
 Technologie-Peripheriegeräte
KI
Ein langer Artikel mit 10.000 Wörtern erläutert die Anwendung großer Modelle im Bereich des autonomen Fahrens
Technologie-Peripheriegeräte
KI
Ein langer Artikel mit 10.000 Wörtern erläutert die Anwendung großer Modelle im Bereich des autonomen Fahrens
Ein langer Artikel mit 10.000 Wörtern erläutert die Anwendung großer Modelle im Bereich des autonomen Fahrens

Mit der Popularität von ChatGPT haben große Models immer mehr Aufmerksamkeit erhalten und die Fähigkeiten, die große Models zeigen, sind erstaunlich.
In den Bereichen Bilderzeugung, Empfehlungssysteme, maschinelle Übersetzung und anderen Bereichen spielen große Modelle zunehmend eine Rolle. Mit ein paar prompten Worten haben die von der Bildgenerierungs-Website Midjourney erstellten Designzeichnungen sogar das Niveau vieler professioneller Designer übertroffen.
Warum können große Models erstaunliche Fähigkeiten zeigen? Warum wird die Leistung des Modells besser, wenn die Anzahl der Parameter und die Kapazität des Modells zunehmen?
Ein Experte eines KI-Algorithmus-Unternehmens sagte dem Autor: Die Zunahme der Anzahl der Parameter des Modells kann als eine Zunahme der Dimension des Modells verstanden werden, was bedeutet, dass wir komplexere Methoden zur Simulation verwenden können Gesetze der realen Welt. Nehmen Sie als Beispiel das einfachste Szenario. Wenn wir eine gerade Linie (eine Funktion mit einer Variablen) verwenden, um das Muster der Streupunkte auf dem Diagramm zu beschreiben, wird dies der Fall sein Sei immer ein Punkt. Der Punkt liegt außerhalb dieser Linie. Wenn wir eine Binärfunktion verwenden, um das Muster dieser Punkte darzustellen, fallen mehr Punkte auf diese Funktionslinie. Mit zunehmender Dimension der Funktion oder zunehmendem Freiheitsgrad fallen immer mehr Punkte auf diese Linie, was bedeutet, dass die Gesetze dieser Punkte genauer angepasst werden.
Mit anderen Worten: Je größer die Anzahl der Parameter des Modells, desto einfacher ist es für das Modell, die Gesetze massiver Daten zu erfüllen.
Mit dem Aufkommen von ChatGPT haben die Menschen herausgefunden, dass der Effekt nicht nur „bessere Leistung“, sondern „besser als erwartet“ ist, wenn die Parameter des Modells ein bestimmtes Niveau erreichen.
Im Bereich NLP (Natural Language Processing) gibt es ein spannendes Phänomen, dessen spezifische Prinzipien in akademischen Kreisen und der Industrie noch nicht erklärt werden konnten: „Emerging Ability“.
Was ist „Emergenz“? „Emergenz“ bedeutet, dass die Genauigkeit des Modells exponentiell zunimmt, wenn die Anzahl der Parameter des Modells linear auf ein bestimmtes Niveau ansteigt.
Die linke Seite des Bildes unten zeigt das Skalierungsgesetz. Dies ist ein Phänomen, das von OpenAI-Forschern vor 2022 entdeckt wurde. Das heißt, die Genauigkeit des Modellparameters nimmt exponentiell zu das Modell steigt linear an. Die Modellparameter im Bild links wachsen nicht exponentiell, sondern linear
Im Januar 2022 stellten einige Forscher fest, dass der Grad der Verbesserung der Modellgenauigkeit den Proportionalwert deutlich übersteigt, wenn die Parameterskala des Modells ein bestimmtes Niveau überschreitet Kurve, wie folgt. Abbildung rechts.
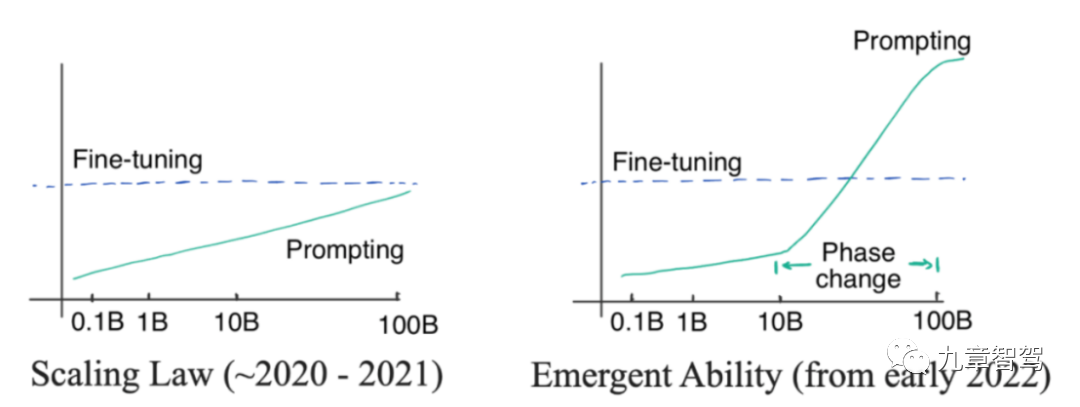
„Emergenz“-Diagramm
Bei der Implementierung auf Anwendungsebene werden wir feststellen, dass große Modelle einige Aufgaben erfüllen können, die kleine Modelle nicht erfüllen können, z. B. große Modelle können addieren und subtrahieren und tun einfache Aufgaben, Argumentation usw.
Welche Art von Modell kann man als großes Modell bezeichnen?
Generell glauben wir, dass Modelle mit mehr als 100 Millionen Parametern als „große Modelle“ bezeichnet werden können. Im Bereich des autonomen Fahrens haben große Modelle hauptsächlich zwei Bedeutungen: Das eine ist ein Modell mit mehr als 100 Millionen Parametern, das andere ist ein Modell, das aus mehreren überlagerten kleinen Modellen besteht wird auch als „Großmodell“ bezeichnet.
Nach dieser Definition werden große Modelle zunehmend im Bereich des autonomen Fahrens eingesetzt. In der Cloud können wir die Kapazitätsvorteile nutzen, die sich aus der erhöhten Anzahl von Modellparametern ergeben, und große Modelle verwenden, um einige Aufgaben wie Data Mining und Datenannotation zu erledigen. Auf der Fahrzeugseite können wir mehrere kleine Modelle, die für verschiedene Teilaufgaben verantwortlich sind, zu einem „großen Modell“ zusammenführen, was bei der Berechnung auf der Fahrzeugseite Argumentationszeit sparen und die Sicherheit erhöhen kann.
Wie können konkret große Modelle ins Spiel kommen? Nach den Informationen, die der Autor mit Branchenexperten kommuniziert hat, setzt die Branche derzeit hauptsächlich große Modelle im Bereich der Wahrnehmung ein. Als nächstes stellen wir vor, wie große Modelle Wahrnehmungsaufgaben in der Cloud bzw. auf der Fahrzeugseite ermöglichen.
01
Application großer Modelle
1.1 Anwendung großer Modelle in der Cloud
1.1.1 Automatische Datenmarkierung erreicht. Am Beispiel der Videoclip-Annotation können Sie zunächst umfangreiche unbeschriftete Clip-Daten verwenden, um ein großes Modell durch Selbstüberwachung vorab zu trainieren, und dann eine kleine Menge manuell beschrifteter Clip-Daten verwenden, um das Modell so zu optimieren, dass das Modell dies hat Erkennungsfunktionen Das Modell kann Clipdaten automatisch mit Anmerkungen versehen.
Je höher die Kennzeichnungsgenauigkeit des Modells, desto höher ist der Grad der Ersetzung von Personen.Derzeit untersuchen viele Unternehmen, wie die Genauigkeit der automatischen Beschriftung großer Modelle verbessert werden kann, in der Hoffnung, eine vollständige unbemannte automatische Beschriftung zu erreichen, sobald die Genauigkeit den Standard erreicht.
Leo, Direktor für intelligente Fahrprodukte von SenseTime Jueying, sagte dem Autor: Wir haben Bewertungen durchgeführt und festgestellt, dass die automatische Kennzeichnungsgenauigkeit der großen Modelle von SenseTime mehr als 98 % erreichen kann Durch die anschließende manuelle Überprüfung können die Schritte sehr rationalisiert werden.
Im Entwicklungsprozess intelligenter Fahrprodukte hat SenseTime Jueying im Vergleich zur Vergangenheit die automatische Vorkennzeichnung großer Modelle für die meisten Wahrnehmungsaufgaben eingeführt, wenn die gleiche Anzahl von Datenproben, der Kennzeichnungszyklus und die Kennzeichnung erhalten wurden Die Kosten sind kürzer. Sie können um mehr als das Dutzendfache reduziert werden, was die Entwicklungseffizienz erheblich verbessert.
Generell gesehen umfassen die Erwartungen aller an Annotationsaufgaben vor allem eine hohe Effizienz des Annotationsprozesses, eine hohe Genauigkeit und eine hohe Konsistenz der Annotationsergebnisse. Hohe Effizienz und hohe Genauigkeit sind leicht zu verstehen. Was bedeutet hohe Konsistenz? Im BEV-Algorithmus für die 3D-Erkennung müssen Ingenieure die gemeinsame Annotation von Lidar und Vision verwenden und Punktwolken- und Bilddaten gemeinsam verarbeiten. Bei dieser Art der Verarbeitungsverbindung müssen Ingenieure möglicherweise auch einige Anmerkungen auf der Timing-Ebene vornehmen, damit die Ergebnisse des vorherigen und des nächsten Frames nicht zu unterschiedlich sein können.
Wenn manuelle Anmerkungen verwendet werden, hängt der Anmerkungseffekt von der Anmerkungsebene des Annotators ab. Die ungleichmäßige Anzahl von Annotatoren kann zu Inkonsistenzen in den Anmerkungsergebnissen führen. Wenn das Modell relativ klein ist, sind die Anmerkungsergebnisse großer Modelle im Allgemeinen konsistenter.
Einige Branchenexperten haben jedoch berichtet, dass es einige Schwierigkeiten bei der Umsetzung der automatischen Kennzeichnung großer Modelle in praktische Anwendungen geben wird, insbesondere im Zusammenhang mit Unternehmen für autonomes Fahren und Kennzeichnungsunternehmen – viele Unternehmen für autonomes Fahren werden einen Teil der Arbeit kennzeichnen wird an Annotationsunternehmen ausgelagert, und einige Unternehmen verfügen nicht über ein internes Annotationsteam, sodass die gesamte Annotationsarbeit ausgelagert wird.
Derzeit handelt es sich bei den Zielen, die die Voranmerkung großer Modelle verwenden, hauptsächlich um dynamische 3D-Ziele. Das Unternehmen für autonomes Fahren verwendet zunächst das große Modell, um Rückschlüsse auf das Video zu ziehen, das mit Anmerkungen versehen werden muss, und verwendet dann das Rückschlussergebnis. das Modell Die generierte 3D-Box wird an das Beschriftungsunternehmen übergeben. Wenn ein großes Modell zunächst vorab kommentiert wird und die vorab kommentierten Ergebnisse dann an ein Annotationsunternehmen übergeben werden, gibt es zwei Hauptprobleme: Zum einen unterstützen die Annotationsplattformen einiger Annotationsunternehmen das Laden vorab annotierter Ergebnisse möglicherweise nicht unbedingt liegt darin, dass das Annotationsunternehmen nicht unbedingt bereit ist, Änderungen an den vorab kommentierten Ergebnissen vorzunehmen.
Wenn ein Annotationsunternehmen vorab kommentierte Ergebnisse laden möchte, benötigt es eine Softwareplattform, die das Laden von 3D-Frames unterstützt, die von großen Modellen generiert wurden. Einige Annotationsunternehmen verwenden jedoch möglicherweise hauptsächlich manuelle Annotationen und verfügen nicht über eine Softwareplattform, die das Laden von Modellergebnissen vor der Annotation unterstützt. Wenn sie bei der Kontaktaufnahme mit Kunden vorab annotierte Modellergebnisse erhalten, haben sie keine Möglichkeit, diese zu akzeptieren.
Darüber hinaus können Annotationsunternehmen aus Sicht der Annotationsunternehmen nur dann wirklich „Aufwand sparen“, wenn der Vorannotationseffekt gut genug ist, andernfalls erhöhen sie möglicherweise ihre Arbeitsbelastung.
Wenn der Voretikettierungseffekt nicht gut genug ist, muss das Etikettierungsunternehmen in Zukunft noch viel Arbeit leisten, z. B. fehlende Kartons kennzeichnen, falsch etikettierte Kartons löschen, die Größe der Kartons vereinheitlichen usw . Dann hilft ihnen die Verwendung der Vorannotation möglicherweise nicht wirklich dabei, ihre Arbeitsbelastung zu reduzieren.
Daher muss in praktischen Anwendungen zwischen dem autonomen Fahrunternehmen und dem Annotationsunternehmen abgewogen werden, ob große Modelle für die Vorannotation verwendet werden sollen.
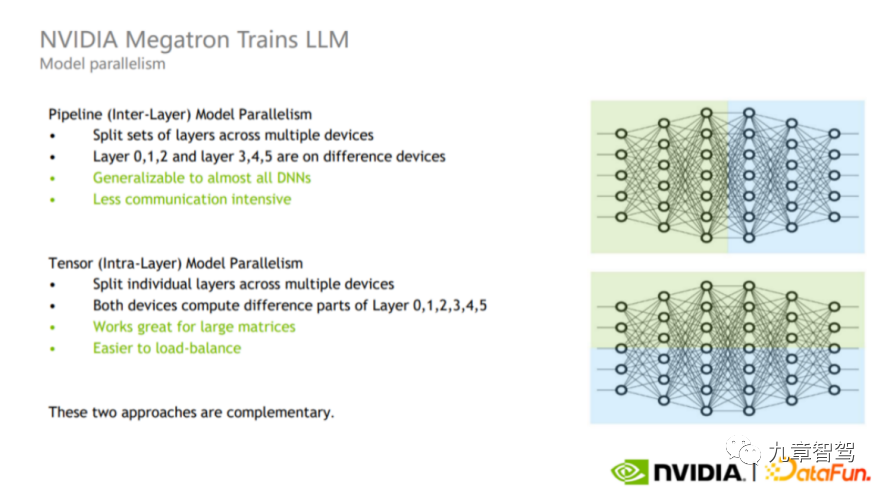
Natürlich sind die aktuellen Kosten für die manuelle Annotation relativ hoch – wenn das Annotationsunternehmen bei Null anfangen darf, können die Kosten für die manuelle Annotation von 1.000 Frames Videodaten 10.000 Yuan erreichen. Daher hoffen Unternehmen für autonomes Fahren immer noch, die Genauigkeit der Vorkennzeichnung großer Modelle so weit wie möglich zu verbessern und den Arbeitsaufwand für die manuelle Kennzeichnung so weit wie möglich zu reduzieren, wodurch die Kennzeichnungskosten gesenkt werden. 1.1.2 Data Mining Große Modelle weisen eine starke Verallgemeinerung auf und eignen sich für das Mining von Long-Tail-Daten. Ein Experte von WeRide sagte dem Autor: Wenn die traditionelle Tag-basierte Methode zum Mining von Long-Tail-Szenen verwendet wird, kann das Modell im Allgemeinen nur bekannte Bildkategorien unterscheiden. Im Jahr 2021 veröffentlichte OpenAI das CLIP-Modell (ein multimodales Text-Bild-Modell, das nach unbeaufsichtigtem Vortraining Text und Bilder korrespondieren kann und dabei Bilder basierend auf Text klassifiziert, anstatt sich nur auf die Beschriftungen der Bilder zu verlassen). Übernehmen Sie auch ein solches multimodales Text-Bild-Modell und verwenden Sie Textbeschreibungen, um Bilddaten im Fahrtenprotokoll abzurufen. Zum Beispiel Longtail-Szenen wie „Baufahrzeuge schleppen Güter“ und „Ampel mit zwei gleichzeitig eingeschalteten Glühbirnen“. Darüber hinaus können große Modelle Merkmale besser aus den Daten extrahieren und dann Ziele mit ähnlichen Merkmalen finden. Angenommen, wir möchten aus vielen Bildern Bilder mit Sanitärarbeitern finden. Wir müssen die Bilder nicht zuerst spezifisch beschriften. Wir können das große Modell mit einer großen Anzahl von Bildern mit Sanitärarbeitern vorab trainieren Daraus lassen sich Merkmale einiger Sanitärarbeiter ableiten. Anschließend werden aus den Bildern Proben gefunden, die den Merkmalen von Sanitärarbeitern entsprechen, wodurch fast alle Bilder herausgesucht werden, die Sanitärarbeiter zeigen. 1.1.3 Nutzen Sie die Wissensdestillation, um kleinen Modellen „beizubringen“. Große Modelle können die Wissensdestillation auch nutzen, um kleinen Modellen „beizubringen“. Was ist Wissensdestillation? Um es mit den gängigsten Worten zu erklären: Das große Modell lernt zunächst etwas Wissen aus den Daten oder extrahiert einige Informationen und verwendet dann das erlernte Wissen, um das kleine Modell zu „lehren“. In der Praxis können wir zunächst die Bilder lernen, die vom großen Modell beschriftet werden müssen. Auf diese Weise können wir diese Bilder beschriften und diese Bilder für das Training verwenden einfachste Art, Wissen zu destillieren. Natürlich können wir auch komplexere Methoden verwenden, z. B. die Verwendung eines großen Modells zum Extrahieren von Features aus massiven Daten, und diese extrahierten Features können zum Trainieren kleiner Modelle verwendet werden. Mit anderen Worten, wir können auch ein komplexeres Modell entwerfen und ein mittleres Modell zwischen dem großen Modell und dem kleinen Modell hinzufügen. Die vom großen Modell extrahierten Merkmale trainieren zunächst das mittlere Modell und verwenden dann das trainierte mittlere Modell, um Merkmale zu extrahieren Geben Sie sie dem kleinen Modell zur Verwendung. Ingenieure können die Entwurfsmethode entsprechend ihren eigenen Anforderungen wählen. Der Autor hat von Xiaoma.ai erfahren, dass durch Destillieren und Feinabstimmen von aus großen Modellen extrahierten Merkmalen kleine Modelle wie Fußgängeraufmerksamkeit und Fußgängerabsichtserkennung erhalten werden können. Da außerdem ein großes Modell in der Merkmalsextraktionsphase gemeinsam genutzt wird, Der Rechenaufwand kann reduziert werden. 1.1.4 Testen Sie die Leistungsobergrenze des Car-End-Modells Das große Modell kann auch zum Testen der Leistungsobergrenze des Car-End-Modells verwendet werden. Wenn einige Unternehmen überlegen, welches Modell im Auto eingesetzt werden soll, testen sie zunächst mehrere alternative Modelle in der Cloud, um zu sehen, welches Modell die beste Wirkung hat und inwieweit nach einer Erhöhung der Parameteranzahl die beste Leistung erzielt werden kann. Verwenden Sie dann das Modell mit der besten Leistung als Basismodell, passen Sie das Basismodell an und optimieren Sie es, bevor Sie es im Fahrzeug einsetzen. 1.1.5 Rekonstruktion und Datengenerierung autonomer Fahrszenen Haomo Zhixing erwähnte am AI DAY im Januar 2023: „Mit der NeRF-Technologie können wir die Szene implizit im neuronalen Netzwerk speichern Implizite Parameter der Szene werden durch überwachtes Lernen der gerenderten Bilder gelernt, und dann kann die autonome Fahrszene rekonstruiert werden.“ Zum Beispiel können wir Bilder, entsprechende Posen und farbige szenendichte Punktwolken in das Netzwerk eingeben, und basierend auf dem Punktgitternetzwerk werden die farbigen Punktwolken entsprechend der Pose des Eingabebildes mit unterschiedlichen Auflösungen gerastert. isierung, generieren neuronale Deskriptoren auf mehreren Skalen und fusionieren dann Merkmale auf verschiedenen Skalen über das Netzwerk. Dann werden der Deskriptor, die Position der erzeugten dichten Punktwolke und die entsprechenden Kameraparameter und Belichtungsparameter des Bildes zur Feinabstimmung der Tonwertzuordnung in das nachfolgende Netzwerk eingegeben, und es kann ein Bild mit konsistenter Farbe und Belichtung erstellt werden synthetisiert. Auf diese Weise können wir die Szene rekonstruieren. Dann können wir verschiedene hochrealistische Daten generieren, indem wir die Perspektive ändern, die Beleuchtung ändern und das Texturmaterial ändern. Durch Ändern der Perspektive können wir beispielsweise verschiedene Hauptverhaltensweisen von Fahrzeugen wie Spurwechsel, Umwege und U-Bahnen simulieren. Kurven und simulieren Sie sogar einige drohende Kollisionsdaten. 1.2 Anwendung großer Modelle auf der Autoseite Verschiedene Teilaufgaben: Kleine Modelle werden zu einem „großen Modell“ zusammengeführt und anschließend wird eine gemeinsame Inferenz durchgeführt. Das „große Modell“ bedeutet hier nicht eine große Anzahl von Parametern im herkömmlichen Sinne – zum Beispiel ein großes Modell mit über 100 Millionen Parametern. Natürlich wird das kombinierte Modell viel größer sein als das kleine Modell, das verschiedene Teilaufgaben behandelt. Das bisherige automatische Fahrsystem hatte weniger Funktionen und die Wahrnehmungsaufgaben waren relativ einfach. Mit der Aktualisierung der Funktionen des automatischen Fahrsystems gibt es jedoch immer mehr Wahrnehmungsaufgaben, wenn verschiedene Aufgaben weiterhin separat verwendet werden. Kleine Modelle, die für die entsprechenden Aufgaben verantwortlich sind, werden gemäß der Argumentationsmethode zu groß und es bestehen Sicherheitsrisiken. Das BEV-Multitask-Wahrnehmungsframework von Juefei Technology kombiniert kleine Einzeltask-Wahrnehmungsmodelle verschiedener Ziele zu einem System, das gleichzeitig statische Informationen ausgeben kann – einschließlich Fahrspurlinien, Bodenpfeile, Zebrastreifen an Kreuzungen und Stopps Linien usw. sowie dynamische Informationen - einschließlich Standort, Größe, Ausrichtung usw. der Verkehrsteilnehmer. Das BEV-Framework für den Multitask-Wahrnehmungsalgorithmus von Juefei Technology ist in der folgenden Abbildung dargestellt: Das Aufgabenwahrnehmungsmodell implementiert das Timing von Features. Fusion – Speichern der BEV-Features zu historischen Zeitpunkten in der Feature-Warteschlange. In der Inferenzphase werden die BEV-Features zu historischen Zeitpunkten basierend auf dem Fahrzeugkoordinatensystem zum aktuellen Zeitpunkt räumlich-zeitlich ausgerichtet. (einschließlich Merkmalsrotation und -verschiebung) basierend auf dem Bewegungszustand des Fahrzeugs und verbinden Sie dann die ausgerichteten BEV-Merkmale des historischen Moments mit den BEV-Merkmalen des aktuellen Moments. In autonomen Fahrszenarien kann die Zeitfusion die Genauigkeit des Wahrnehmungsalgorithmus verbessern und die Einschränkungen der Einzelbildwahrnehmung bis zu einem gewissen Grad ausgleichen. Am Beispiel der in der Abbildung gezeigten 3D-Zielerkennungsunteraufgabe kann das Wahrnehmungsmodell mit zeitlicher Fusion einige Ziele erkennen, die vom Einzelbild-Wahrnehmungsmodell nicht erkannt werden können (z. B. Ziele, die im aktuellen Moment verdeckt sind). kann auch die Bewegungsgeschwindigkeit des Ziels genauer beurteilen und nachgelagerte Aufgaben bei der Vorhersage der Zielbahn unterstützen. Dr. Qi Yuhan, Leiter der BEV-Sensortechnologie bei Juefei Technology, sagte dem Autor: Wenn Sensoraufgaben immer komplexer werden, kann das Multitasking-Joint-Sensing-Framework mithilfe einer solchen Modellarchitektur eine Echtzeiterfassung gewährleisten und kann auch immer genauere Wahrnehmungsergebnisse für die nachgelagerte Nutzung des autonomen Fahrsystems ausgeben. Allerdings wird die Zusammenführung kleiner Multitasking-Modelle auch einige Probleme mit sich bringen. Auf algorithmischer Ebene kann die Leistung des zusammengeführten Modells bei verschiedenen Unteraufgaben „zurückgesetzt“ werden – das heißt, die Leistung der Modellerkennung ist geringer als die des unabhängigen Einzelaufgabenmodells. Obwohl die Netzwerkstruktur eines großen Modells, das durch die Zusammenführung verschiedener kleiner Modelle gebildet wird, immer noch sehr anspruchsvoll sein kann, muss das kombinierte Modell das Problem des gemeinsamen Trainings mit mehreren Aufgaben lösen. Beim gemeinsamen Training mit mehreren Aufgaben kann möglicherweise nicht jede Unteraufgabe eine gleichzeitige und synchrone Konvergenz erreichen, und die Aufgaben werden durch eine „negative Übertragung“ beeinträchtigt, und das kombinierte Modell weist bei einigen spezifischen Aufgaben eine schlechte Genauigkeit auf . "Zurückgreifen". Das Algorithmenteam muss die Struktur des zusammengeführten Modells so weit wie möglich optimieren, die gemeinsame Trainingsstrategie anpassen und die Auswirkungen des Phänomens der „negativen Übertragung“ verringern. 1.2.2 Objekterkennung Ein Branchenexperte sagte dem Autor: Einige Objekte mit relativ festen wahren Werten eignen sich für die Erkennung mit großen Modellen. Was ist also ein Objekt, dessen wahrer Wert relativ feststeht? Die sogenannten Objekte mit festen Wahrheitswerten sind Objekte, deren wahrer Wert nicht durch Wetter, Zeit und andere Faktoren beeinflusst wird, wie z. B. Fahrspurlinien, Säulen, Laternenpfähle, Ampeln, Zebrastreifen, Parklinien in Kellern, Parkplätzen usw. Die Existenz und Lage dieser Objekte ist fest und ändert sich nicht durch Faktoren wie Regen oder Dunkelheit. Solange das Fahrzeug durch den entsprechenden Bereich fährt, sind ihre Positionen fest. Solche Objekte eignen sich zur Erkennung mit großen Modellen. 1.2.3 Vorhersage der Spurtopologie Ein Unternehmen für autonomes Fahren, das auf dem AI DAY des Unternehmens erwähnt wurde: „Wir verwenden die Standardkarte als Leitinformationen basierend auf der BEV-Funktionskarte und verwenden die autoregressive Codierung.“ und Dekodierungsnetzwerk, um BEV-Merkmale in eine strukturierte topologische Punktsequenz zu dekodieren, um eine Vorhersage der Spurtopologie zu erreichen Grundlagen Das Modell-Framework ist kein Geheimnis. Ob ein Unternehmen ein gutes Produkt herstellen kann, hängt oft von seinen technischen Fähigkeiten ab. 2.1 Aktualisieren Sie das Datenspeicher- und Dateiübertragungssystem Die Parameter großer Modelle sind groß, und dementsprechend ist auch die Datenmenge groß, die zum Trainieren großer Modelle verwendet wird. Beispielsweise nutzte das Algorithmenteam von Tesla rund 1,4 Milliarden Bilder, um das 3D-Belegungsnetzwerk zu trainieren, über das das Team letztes Jahr beim AI Day sprach. Tatsächlich wird der Anfangswert der Anzahl der Bilder wahrscheinlich das Dutzende oder Hundertfache der tatsächlich verwendeten Anzahl betragen, da wir zunächst die für das Modelltraining wertvollen Daten aus den massiven Daten herausfiltern müssen. Da es für das Modell verwendet wird, beträgt die Anzahl der Trainingsbilder 1,4 Milliarden, daher muss die Anzahl der Originalbilder viel größer als 1,4 Milliarden sein. Um solche Herausforderungen zu bewältigen, verwenden einige Unternehmen in der Branche eine Slicing-Speichermethode für Daten und verwenden dann eine verteilte Architektur, um den Mehrbenutzer- und Mehrfachzugriff zu unterstützen. Die Datendurchsatzbandbreite kann 100 G/s erreichen. Die E/A-Latenz kann bis zu 2 Millisekunden betragen. Der sogenannte Multi-User bezieht sich auf den gleichzeitigen Zugriff vieler Benutzer auf eine bestimmte Datendatei; Multi-Parallelität bezieht sich auf die Notwendigkeit, in mehreren Threads auf eine bestimmte Datendatei zuzugreifen. Wenn Ingenieure beispielsweise ein Modell trainieren, verwenden sie Multi -Threading. Jeder Thread erfordert die Verwendung einer bestimmten Datendatei. Wie kann bei Big Data sichergestellt werden, dass das Modell die Dateninformationen besser abstrahiert? Dies erfordert, dass das Modell über eine Netzwerkarchitektur verfügt, die für die entsprechenden Aufgaben geeignet ist, damit der Vorteil der großen Anzahl von Parametern des Modells voll ausgenutzt werden kann und das Modell über starke Fähigkeiten zur Informationsextraktion verfügt. Lucas, Senior Manager für Forschung und Entwicklung großer Modelle bei SenseTime, sagte dem Autor: Wir verfügen über ein standardisiertes, halbautomatisches Designsystem für sehr große Modelle in Industriequalität. Auf der Grundlage dieses Systems können wir eine Reihe neuronaler Netze verwenden Entwerfen der Netzwerkarchitektur sehr großer Modelle. Durchsuchen Sie das System als Grundlage, um die am besten geeignete Netzwerkarchitektur zum Lernen großer Datenmengen zu finden. Beim Entwerfen kleiner Modelle verlassen wir uns hauptsächlich auf manuelles Design, Tuning und Iteration und erhalten schließlich ein Modell mit zufriedenstellenden Ergebnissen. Obwohl dieses Modell nach der Iteration nicht unbedingt optimal ist, kann es grundsätzlich die Anforderungen erfüllen. Da bei großen Modellen die Netzwerkstruktur großer Modelle sehr komplex ist, verbraucht manuelles Design, Tuning und Iteration viel Rechenleistung und die Kosten sind entsprechend hoch. Daher ist es ein Problem, das gelöst werden muss, wie man mit begrenzten Ressourcen schnell und effizient eine Netzwerkarchitektur entwerfen kann, die gut genug für das Training ist. Lucas erklärte, dass wir über eine Reihe von Operatorbibliotheken verfügen und die Netzwerkstruktur des Modells als Anordnung und Kombination dieser Operatorenmenge angesehen werden kann. Dieses industrietaugliche Suchsystem kann berechnen, wie Operatoren angeordnet und kombiniert werden, indem grundlegende Parameter festgelegt werden, darunter die Anzahl der Netzwerkschichten und die Größe der Parameter, um bessere Modelleffekte zu erzielen. Der Modelleffekt kann anhand einiger Kriterien bewertet werden, darunter die Vorhersagegenauigkeit für bestimmte Datensätze, der vom Modell beim Ausführen verwendete Speicher und die für die Modellausführung erforderliche Zeit. Indem wir diesen Metriken entsprechende Gewichtungen zuweisen, können wir so lange iterieren, bis wir ein zufriedenstellendes Modell gefunden haben. Natürlich werden wir in der Suchphase zunächst versuchen, anhand einiger kleiner Szenen zunächst die Wirkung des Modells zu bewerten. Wie wählt man bei der Bewertung des Modelleffekts einige repräsentativere Szenen aus? Generell können Sie einige gängige Szenarien auswählen. Die Netzwerkarchitektur soll hauptsächlich sicherstellen, dass das Modell wichtige Informationen aus einer großen Datenmenge extrahieren kann, und nicht darauf hoffen, dass das Modell die Eigenschaften bestimmter spezifischer Szenarien lernen kann. Das Modell wird verwendet, um einige Aufgaben des Mining von Long-Tail-Szenarien abzuschließen. Bei der Auswahl einer Modellarchitektur werden jedoch allgemeine Szenarien verwendet, um die Fähigkeiten des Modells zu bewerten. Mit einem hocheffizienten und hochpräzisen Suchsystem für neuronale Netze sind die Berechnungseffizienz und die Berechnungsgenauigkeit hoch genug, sodass der Modelleffekt schnell konvergieren kann und eine gute Netzwerkarchitektur schnell in einem riesigen Raum gefunden werden kann . Nachdem die vorherige grundlegende Arbeit erledigt ist, kommen wir zum Trainingslink. Es gibt viele Bereiche, die es wert sind, im Trainingslink optimiert zu werden. 2.3.1 Optimierungsoperator Neuronales Netzwerk kann als Kombination vieler Grundoperatoren verstanden werden. Die Berechnung von Operatoren beansprucht einerseits Rechenressourcen und andererseits Speicher. Wenn der Bediener optimiert werden kann, um die Recheneffizienz des Bedieners zu verbessern, kann die Trainingseffizienz verbessert werden. Es gibt bereits einige KI-Trainings-Frameworks auf dem Markt – wie PyTorch, TensorFlow usw. Diese Trainings-Frameworks können grundlegende Operatoren bereitstellen, die Ingenieure für maschinelles Lernen aufrufen können, um ihre eigenen Modelle zu erstellen. Einige Unternehmen bauen ihren eigenen Schulungsrahmen auf und optimieren die zugrunde liegenden Bediener, um die Schulungseffizienz zu verbessern. PyTorch und TensorFlow müssen größtmögliche Vielseitigkeit gewährleisten, daher sind die bereitgestellten Operatoren im Allgemeinen sehr einfach. Unternehmen können Basisoperatoren entsprechend ihren eigenen Anforderungen integrieren, wodurch die Speicherung von Zwischenergebnissen entfällt, der Speicherverbrauch gespart und Leistungsverluste vermieden werden. Um das Problem zu lösen, dass einige bestimmte Operatoren aufgrund ihrer hohen Abhängigkeit von Zwischenergebnissen während der Berechnung die Parallelität der GPU nicht sinnvoll nutzen können, haben einige Unternehmen in der Branche außerdem eigene Beschleunigungsbibliotheken erstellt Reduzieren Sie den Einfluss dieser Operatoren auf Zwischenergebnisse. Durch die Abhängigkeit der Ergebnisse kann der Berechnungsprozess die Vorteile der parallelen Berechnung der GPU voll ausnutzen und die Trainingsgeschwindigkeit verbessern. Beispielsweise erreichte ByteDances LightSeq bei vier Mainstream-Transformer-Modellen eine bis zu achtfache Beschleunigung basierend auf PyTorch. 2.3.2 Nutzen Sie parallele Strategien sinnvoll Parallelrechnen ist eine Methode zum „Austausch von Raum gegen Zeit“, d in kleine Stapel aufteilen, wodurch die Wartezeit im Leerlauf der GPU in jedem Berechnungsschritt reduziert und der Berechnungsdurchsatz verbessert wird. Derzeit haben viele Unternehmen das PyTorch-Trainings-Framework übernommen. Als verteilter Daten-Parallel-Trainingsmodus entwirft der DDP-Modus einen Datenverteilungsmechanismus zur Unterstützung mehrerer Maschinen und mehrerer Karten Wenn ein Unternehmen beispielsweise über 8 Server verfügt und jeder Server über 8 Karten verfügt, können wir 64 Karten gleichzeitig für Schulungen verwenden. Ohne diesen Modus können Ingenieure nur eine einzige Maschine mit mehreren Karten zum Trainieren des Modells verwenden. Angenommen, wir verwenden jetzt 100.000 Bilddaten, um das Modell zu trainieren. Im Einzelmaschinen-Mehrkartenmodus beträgt die Trainingszeit mehr als eine Woche. Wenn wir die Trainingsergebnisse verwenden möchten, um eine bestimmte Vermutung zu bewerten, oder das beste aus mehreren alternativen Modellen auswählen möchten, führt eine solche Trainingszeit dazu, dass die Wartezeit, die erforderlich ist, um die Vermutung schnell zu überprüfen und den Modelleffekt schnell zu testen, sehr lang wird. Dann wird die F&E-Effizienz sehr gering sein. Beim parallelen Training mit mehreren Maschinen und mehreren Karten sind die meisten experimentellen Ergebnisse in 2-3 Tagen sichtbar. Auf diese Weise ist der Prozess der Überprüfung des Modelleffekts viel schneller. In Bezug auf spezifische Parallelmethoden können hauptsächlich Modellparallelität und Sequenzparallelität verwendet werden. Modellparallelität kann in Pipeline-Parallelität und Tensor-Parallelität unterteilt werden, wie in der folgenden Abbildung dargestellt. Schematisches Diagramm der Pipeline-Parallelität und Tensor-Parallelität, Bild von NVIDIA Pipeline-Parallelität ist auch Zwischenschicht-Parallelität (oberer Teil des Bildes). Trainingsprozess Verschiedene Schichten werden zur Berechnung in verschiedene GPUs unterteilt. Wie in der oberen Hälfte der Abbildung gezeigt, können beispielsweise der grüne Teil der Ebene und der blaue Teil auf verschiedenen GPUs berechnet werden. Tensor-Parallelität ist Intra-Layer-Parallelität (unterer Teil des Bildes). Ingenieure können die Berechnung einer Schicht auf verschiedene GPUs aufteilen. Dieser Modus eignet sich für die Berechnung großer Matrizen, da er einen Lastausgleich zwischen GPUs erreichen kann, die Anzahl der Kommunikationen und die Datenmenge jedoch relativ groß sind. Zusätzlich zur Modellparallelität gibt es auch Sequenzparallelität. Da die Tensorparallelität Layer-Norm und Dropout nicht aufteilt, werden diese beiden Operatoren wiederholt zwischen jeder GPU berechnet, obwohl der Berechnungsaufwand nicht groß ist, aber dauert Dadurch wird viel aktiver Videospeicher frei. Um dieses Problem zu lösen, können wir im eigentlichen Prozess die Tatsache ausnutzen, dass Layer-Norm und Dropout entlang der Dimensionen der Sequenz unabhängig voneinander sind (d. h. Layer_norm und Dropout zwischen verschiedenen Ebenen). beeinflussen sich nicht gegenseitig), teilen Sie Layer-Norm und Dropout auf, wie in der Abbildung unten gezeigt. Der Vorteil dieser Aufteilung besteht darin, dass sie das Kommunikationsvolumen nicht erhöht und die Speichernutzung erheblich reduzieren kann. Im traditionellen autoseitigen Wahrnehmungsmodell führen die Modelle, die verschiedene Teilaufgaben bearbeiten, unabhängig voneinander Schlussfolgerungen durch. Beispielsweise ist ein Modell für die Fahrspurerkennungsaufgabe und ein anderes Modell für die Ampelerkennungsaufgabe verantwortlich. Mit zunehmenden Wahrnehmungsaufgaben werden Ingenieure dem System entsprechend Modelle zur Wahrnehmung spezifischer Ziele hinzufügen.
Um die Fähigkeiten großer Modelle in der Praxis voll auszuschöpfen, sind die technischen Fähigkeiten des Unternehmens sehr wichtig. Als nächstes erklären wir, welche technischen Fähigkeiten erforderlich sind, um große Modelle entsprechend dem Modellentwicklungsprozess sinnvoll zu nutzen.
Wie speichert man also zig Milliarden oder sogar Hunderte Milliarden Bilddaten? Dies stellt sowohl für Dateilesesysteme als auch für Datenspeichersysteme eine große Herausforderung dar. Insbesondere liegen die aktuellen autonomen Fahrdaten in Form von Clips vor und die Anzahl der Dateien ist groß, was eine hohe Effizienz bei der sofortigen Speicherung kleiner Dateien erfordert.
2.2 Finden Sie effizient die geeignete Netzwerkarchitektur
2.3 Effizienz des Modelltrainings verbessern
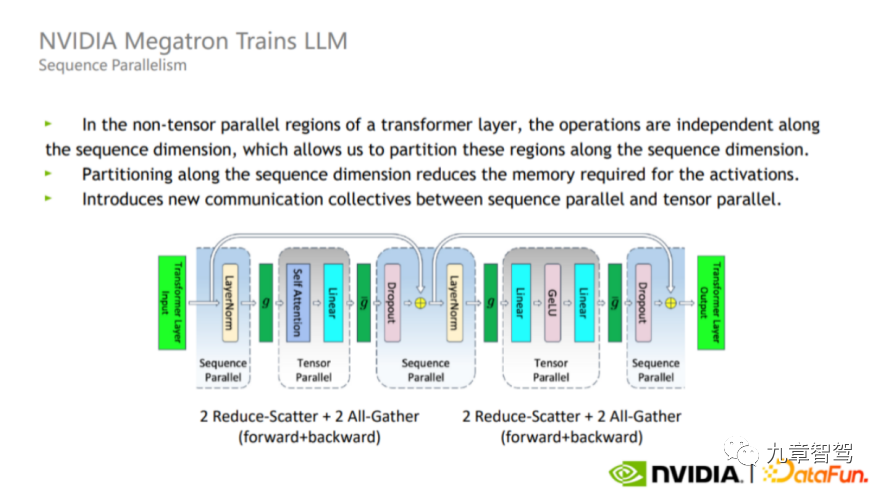
Sequenzparalleles schematisches Diagramm, Bild von NVIDIA
In der Praxis müssen verschiedene Modelle unterschiedliche Parallelstrategien berücksichtigen. Neben dem Zwischenberechnungsprozess sollten Sie auch mit dem Debuggen fortfahren, bevor Sie eine geeignete Parallelstrategie finden.
2.3.3 Nutzen Sie die „sparse“-Eigenschaft sinnvoll aus
Beim Training des Modells müssen Sie auch die Sparsity gut nutzen, das heißt, nicht jedes Neuron muss „aktiviert“ werden – das heißt, beim Hinzufügen von Trainingsdaten muss nicht jeder Modellparameter auf den neu hinzugefügten Daten basieren , aber einige Modellparameter bleiben unverändert und einige Modellparameter werden mit neu hinzugefügten Daten aktualisiert.
Eine gute, spärliche Verarbeitung kann die Genauigkeit gewährleisten und gleichzeitig die Effizienz des Modelltrainings verbessern.
Wenn beispielsweise in einer Wahrnehmungsaufgabe neue Bilder eingegeben werden, können Sie die Parameter auswählen, die basierend auf diesen Bildern aktualisiert werden müssen, um eine gezielte Merkmalsextraktion durchzuführen.
2.3.4 Einheitliche Verarbeitung grundlegender Informationen
Im Allgemeinen wird mehr als ein Modell innerhalb des Unternehmens verwendet, und diese Modelle verwenden möglicherweise dieselben Daten. Beispielsweise werden die meisten Modelle verwendet Videodaten. Wenn jedes Modell Videodaten lädt und verarbeitet, werden viele Berechnungen wiederholt. Wir können verschiedene modale Informationen wie Videos, Punktwolken, Karten und CAN-Signale, die die meisten Modelle verwenden müssen, einheitlich verarbeiten, sodass verschiedene Modelle die Verarbeitungsergebnisse wiederverwenden können.
2.3.5 Hardwarekonfiguration optimieren
Beim tatsächlichen Einsatz des verteilten Trainings können 1.000 Maschinen verwendet werden, um während des Trainingsprozesses Zwischenergebnisse von verschiedenen Servern zu erhalten, die Daten speichern , Gradient und dann ein sehr umfangreiches verteiltes Training durchzuführen, ist eine große Herausforderung.
Um diese Herausforderung zu bewältigen, müssen Sie zunächst überlegen, wie Sie CPU, GPU usw. konfigurieren, wie Sie die Netzwerkkarte auswählen und wie schnell die Netzwerkkarte sein darf, damit die Übertragung zwischen Maschinen schnell erfolgen kann .
Zweitens ist es notwendig, Parameter zu synchronisieren und Zwischenergebnisse zu speichern. Wenn der Maßstab jedoch groß ist, wird diese Angelegenheit sehr schwierig und erfordert einige Netzwerkkommunikationsarbeiten.
Darüber hinaus dauert der gesamte Trainingsprozess lange, sodass die Stabilität des Clusters sehr hoch sein muss.
03
Ist es sinnvoll, die Modellparameter weiter zu erhöhen?
Da große Modelle bereits eine gewisse Rolle im Bereich des autonomen Fahrens spielen können, können wir, wenn wir die Modellparameter weiter erhöhen, mit großen Modellen rechnen kann einige erstaunliche Ergebnisse zeigen. Effektiv?
Laut der Kommunikation des Autors mit Algorithmenexperten im Bereich des autonomen Fahrens lautet die aktuelle Antwort wahrscheinlich nein, da das oben erwähnte „Emergenz“-Phänomen im Bereich CV (Computer Vision) noch nicht aufgetreten ist. Derzeit ist die Anzahl der im Bereich des autonomen Fahrens verwendeten Modellparameter deutlich geringer als bei ChatGPT. Denn wenn es keinen „Emergenz“-Effekt gibt, besteht ein ungefähr linearer Zusammenhang zwischen der Verbesserung der Modellleistung und der Erhöhung der Anzahl der Parameter. Unter Berücksichtigung von Kostenbeschränkungen haben Unternehmen die Anzahl der Parameter im Modell noch nicht maximiert.
Warum ist das „Emergenz“-Phänomen im Bereich Computer Vision noch nicht aufgetreten? Die Erklärung eines Experten lautet:
Erstens: Obwohl es auf der Welt weit mehr visuelle Daten als Textdaten gibt, sind Bilddaten spärlich, das heißt, die meisten Fotos und jedes Foto enthalten möglicherweise nicht viele effektive Informationen Pixel im Bild liefern keine nützlichen Informationen. Wenn wir ein Selfie machen, gibt es bis auf das Gesicht in der Mitte keine gültigen Informationen im Hintergrundbereich.
Zweitens weisen die Bilddaten erhebliche Maßstabsveränderungen auf und sind völlig unstrukturiert. Eine Maßstabsänderung bedeutet, dass Objekte mit derselben Semantik im entsprechenden Bild groß oder klein sein können. Ich mache zum Beispiel zuerst ein Selfie und bitte dann einen weit entfernten Freund, ein weiteres Foto für mich zu machen. Auf den beiden Fotos sind die Proportionen des Gesichts auf dem Foto sehr unterschiedlich. Unstrukturiert bedeutet, dass die Beziehung zwischen den einzelnen Pixeln ungewiss ist.
Aber im Bereich der Verarbeitung natürlicher Sprache sind Kontexte normalerweise miteinander verbunden, da Sprache ein Werkzeug für die Kommunikation zwischen Menschen ist und die Informationsdichte jedes Satzes im Allgemeinen groß ist und es kein Problem mit Skalenänderungen gibt Beispielsweise ist das Wort „Apfel“ in jeder Sprache normalerweise nicht zu lang.
Daher wird das Verständnis visueller Daten selbst schwieriger sein als das Verständnis natürlicher Sprache.
Ein Branchenexperte sagte dem Autor: Obwohl wir davon ausgehen können, dass sich die Leistung des Modells mit zunehmender Anzahl von Parametern verbessert, ist die derzeitige Kosteneffizienz einer weiteren Erhöhung der Anzahl von Parametern gering.
Wenn wir beispielsweise die Kapazität des Modells auf der bestehenden Basis um das Zehnfache erweitern, kann seine relative Fehlerrate um 90 % reduziert werden. Zu diesem Zeitpunkt kann das Modell bereits einige Computer-Vision-Aufgaben wie die Gesichtserkennung ausführen. Wenn wir die Kapazität des Modells zu diesem Zeitpunkt weiterhin um das Zehnfache erweitern und die relative Fehlerrate weiterhin um 90 % sinkt, sich der erreichbare Wert jedoch nicht um das Zehnfache erhöht, besteht für uns keine Notwendigkeit, weiter zu erweitern die Kapazität des Modells.
Durch die Erweiterung der Modellkapazität steigen die Kosten, da größere Modelle mehr Trainingsdaten und mehr Rechenleistung erfordern. Wenn die Genauigkeit des Modells einen akzeptablen Bereich erreicht, müssen wir einen Kompromiss zwischen steigenden Kosten und verbesserter Genauigkeit eingehen und die Kosten bei akzeptabler Genauigkeit entsprechend den tatsächlichen Anforderungen so weit wie möglich senken.
Obwohl es noch einige Aufgaben gibt, die wir zur Verbesserung der Genauigkeit benötigen, ersetzen große Modelle hauptsächlich einige manuelle Arbeiten in der Cloud, wie automatische Annotation, Data Mining usw., die von Menschen erledigt werden können. Wenn die Kosten zu hoch sind, wird die Volkswirtschaftliche Gesamtrechnung nicht berechnet.
Aber einige Branchenexperten sagten dem Autor: Obwohl es noch keinen qualitativen Änderungspunkt erreicht hat, können wir mit zunehmenden Parametern des Modells und zunehmender Datenmenge tatsächlich beobachten, dass sich die Genauigkeit des Modells verbessert hat . Wenn die Genauigkeit des für die Etikettierungsaufgabe verwendeten Modells hoch genug ist, wird der Grad der automatisierten Etikettierung verbessert und dadurch die Arbeitskosten erheblich gesenkt. Obwohl die Trainingskosten derzeit mit zunehmender Modellgröße steigen, hängen die Kosten in etwa linear von der Anzahl der Modellparameter ab. Obwohl die Schulungskosten steigen werden, kann der Personalabbau diesen Anstieg ausgleichen, so dass eine Erhöhung der Parameterzahl immer noch Vorteile bringt.
Darüber hinaus werden wir auch einige Techniken verwenden, um die Anzahl der Modellparameter zu erhöhen und gleichzeitig die Trainingseffizienz zu verbessern, um die Trainingskosten zu minimieren. Wir können die Anzahl der Parameter des Modells erhöhen und die Genauigkeit des Modells verbessern, während wir gleichzeitig die Kosten innerhalb des bestehenden Modellmaßstabs konstant halten. Dies ist gleichbedeutend damit, dass die Kosten des Modells nicht linear mit der Anzahl der Modellparameter steigen. Wir können fast keine oder nur eine geringe Kostensteigerung erzielen.
04
Andere mögliche Anwendungen großer Modelle
Wie können wir zusätzlich zu den oben genannten Anwendungen den Wert großer Modelle erkunden? 4.1 Auf dem Gebiet der Wahrnehmung . Wenn das gesamte Modell keine interne Schleife oder kein kontinuierliches Online-Training erreichen kann, ist es schwierig, gute Ergebnisse zu erzielen.
Wie implementiert man also die „innere Schleife“ des Modells? Wir können uns auf das Trainingsframework von ChatGPT beziehen, wie in der folgenden Abbildung dargestellt.
ChatGPT-Trainingsframework, das Bild stammt von der offiziellen Website von Open AI
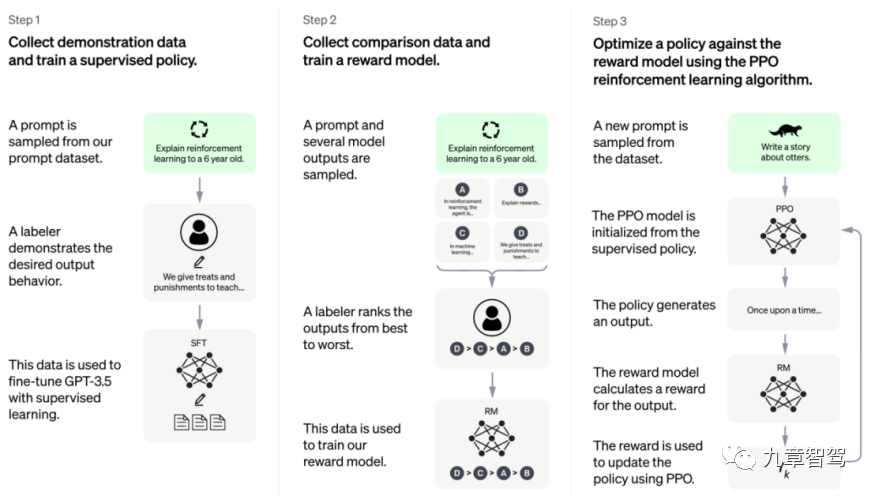
Solange der dritte Schritt erreicht ist, müssen die Ingenieure keine beschrifteten Daten mehr hinzufügen, sondern können den Verlust nach Erhalt der unbeschrifteten Daten selbst berechnen und dann die Parameter aktualisieren Die Ausbildung ist endlich abgeschlossen.
„Wenn wir bei der Durchführung von Wahrnehmungsaufgaben eine geeignete Belohnungsrichtlinie entwerfen können, sodass das Modelltraining nicht mehr auf gekennzeichneten Daten basiert, können wir sagen, dass das Modell eine „innere Schleife“ erreicht hat und basierend auf nicht gekennzeichneten Daten kontinuierlich aktualisiert werden kann . Parameter.“
4.2 Im Bereich Planung
In Bereichen wie Go ist es einfacher, die Qualität jedes einzelnen Schritts zu beurteilen, da unser Ziel in der Regel nur darin besteht, am Ende das Spiel zu gewinnen.
Allerdings ist im Bereich der autonomen Fahrplanung das Bewertungssystem für das vom autonomen Fahrsystem angezeigte Verhalten unklar. Neben der Gewährleistung der Sicherheit hat jeder unterschiedliche Vorstellungen von Komfort und möchte vielleicht auch so schnell wie möglich ans Ziel kommen.
Um in die Chat-Szene zu wechseln, ist es eigentlich kein sehr klares Bewertungssystem wie Go, ob das Feedback, das der Roboter jedes Mal gibt, „gut“ oder „schlecht“ ist. Ähnlich verhält es sich mit dem autonomen Fahren: Jeder Mensch hat unterschiedliche Vorstellungen davon, was „gut“ und „schlecht“ ist, und er oder sie hat möglicherweise Bedürfnisse, die schwer zu artikulieren sind.
Im zweiten Schritt des ChatGPT-Trainingsframeworks sortiert der Annotator die vom Modell ausgegebenen Ergebnisse und verwendet dieses sortierte Ergebnis dann zum Trainieren des Belohnungsmodells. Am Anfang ist dieses Belohnungsmodell nicht perfekt, aber durch kontinuierliches Training können wir dafür sorgen, dass dieses Belohnungsmodell weiterhin den gewünschten Effekt erzielt.
Ein Experte eines Unternehmens für künstliche Intelligenz sagte dem Autor: Im Bereich der autonomen Fahrplanung können wir kontinuierlich Daten zum Autofahren sammeln und dem Modell dann mitteilen, unter welchen Umständen Menschen übernehmen werden (das heißt, Menschen werden). Wenn Sie das Gefühl haben, dass eine Gefahr besteht) ), unter welchen Umständen es normal fahren kann, wird das Belohnungsmodell mit zunehmender Datenmenge der Perfektion immer näher kommen.
Mit anderen Worten, wir können darüber nachdenken, das explizite Schreiben eines perfekten Belohnungsmodells aufzugeben und stattdessen eine Lösung zu erhalten, die sich ständig der Perfektion nähert, indem wir dem Modell kontinuierlich Feedback geben.
Verglichen mit der derzeit gängigen Praxis im Planungsbereich, bei der versucht wird, explizit die optimale Lösung zu finden, indem man sich auf manuelle Schreibregeln verlässt, ist die Methode, zunächst ein anfängliches Belohnungsmodell zu verwenden und dann kontinuierlich auf Datenbasis zu optimieren ein Paradigmenwechsel.
Nach der Einführung dieser Methode kann das Optimierungsplanungsmodul einen relativ standardmäßigen Prozess übernehmen. Wir müssen lediglich kontinuierlich Daten sammeln und dann das Belohnungsmodell trainieren. Es ist nicht mehr auf die Steuerung des gesamten Prozesses angewiesen wie die traditionelle Methode. Tiefes Verständnis des Planungsmoduls.
Darüber hinaus können alle historischen Daten für das Training verwendet werden. Nach einer bestimmten Regeländerung müssen wir uns darüber keine Sorgen machen, obwohl einige aktuelle Probleme gelöst sind, werden einige Probleme, die zuvor gelöst wurden, wieder auftreten Methoden, wir könnten von diesem Problem beunruhigt sein.
Das obige ist der detaillierte Inhalt vonEin langer Artikel mit 10.000 Wörtern erläutert die Anwendung großer Modelle im Bereich des autonomen Fahrens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
