
 Betrieb und Instandhaltung
Nginx
Fünf Minuten technischer Spaß |. Eine kurze Analyse der hierarchischen Regeln der Linux-Cgroup
Betrieb und Instandhaltung
Nginx
Fünf Minuten technischer Spaß |. Eine kurze Analyse der hierarchischen Regeln der Linux-Cgroup
Fünf Minuten technischer Spaß |. Eine kurze Analyse der hierarchischen Regeln der Linux-Cgroup


Teil 01 cgroup-Übersicht
cgroup ist die Abkürzung für Control Groups. Dabei handelt es sich um eine Art physische Ressourcen (z. B. CPU, Speicher, Geräte-E/A), die vom Linux-Kernel bereitgestellt werden können Prozesse oder Prozessgruppen usw. steuern) Mechanismen zur Einschränkung, Isolation und Statistik. Die Benutzerraumverwaltung von cgroup wird über das cgroup-Dateisystem realisiert. Dank des virtuellen Dateisystems von Linux werden die Details des Dateisystems ausgeblendet, und der Benutzer erkennt die Verwendung dieser Funktion über die relevanten Steuerdateien.
cgroup wurde von Google während der 2.6-Kernel-Periode eingeführt. Es ist die technische Grundlage für die Ressourcenvirtualisierung im Linux-Kernel und der technische Eckpfeiler von LXC (Linux Containers) und Docker-Containern. Es gibt die folgenden verwandten Konzepte in cgroup:
- Aufgabe: Ein Alias für den Prozess;
- Kontrollgruppe: Folgen Sie einem bestimmten A-Satz von Prozessen geteilt durch einen Standard. Die Ressourcenkontrolle in Cgroup wird in Einheiten von Kontrollgruppen implementiert. Ein Prozess kann einer Kontrollgruppe hinzugefügt oder von einer Prozessgruppe in eine andere migriert werden. Prozesse in einer Prozessgruppe können von cgroups zugewiesene Ressourcen in Einheiten von Kontrollgruppen nutzen und unterliegen Ressourcenbeschränkungen, die von cgroup in Einheiten von Kontrollgruppen festgelegt werden.
- Hierarchie: Die hierarchische Beziehung der Kontrollgruppe ist in einer Baumstruktur organisiert. Die Kontrollgruppe des untergeordneten Knotens erbt die Ressourceneinstellungsattribute des übergeordneten Knotens.
- Subsystem (Subsystem): Ein Subsystem ist ein Ressourcencontroller. Beispielsweise kann das CPU-Subsystem die CPU-Nutzungszeitzuteilung steuern, wie in Abbildung 1 dargestellt. Um zu funktionieren, muss ein Subsystem einer Ebene zugeordnet werden. Nachdem ein Subsystem einer bestimmten Ebene zugeordnet wurde, werden alle Kontrollgruppen auf dieser Ebene von diesem Subsystem gesteuert.
Teil 02 cgroup-Subsystem
Das. Subsystem hängt mit der Kernel-Version zusammen, die Ressourcen, die vorhanden sein können begrenzt Es gibt auch immer mehr, im Allgemeinen einschließlich der folgenden Subsysteme.
➤ blkio: Legen Sie Beschränkungen für den Eingabe-/Ausgabezugriff fest, um Geräte wie physische Geräte (Festplatte, SSD, USB usw.) zu blockieren.
➤ CPU: Begrenzen Sie die CPU-Nutzung des Prozesses, einschließlich der Zuweisung von CPU-Zeitscheiben.
➤ cpuacct: Automatisch einen CPU-Bericht generieren, der von Aufgaben in der cgroup verwendet wird.
➤ cpuset: Unabhängige CPU (Multi-Core-System) und Speicherknoten den Aufgaben in der cgroup zuweisen.
➤ Geräte: Zulassen oder verweigern, dass Aufgaben in der Kontrollgruppe auf das Gerät zugreifen.
➤ Freezer: Aufgaben in einer Gruppe aussetzen oder fortsetzen.
➤ Speicher: Legen Sie das von Aufgaben in einer Kontrollgruppe verwendete Speicherlimit fest und erstellen Sie automatisch einen Bericht über die von diesen Aufgaben verwendeten Speicherressourcen.
➤ net_cls: Durch das Markieren von Netzwerkpaketen mit Klassenkennungen kann das Linux-Wanderkontrollprogramm Pakete identifizieren, die von bestimmten Kontrollgruppen generiert wurden.
➤ ns: Namespace-Subsystem.
Teil 03 cgroup-Hierarchieregeln
In Kombination mit der cgroup-Hierarchie kann es als Baum verstanden werden. Jeder Knoten des Baums ist eine Prozessgruppe, und jeder Baum wird es sein verbunden mit mehreren Subsystemen. In einem Baum werden alle Prozesse im Linux-System enthalten, aber jeder Prozess kann nur zu einem Knoten (Prozessgruppe) gehören. Es kann viele Kontrollgruppenbäume im System geben, und jeder Baum ist einem anderen Subsystem zugeordnet. Ein Prozess kann mehreren Bäumen angehören, das heißt, ein Prozess kann mehreren Prozessgruppen angehören, diese Prozessgruppen sind jedoch unterschiedlichen Subsystemen zugeordnet. Derzeit kann Linux bis zu zwölf Cgroup-Bäume erstellen, und jeder Baum ist einem Subsystem zugeordnet. Natürlich können Sie auch nur einen Baum erstellen und diesen Baum dann allen Subsystemen zuordnen. Wenn ein cgroup-Baum keinem Subsystem zugeordnet ist, bedeutet dies, dass der Baum nur Prozesse gruppiert, die auf der Gruppierung basieren. Systemd ist ein solches Beispiel.
Es gibt vier Zusammensetzungsregeln für die Hierarchie, die wie folgt beschrieben werden:
Regel 1: Eine einzelne Hierarchie kann ein oder mehrere Subsysteme haben. Wie in Abbildung 1 dargestellt, richtet die Ebene /cpu_memory_cg zwei Subsysteme ein, CPU und Speicher, für cgroup1 und cgroup2.
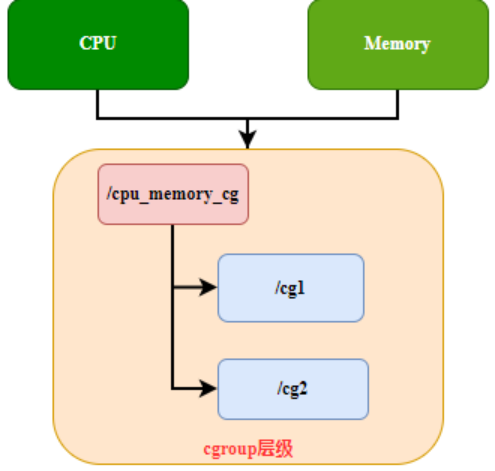
Abbildung 1 Hierarchieregel 1
Regel 2: Wenn ein Subsystem bereits einer Ebene zugeordnet ist, kann es nicht der Struktur einer anderen Ebene zugeordnet werden. Wie in Abbildung 2 dargestellt, verwaltet cpu_cg auf Ebene A zunächst das CPU-Subsystem, dann kann cpu_mem_cg auf Ebene B das CPU-Subsystem nicht verwalten.
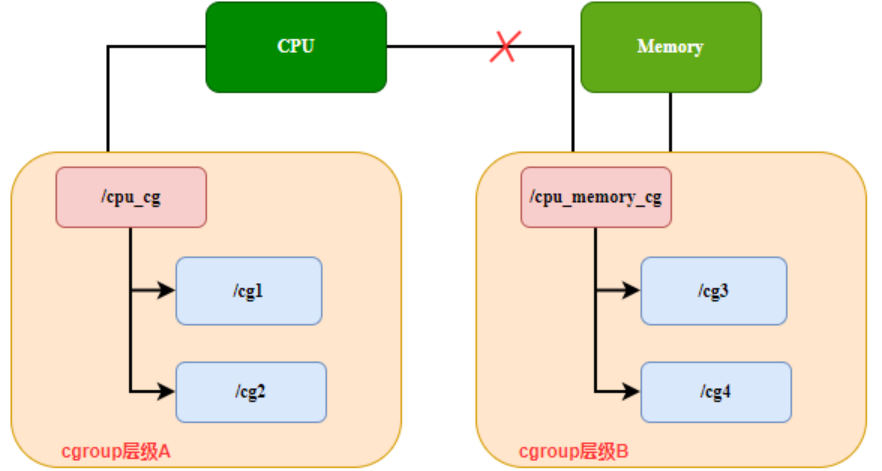
Abbildung 2 Gruppenhierarchieregel 2
Regel 3: Jedes Mal, wenn eine neue Hierarchie auf einem System erstellt wird, sind alle Aufgaben auf dem System zunächst Mitglieder der Standard-Kontrollgruppe dieser Hierarchie (die sogenannte Stamm-Kontrollgruppe). Für jede einzelne erstellte Hierarchie kann jede Aufgabe im System ein Kontrollgruppenmitglied in dieser Hierarchie sein. Eine Aufgabe kann in mehreren Kontrollgruppen enthalten sein, solange sich jede dieser Kontrollgruppen in einer anderen Subsystemhierarchie befindet. Sobald eine Aufgabe Mitglied der zweiten Kontrollgruppe in derselben Hierarchie wird, wird sie aus der ersten Kontrollgruppe in der Hierarchie gelöscht. Das heißt, dass zwei verschiedene Kontrollgruppen in derselben Hierarchie niemals dieselbe Aufgabe haben kann nur eine Möglichkeit sein, einen bestimmten Typ von Cgroup-Subsystem für einen bestimmten Prozess einzuschränken. Wenn Sie die erste Hierarchie erstellen, ist jede Aufgabe im System Mitglied von mindestens einer Kontrollgruppe (der Stammkontrollgruppe). Wenn Sie also Kontrollgruppen verwenden, befindet sich jede Systemaufgabe immer in mindestens einer Kontrollgruppe, wie in Abbildung 3 dargestellt.
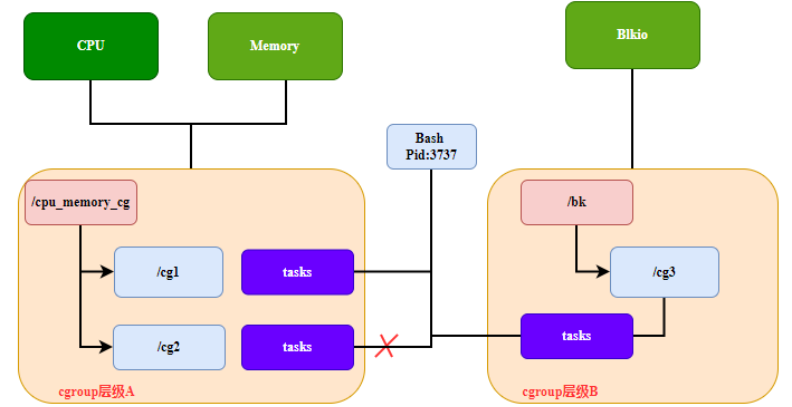
Abbildung 3 cgroup-Hierarchie, Regel 3
Regel 4: Jeder auf dem System gegabelte Prozess erstellt einen untergeordneten Prozess (oder Thread). Der untergeordnete Prozess erbt automatisch die Kontrollgruppenmitgliedschaft seines übergeordneten Prozesses, kann jedoch bei Bedarf in andere Kontrollgruppen verschoben werden. Nach dem Verschieben sind der übergeordnete und untergeordnete Prozess völlig unabhängig, wie in Abbildung 4 dargestellt.
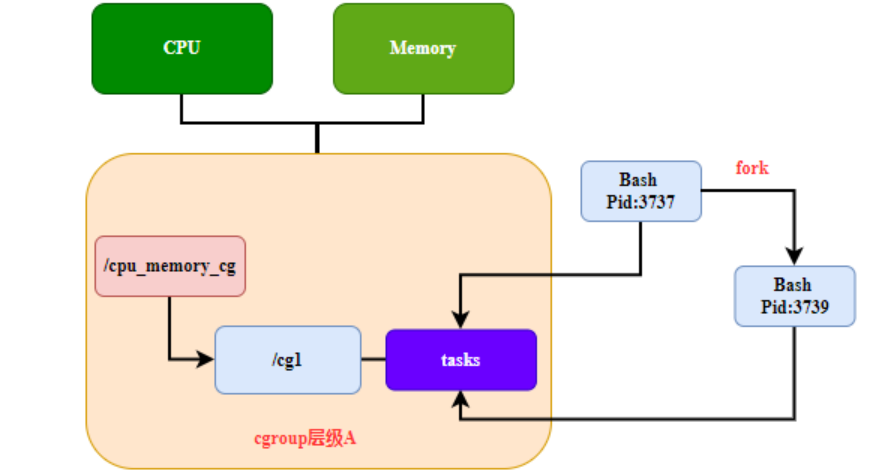
Abbildung 4 cgroup-Hierarchieregel 4
Teil 04cgroup-Hierarchie-Beziehungsanalyse
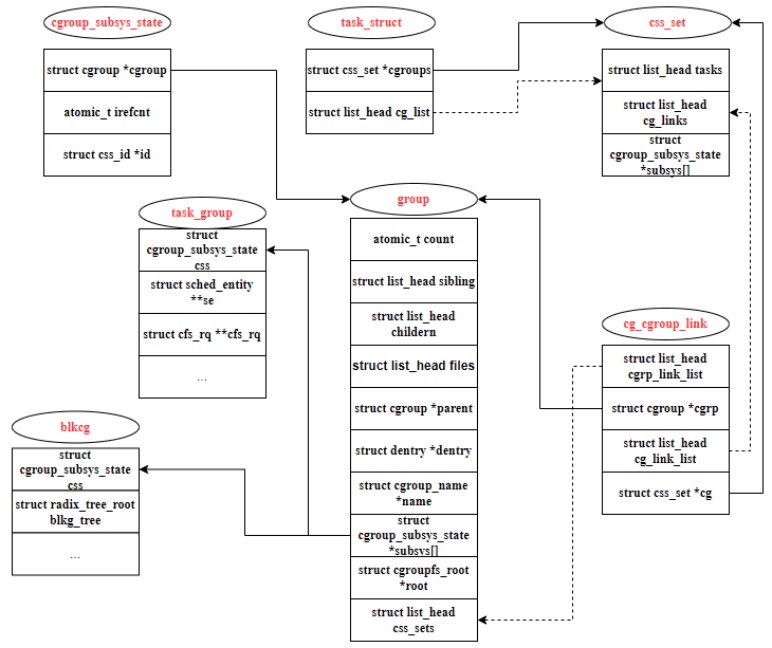
Wir beginnen aus der Perspektive des Prozesses und kombinieren Die Datenstruktur im Quellcode wird verwendet, um die Beziehung zwischen cgroups-bezogenen Daten zu analysieren. Erstens ist unter Linux die Datenstruktur zum Verwalten von Prozessen task_struct, in der die mit cgroups verbundenen Mitglieder wie folgt lauten: Hier werden prozessbezogene Cgroup-Informationen gespeichert. cg_list ist eine prozessverknüpfte Liste, die dasselbe css_set verwendet. Die css_set-Struktur lautet wie folgt:
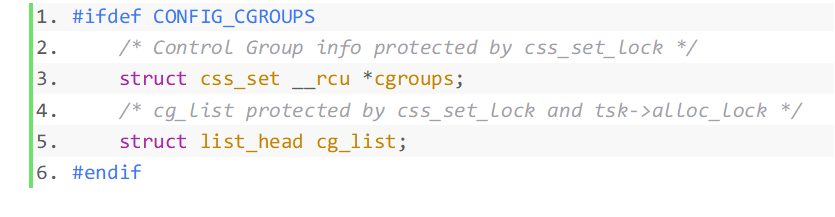
Die Elementinformationen der Struktur werden wie folgt erklärt:
refcount ist der Referenzzähler von. css _set, was kann von mehreren Prozessen gemeinsam genutzt werden, solange die cgroups-Informationen dieser Prozesse gleich sind. Beispielsweise Prozesse in derselben Kontrollgruppe in allen erstellten Hierarchien. 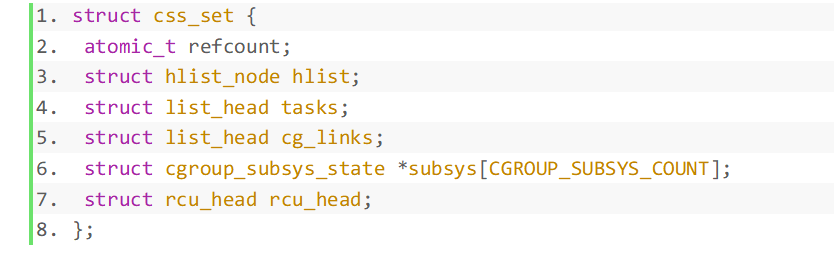
hlist wird verwendet, um alle CSS-Sets in einer Hash-Tabelle zusammenzustellen, und der Kernel kann schnell bestimmte CSS-Sets finden.
- tasks verknüpft alle Prozesse, die auf dieses css_set verweisen, in einer verknüpften Liste.
- cg_links zeigt auf eine verknüpfte Liste, die aus der Struktur cg_group_link besteht.
- subsys ist ein Zeiger-Array, das eine Reihe von Zeigern auf cgroup_subsys_state speichert. Ein cgroup_subsys_state ist eine Information, die sich auf einen Prozess und ein bestimmtes Subsystem bezieht. Über diesen Zeiger kann der Prozess die entsprechenden Kontrollinformationen der Kontrollgruppe abrufen.
- Als nächstes werfen wir einen Blick auf die cgroup_subsys_state-Struktur:

Der cgroup-Zeiger in der Struktur wird durch die Ressourcen des Subsystems gesteuert. Dies wird tatsächlich durch den Beitritt zu einem bestimmten cgroup-Subsystem erreicht einer bestimmten Ebene sind Subsysteme zugeordnet.
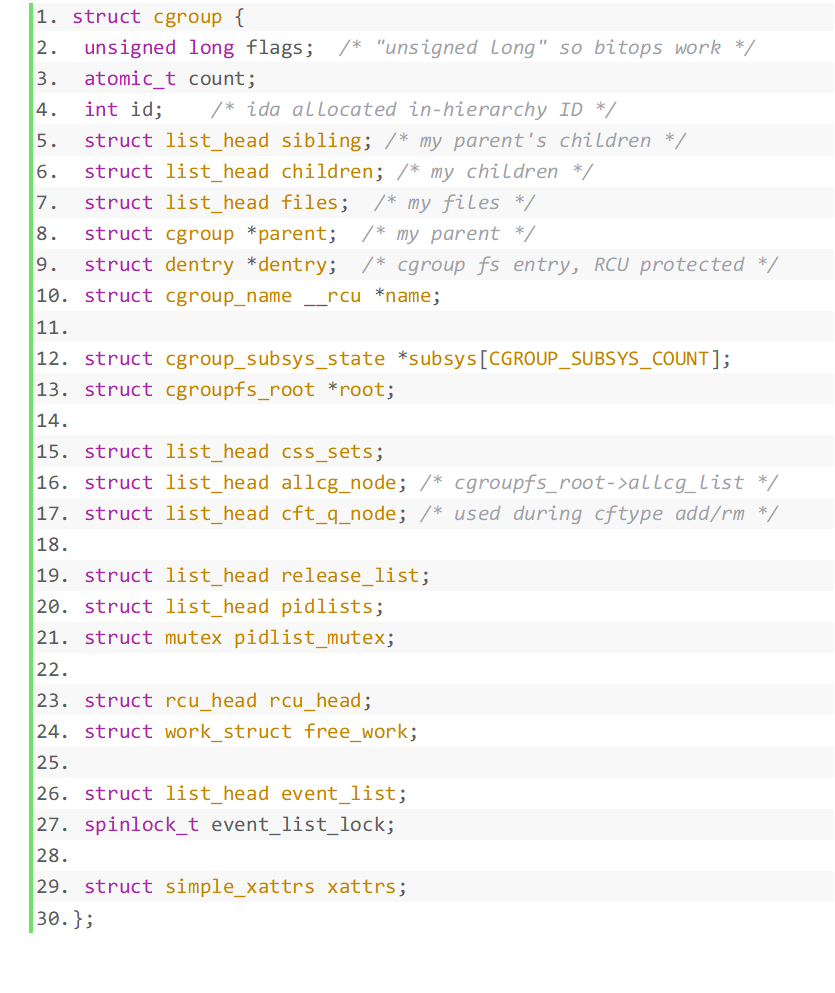
Werfen wir einen Blick auf die Struktur der Kontrollgruppe.
- Geschwister, Kinder und Eltern sind drei verknüpfte Listen, die für die Verbindung von Kontrollgruppen auf derselben Ebene in einem Baum verantwortlich sind.
- susys ist das zuvor beschriebene Subsystem-Zeiger-Array.
- root zeigt auf eine cgroupfs_root-Struktur, bei der es sich um die Struktur handelt, die der Ebene entspricht, auf der sich die cgroup befindet.
- root->top_cgroup zeigt auf die Root-Cgroup der aktuellen Ebene, bei der es sich um die automatisch auf der Fantasy Sword-Ebene erstellte Cgroup handelt. Sie können die Stammkontrollgruppe der Hierarchie über cgroup->root->top_cgroup abrufen.
- css_sets verweist auf eine verknüpfte Liste von cg_cgroup_link, die mit cg_links in css_set übereinstimmt.
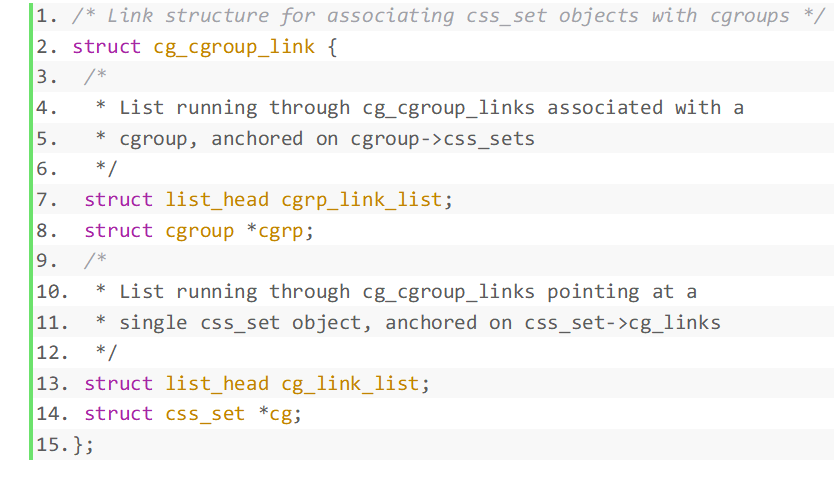
Um die Beziehung zwischen css_set und cgroup zu klären, müssen wir auch die cg_cgroup_link-Struktur der mittleren Ebene analysieren. Die Strukturdaten lauten wie folgt:
Die Daten in der Struktur werden wie folgt beschrieben:
cgrp_link_list ist mit der verknüpften Liste verknüpft, auf die cgroup->css_sets verweist.
cgrp verweist auf die Gruppe, die mit diesem cg_cgroup_link verknüpft ist.
cg_link_list ist mit der verknüpften Liste verknüpft, auf die css_set->cg_links verweist.
cg verweist auf das css_set, das sich auf cg_cgroup_link bezieht.
Es ist ersichtlich, dass cgroup und css_set tatsächlich eine Viele-zu-Viele-Beziehung sind, um die beiden Elemente cgrp und cg zu kombinieren Die verknüpften Listen von cgrp_link_list und cg_link_list sind die angehängten cgroup- und css_set-Entitäten, um die Abfrage zu erleichtern.
Aus den hierarchischen Regeln von cgroup geht hervor, dass eine Gruppe von Prozessen zu cgroups gehören kann, die sich nicht auf derselben Ebene befinden. Zusammengenommen speichert ein css_set Informationen zu jedem Subsystem einer Gruppe von Prozesswurzeln . Das Subsystem stammt aus verschiedenen cgroup-Ebenen, sodass der in einem css_set gespeicherte cgroup_subsys_state mehreren cgroups entsprechen kann. Andererseits speichert die cgroup-Ebene auch einen Satz von cgroup_subsys_state, der von dem Subsystem abgerufen wird, das der Ebene zugeordnet ist, auf der sich die cgroup befindet. Eine cgroup kann mehrere Prozesse haben, und der css_set des Prozesses ist nicht unbedingt derselbe. Da der Prozess möglicherweise mehrere Ebenen verwendet, muss eine cgroup auch mehreren css_sets entsprechen. Abbildung 5 beschreibt die Viele-zu-Viele-Hooking-Beziehung im Detail.
Abbildung 5 Prozess- und Gruppen-Viele-zu-Viele-Beziehungsdiagramm
Teil 05 Fazit
Basierend auf dem Konzept der cgroup zerlegt dieser Artikel die Viele-zu-Viele-Beziehung zwischen ihr und dem Prozess und analysiert sie anhand der Verknüpfung von Variablen in den relevanten Die spezifische Code-Implementierung soll den Lesern helfen, die hierarchische Beziehung und Verwendung von cgroups besser zu verstehen.

Das obige ist der detaillierte Inhalt vonFünf Minuten technischer Spaß |. Eine kurze Analyse der hierarchischen Regeln der Linux-Cgroup. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Wenn der Port -80 -Port der Apache 80 besetzt ist, lautet die Lösung wie folgt: Finden Sie den Prozess, der den Port einnimmt, und schließen Sie ihn. Überprüfen Sie die Firewall -Einstellungen, um sicherzustellen, dass Apache nicht blockiert ist. Wenn die obige Methode nicht funktioniert, konfigurieren Sie Apache bitte so, dass Sie einen anderen Port verwenden. Starten Sie den Apache -Dienst neu.
 So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
In diesem Artikel wird beschrieben, wie die SSL -Leistung von NGINX -Servern auf Debian -Systemen effektiv überwacht wird. Wir werden Nginxexporter verwenden, um Nginx -Statusdaten in Prometheus zu exportieren und sie dann visuell über Grafana anzeigen. Schritt 1: Konfigurieren von Nginx Erstens müssen wir das Modul stub_status in der nginx -Konfigurationsdatei aktivieren, um die Statusinformationen von Nginx zu erhalten. Fügen Sie das folgende Snippet in Ihre Nginx -Konfigurationsdatei hinzu (normalerweise in /etc/nginx/nginx.conf oder deren inklusive Datei): location/nginx_status {stub_status
 So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
In diesem Artikel werden zwei Methoden zur Konfiguration eines Recycling -Bin in einem Debian -System eingeführt: eine grafische Schnittstelle und eine Befehlszeile. Methode 1: Verwenden Sie die grafische Schnittstelle Nautilus, um den Dateimanager zu öffnen: Suchen und starten Sie den Nautilus -Dateimanager (normalerweise als "Datei") im Menü Desktop oder Anwendungen. Suchen Sie den Recycle Bin: Suchen Sie nach dem Ordner recycelner Behälter in der linken Navigationsleiste. Wenn es nicht gefunden wird, klicken Sie auf "Andere Speicherort" oder "Computer", um sie zu suchen. Konfigurieren Sie Recycle Bin-Eigenschaften: Klicken Sie mit der rechten Maustaste auf "Recycle Bin" und wählen Sie "Eigenschaften". Im Eigenschaftenfenster können Sie die folgenden Einstellungen einstellen: Maximale Größe: Begrenzen Sie den im Recycle -Behälter verfügbaren Speicherplatz. Aufbewahrungszeit: Legen Sie die Erhaltung fest, bevor die Datei automatisch im Recyclingbehälter gelöscht wird
 Die Bedeutung von Debian Sniffer für die Netzwerküberwachung
Apr 12, 2025 pm 11:03 PM
Die Bedeutung von Debian Sniffer für die Netzwerküberwachung
Apr 12, 2025 pm 11:03 PM
Obwohl in den Suchergebnissen "Debiansniffer" und ihre spezifische Anwendung bei der Netzwerküberwachung nicht direkt erwähnt werden, können wir schließen, dass sich "Sniffer" auf ein Tool für Netzwerkpaket -Capture -Analyse bezieht, und seine Anwendung im Debian -System unterscheidet sich nicht wesentlich von anderen Linux -Verteilungen. Die Netzwerküberwachung ist entscheidend für die Aufrechterhaltung der Netzwerkstabilität und die Optimierung der Leistung, und Tools für die Analyse der Paketerfassung spielen eine Schlüsselrolle. Im Folgenden werden die wichtige Rolle von Tools zur Netzwerküberwachung (z. B. in Debian-Systemen ausgeführt) erklärt: Der Wert von Netzwerküberwachungstools: Schneller Fehlerstandort: Echtzeitüberwachung von Netzwerkmetriken, wie z.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
Befolgen Sie die folgenden Schritte, um den Apache -Server neu zu starten: Linux/MacOS: Führen Sie sudo systemCTL RESTART APache2 aus. Windows: Net Stop Apache2.4 und dann Net Start Apache2.4 ausführen. Führen Sie Netstat -a | Findstr 80, um den Serverstatus zu überprüfen.
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
