich das Datenbankkennwort in Navicat für MongoDB anzeigen?
Apr 08, 2025 pm 09:21 PM
Wie kann ich das Datenbankkennwort in Navicat für MongoDB anzeigen?
Apr 08, 2025 pm 09:21 PM
Navicat für MongoDB kann das Datenbankkennwort nicht anzeigen, da das Passwort verschlüsselt ist und nur Verbindungsinformationen enthält. Das Abrufen von Kennwörtern erfordert MongoDB selbst, und der spezifische Betrieb hängt von der Bereitstellungsmethode ab. Sicherheit zuerst, entwickeln Sie gute Kennwortgewohnheiten und versuchen Sie niemals, Passwörter von Tools von Drittanbietern zu erhalten, um Sicherheitsrisiken zu vermeiden.
