
 Technologie-Peripheriegeräte
KI
OpenAI dominiert die Top 2! Die Rangliste der großen Modellcode-Generierung wird veröffentlicht, wobei 7 Milliarden LLaMA diese übertreffen und von 250 Millionen Codex übertroffen werden.
Technologie-Peripheriegeräte
KI
OpenAI dominiert die Top 2! Die Rangliste der großen Modellcode-Generierung wird veröffentlicht, wobei 7 Milliarden LLaMA diese übertreffen und von 250 Millionen Codex übertroffen werden.
OpenAI dominiert die Top 2! Die Rangliste der großen Modellcode-Generierung wird veröffentlicht, wobei 7 Milliarden LLaMA diese übertreffen und von 250 Millionen Codex übertroffen werden.

Kürzlich löste ein Tweet von Matthias Plappert eine breite Diskussion im LLMs-Kreis aus.
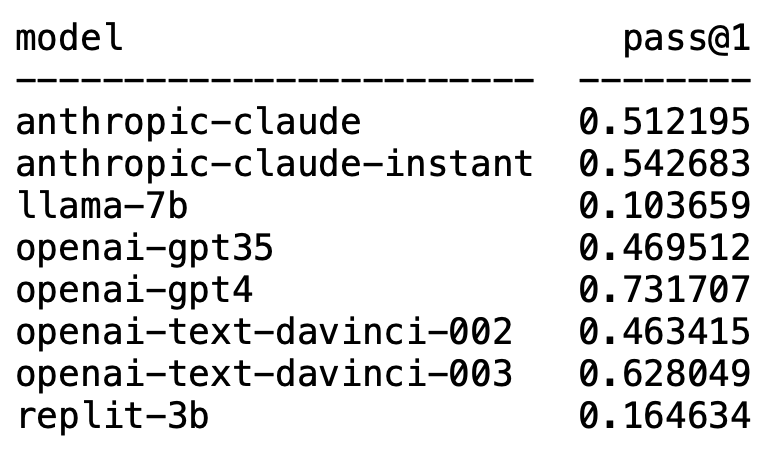
Plappert ist ein bekannter Informatiker. Er hat seine Benchmark-Testergebnisse zum Mainstream-LLM im AI-Circle auf HumanEval veröffentlicht.
Seine Tests sind auf die Codegenerierung ausgerichtet.
Die Ergebnisse sind schockierend und schockierend zugleich.

Unerwartet dominiert GPT-4 zweifellos die Liste und belegt den ersten Platz.
Unerwartet tauchte plötzlich text-davinci-003 von OpenAI auf und belegte den zweiten Platz.
Plappert sagte, dass text-davinci-003 als „Schatz“-Modell bezeichnet werden kann.
Das bekannte LLaMA ist nicht gut in der Codegenerierung.
OpenAI dominiert die Liste
Plappert sagte, dass die Leistung von GPT-4 sogar besser ist als die Daten in der Literatur.
Die Ein-Runden-Testdaten von GPT-4 in der Arbeit besagen eine Erfolgsquote von 67 %, während Plapperts Test 73 % erreichte.

Bei der Analyse der Ursachen sagte er, dass es viele Möglichkeiten für Unterschiede in den Daten gebe. Einer davon ist, dass die Eingabeaufforderung, die er GPT-4 gab, etwas besser war als zu dem Zeitpunkt, als der Autor des Artikels es testete.
Ein weiterer Grund ist, dass er vermutete, dass die Temperatur des Modells nicht 0 war, als das Papier GPT-4 testete.
„Temperatur“ ist ein Parameter, der verwendet wird, um die Kreativität und Vielfalt des Modells bei der Textgenerierung anzupassen. „Temperatur“ ist ein Wert größer als 0, normalerweise zwischen 0 und 1. Es beeinflusst die Wahrscheinlichkeitsverteilung der abgetasteten vorhergesagten Wörter, wenn das Modell Text generiert.
Wenn die „Temperatur“ des Modells höher ist (z. B. 0,8, 1 oder höher), ist das Modell eher geneigt, aus vielfältigeren und unterschiedlicheren Wörtern auszuwählen, was den generierten Text riskanter und kreativer macht , sondern führt wahrscheinlich auch zu mehr Fehlern und Inkonsistenzen.
Und wenn die „Temperatur“ niedrig ist (z. B. 0,2, 0,3 usw.), wählt das Modell hauptsächlich Wörter mit höherer Wahrscheinlichkeit aus, was zu einem glatteren und kohärenteren Text führt.
Aber an dieser Stelle erscheint der generierte Text möglicherweise zu konservativ und eintönig.
Bei tatsächlichen Anwendungen ist es also notwendig, den geeigneten „Temperatur“-Wert entsprechend den spezifischen Anforderungen abzuwägen und auszuwählen.
Als nächstes sagte Plappert in seinem Kommentar zu text-davinci-003, dass dies auch ein sehr leistungsfähiges Modell unter OpenAI sei.
Obwohl es nicht so gut ist wie GPT-4, belegt es mit einer Erfolgsquote von 62 % in einer Testrunde immer noch den klaren zweiten Platz.
Plappert betonte, dass das Beste an text-davinci-003 darin besteht, dass Benutzer nicht die API von ChatGPT verwenden müssen. Das bedeutet, dass es einfacher sein kann, Eingabeaufforderungen zu geben.
Darüber hinaus gab Plappert auch dem Claude-Instant-Modell von Anthropic AI eine relativ hohe Bewertung.
Er findet die Leistung dieses Modells gut und kann GPT-3.5 schlagen. Die Erfolgsquote von GPT-3.5 beträgt 46 %, während die Erfolgsquote von Claude-Instant 54 % beträgt.
Natürlich kann der andere LLM von Anthropic AI, Claude, nicht von Claude-Instant gespielt werden, und die Erfolgsquote beträgt nur 51 %.
Plappert sagte, dass die Eingabeaufforderungen zum Testen der beiden Modelle gleich seien: Wenn es nicht funktioniert, funktioniert es nicht.
Zusätzlich zu diesen bekannten Modellen hat Plappert auch viele kleine Open-Source-Modelle getestet.
Plappert sagte, dass es gut sei, dass er diese Modelle vor Ort betreiben kann.
Vom Maßstab her sind diese Modelle jedoch offensichtlich nicht so groß wie die von OpenAI und Anthropic AI, sodass ein Vergleich etwas überwältigend ist.

LLaMA-Codegenerierung? Natürlich war Plappert mit den LLaMA-Testergebnissen nicht zufrieden.
Den Testergebnissen nach zu urteilen, schneidet LLaMA bei der Codegenerierung sehr schlecht ab. Wahrscheinlich, weil sie beim Sammeln von Daten von GitHub eine Unterabtastung verwendet haben.
 Selbst im Vergleich zu Codex 2.5B ist die Leistung von LLaMA nicht die gleiche. (Erfolgsquote 10 % vs. 22 %)
Selbst im Vergleich zu Codex 2.5B ist die Leistung von LLaMA nicht die gleiche. (Erfolgsquote 10 % vs. 22 %)
 Schließlich testete er das 3B-Modell von Replit.
Schließlich testete er das 3B-Modell von Replit.
Er sagte, dass die Leistung nicht schlecht sei, aber im Vergleich zu den auf Twitter beworbenen Daten (Erfolgsquote 16 % gegenüber 22 %)
Plappert glaubt, dass dies daran liegen könnte, dass er dieses Modell getestet hat. Die Quantifizierungsmethode Die Erfolgsquote sank um mehrere Prozentpunkte.
 Am Ende der Rezension erwähnte Plappert einen interessanten Punkt.
Am Ende der Rezension erwähnte Plappert einen interessanten Punkt.
Ein Benutzer hat auf Twitter entdeckt, dass GPT-3.5-turbo eine bessere Leistung erbringt, wenn die Completion API der Azure-Plattform (anstelle der Chat API) verwendet wird.
Plappert glaubt, dass dieses Phänomen durchaus legitim ist, da die Eingabe von Eingabeaufforderungen über die Chat-API recht kompliziert sein kann.
Das obige ist der detaillierte Inhalt vonOpenAI dominiert die Top 2! Die Rangliste der großen Modellcode-Generierung wird veröffentlicht, wobei 7 Milliarden LLaMA diese übertreffen und von 250 Millionen Codex übertroffen werden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Remotedesktop kann die Identität des Remotecomputers nicht authentifizieren
Feb 29, 2024 pm 12:30 PM
Remotedesktop kann die Identität des Remotecomputers nicht authentifizieren
Feb 29, 2024 pm 12:30 PM
Mit dem Windows-Remotedesktopdienst können Benutzer aus der Ferne auf Computer zugreifen, was für Personen, die aus der Ferne arbeiten müssen, sehr praktisch ist. Es können jedoch Probleme auftreten, wenn Benutzer keine Verbindung zum Remotecomputer herstellen können oder Remotedesktop die Identität des Computers nicht authentifizieren kann. Dies kann durch Netzwerkverbindungsprobleme oder einen Fehler bei der Zertifikatsüberprüfung verursacht werden. In diesem Fall muss der Benutzer möglicherweise die Netzwerkverbindung überprüfen, sicherstellen, dass der Remote-Computer online ist, und versuchen, die Verbindung wiederherzustellen. Außerdem ist es wichtig, sicherzustellen, dass die Authentifizierungsoptionen des Remotecomputers richtig konfiguriert sind, um das Problem zu lösen. Solche Probleme mit den Windows-Remotedesktopdiensten können normalerweise durch sorgfältiges Überprüfen und Anpassen der Einstellungen behoben werden. Aufgrund eines Zeit- oder Datumsunterschieds kann Remote Desktop die Identität des Remotecomputers nicht überprüfen. Bitte stellen Sie Ihre Berechnungen sicher
 So lösen Sie Win7-Treibercode 28
Dec 30, 2023 pm 11:55 PM
So lösen Sie Win7-Treibercode 28
Dec 30, 2023 pm 11:55 PM
Bei einigen Benutzern sind bei der Installation des Geräts Fehler aufgetreten, die den Fehlercode 28 angezeigt haben. Tatsächlich ist dies hauptsächlich auf den Treiber zurückzuführen. Wir müssen nur das Problem mit dem Win7-Treibercode 28 lösen. Schauen wir uns an, was zu tun ist . Was tun mit dem Win7-Treibercode 28? Zuerst müssen wir auf das Startmenü in der unteren linken Ecke des Bildschirms klicken. Suchen Sie dann im Popup-Menü nach der Option „Systemsteuerung“ und klicken Sie darauf. Diese Option befindet sich normalerweise am oder nahe dem unteren Rand des Menüs. Nach dem Klicken öffnet das System automatisch die Benutzeroberfläche des Bedienfelds. Im Bedienfeld können wir verschiedene Systemeinstellungen und Verwaltungsvorgänge durchführen. Dies ist der erste Schritt in der Nostalgie-Reinigungsstufe. Ich hoffe, er hilft. Dann müssen wir fortfahren und das System betreten und
 Die CSRankings National Computer Science Rankings 2024 sind veröffentlicht! CMU dominiert die Liste, MIT fällt aus den Top 5
Mar 25, 2024 pm 06:01 PM
Die CSRankings National Computer Science Rankings 2024 sind veröffentlicht! CMU dominiert die Liste, MIT fällt aus den Top 5
Mar 25, 2024 pm 06:01 PM
Die 2024CSRankings National Computer Science Major Rankings wurden gerade veröffentlicht! In diesem Jahr gehört die Carnegie Mellon University (CMU) im Ranking der besten CS-Universitäten in den Vereinigten Staaten zu den Besten des Landes und im Bereich CS, während die University of Illinois at Urbana-Champaign (UIUC) einen der besten Plätze belegt sechs Jahre in Folge den zweiten Platz belegt. Georgia Tech belegte den dritten Platz. Dann teilten sich die Stanford University, die University of California in San Diego, die University of Michigan und die University of Washington den vierten Platz weltweit. Es ist erwähnenswert, dass das Ranking des MIT zurückgegangen ist und aus den Top 5 herausgefallen ist. CSRankings ist ein globales Hochschulrankingprojekt im Bereich Informatik, das von Professor Emery Berger von der School of Computer and Information Sciences der University of Massachusetts Amherst initiiert wurde. Die Rangfolge erfolgt objektiv
 Was tun, wenn der Bluescreen-Code 0x0000001 auftritt?
Feb 23, 2024 am 08:09 AM
Was tun, wenn der Bluescreen-Code 0x0000001 auftritt?
Feb 23, 2024 am 08:09 AM
Was tun mit dem Bluescreen-Code 0x0000001? Der Bluescreen-Fehler ist ein Warnmechanismus, wenn ein Problem mit dem Computersystem oder der Hardware vorliegt. Der Code 0x0000001 weist normalerweise auf einen Hardware- oder Treiberfehler hin. Wenn Benutzer bei der Verwendung ihres Computers plötzlich auf einen Bluescreen-Fehler stoßen, geraten sie möglicherweise in Panik und sind ratlos. Glücklicherweise können die meisten Bluescreen-Fehler mit ein paar einfachen Schritten behoben werden. In diesem Artikel werden den Lesern einige Methoden zur Behebung des Bluescreen-Fehlercodes 0x0000001 vorgestellt. Wenn ein Bluescreen-Fehler auftritt, können wir zunächst versuchen, neu zu starten
 Das Gruppenrichtlinienobjekt kann auf diesem Computer nicht geöffnet werden
Feb 07, 2024 pm 02:00 PM
Das Gruppenrichtlinienobjekt kann auf diesem Computer nicht geöffnet werden
Feb 07, 2024 pm 02:00 PM
Gelegentlich kann es bei der Verwendung eines Computers zu Fehlfunktionen des Betriebssystems kommen. Das Problem, auf das ich heute gestoßen bin, bestand darin, dass das System beim Zugriff auf gpedit.msc mitteilte, dass das Gruppenrichtlinienobjekt nicht geöffnet werden könne, weil möglicherweise die richtigen Berechtigungen fehlten. Das Gruppenrichtlinienobjekt auf diesem Computer konnte nicht geöffnet werden: 1. Beim Zugriff auf gpedit.msc meldet das System, dass das Gruppenrichtlinienobjekt auf diesem Computer aufgrund fehlender Berechtigungen nicht geöffnet werden kann. Details: Das System kann den angegebenen Pfad nicht finden. 2. Nachdem der Benutzer auf die Schaltfläche „Schließen“ geklickt hat, wird das folgende Fehlerfenster angezeigt. 3. Überprüfen Sie sofort die Protokolleinträge und kombinieren Sie die aufgezeichneten Informationen, um festzustellen, dass das Problem in der Datei C:\Windows\System32\GroupPolicy\Machine\registry.pol liegt
 Der Computer zeigt häufig einen Bluescreen an und der Code ist jedes Mal anders
Jan 06, 2024 pm 10:53 PM
Der Computer zeigt häufig einen Bluescreen an und der Code ist jedes Mal anders
Jan 06, 2024 pm 10:53 PM
Das Win10-System ist ein sehr hervorragendes, hochintelligentes System, das den Benutzern das beste Benutzererlebnis bieten kann. Unter normalen Umständen werden die Computer des Win10-Systems keine Probleme haben. Es ist jedoch unvermeidlich, dass bei hervorragenden Computern verschiedene Fehler auftreten. In letzter Zeit haben Freunde berichtet, dass ihre Win10-Systeme häufig auf Bluescreens stoßen! Heute stellt Ihnen der Editor Lösungen für verschiedene Codes vor, die häufige Bluescreens auf Windows 10-Computern verursachen. Lösungen für häufige Computer-Bluescreens mit jeweils unterschiedlichen Codes: Ursachen verschiedener Fehlercodes und Lösungsvorschläge 1. Ursache des Fehlers 0×000000116: Es sollte sein, dass der Grafikkartentreiber nicht kompatibel ist. Lösung: Es wird empfohlen, den Treiber des Originalherstellers zu ersetzen. 2,
 Beheben Sie den Fehlercode 0xc000007b
Feb 18, 2024 pm 07:34 PM
Beheben Sie den Fehlercode 0xc000007b
Feb 18, 2024 pm 07:34 PM
Beendigungscode 0xc000007b Bei der Verwendung Ihres Computers treten manchmal verschiedene Probleme und Fehlercodes auf. Unter ihnen ist der Beendigungscode am störendsten, insbesondere der Beendigungscode 0xc000007b. Dieser Code weist darauf hin, dass eine Anwendung nicht ordnungsgemäß gestartet werden kann, was zu Unannehmlichkeiten für den Benutzer führt. Lassen Sie uns zunächst die Bedeutung des Beendigungscodes 0xc000007b verstehen. Bei diesem Code handelt es sich um einen Fehlercode des Windows-Betriebssystems, der normalerweise auftritt, wenn eine 32-Bit-Anwendung versucht, auf einem 64-Bit-Betriebssystem ausgeführt zu werden. Es bedeutet, dass es so sein sollte
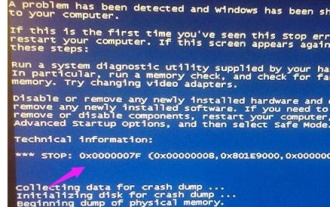 Ausführliche Erläuterung der Ursachen und Lösungen des Bluescreen-Codes 0x0000007f
Dec 25, 2023 pm 02:19 PM
Ausführliche Erläuterung der Ursachen und Lösungen des Bluescreen-Codes 0x0000007f
Dec 25, 2023 pm 02:19 PM
Bluescreen ist ein Problem, das bei der Nutzung des Systems häufig auftritt. Je nach Fehlercode gibt es viele verschiedene Gründe und Lösungen. Wenn wir beispielsweise auf das Problem „stop: 0x0000007f“ stoßen, kann es sich um einen Hardware- oder Softwarefehler handeln. Folgen wir dem Editor, um die Lösung herauszufinden. 0x000000c5 Bluescreen-Code-Grund: Antwort: Der Speicher, die CPU und die Grafikkarte sind plötzlich übertaktet oder die Software läuft falsch. Lösung 1: 1. Drücken Sie beim Booten weiterhin F8 zum Aufrufen, wählen Sie den abgesicherten Modus und drücken Sie zum Aufrufen die Eingabetaste. 2. Drücken Sie nach dem Aufrufen des abgesicherten Modus win+r, um das Ausführungsfenster zu öffnen, geben Sie cmd ein und drücken Sie die Eingabetaste. 3. Geben Sie im Eingabeaufforderungsfenster „chkdsk /f /r“ ein, drücken Sie die Eingabetaste und drücken Sie dann die Y-Taste. 4.
