
 Technologie-Peripheriegeräte
KI
Wenn LLM auf Datenbank trifft: Alibaba DAMO Academy und HKU starten einen neuen Text-to-SQL-Benchmark
Technologie-Peripheriegeräte
KI
Wenn LLM auf Datenbank trifft: Alibaba DAMO Academy und HKU starten einen neuen Text-to-SQL-Benchmark
Wenn LLM auf Datenbank trifft: Alibaba DAMO Academy und HKU starten einen neuen Text-to-SQL-Benchmark

Hintergrund
Das Large Model (LLM) bietet eine neue Richtung für die Entwicklung der künstlichen allgemeinen Intelligenz (AGI). Es führt groß angelegte selbstüberwachte Schulungen mithilfe umfangreicher öffentlicher Daten wie dem Internet, Büchern und anderen Korpora durch Erwirbt ein leistungsfähiges Sprachverständnis, Sprachproduktion, Argumentation und andere Fähigkeiten. Allerdings stehen große Modelle bei der Nutzung privater Domänendaten immer noch vor einigen Herausforderungen. Private Domänendaten beziehen sich auf Daten, die bestimmten Unternehmen oder Einzelpersonen gehören und in der Regel domänenspezifisches Wissen enthalten. Die Kombination großer Modelle mit privatem Domänenwissen bietet großen Wert.
Privates Domänenwissen kann hinsichtlich der Datenform in unstrukturierte und strukturierte Daten unterteilt werden. Unstrukturierte Daten wie Dokumente werden in der Regel durch Retrieval erweitert und Tools wie Langchain können zur schnellen Implementierung eines Frage- und Antwortsystems verwendet werden. Strukturierte Daten wie Datenbanken (DB) erfordern große Modelle, die mit der Datenbank interagieren, Abfragen und Analysen durchführen, um nützliche Informationen zu erhalten. In jüngster Zeit wurde eine Reihe von Produkten und Anwendungen rund um große Modelle und Datenbanken entwickelt, beispielsweise die Verwendung von LLM zur Erstellung intelligenter Datenbanken, zur Durchführung von BI-Analysen und zur vollständigen automatischen Tabellenerstellung. Unter ihnen war die Text-to-SQL-Technologie, die in natürlicher Sprache mit der Datenbank interagiert, schon immer eine mit Spannung erwartete Richtung.
Im akademischen Bereich konzentrierten sich frühere Text-to-SQL-Benchmarks nur auf kleine Datenbanken. Das fortschrittlichste LLM kann bereits eine Ausführungsgenauigkeit von 85,3 % erreichen, bedeutet aber, dass LLM bereits als natürliche Sprache verwendet werden kann Schnittstelle für die Datenbank?
Datensatz der neuen Generation
Kürzlich hat Alibaba zusammen mit der Universität von Hongkong und anderen Institutionen einen neuen Benchmark-BIRD (Kann LLM bereits als Datenbankschnittstelle dienen? Eine BIg Bench für Large-Scale Database Grounded Text) eingeführt ) für große reale Datenbanken (zu-SQLs), einschließlich 95 großer Datenbanken und hochwertiger Text-SQL-Paare, mit einer Datenspeicherkapazität von bis zu 33,4 GB. Das bisher beste Modell erreichte bei BIRD nur eine Bewertung von 40,08 %, was immer noch weit vom menschlichen Ergebnis von 92,96 % entfernt ist, was beweist, dass es immer noch Herausforderungen gibt. Zusätzlich zur Bewertung der Richtigkeit von SQL fügte der Autor auch eine Bewertung der SQL-Ausführungseffizienz hinzu, in der Hoffnung, dass das Modell nicht nur korrektes SQL, sondern auch effizientes SQL schreiben kann.

Papier: https://arxiv.org/abs/2305.03111
Homepage: https://bird-bench.github.io
Code: https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/bird

Derzeit sind die Daten, der Code und die Rankings von BIRD Open Source, und die Anzahl der Downloads weltweit ist ebenfalls Open Source 10000 überschritten. BIRD hat seit seiner Einführung auf Twitter große Aufmerksamkeit und Diskussionen hervorgerufen.


Auch die Kommentare von Nutzern aus Übersee sind sehr spannend:

Ein LLM-Projekt, das man sich nicht entgehen lassen sollte

sehr nützliche Kontrollpunkte, Brutstätten der Verbesserung
Methodenübersicht Neue Herausforderungen
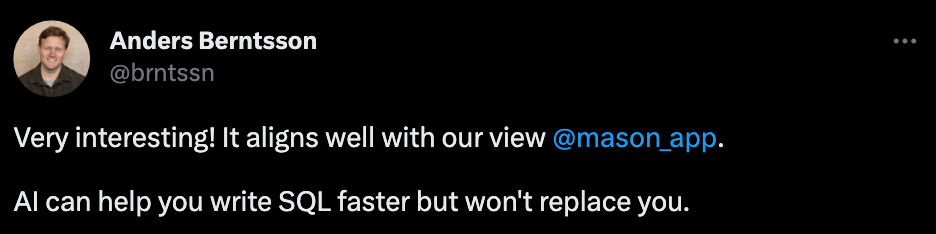
Diese Forschung konzentriert sich hauptsächlich auf die Text-to-SQL-Bewertung realer Datenbanken wie Spider und WikiSQL und konzentrierte sich nur auf Datenbankschemata mit einer geringen Menge an Datenbankinhalte, die zu akademischer Forschung und tatsächlichen Anwendungen führen. Es besteht eine Lücke. BIRD konzentriert sich auf drei neue Herausforderungen: massive und reale Datenbankinhalte, externe Wissensbegründung zwischen Fragen in natürlicher Sprache und Datenbankinhalten sowie die Effizienz von SQL bei der Verarbeitung großer Datenbanken. 
Zuallererst enthält die Datenbank riesige und verrauschte Datenwerte. Im Beispiel links muss das Durchschnittsgehalt berechnet werden, indem die Zeichenfolge in der Datenbank in einen Gleitkommawert (Float) umgewandelt und anschließend die Aggregationsberechnung (Aggregation) durchgeführt wird. Zweitens ist eine externe Wissensinferenz erforderlich Im mittleren Beispiel muss das Modell zunächst wissen, dass der für den Kredit in Frage kommende Kontotyp „EIGENTÜMER“ („EIGENTÜMER“) sein muss, um die Antwort genau an den Benutzer zurückzugeben, was das Geheimnis darstellt, das sich hinter der riesigen Datenbank verbirgt Manchmal ist es notwendig, externes Wissen und Argumentation offenzulegen. Abschließend muss die Effizienz der Abfrageausführung berücksichtigt werden. Im Beispiel rechts kann die Verwendung effizienterer SQL-Abfragen die Geschwindigkeit erheblich verbessern, was für die Branche von großem Wert ist, da Benutzer nicht nur erwarten, korrektes SQL zu schreiben, sondern auch eine effiziente SQL-Ausführung erwarten, insbesondere in großen Datenbanken ;
Datenannotation
BIRD entkoppelt Fragengenerierung und SQL-Annotation während des Annotationsprozesses. Gleichzeitig werden Experten hinzugezogen, die Datenbankbeschreibungsdateien schreiben, um dem Problem- und SQL-Annotationspersonal ein besseres Verständnis der Datenbank zu ermöglichen.
 1. Datenbanksammlung: Der Autor hat 80 Datenbanken von Open-Source-Datenplattformen wie Kaggle und CTU Prague Relational Learning Repository gesammelt und verarbeitet. Fünfzehn Datenbanken wurden manuell als Black-Box-Tests erstellt, indem reale Tabellendaten gesammelt, ER-Diagramme erstellt und Datenbankbeschränkungen festgelegt wurden, um zu verhindern, dass die aktuelle Datenbank vom aktuellen großen Modell gelernt wird. Die Datenbank von BIRD enthält Muster und Werte in mehreren Feldern, 37 Feldern, die Blockchain, Sport, medizinische Versorgung, Spiele usw. abdecken.
1. Datenbanksammlung: Der Autor hat 80 Datenbanken von Open-Source-Datenplattformen wie Kaggle und CTU Prague Relational Learning Repository gesammelt und verarbeitet. Fünfzehn Datenbanken wurden manuell als Black-Box-Tests erstellt, indem reale Tabellendaten gesammelt, ER-Diagramme erstellt und Datenbankbeschränkungen festgelegt wurden, um zu verhindern, dass die aktuelle Datenbank vom aktuellen großen Modell gelernt wird. Die Datenbank von BIRD enthält Muster und Werte in mehreren Feldern, 37 Feldern, die Blockchain, Sport, medizinische Versorgung, Spiele usw. abdecken.
2. Problemsammlung: Zunächst beauftragt der Autor Experten, eine Beschreibungsdatei für die Datenbank zu schreiben. Die Beschreibungsdatei enthält vollständige Spaltennamen, Beschreibungen von Datenbankwerten und externes Wissen, das zum Verständnis der Werte verwendet wird. Anschließend wurden 11 Muttersprachler aus den USA, dem Vereinigten Königreich, Kanada, Singapur und anderen Ländern rekrutiert, um Fragen für BIRD zu generieren. Jeder Redner hat mindestens einen Bachelor-Abschluss oder höher.
3. SQL-Generierung: Ein globales Annotationsteam bestehend aus Dateningenieuren und Datenbankkursteilnehmern wurde rekrutiert, um SQL für BIRD zu generieren. Bei einer Datenbank und einer Referenzdatenbankbeschreibungsdatei muss der Annotator SQL generieren, um die Frage korrekt zu beantworten. Es wird die Double-Blind-Annotationsmethode übernommen, bei der zwei Annotatoren dieselbe Frage kommentieren müssen. Durch die doppelblinde Annotation können Fehler minimiert werden, die durch einen einzelnen Annotator verursacht werden.
4. Qualitätsprüfung: Die Qualitätsprüfung gliedert sich in zwei Teile: Wirksamkeit und Konsistenz der Ergebnisausführung. Die Gültigkeit erfordert nicht nur die Richtigkeit der Ausführung, sondern auch, dass das Ausführungsergebnis nicht null (NULL) sein darf. Experten werden die Problembedingungen schrittweise ändern, bis die SQL-Ausführungsergebnisse gültig sind.
5. Schwierigkeitsteilung: Der Schwierigkeitsindex von Text-to-SQL kann Forschern eine Referenz für die Optimierung von Algorithmen liefern. Die Schwierigkeit von Text-to-SQL hängt nicht nur von der Komplexität des SQL ab, sondern auch von Faktoren wie Problemschwierigkeit, einfacher Verständlichkeit mit zusätzlichem Wissen und Datenbankkomplexität. Die Autoren baten daher SQL-Annotatoren, die Schwierigkeit während des Annotationsprozesses zu bewerten und teilten die Schwierigkeit in drei Kategorien ein: leicht, mittel und anspruchsvoll.
Datenstatistik
1. Fragentypstatistiken: Fragen sind in zwei Kategorien unterteilt: Grundlegender Typ und Begründungstyp. Zu den grundlegenden Fragetypen gehören diejenigen, die in herkömmlichen Text-to-SQL-Datensätzen behandelt werden, während Inferenzfragetypen Fragen umfassen, die externes Wissen erfordern, um die Werte zu verstehen:
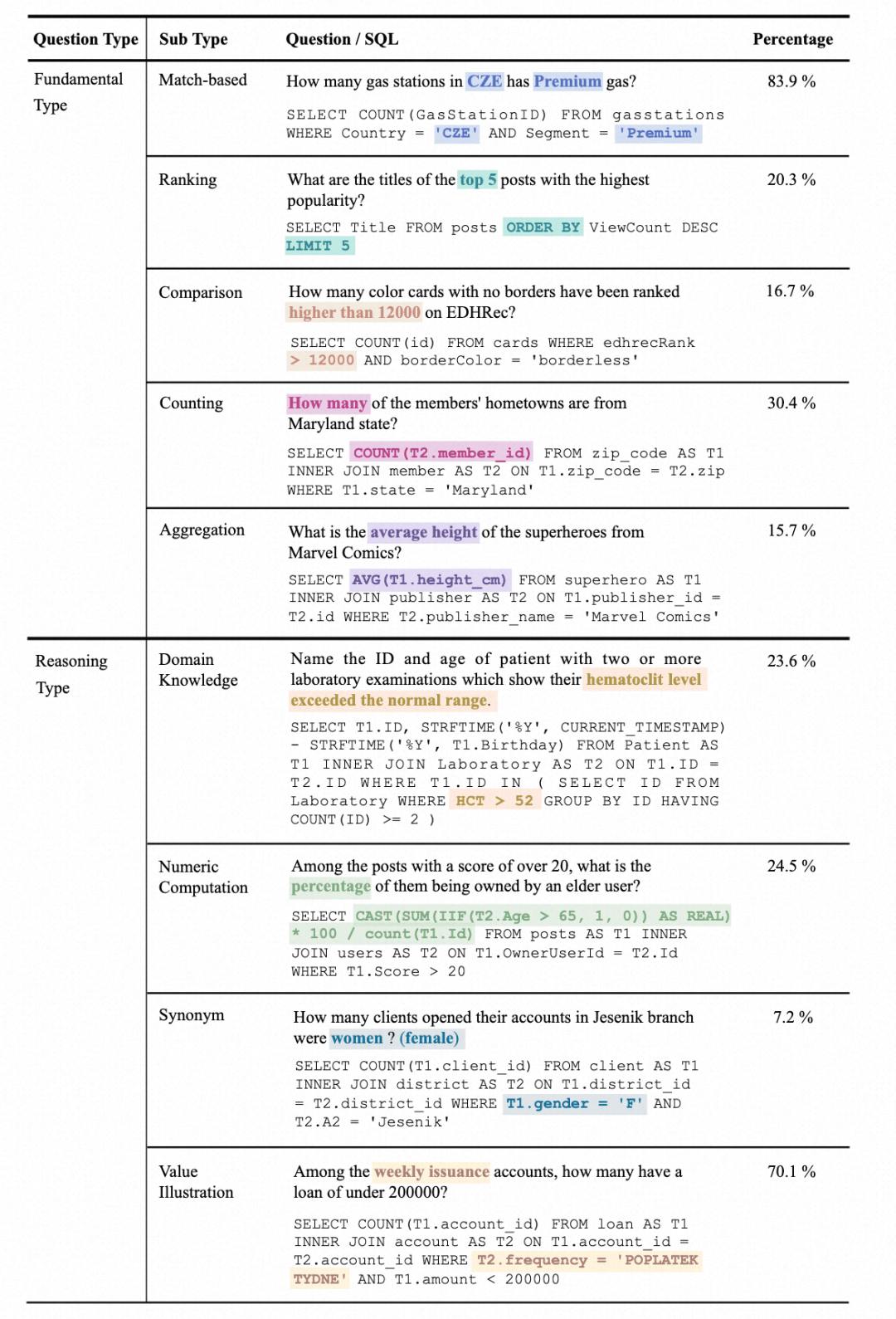
2. Datenbankverteilung: Der Autor verwendet Sunburst-Graph Zeigt die Beziehung zwischen der Datenbankdomäne und ihrer Datengröße. Ein größerer Radius bedeutet, dass mehr Text-SQL auf dieser Datenbank basiert und umgekehrt. Je dunkler die Farbe, desto größer ist die Datenbankgröße. Beispielsweise ist Donor die größte Datenbank im Benchmark und belegt 4,5 GB Speicherplatz.
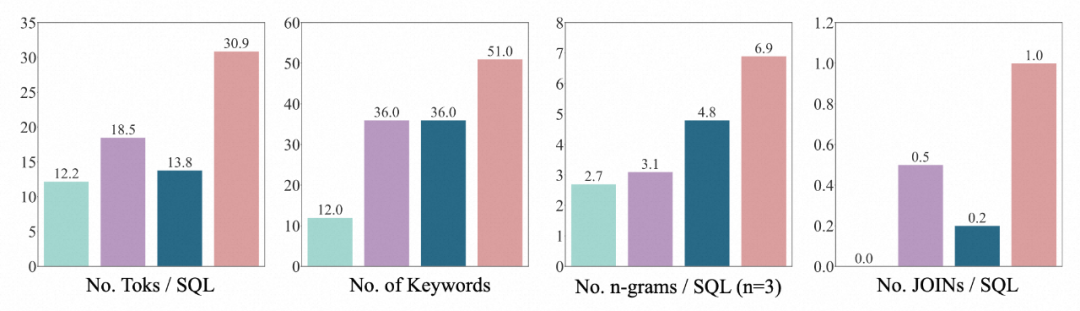
3.SQL-Verteilung: Der Autor beweist, dass BIRDs SQL bei weitem das vielfältigste und komplexeste ist, und zwar anhand von vier Dimensionen: der Anzahl der SQL-Tokens, der Anzahl der Schlüsselwörter und der Anzahl der N-Gramm-Typen und die Anzahl der JOINs.
Auswertungsindikatoren
1. Vergleichen Sie den Unterschied zwischen den vom Modell vorhergesagten SQL-Ausführungsergebnissen und den tatsächlichen annotierten SQL-Ausführungsergebnissen.
2 Punktzahl: Gleichzeitig wird unter Berücksichtigung der Genauigkeit und Effizienz von SQL der relative Unterschied zwischen der vom Modell vorhergesagten SQL-Ausführungsgeschwindigkeit und der tatsächlichen annotierten SQL-Ausführungsgeschwindigkeit verglichen und die Laufzeit als Hauptindikator für die Effizienz angesehen.
Experimentelle Analyse
Der Autor hat das T5-Modell im Trainingsstil und das Large Language Model (LLM) als Basismodelle ausgewählt, die in früheren Benchmark-Tests eine hervorragende Leistung erbracht haben: Codex (code-davinci-002) und ChatGPT (gpt-3,5-turbo). Um besser zu verstehen, ob mehrstufiges Denken die Argumentationsfähigkeiten großer Sprachmodelle in realen Datenbankumgebungen stimulieren kann, wird auch deren Chain-of-Thought-Version bereitgestellt. Und testen Sie das Basismodell in zwei Einstellungen: Eine ist die vollständige Eingabe von Schemainformationen und die andere ist das menschliche Verständnis der an dem Problem beteiligten Datenbankwerte, zusammengefasst in einer Beschreibung in natürlicher Sprache (Wissensnachweise), um das Modell beim Verständnis der Datenbank zu unterstützen .
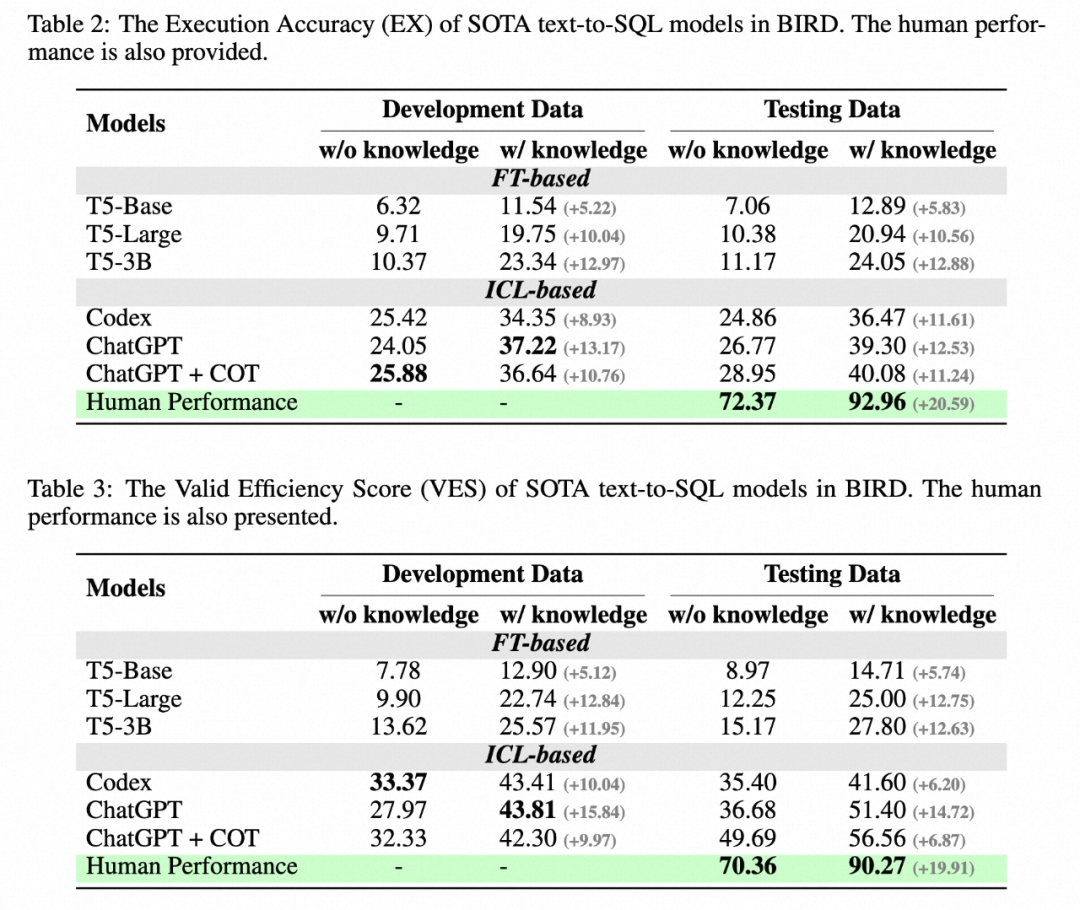
Der Autor zieht einige Schlussfolgerungen:
1. Gewinnung zusätzlicher Erkenntnisse: Die Verbesserung des Wissensnachweises für das Verständnis von Datenbankwerten hat offensichtliche Auswirkungen, was beweist, dass dies in realen Datenbanken der Fall ist Es reicht nicht aus, sich ausschließlich auf semantische Analysefunktionen zu verlassen. Das Verständnis der Datenbankwerte hilft Benutzern, genauere Antworten zu finden.
2. Die Gedankenverkettung ist nicht unbedingt von Vorteil: Wenn das Modell keine gegebene Datenbankwertbeschreibung und keinen Nullschuss hat, kann die COT-Inferenz des Modells genauere Antworten generieren. Als jedoch zusätzliches Wissen (Wissensbeweis) zur Verfügung gestellt wurde, wurde LLM gebeten, eine COT durchzuführen und stellte fest, dass der Effekt nicht signifikant war oder sogar nachließ. Daher kann LLM in diesem Szenario zu Wissenskonflikten führen. Wie dieser Konflikt gelöst werden kann, sodass das Modell sowohl externes Wissen akzeptieren als auch von seinem eigenen leistungsstarken mehrstufigen Denken profitieren kann, wird eine wichtige Forschungsrichtung der Zukunft sein.
3. Die Lücke zum Menschen: BIRD stellt auch menschliche Indikatoren bereit. Der Autor testet die Leistung des Annotators zum ersten Mal und verwendet sie als Grundlage für menschliche Indikatoren. Experimente haben ergeben, dass das derzeit beste LLM immer noch weit hinter dem Menschen zurückbleibt, was beweist, dass es immer noch Herausforderungen gibt. Die Autoren führten eine detaillierte Fehleranalyse durch und gaben einige mögliche Hinweise für zukünftige Forschungen.

Fazit
Die Anwendung von LLM im Datenbankbereich bietet Benutzern eine intelligentere und bequemere Datenbankinteraktionserfahrung. Das Aufkommen von BIRD wird die intelligente Entwicklung der Interaktion zwischen natürlicher Sprache und realen Datenbanken fördern, Raum für Fortschritte in der Text-to-SQL-Technologie für reale Datenbankszenarien schaffen und Forschern dabei helfen, fortschrittlichere und praktischere Datenbankanwendungen zu entwickeln.
Das obige ist der detaillierte Inhalt vonWenn LLM auf Datenbank trifft: Alibaba DAMO Academy und HKU starten einen neuen Text-to-SQL-Benchmark. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
