
 Technologie-Peripheriegeräte
KI
5-Millionen-Token-Monster, lesen Sie den gesamten „Harry Potter' auf einmal! Mehr als 1000-mal länger als ChatGPT
Technologie-Peripheriegeräte
KI
5-Millionen-Token-Monster, lesen Sie den gesamten „Harry Potter' auf einmal! Mehr als 1000-mal länger als ChatGPT
5-Millionen-Token-Monster, lesen Sie den gesamten „Harry Potter' auf einmal! Mehr als 1000-mal länger als ChatGPT

Schlechtes Gedächtnis ist das Hauptproblem aktueller Mainstream-Sprachmodelle. ChatGPT kann beispielsweise nur 4096 Token (ungefähr 3000 Wörter) eingeben, und das reicht nicht einmal aus Lesen Sie eine Kurzgeschichte von.
Das kurze Eingabefenster schränkt auch die Anwendungsszenarien des Sprachmodells ein. Wenn Sie beispielsweise eine wissenschaftliche Arbeit (ca. 10.000 Wörter) zusammenfassen, müssen Sie den Artikel manuell segmentieren und ihn dann in verschiedene Kapitel in das Modell eingeben. Die zugehörigen Informationen gehen verloren.
Obwohl GPT-4 bis zu 32.000 Token unterstützt und der aktualisierte Claude bis zu 100.000 Token unterstützt, können sie das Problem der unzureichenden Gehirnkapazität nur lindern.
Kürzlich gab das Unternehmerteam Magic bekannt, dass es bald das LTM-1-Modell herausbringen wird, das bis zu 5 Millionen Token unterstützt, was etwa 500.000 Codezeilen oder 5000 Dateien entspricht, also 50 Mal höher als Claude. Es ist im Grunde in Ordnung. Es deckt die meisten Speicheranforderungen ab, das macht wirklich einen Unterschied in Quantität und Qualität!
Das Hauptanwendungsszenario von LTM-1 ist die Codevervollständigung, mit der beispielsweise längere und komplexere Codevorschläge generiert werden können.Sie können Informationen auch über mehrere Dateien hinweg wiederverwenden und synthetisieren.
Die schlechte Nachricht ist, dass Magic, der Entwickler von LTM-1, die spezifischen technischen Prinzipien nicht veröffentlicht hat, sondern nur gesagt hat, dass es eine brandneue Methode entwickelt hat, das Long-Term Memory Network (LTM Net).
Aber es gibt auch gute Nachrichten: Im September 2021 haben Forscher von DeepMind und anderen Institutionen ein Modell namens ∞-former vorgeschlagen, das einen Langzeitgedächtnismechanismus (LTM) enthält. Die Theorie kann das Transformer-Modell unendlich machen Speicher, aber es ist nicht klar, ob es sich bei beiden um die gleiche Technologie oder eine verbesserte Version handelt.

Link zum Papier: https://arxiv.org/pdf/2109.00301.pdf
Das Entwicklungsteam gab an, dass LTM-Netze zwar mehr Kontext sehen können als GPT, LTM-Netzwerke jedoch mehr Kontext sehen können als GPT Die Parameter des -1-Modells sind viel kleiner als die des aktuellen Sota-Modells, daher ist auch der Intelligenzgrad geringer. Eine weitere Vergrößerung der Modellgröße dürfte jedoch die Leistung von LTM-Netzen verbessern.Derzeit hat LTM-1 Alpha-Testanwendungen geöffnet.

Anwendungslink: https://www.php.cn/link/bbfb937a66597d9646ad992009aee405
LTM-1-Entwickler Magic wurde 2022 gegründet und entwickelt hauptsächlich ähnliche GitHub Copilot’s Das Produkt kann Softwareentwicklern beim Schreiben, Überprüfen, Debuggen und Ändern von Code helfen. Das Ziel besteht darin, einen KI-Kollegen für Programmierer zu schaffen. Sein Hauptwettbewerbsvorteil besteht darin, dass das Modell längeren Code lesen kann.Magic ist dem Gemeinwohl verpflichtet und seine Mission besteht darin, AGI-Systeme zu entwickeln und sicher einzusetzen, die die menschlichen Fähigkeiten übertreffen. Derzeit ist das Unternehmen ein Startup-Unternehmen mit nur 10 Mitarbeitern.

Eric Steinberger, CEO und Mitbegründer von Magic, hat einen Bachelor-Abschluss in Informatik von der Universität Cambridge und hat bei FAIR maschinelles Lernen geforscht.

Vor der Gründung von Magic gründete Steinberger auch ClimateScience, um Kindern auf der ganzen Welt dabei zu helfen, etwas über die Auswirkungen des Klimawandels zu lernen.
Infinite Memory Transformer
Das Design des Aufmerksamkeitsmechanismus im Transformer, der Kernkomponente des Sprachmodells, führt dazu, dass die Zeitkomplexität jedes Mal quadratisch zunimmt, wenn die Länge der Eingabesequenz erhöht wird.
Obwohl es bereits einige Varianten des Aufmerksamkeitsmechanismus gibt, wie z. B. spärliche Aufmerksamkeit usw., um die Komplexität des Algorithmus zu reduzieren, hängt seine Komplexität immer noch von der Eingabelänge ab und kann nicht unendlich erweitert werden.
∞-former Der Schlüssel zum Transformer-Modell des Langzeitgedächtnisses (LTM), das die Eingabesequenz auf unbegrenzt erweitern kann, ist ein kontinuierliches räumliches Aufmerksamkeitsgerüst, das die Anzahl der Gedächtnisinformationseinheiten (basierend auf der Funktion) erhöht.
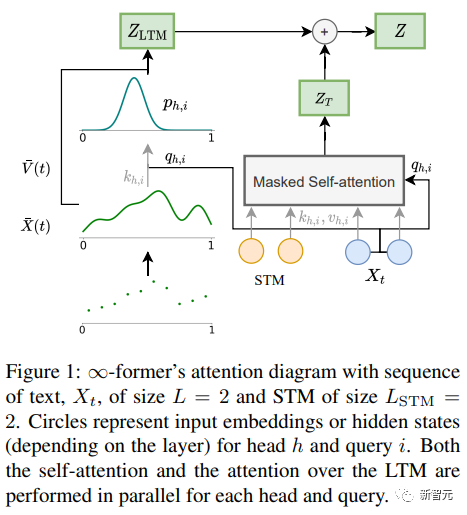
Im Framework wird die Eingabesequenz als „kontinuierliches Signal“ dargestellt, das eine lineare Kombination von N radialen Basisfunktionen (RBF) darstellt. Auf diese Weise beträgt die Aufmerksamkeitskomplexität von ∞-former Es wird auf O(L^2 + L × N) reduziert, während die Aufmerksamkeitskomplexität des ursprünglichen Transformers O(L×(L+L_LTM)) beträgt, wobei L und L_LTM der Transformer-Eingabegröße und dem Langzeitgedächtnis entsprechen Länge bzw.
Diese Darstellungsmethode hat zwei Hauptvorteile:
1 Der Kontext kann durch eine Basisfunktion N dargestellt werden, die kleiner ist als die Anzahl der Token, was den Rechenaufwand für die Aufmerksamkeit reduziert;
2 kann festgelegt werden und ist somit in der Lage, einen unbegrenzten Kontext im Gedächtnis darzustellen, ohne die Komplexität des Aufmerksamkeitsmechanismus zu erhöhen.

Natürlich gibt es kein kostenloses Mittagessen auf der Welt, und der Preis ist die Verringerung der Auflösung: Die Verwendung einer geringeren Anzahl von Basisfunktionen führt zu einer Verringerung der Genauigkeit bei der Darstellung der Eingabesequenz als ein Dauersignal.
Um das Problem der Auflösungsreduzierung zu lindern, führten Forscher das Konzept der „Sticky Memories“ ein, das den größeren Platz im LTM-Signal auf häufiger aufgerufene Speicherbereiche zurückführte und so ein „Sticky Memory“ im LTM schuf Das Konzept der „Permanenz“ ermöglicht es dem Modell, den langfristigen Kontext besser zu erfassen, ohne relevante Informationen zu verlieren, und ist außerdem vom langfristigen Potenzial und der Plastizität des Gehirns inspiriert.
Experimenteller Teil
Um zu überprüfen, ob ∞-former lange Kontexte modellieren kann, führten die Forscher zunächst Experimente zu einer synthetischen Aufgabe durch, d. h. zum Sortieren von Token nach Häufigkeit in einer langen Sequenz mit Sprachmodellierung und dokumentbasierter Dialoggenerierung durch Feinabstimmung vorab trainierter Sprachmodelle.
Sortierung
Die Eingabe umfasst eine Sequenz von Token, die gemäß einer Wahrscheinlichkeitsverteilung (dem System unbekannt) abgetastet werden, und das Ziel besteht darin, Token in der Reihenfolge abnehmender Häufigkeit in der Sequenz zu generieren
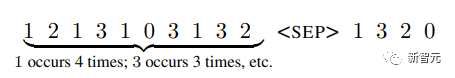
Um langfristig zu untersuchen, ob der Speicher effizient genutzt wird und ob der Transformer einfach durch Modellierung der neuesten Tags sortiert, haben die Forscher die Tag-Wahrscheinlichkeitsverteilung so entworfen, dass sie sich im Laufe der Zeit ändert.
Es gibt 20 Token im Vokabular, und zum Vergleich werden Experimente mit Sequenzen der Längen 4.000, 8.000 und 16.000 durchgeführt.
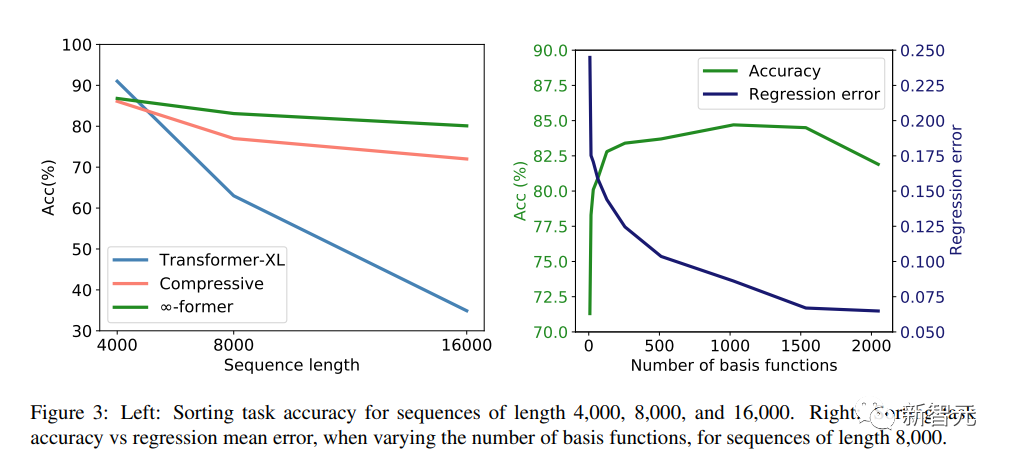
Die experimentellen Ergebnisse zeigen, dass Transformer-XL bei einer kurzen Sequenzlänge (4.000) eine etwas höhere Genauigkeit als andere Modelle erreicht. Mit zunehmender Sequenzlänge nimmt die Genauigkeit jedoch ebenfalls schnell ab, jedoch für ∞-former For Dieser Rückgang ist nicht offensichtlich, was darauf hindeutet, dass er bei der Modellierung langer Sequenzen mehr Vorteile bietet.
Sprachmodellierung
Um zu verstehen, ob das Langzeitgedächtnis zur Erweiterung vorab trainierter Sprachmodelle verwendet werden kann, führten die Forscher GPT-2 Small an einer Teilmenge von Wikitext103 und PG-19 Fine- durch. abgestimmt, darunter rund 200 Millionen Token.
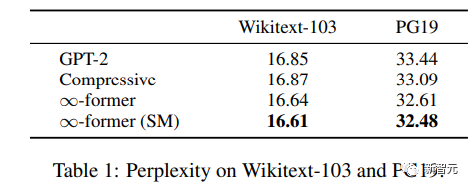
Die experimentellen Ergebnisse zeigen, dass ∞-Former die Verwirrung von Wikitext-103 und PG19 verringern kann und ∞-Former eine größere Verbesserung gegenüber dem PG19-Datensatz erzielt, da Bücher stärker davon abhängig sind als Wikipedia-Artikel Langzeitgedächtnis.
Dokumentbasierter Dialog
Bei der dokumentbasierten Dialoggenerierung kann das Modell neben dem Dialogverlauf auch Dokumente zum Gesprächsthema abrufen.
Im CMU Document Grounded Conversation-Datensatz (CMU-DoG) handelt es sich bei der Konversation um einen Film, und eine Zusammenfassung des Films wird als Hilfsdokument angegeben; die Konversation enthält mehrere verschiedene fortlaufende Diskurse, die Hilfsdokumente sind in mehrere Teile unterteilt.
Um den Nutzen des Langzeitgedächtnisses zu beurteilen, gewährten die Forscher dem Modell erst vor Beginn des Gesprächs Zugriff auf die Datei, was die Aufgabe schwieriger machte.
Nach der Feinabstimmung von GPT-2 wird GPT-2 mithilfe eines kontinuierlichen LTM (∞-Former) mit N=512 Basisfunktionen erweitert, damit das Modell das gesamte Dokument im Speicher behalten kann.
Um den Modelleffekt zu bewerten, verwenden Sie Ratlosigkeit, F1-Score, Rouge-1 und Rouge-L sowie Meteor-Indikatoren.
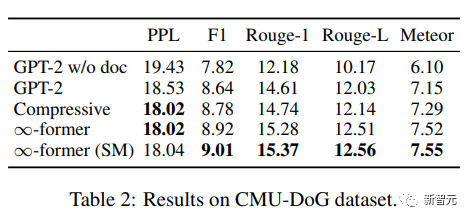
Den Ergebnissen nach zu urteilen, können ∞-Former und Komprimierungstransformator einen besseren Korpus erzeugen. Obwohl die Verwirrung der beiden im Grunde die gleiche ist, erzielt ∞-Former bessere Ergebnisse.
Das obige ist der detaillierte Inhalt von5-Millionen-Token-Monster, lesen Sie den gesamten „Harry Potter' auf einmal! Mehr als 1000-mal länger als ChatGPT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
 Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Feldbetriebshandbuch in MySQL: Felder hinzufügen, ändern und löschen. Feld hinzufügen: Alter table table_name hinzufügen column_name data_type [nicht null] [Standard default_value] [Primärschlüssel] [auto_increment] Feld ändern: Alter table table_name Ändern Sie Column_Name Data_type [nicht null] [diffault default_value] [Primärschlüssel] [Primärschlüssel]
 Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Die Integritätsbeschränkungen von Oracle -Datenbanken können die Datengenauigkeit sicherstellen, einschließlich: nicht Null: Nullwerte sind verboten; Einzigartig: Einzigartigkeit garantieren und einen einzelnen Nullwert ermöglichen; Primärschlüssel: Primärschlüsselbeschränkung, Stärkung der einzigartigen und verboten Nullwerte; Fremdschlüssel: Verwalten Sie die Beziehungen zwischen Tabellen, Fremdschlüssel beziehen sich auf Primärtabellen -Primärschlüssel. Überprüfen Sie: Spaltenwerte nach Bedingungen begrenzen.
 Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Verschachtelte Anfragen sind eine Möglichkeit, eine andere Frage in eine Abfrage aufzunehmen. Sie werden hauptsächlich zum Abrufen von Daten verwendet, die komplexe Bedingungen erfüllen, mehrere Tabellen assoziieren und zusammenfassende Werte oder statistische Informationen berechnen. Beispiele hierfür sind zu findenen Mitarbeitern über den überdurchschnittlichen Löhnen, das Finden von Bestellungen für eine bestimmte Kategorie und die Berechnung des Gesamtbestellvolumens für jedes Produkt. Beim Schreiben verschachtelter Abfragen müssen Sie folgen: Unterabfragen schreiben, ihre Ergebnisse in äußere Abfragen schreiben (auf Alias oder als Klauseln bezogen) und optimieren Sie die Abfrageleistung (unter Verwendung von Indizes).
 Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Oracle ist das weltweit größte Softwareunternehmen für Datenbankverwaltungssystem (DBMS). Zu den Hauptprodukten gehören die folgenden Funktionen: Entwicklungstools für relationale Datenbankverwaltungssysteme (Oracle Database) (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle Soa Suite) Cloud -Dienst (Oracle Cloud Infrastructure) Analyse und Business Intelligence (Oracle Analytic
 So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
In diesem Artikel wird beschrieben, wie das Protokollformat von Apache auf Debian -Systemen angepasst wird. Die folgenden Schritte führen Sie durch den Konfigurationsprozess: Schritt 1: Greifen Sie auf die Apache -Konfigurationsdatei zu. Die Haupt -Apache -Konfigurationsdatei des Debian -Systems befindet sich normalerweise in /etc/apache2/apache2.conf oder /etc/apache2/httpd.conf. Öffnen Sie die Konfigurationsdatei mit Root -Berechtigungen mit dem folgenden Befehl: Sudonano/etc/apache2/apache2.conf oder sudonano/etc/apache2/httpd.conf Schritt 2: Definieren Sie benutzerdefinierte Protokollformate, um zu finden oder zu finden oder
