
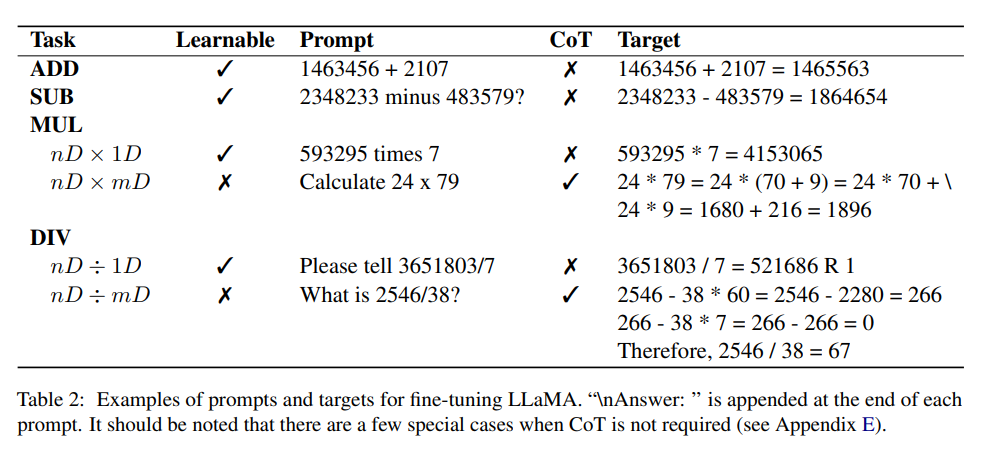
 Technologie-Peripheriegeräte
KI
Die Rechenfähigkeit liegt nahezu perfekt! Die National University of Singapore veröffentlicht Goat, das GPT-4 mit nur 7 Milliarden Parametern tötet und zunächst 16-stellige Multiplikation und Division unterstützt.
Technologie-Peripheriegeräte
KI
Die Rechenfähigkeit liegt nahezu perfekt! Die National University of Singapore veröffentlicht Goat, das GPT-4 mit nur 7 Milliarden Parametern tötet und zunächst 16-stellige Multiplikation und Division unterstützt.
Die Rechenfähigkeit liegt nahezu perfekt! Die National University of Singapore veröffentlicht Goat, das GPT-4 mit nur 7 Milliarden Parametern tötet und zunächst 16-stellige Multiplikation und Division unterstützt.

Obwohl groß angelegte Sprachmodelle bei verschiedenen Aufgaben zur Verarbeitung natürlicher Sprache eine überlegene Leistung gezeigt haben, stellen arithmetische Fragen immer noch eine große Schwierigkeit dar, selbst in den derzeit schwierigsten Situationen Das leistungsstarke GPT-4 ist auch schwierig mit grundlegenden Rechenproblemen umzugehen.
Kürzlich haben Forscher der National University of Singapore ein Rechenmodell namens Goat vorgeschlagen, das nach einer Feinabstimmung auf der Grundlage des LLaMA-Modells deutlich bessere Ergebnisse erzielte Leistung als Goat. Arithmetische Fähigkeit von GPT -4.

Papierlink: https://arxiv.org /pdf/2305.14201.pdf
Durch die Feinabstimmung des synthetischen arithmetischen Datensatzes erreicht Goat eine hochmoderne Leistung auf der BIG-Bank Arithmetische Unteraufgabe. Leistung,
Goat kann nur durch überwachte Feinabstimmung eine nahezu perfekte Genauigkeit bei Additions- und Subtraktionsoperationen mit großen Zahlen erreichen und übertrifft alle vorherigen vorab trainierten Sprachmodelle , wie Bloom, OPT, GPT-NeoX usw. Unter ihnen übersteigt die von Goat-7B mit null Proben erreichte Genauigkeit nach dem Lernen mit wenigen Schüssen sogar die von PaLM-540. Die hervorragende Leistung von Goat wird auf die konsistente Wortsegmentierung von LLaMA zurückgeführt Technologie für Zahlen.
Um anspruchsvollere Aufgaben wie die Multiplikation und Division großer Zahlen zu lösen, schlugen die Forscher außerdem eine Methode vor, um die Aufgaben anhand ihrer Lernfähigkeit in der Arithmetik zu klassifizieren und dann die Grundfunktionen zu verwenden Arithmetische Prinzipien, um nicht lernbare Aufgaben (z. B. mehrstellige Multiplikation und Division) in eine Reihe lernbarer Aufgaben zu zerlegen.
Nach umfassender experimenteller Überprüfung können die im Artikel vorgeschlagenen Zerlegungsschritte die Rechenleistung effektiv verbessern.
Und Goat-7 B kann mit LoRA auf einer 24-GB-VRAM-GPU effizient trainiert werden, andere Forscher können das Experiment, das Modell, den Datensatz und die Generierung von Python ganz einfach wiederholen Das Skript für den Datensatz wird bald Open Source sein. #🎜🎜 ## 🎜🎜 ## 🎜🎜#Sprachmodell, das#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Language Model#🎜🎜 ## 🎜🎜 ## 🎜🎜 zählen kann. #
LLaMA ist eine Reihe vorab trainierter Open-Source-Sprachmodelle, die auf Billionen von Token unter Verwendung öffentlich verfügbarer Datensätze trainiert und auf mehreren Benchmarks mit modernster Leistung implementiert werden.
Frühere Forschungsergebnisse zeigen, dass die Tokenisierung für die Rechenfähigkeit von LLM wichtig ist, aber gängige Tokenisierungstechniken können Zahlen nicht gut darstellen, da beispielsweise zu viele Ziffern aufgeteilt werden können.
LLaMA entscheidet sich dafür, die Zahl in mehrere Token aufzuteilen, um die digitale Darstellung sicherzustellen Forscher glauben, dass die in den experimentellen Ergebnissen gezeigten außergewöhnlichen Rechenfähigkeiten hauptsächlich auf die konsistente Segmentierung von Zahlen durch LLaMA zurückzuführen sind.
In Experimenten konnten andere fein abgestimmte Sprachmodelle wie Bloom, OPT, GPT-NeoX und Pythia nicht mit den Rechenfähigkeiten von LLaMA mithalten.
Erlernbarkeit von Rechenaufgaben 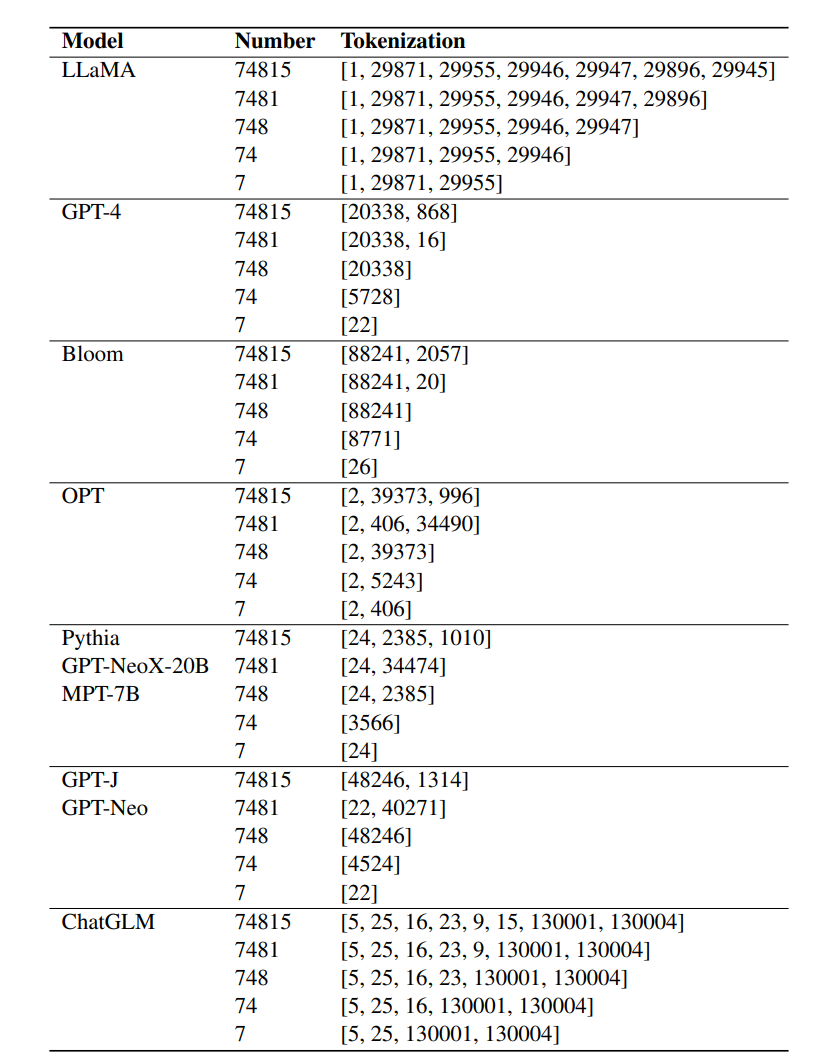
# 🎜 🎜# Zuvor führten Forscher eine theoretische Analyse der Verwendung von Zwischenüberwachung zur Lösung zusammengesetzter Aufgaben durch. Die Ergebnisse zeigten, dass diese Art von Aufgabe nicht erlernbar ist, sondern in eine polynomielle Anzahl einfacher Teilaufgaben zerlegt werden kann.
Das heißt, nicht lernbare zusammengesetzte Probleme können durch Zwischensupervision oder Schrittketten (CoT) gelernt werden.
Basierend auf dieser Analyse klassifizierten die Forscher zunächst experimentell lernbare und nicht lernbare Aufgaben. Im Kontext des arithmetischen Rechnens beziehen sich lernbare Aufgaben im Allgemeinen auf solche Aufgaben, für die ein Modell erfolgreich trainiert werden kann, um innerhalb einer vordefinierten Anzahl von Trainingsepochen direkt eine Antwort zu generieren Erreichen Sie eine ausreichend hohe Genauigkeit.
Unlernbare Aufgaben sind solche, bei denen ein Modell auch nach umfangreichem Training Schwierigkeiten hat, richtig zu lernen und direkte Antworten zu generieren.
Während die genauen Gründe für Veränderungen in der Lernfähigkeit von Aufgaben nicht vollständig geklärt sind, kann angenommen werden, dass sie mit der Komplexität des zugrunde liegenden Musters und der Größe des Arbeitsgedächtnisses zusammenhängen, das zur Erledigung der Aufgabe erforderlich ist.
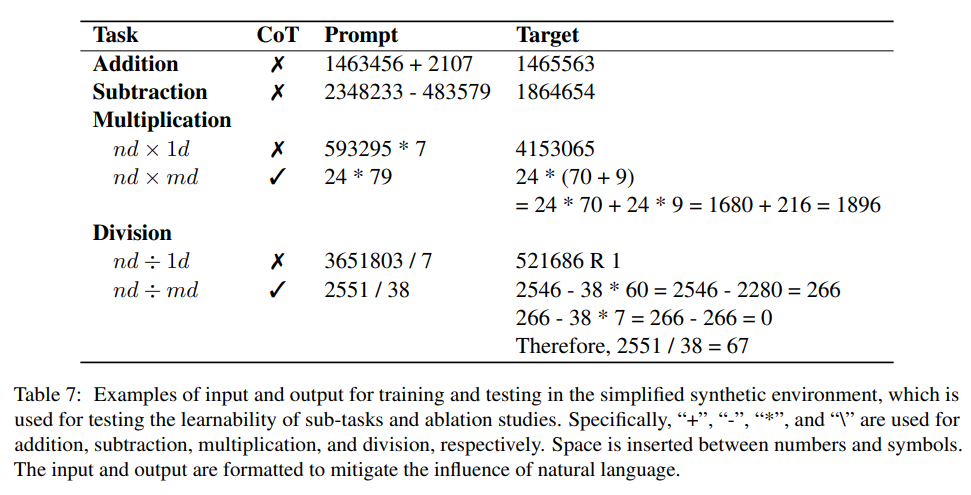
Die Forscher untersuchten experimentell die Lernbarkeit dieser Aufgaben, indem sie das Modell speziell für jede Aufgabe in einer vereinfachten synthetischen Umgebung verfeinerten.
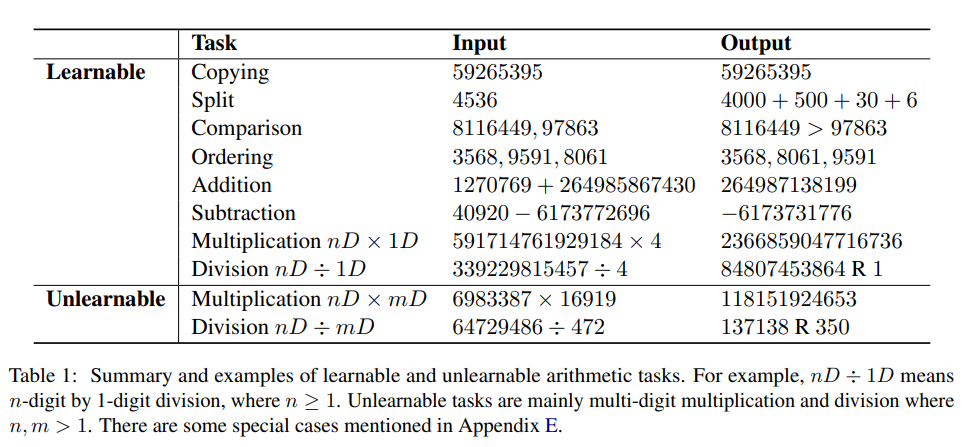
Lernbare und nicht lernbare Aufgaben
Die Ergebnisse der Aufgabenklassifizierung sind auch die gleichen wie die menschliche Wahrnehmung. Mit etwas Übung kann der Mensch die Additionssumme zweier großer Zahlen im Kopf berechnen Bei der Subtraktion können Sie die endgültige numerische Antwort direkt von links (höchstwertige Ziffer) nach rechts (niedrigstwertige Ziffer) schreiben, ohne die Berechnung von Hand durchführen zu müssen.
Aber Kopfrechnen zur Lösung der Multiplikation und Division großer Zahlen ist eine herausfordernde Aufgabe.
Es kann auch beobachtet werden, dass die oben genannten Klassifizierungsergebnisse von Aufgaben auch mit der Leistung von GPT-4 übereinstimmen, insbesondere ist GPT-4 gut darin, direkte Antworten für die Addition und Subtraktion großer Zahlen zu generieren, wenn es um Multi- Bei Ziffernmultiplikations- und Divisionsaufgaben nimmt die Genauigkeit erheblich ab.
Die Unfähigkeit eines leistungsstarken Modells wie GPT-4, nicht lernbare Aufgaben direkt zu lösen, kann auch darauf hindeuten, dass die Generierung direkter Antworten für diese Aufgaben selbst nach umfangreichem Training äußerst schwierig ist.
Es ist erwähnenswert, dass Aufgaben, die für LLaMA erlernbar sind, nicht unbedingt auch für andere LLMs erlernbar sind.
Darüber hinaus sind nicht alle als nicht lernbar eingestuften Aufgaben für das Modell völlig unmöglich zu lernen.
Zum Beispiel wird das Multiplizieren zweistelliger Zahlen mit zweistelligen Zahlen als nicht lernbare Aufgabe angesehen. Wenn der Trainingssatz jedoch alle möglichen zweistelligen Multiplikationsaufzählungsdaten enthält, kann das Modell dennoch durch Überanpassung des Trainingssatzes lernen . Generieren Sie direkt Antworten.
Allerdings benötigt der gesamte Prozess fast 10 Epochen, um eine Genauigkeit von etwa 90 % zu erreichen.
Durch Einfügen des im Artikel vorgeschlagenen CoT vor der endgültigen Antwort kann das Modell nach einer Trainingsepoche eine recht gute Genauigkeit bei der zweistelligen Multiplikation erreichen, was auch mit früheren Forschungsergebnissen, d. h. der Mitte, übereinstimmt Das Vorhandensein einer Aufsicht erleichtert den Lernprozess.
Addition und Subtraktion
Diese beiden arithmetischen Operationen sind lernbar, und allein durch überwachte Feinabstimmung hat das Modell eine außergewöhnliche Fähigkeit bewiesen, direkte numerische Antworten genau zu generieren.
Obwohl das Modell nur auf einer sehr begrenzten Teilmenge von Additionsdaten trainiert wurde, erfasst das Modell erfolgreich arithmetische Operationen, wie aus der Tatsache ersichtlich ist, dass das Modell bei einem noch nie dagewesenen Testsatz eine nahezu perfekte Genauigkeit erreichte. Der Basismodus ohne mit CoT
Multiplikation
Die Forscher haben experimentell bestätigt, dass die n-stellige Multiplikation mit der 1-stelligen Multiplikation erlernbar ist, während die mehrstellige Multiplikation nicht erlernt werden kann.
Um dieses Problem zu lösen, entschieden sich die Forscher für eine Feinabstimmung des LLM, um CoT vor der Generierung der Antwort zu generieren, und zerlegten die mehrstellige Multiplikation in 5 lernbare Unteraufgaben:
1. Extraktion, Extrahieren arithmetischer Ausdrücke aus natürlicher Sprache Anleitung
2. Teilen Sie den kleineren der beiden in Ortswerte auf
3. Erweiterung, basierend auf Verteilungserweiterung und Summierung
4. Berechnen Sie jedes Produkt gleichzeitig
5. Fügen Sie die beiden vorherigen Terme hinzu Holen Sie sich die Endsumme

Jede dieser Aufgaben ist lernbar.
Division
In ähnlicher Weise kann experimentell beobachtet werden, dass das Teilen von n-stelligen Zahlen durch eine 1-stellige Zahl lernbar ist, während die mehrstellige Division nicht lernbar ist.
Forscher haben eine neue Eingabeaufforderung für die Denkkette entworfen, die die Rekursionsgleichung der verbesserten langsamen Division verwendet.
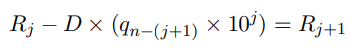
Die Hauptidee besteht darin, Vielfache des Divisors von der Dividende zu subtrahieren, bis der Rest kleiner als der Divisor ist.
Datensatz
Das im Artikel entworfene Experiment ist die Addition und Subtraktion zweier positiver Ganzzahlen, und das Ergebnis der Subtraktionsoperation kann sein eine negative Zahl.
Um die maximal erzeugte Sequenzlänge zu begrenzen, ist das Ergebnis der Multiplikation eine positive ganze Zahl innerhalb von 12 Stellen; bei der Division zweier positiver ganzer Zahlen beträgt der Dividend weniger als 12 Stellen und der Quotient liegt innerhalb von 6 Stellen.
Die Forscher verwendeten ein Python-Skript, um einen Datensatz zu synthetisieren und etwa 1 Million Frage-Antwort-Paare zu generieren. Die Antworten enthalten den vorgeschlagenen CoT und die endgültige numerische Ausgabe. Alle Zahlen werden zufällig generiert, was die Wahrscheinlichkeit einer Wiederholung gewährleistet Die Anzahl der Instanzen ist sehr niedrig, aber kleine Zahlen können mehrfach abgetastet werden.
Feinabstimmung
Um das Modell in die Lage zu versetzen, arithmetische Probleme auf der Grundlage von Anweisungen zu lösen und die Beantwortung von Fragen in natürlicher Sprache zu erleichtern, verwendeten die Forscher ChatGPT, um Hunderte von Anweisungsvorlagen zu generieren.
Während des Anweisungsoptimierungsprozesses wird für jede arithmetische Eingabe aus dem Trainingssatz eine Vorlage zufällig ausgewählt und LLaMA-7B feinabgestimmt, ähnlich der in Alpaca verwendeten Methode.

Goat-7B kann mit LoRA auf einer 24-GB-VRAM-GPU feinabgestimmt werden. Die Durchführung von 100.000 Samples auf einer A100-GPU dauert nur etwa 1,5 Stunden und erreicht eine nahezu perfekte Genauigkeit.
Experimentelle Ergebnisse
Es erscheint unfair, die Leistung von Goat und GPT-4 im Hinblick auf eine große Anzahl von Multiplikationen und Divisionen zu vergleichen, da GPT-4 Antworten direkt generiert, während Goat sich auf eine entworfene Denkkette verlässt GPT-4 Während der Evaluierung wurde am Ende jeder Eingabeaufforderung auch „Lösen Sie es Schritt für Schritt“ hinzugefügt
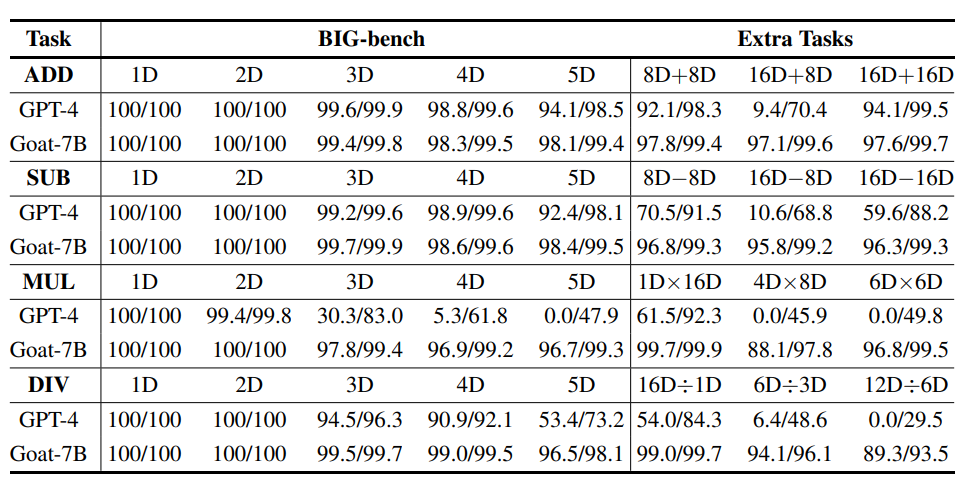
Es kann jedoch beobachtet werden, dass GPT-4 in einigen Fällen die Zwischenschritte umfasst Die lange Multiplikation und Division ist falsch, aber die endgültige Antwort ist immer noch richtig, was bedeutet, dass GPT-4 die Zwischenüberwachung der Denkkette nicht verwendet, um die endgültige Ausgabe zu verbessern.
Die folgenden drei häufigen Fehler wurden schließlich anhand der GPT-4-Lösung identifiziert:
1. Ausrichtung entsprechender Zahlen
2. Wiederholte Zahlen 16D-Aufgaben Die Leistung ist recht gut, aber die Berechnungsergebnisse sind bei den meisten 16D+8D-Aufgaben falsch, obwohl 16D+8D intuitiv relativ einfacher sein sollte als 16D+16D.Während die genaue Ursache hierfür unbekannt ist, könnte ein möglicher Faktor der inkonsistente Ziffernsegmentierungsprozess von GPT-4 sein, der die Zuordnung zwischen den beiden Ziffern erschwert.
Das obige ist der detaillierte Inhalt vonDie Rechenfähigkeit liegt nahezu perfekt! Die National University of Singapore veröffentlicht Goat, das GPT-4 mit nur 7 Milliarden Parametern tötet und zunächst 16-stellige Multiplikation und Division unterstützt.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
