
 Technologie-Peripheriegeräte
KI
Ein großes 33-Milliarden-Parameter-Modell in eine einzige Verbraucher-GPU „packen', was eine Geschwindigkeitssteigerung von 15 % ohne Leistungseinbußen bedeutet
Technologie-Peripheriegeräte
KI
Ein großes 33-Milliarden-Parameter-Modell in eine einzige Verbraucher-GPU „packen', was eine Geschwindigkeitssteigerung von 15 % ohne Leistungseinbußen bedeutet
Ein großes 33-Milliarden-Parameter-Modell in eine einzige Verbraucher-GPU „packen', was eine Geschwindigkeitssteigerung von 15 % ohne Leistungseinbußen bedeutet

Die Leistung vorab trainierter großer Sprachmodelle (LLM) bei bestimmten Aufgaben verbessert sich anschließend, wenn die prompten Anweisungen angemessen sind. Viele Menschen führen dieses Phänomen auf die Zunahme zurück Beim Trainieren von Daten und Parametern zeigen aktuelle Trends, dass Forscher sich mehr auf kleinere Modelle konzentrieren, diese Modelle jedoch auf mehr Daten trainiert werden und daher bei der Inferenz einfacher zu verwenden sind.
Zum Beispiel wurde LLaMA mit einer Parametergröße von 7B auf 1T-Tokens trainiert. Obwohl die durchschnittliche Leistung etwas niedriger ist als bei GPT-3, beträgt die Parametergröße 1/25 davon. Darüber hinaus können aktuelle Komprimierungstechnologien diese Modelle weiter komprimieren, wodurch der Speicherbedarf bei gleichbleibender Leistung deutlich reduziert wird. Mit solchen Verbesserungen können leistungsstarke Modelle auf Endbenutzergeräten wie Laptops bereitgestellt werden.
Allerdings steht dies vor einer weiteren Herausforderung: Wie können diese Modelle unter Berücksichtigung der Generierungsqualität auf eine ausreichend kleine Größe komprimiert werden, um in diese Geräte zu passen? Untersuchungen zeigen, dass komprimierte Modelle zwar Antworten mit akzeptabler Genauigkeit generieren, bestehende 3-4-Bit-Quantisierungstechniken jedoch immer noch die Genauigkeit verschlechtern. Da die LLM-Generierung sequentiell erfolgt und auf zuvor generierten Token basiert, häufen sich kleine relative Fehler und führen zu schwerwiegenden Ausgabefehlern. Um eine zuverlässige Qualität sicherzustellen, ist es wichtig, Quantisierungsmethoden mit geringer Bitbreite zu entwickeln, die die Vorhersageleistung im Vergleich zu 16-Bit-Modellen nicht beeinträchtigen.
Allerdings führt die Quantisierung jedes Parameters auf 3–4 Bit häufig zu moderaten oder sogar hohen Genauigkeitsverlusten, insbesondere bei kleineren Modellen im Parameterbereich 1–10B, die sich ideal für den Edge-Einsatz eignen.
Um das Genauigkeitsproblem zu lösen, schlugen Forscher der University of Washington, der ETH Zürich und anderer Institutionen ein neues Komprimierungsformat und eine Quantisierungstechnologie SpQR (Sparse-Quantized Representation, spärlich quantisierte Darstellung) vor, die für die implementiert wurde Zum ersten Mal bietet LLM eine nahezu verlustfreie Komprimierung über Modellskalen hinweg und erreicht dabei ähnliche Komprimierungsniveaus wie frühere Methoden.
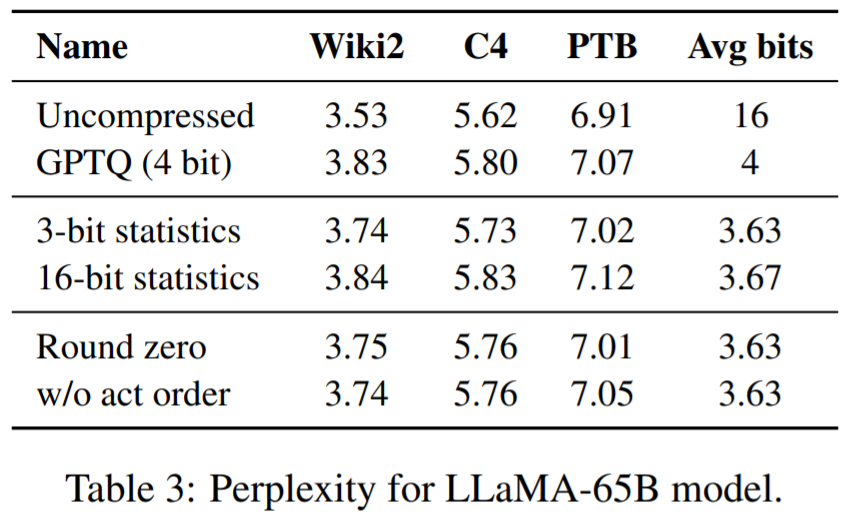
SpQR identifiziert und isoliert anomale Gewichte, die besonders große Quantisierungsfehler verursachen, speichert sie mit höherer Präzision, während alle anderen Gewichte in LLaMA auf 3-4 Bits komprimiert werden, und erreicht in Perplexity einen relativen Genauigkeitsverlust von weniger als 1 % Falcon-LLMs. Dadurch kann ein 33-B-Parameter-LLM auf einer einzelnen 24-GB-Consumer-GPU ohne Leistungseinbußen ausgeführt werden und ist gleichzeitig 15 % schneller.
Der SpQR-Algorithmus ist effizient und kann die Gewichte sowohl in andere Formate kodieren als auch zur Laufzeit effizient dekodieren. Konkret stellt diese Forschung SpQR einen effizienten GPU-Inferenzalgorithmus zur Verfügung, der eine schnellere Inferenz als 16-Bit-Basismodelle ermöglicht und gleichzeitig eine über 4-fache Steigerung der Speicherkomprimierung erzielt.

- Papieradresse: https://arxiv.org/pdf/2306.03078.pdf
- Projektadresse: https://github.com/Vahe1994/SpQR
Methode
Diese Studie schlägt ein neues Format für die hybride Sparse-Quantisierung vor – Sparse Quantization Representation (SpQR), das präzise vorab trainierte LLM auf 3–4 Bits pro Parameter komprimieren kann und dabei nahezu verlustfrei bleibt.
Konkret unterteilte die Studie den gesamten Prozess in zwei Schritte. Der erste Schritt ist die Erkennung von Ausreißern: Die Studie isoliert zunächst die Ausreißergewichte und zeigt, dass ihre Quantisierung zu hohen Fehlern führt: Ausreißergewichte bleiben mit hoher Präzision erhalten, während andere Gewichte mit geringer Präzision gespeichert werden (z. B. in einem 3-Bit-Format). Die Studie implementiert dann eine Variante der gruppierten Quantisierung mit sehr kleinen Gruppengrößen und zeigt, dass die Quantisierungsskala selbst in eine 3-Bit-Darstellung quantisiert werden kann.
SpQR reduziert den Speicherbedarf von LLM erheblich, ohne die Genauigkeit zu beeinträchtigen, und produziert LLM im Vergleich zur 16-Bit-Inferenz um 20–30 % schneller.
Darüber hinaus ergab die Studie, dass die Positionen sensibler Gewichte in der Gewichtsmatrix nicht zufällig sind, sondern eine bestimmte Struktur haben. Um seine Struktur während der Quantifizierung hervorzuheben, berechnete die Studie die Empfindlichkeit jedes Gewichts und visualisierte diese Gewichtsempfindlichkeiten für das LLaMA-65B-Modell. Abbildung 2 unten zeigt die Ausgabeprojektion der letzten Selbstaufmerksamkeitsschicht von LLaMA-65B.
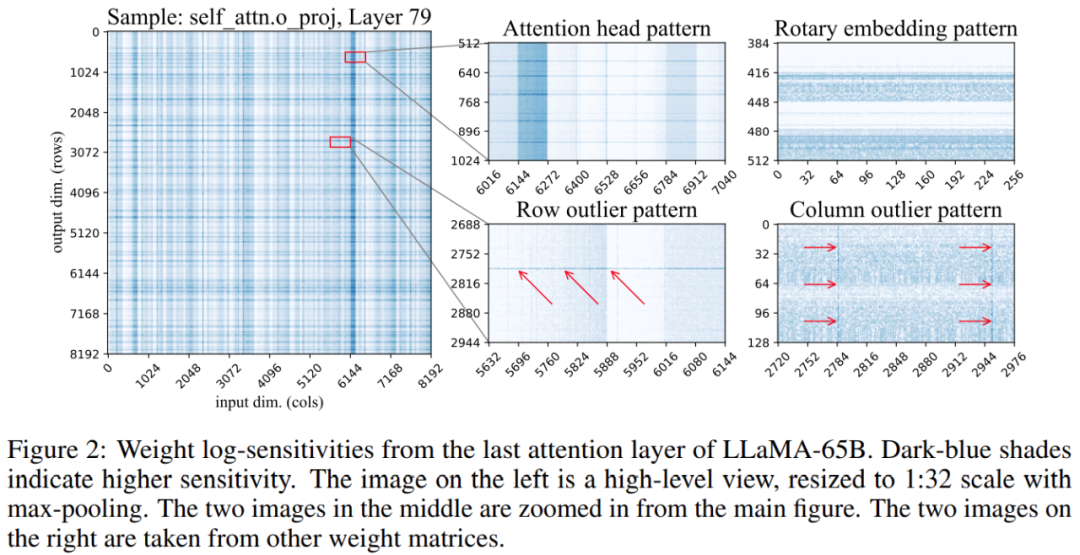
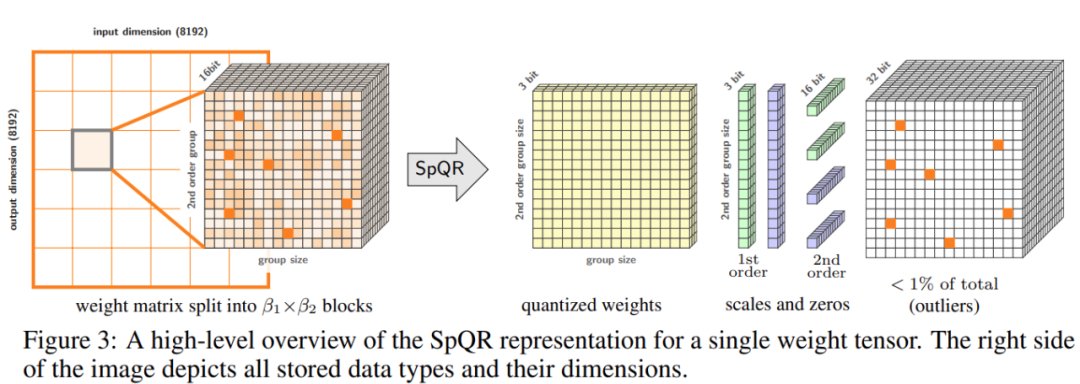
Diese Studie nimmt zwei Änderungen am Quantifizierungsprozess vor: eine zur Erfassung kleiner empfindlicher Gewichtsgruppen und die andere zur Erfassung einzelner Ausreißer. Abbildung 3 unten zeigt die Gesamtarchitektur von SpQR:
Die folgende Tabelle zeigt den SpQR-Quantisierungsalgorithmus. Das Codefragment auf der linken Seite beschreibt den gesamten Prozess, und das Codefragment auf der rechten Seite enthält Unterprogramme für die Sekundärseite Quantisierung und Finden von Ausreißern. :

Die Studie verglich SpQR mit zwei anderen Quantisierungsschemata: GPTQ, RTN (Aufrunden auf den nächsten Wert) und verwendete zwei Metriken, um die Leistung des Quantisierungsmodells zu bewerten. Die erste ist die Messung der Perplexität unter Verwendung von Datensätzen wie WikiText2, Penn Treebank und C4; die zweite ist die Null-Stichproben-Genauigkeit bei fünf Aufgaben: WinoGrande, PiQA, HellaSwag, ARC-easy, ARC-challenge.
Hauptergebnisse. Die Ergebnisse aus Abbildung 1 zeigen, dass SpQR bei ähnlichen Modellgrößen deutlich besser abschneidet als GPTQ (und das entsprechende RTN), insbesondere bei kleineren Modellen. Diese Verbesserung ist darauf zurückzuführen, dass SpQR eine stärkere Komprimierung erzielt und gleichzeitig die Verlustverschlechterung reduziert.
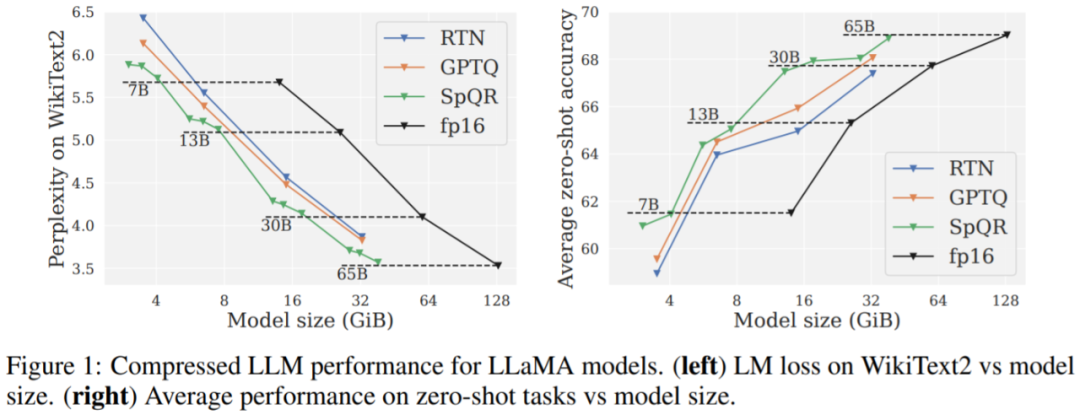
Tabelle 1, Tabelle 2 Die Ergebnisse zeigen, dass bei der 4-Bit-Quantisierung der Fehler von SpQR relativ zur 16-Bit-Basislinie im Vergleich zu GPTQ halbiert ist.
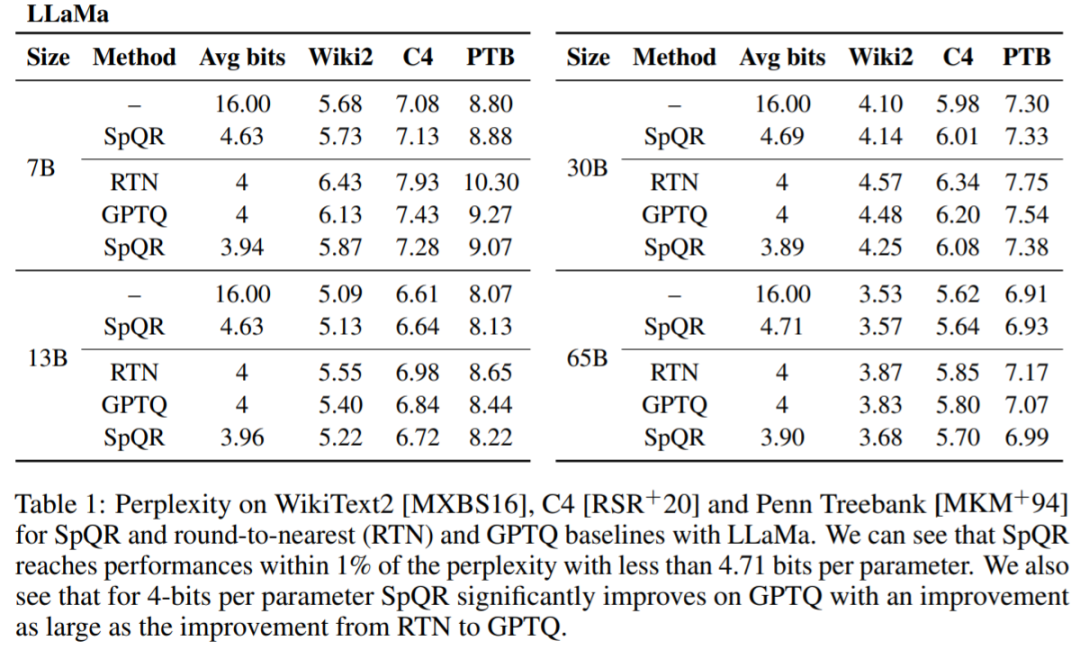
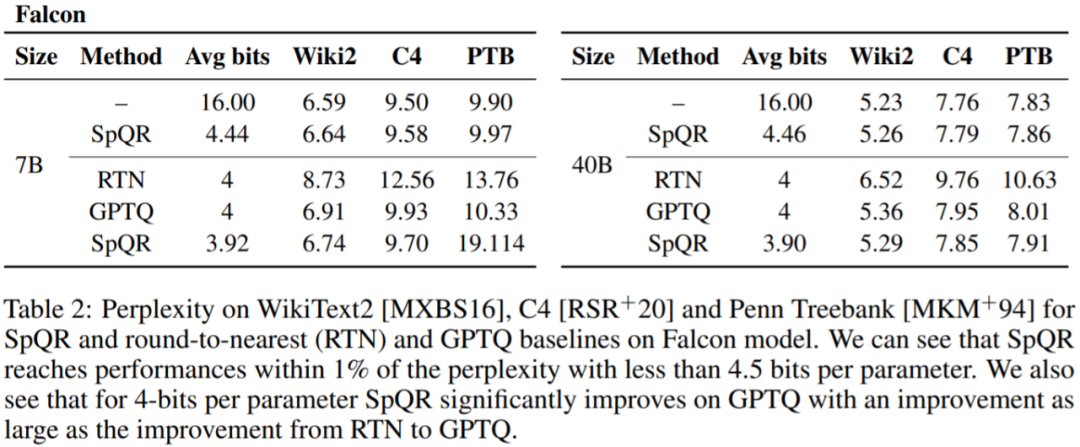
Tabelle 3 zeigt die Verwirrungsergebnisse des LLaMA-65B-Modells für verschiedene Datensätze.
Abschließend bewertet die Studie die SpQR-Inferenzgeschwindigkeit. In dieser Studie wird ein speziell entwickelter Sparse-Matrix-Multiplikationsalgorithmus mit dem in PyTorch (cuSPARSE) implementierten Algorithmus verglichen. Die Ergebnisse sind in Tabelle 4 aufgeführt. Wie Sie sehen können, ist die standardmäßige Sparse-Matrix-Multiplikation in PyTorch zwar nicht schneller als die 16-Bit-Inferenz, der in diesem Artikel speziell entwickelte Sparse-Matrix-Multiplikationsalgorithmus kann die Geschwindigkeit jedoch um etwa 20–30 % verbessern.

Das obige ist der detaillierte Inhalt vonEin großes 33-Milliarden-Parameter-Modell in eine einzige Verbraucher-GPU „packen', was eine Geschwindigkeitssteigerung von 15 % ohne Leistungseinbußen bedeutet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
Oben geschrieben und persönliches Verständnis des Autors: Dieses Papier widmet sich der Lösung der wichtigsten Herausforderungen aktueller multimodaler großer Sprachmodelle (MLLMs) in autonomen Fahranwendungen, nämlich dem Problem der Erweiterung von MLLMs vom 2D-Verständnis auf den 3D-Raum. Diese Erweiterung ist besonders wichtig, da autonome Fahrzeuge (AVs) genaue Entscheidungen über 3D-Umgebungen treffen müssen. Das räumliche 3D-Verständnis ist für AVs von entscheidender Bedeutung, da es sich direkt auf die Fähigkeit des Fahrzeugs auswirkt, fundierte Entscheidungen zu treffen, zukünftige Zustände vorherzusagen und sicher mit der Umgebung zu interagieren. Aktuelle multimodale große Sprachmodelle (wie LLaVA-1.5) können häufig nur Bildeingaben mit niedrigerer Auflösung verarbeiten (z. B. aufgrund von Auflösungsbeschränkungen des visuellen Encoders und Einschränkungen der LLM-Sequenzlänge). Allerdings erfordern autonome Fahranwendungen
 Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks: REST-API-Anforderungsverarbeitung: Vert.x ist am besten, mit einer Anforderungsrate von 2-mal SpringBoot und 3-mal Dropwizard. Datenbankabfrage: HibernateORM von SpringBoot ist besser als ORM von Vert.x und Dropwizard. Caching-Vorgänge: Der Hazelcast-Client von Vert.x ist den Caching-Mechanismen von SpringBoot und Dropwizard überlegen. Geeignetes Framework: Wählen Sie entsprechend den Anwendungsanforderungen. Vert.x eignet sich für leistungsstarke Webdienste, SpringBoot eignet sich für datenintensive Anwendungen und Dropwizard eignet sich für Microservice-Architekturen.
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
