
 Technologie-Peripheriegeräte
KI
Das stärkste API-Aufrufmodell ist da! Basierend auf der LLaMA-Feinabstimmung übertrifft die Leistung GPT-4
Technologie-Peripheriegeräte
KI
Das stärkste API-Aufrufmodell ist da! Basierend auf der LLaMA-Feinabstimmung übertrifft die Leistung GPT-4
Das stärkste API-Aufrufmodell ist da! Basierend auf der LLaMA-Feinabstimmung übertrifft die Leistung GPT-4

Nach dem Alpaka gibt es ein weiteres Modell, das nach einem Tier benannt ist, dieses Mal ist es der Gorilla.
Obwohl LLM derzeit boomt, große Fortschritte macht und auch seine Leistung bei verschiedenen Aufgaben bemerkenswert ist, muss das Potenzial dieser Modelle zur effektiven Nutzung von Tools über API-Aufrufe noch erforscht werden.
Selbst für die heutigen hochmodernen LLMs wie GPT-4 sind API-Aufrufe eine herausfordernde Aufgabe, vor allem weil sie nicht in der Lage sind, genaue Eingabeparameter zu generieren, und LLMs dazu neigen, die falsche Verwendung von API-Aufrufen zu halluzinieren.
Nein, die Forscher haben Gorilla entwickelt, ein fein abgestimmtes LLaMA-basiertes Modell, dessen Leistung beim Schreiben von API-Aufrufen sogar GPT-4 übertrifft.
In Kombination mit einem Dokumenten-Retriever zeigt Gorilla außerdem eine starke Leistung und macht Benutzeraktualisierungen oder Versionsänderungen flexibler.
Darüber hinaus lindert Gorilla auch das Halluzinationsproblem, mit dem LLM häufig konfrontiert ist, erheblich.
Um die Fähigkeiten des Modells zu bewerten, führten die Forscher außerdem einen API-Benchmark ein, einen umfassenden Datensatz bestehend aus HuggingFace-, TorchHub- und TensorHub-APIs
Gorilla
Die leistungsstarken Funktionen von LLMs bedürfen keiner weiteren Einführung . , einschließlich natürlicher Konversationsfähigkeit, Fähigkeit zum mathematischen Denken und Fähigkeit zur Programmsynthese.
Allerdings weist LLM trotz seiner starken Leistung immer noch einige Einschränkungen auf. Darüber hinaus müssen auch LLM-Absolventen umgeschult werden, um ihre Wissensbasis und Argumentationsfähigkeiten zeitnah zu aktualisieren.
Durch die Autorisierung der für LLM verfügbaren Tools können Forscher LLM den Zugriff auf eine riesige und sich ständig ändernde Wissensdatenbank ermöglichen, um komplexe Computeraufgaben zu erledigen.
Durch die Bereitstellung des Zugriffs auf Suchtechnologien und Datenbanken können Forscher die Fähigkeiten von LLM verbessern, um größere und dynamischere Wissensräume zu bewältigen.
Ebenso kann LLM durch den Einsatz von Berechnungstools auch komplexe Berechnungsaufgaben erledigen.
Daher haben Technologiegiganten begonnen, verschiedene Plug-Ins zu integrieren, um LLM den Aufruf externer Tools über APIs zu ermöglichen.
Von einem kleineren, handcodierten Tool bis hin zur Möglichkeit, einen großen und sich ständig ändernden Cloud-API-Bereich aufzurufen, kann diese Transformation LLM in die vom Netzwerk benötigte Computerinfrastruktur und primäre Schnittstelle verwandeln.
Aufgaben von der Buchung eines ganzen Urlaubs bis zur Ausrichtung einer Konferenz können so einfach sein wie das Gespräch mit einem LLM mit Zugriff auf Web-APIs für Flüge, Mietwagen, Hotels, Restaurants und Unterhaltung.
Allerdings berücksichtigen viele frühere Arbeiten zur Integration von Tools in LLM einen kleinen Satz gut dokumentierter APIs, die leicht in Eingabeaufforderungen eingefügt werden können.
Die Unterstützung einer webbasierten Sammlung potenziell Millionen sich ändernder APIs erfordert ein Umdenken bei der Art und Weise, wie Forscher Tools integrieren.
Es ist nicht mehr möglich, alle APIs in einer einzigen Umgebung zu beschreiben. Viele APIs verfügen über überlappende Funktionen mit subtilen Einschränkungen und Einschränkungen. Allein die Evaluierung von LLM in dieser neuen Umgebung erfordert neue Maßstäbe.
In diesem Artikel untersuchen Forscher Methoden zur Verwendung selbststrukturierter Feinabstimmung und Abfrage, um LLM in die Lage zu versetzen, aus einem großen, überlappenden und sich ändernden Toolset, das mithilfe seiner API und API-Dokumentation ausgedrückt wird, genau auszuwählen.
Forscher bauen API Bench auf, indem sie ML-APIs (Modelle) aus öffentlichen Modellzentren extrahieren, einem großen Korpus von APIs mit komplexer und oft überlappender Funktionalität.
Die Forscher wählten drei Hauptmodellzentren für die Erstellung des Datensatzes: TorchHub, TensorHub und HuggingFace.
Die Forscher haben jeden API-Aufruf umfassend in TorchHub (94 API-Aufrufe) und TensorHub (696 API-Aufrufe) einbezogen.
Für HuggingFace wählten die Forscher aufgrund der großen Anzahl an Modellen die 20 am häufigsten heruntergeladenen Modelle in jeder Aufgabenkategorie aus (insgesamt 925).
Die Forscher verwendeten außerdem Self-Instruct, um Eingabeaufforderungen für 10 Benutzerfragen für jede API zu generieren.
Somit wird jeder Eintrag im Datensatz zu einem Anweisungsreferenz-API-Paar. Die Forscher verwendeten gängige AST-Teilbaum-Matching-Techniken, um die funktionale Korrektheit der generierten APIs zu bewerten.
Der Forscher analysiert zunächst den generierten Code in einen AST-Baum, findet dann einen Unterbaum, dessen Wurzelknoten der API-Aufruf ist, der dem Forscher wichtig ist, und verwendet diesen dann, um den Datensatz des Forschers zu indizieren.
Forscher prüfen die funktionale Korrektheit und Halluzinationsprobleme von LLMs und geben Feedback zur entsprechenden Genauigkeit. Anschließend optimierten die Forscher Gorilla, ein auf LLaMA-7B basierendes Modell, um mithilfe des Datensatzes der Forscher Dokumentenabrufvorgänge durchzuführen.
Forscher fanden heraus, dass Gorilla GPT-4 in Bezug auf die Genauigkeit der API-Funktionen und die Reduzierung von Halluzinationsfehlern deutlich übertraf.
Ein Beispiel zeigen die Forscher in Abbildung 1.

Darüber hinaus ermöglichte das abrufbewusste Training von Gorilla durch die Forscher, dass sich das Modell an Änderungen in der API-Dokumentation anpassen konnte.
Schließlich demonstrierten die Forscher auch Gorillas Fähigkeit, Einschränkungen zu verstehen und darüber nachzudenken.
Darüber hinaus schnitt Gorilla auch in Sachen Illusionen gut ab.
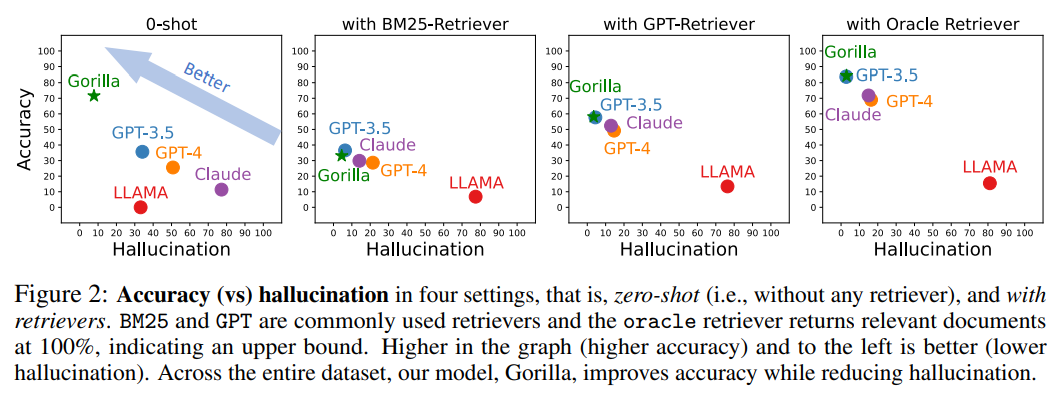
Die folgende Abbildung ist ein Vergleich von Genauigkeit und Halluzination in vier Fällen, Nullproben (d. h. ohne Retriever) und unter Verwendung von Retrievern von BM25, GPT und Oracle.
Unter diesen sind BM25 und GPT häufig verwendete Sucher, während der Oracle-Sucher relevante Dokumente mit 100 % Relevanz zurückgibt, was eine Obergrenze angibt.
Diejenige mit höherer Genauigkeit und weniger Illusionen im Bild hat eine bessere Wirkung.
Im gesamten Datensatz verbessert Gorilla die Genauigkeit und reduziert gleichzeitig Halluzinationen.
Um den Datensatz zu sammeln, zeichneten die Forscher sorgfältig alle Online-Modelle der Modelle The Model Hub, PyTorch Hub und TensorFlow Hub von HuggingFace auf.
Die HuggingFace-Plattform hostet und bedient insgesamt 203681 Modelle.
Allerdings ist die Dokumentation für viele dieser Modelle dürftig.
Um diese minderwertigen Modelle herauszufiltern, wählten die Forscher schließlich die 20 besten Modelle aus jeder Domäne aus.
Die Forscher betrachteten 7 Domänen für multimodale Daten, 8 Domänen für Lebenslauf, 12 Domänen für NLP, 5 Domänen für Audio, 2 Domänen für tabellarische Daten und 2 Domänen für verstärkendes Lernen.
Nach der Filterung erhielten die Forscher insgesamt 925 Modelle von HuggingFace. Die Versionen von TensorFlow Hub sind in v1 und v2 unterteilt.
Die neueste Version (v2) verfügt über insgesamt 801 Modelle, und die Forscher haben alle Modelle verarbeitet. Nach dem Herausfiltern von Modellen mit wenigen Informationen blieben 626 Modelle übrig.
Ähnlich wie bei TensorFlow Hub erhielten die Forscher 95 Modelle von Torch Hub.
Unter der Anleitung des Selbstinstruktionsparadigmas übernehmen Forscher GPT-4, um synthetische Instruktionsdaten zu generieren.
Die Forscher stellten drei kontextbezogene Beispiele sowie ein Referenz-API-Dokument zur Verfügung und beauftragten das Modell mit der Generierung realer Anwendungsfälle für den Aufruf der API.
Die Forscher haben das Modell ausdrücklich angewiesen, bei der Erstellung von Anweisungen keine API-Namen oder Hinweise zu verwenden. Die Forscher erstellten sechs Beispiele (Anweisungs-API-Paare) für jeden der drei Modell-Hubs.
Diese 18 Punkte sind die einzigen Daten, die manuell generiert oder geändert werden.
Und Gorilla ist ein abruffähiges LLaMA-7B-Modell, das speziell für API-Aufrufe verwendet wird.
Wie in Abbildung 3 dargestellt, nutzten die Forscher die Selbstkonstruktion, um {Anweisung, API}-Paare zu generieren.
Um LLaMA zu verfeinern, haben die Forscher es in eine Konversation im Chat-Stil zwischen Benutzer und Agent umgewandelt, bei der jeder Datenpunkt eine Konversation darstellt und der Benutzer und der Agent abwechselnd reden.
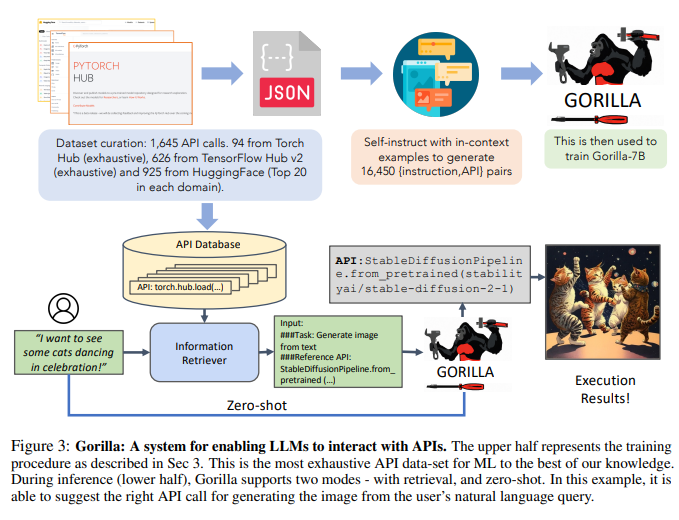
Dann führten die Forscher eine Feinabstimmung der Standardanweisungen am Basismodell LLaMA-7B durch. In Experimenten trainierten die Forscher Gorillas mit und ohne Retriever.
In der Studie konzentrierten sich die Forscher auf Techniken, die darauf abzielen, die Fähigkeit von LLM zu verbessern, geeignete APIs für bestimmte Aufgaben genau zu identifizieren – ein entscheidender, aber oft übersehener Aspekt der Technologieentwicklung.
Da API als universelle Sprache fungiert, die eine effektive Kommunikation zwischen verschiedenen Systemen ermöglicht, kann die ordnungsgemäße Verwendung von API die Fähigkeit von LLM verbessern, mit einer breiteren Palette von Tools zu interagieren.
Gorilla übertraf das hochmoderne LLM (GPT-4) bei drei von den Forschern gesammelten umfangreichen Datensätzen. Gorilla erstellt zuverlässige ML-Modelle von API-Aufrufen ohne Halluzinationen und erfüllt Einschränkungen bei der Auswahl von APIs.
Auf der Suche nach einem anspruchsvollen Datensatz entschieden sich die Forscher aufgrund ihrer ähnlichen Funktionalität für ML-APIs. Ein potenzieller Nachteil ML-fokussierter APIs besteht darin, dass sie, wenn sie auf voreingenommenen Daten trainiert werden, das Potenzial haben, voreingenommene Vorhersagen zu erstellen, die bestimmte Untergruppen benachteiligen können.
Um diese Bedenken auszuräumen und ein tieferes Verständnis dieser APIs zu fördern, veröffentlichen Forscher einen umfangreicheren Datensatz, der mehr als 11.000 Befehls-API-Paare umfasst.
Im folgenden Beispiel verwenden Forscher den AST-Teilbaumvergleich (Abstract Syntax Tree), um die Richtigkeit von API-Aufrufen zu bewerten.
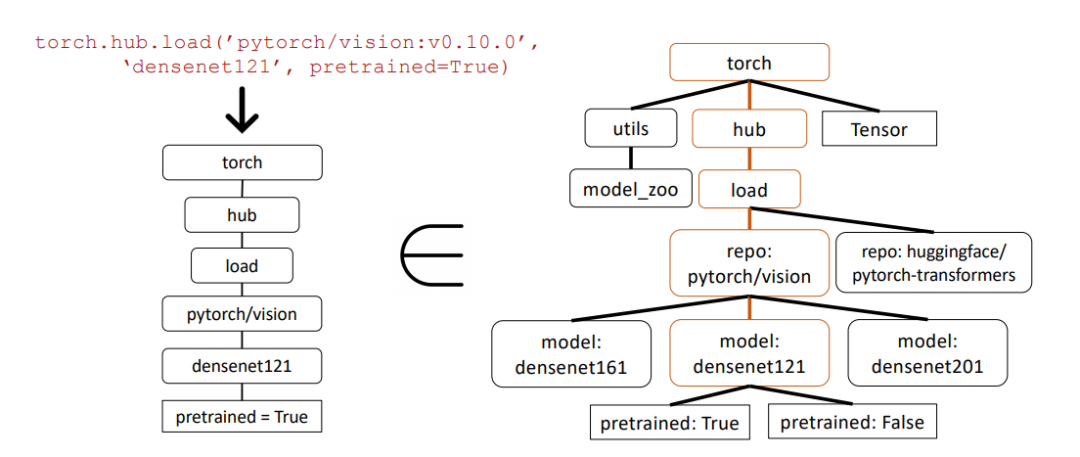
Abstrakter Syntaxbaum ist eine Baumdarstellung der Quellcodestruktur, die hilft, den Code besser zu analysieren und zu verstehen.
Zuerst erstellten die Forscher den relevanten API-Baum aus den von Gorilla zurückgegebenen API-Aufrufen (links). Dies wird dann mit dem Datensatz verglichen, um festzustellen, ob der API-Datensatz eine Teilbaumübereinstimmung aufweist.
Im obigen Beispiel ist der passende Teilbaum braun hervorgehoben, was darauf hinweist, dass der API-Aufruf tatsächlich korrekt ist. Wobei Pretrained=True ein optionaler Parameter ist.
Diese Ressource wird der breiteren Community als wertvolles Werkzeug zur Erforschung und Messung vorhandener APIs dienen und zu einer gerechteren und optimalen Nutzung des maschinellen Lernens beitragen.
Das obige ist der detaillierte Inhalt vonDas stärkste API-Aufrufmodell ist da! Basierend auf der LLaMA-Feinabstimmung übertrifft die Leistung GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Die zehn Top-Empfehlungen zur Plattform für Echtzeitdaten auf den Währungskreismärkten werden veröffentlicht
Apr 22, 2025 am 08:12 AM
Die zehn Top-Empfehlungen zur Plattform für Echtzeitdaten auf den Währungskreismärkten werden veröffentlicht
Apr 22, 2025 am 08:12 AM
Zu den für Anfängern geeigneten Kryptowährungsdatenplattformen gehören CoinMarketCap und nicht-kleine Trompete. 1. CoinmarketCap bietet globale Rangliste für den Preis, den Marktwert und der Handelsvolumen für Anfänger für Anfänger und Grundanalyse. 2. Das nichtklammernde Angebot bietet eine chinesisch-freundliche Schnittstelle, die chinesischen Benutzern geeignet ist, um potenzielle Projekte mit geringem Risiko schnell zu untersuchen.
 OKX Online OKX Exchange Offizielle Website online
Apr 22, 2025 am 06:45 AM
OKX Online OKX Exchange Offizielle Website online
Apr 22, 2025 am 06:45 AM
Die detaillierte Einführung von OKX Exchange lautet wie folgt: 1) Entwicklungsgeschichte: Im Jahr 2017 gegründet und in OKX im Jahr 2022 umbenannt; 2) seinen Hauptsitz in Seychellen; 3) Business Scope deckt eine Vielzahl von Handelsprodukten ab und unterstützt mehr als 350 Kryptowährungen. 4) Benutzer sind in mehr als 200 Ländern verteilt, wobei zig Millionen von Nutzern; 5) Es werden mehrere Sicherheitsmaßnahmen angewendet, um die Benutzervermögen zu schützen. 6) Die Transaktionsgebühren basieren auf dem Markt für das Markthersteller, und die Gebührenquote nimmt mit dem Anstieg des Handelsvolumens ab. 7) Es hat viele Auszeichnungen wie "Kryptowährungsaustausch des Jahres" gewonnen.
 Eine Liste spezieller Dienste für wichtige Handelsplattformen für virtuelle Währung
Apr 22, 2025 am 08:09 AM
Eine Liste spezieller Dienste für wichtige Handelsplattformen für virtuelle Währung
Apr 22, 2025 am 08:09 AM
Institutionelle Anleger sollten konforme Plattformen wie Coinbase Pro und Genesis Trading wählen, die sich auf Kühlspeicherverhältnisse und die Überwachung der Transparenz konzentrieren. Einzelhandelsinvestoren sollten große Plattformen wie Binance und Huobi auswählen und sich auf Benutzererfahrung und Sicherheit konzentrieren. Benutzer in konform-sensitiven Gebieten können durch Circle Trade und Huobi Global Fiat-Währungshandel durchführen, und chinesische Benutzer auf dem Festland müssen konforme rezeptfreie Kanäle durchlaufen.
 Top 10 neueste Veröffentlichungen für virtuelle Währungshandelsplattformen für Bulk -Transaktionen
Apr 22, 2025 am 08:18 AM
Top 10 neueste Veröffentlichungen für virtuelle Währungshandelsplattformen für Bulk -Transaktionen
Apr 22, 2025 am 08:18 AM
Die folgenden Faktoren sollten bei der Auswahl einer Bulk -Handelsplattform berücksichtigt werden: 1. Liquidität: Plattformen mit einem durchschnittlichen täglichen Handelsvolumen von mehr als 5 Milliarden US -Dollar wird vor Priorität gegeben. 2. Compliance: Überprüfen Sie, ob die Plattform Lizenzen wie Fincen in den USA, MICA in der Europäischen Union, enthält. 3. Sicherheit: Kaltbrieftaschenspeicherverhältnis und Versicherungsmechanismus sind Schlüsselindikatoren. 4. Servicefunktion: Ob exklusive Kontomanager und maßgeschneiderte Transaktionstools bereitgestellt werden.
 Eine Liste der zehn Top -Handelsplattformen für virtuelle Währung, die mehrere Währungen unterstützen
Apr 22, 2025 am 08:15 AM
Eine Liste der zehn Top -Handelsplattformen für virtuelle Währung, die mehrere Währungen unterstützen
Apr 22, 2025 am 08:15 AM
Priorität wird konforme Plattformen wie OKX und Coinbase erteilt, wodurch die Überprüfung der Multi-Faktoren ermöglicht wird, und die Selbstversorgung von Asset kann die Abhängigkeiten reduzieren: 1. Wählen Sie einen Austausch mit einer regulierten Lizenz aus; 2. Schalten Sie die Whitelist von 2FA und Abhebungen ein; 3. Verwenden Sie eine Hardware-Brieftasche oder eine Plattform, die die Selbstversorgung unterstützt.
 Empfohlene Top 10 für einfachen Zugriff auf digitale Währungshandels -Apps (neueste Ranking in 25)
Apr 22, 2025 am 07:45 AM
Empfohlene Top 10 für einfachen Zugriff auf digitale Währungshandels -Apps (neueste Ranking in 25)
Apr 22, 2025 am 07:45 AM
Gate.io (Global Version) Kernvorteil ist, dass die Schnittstelle minimalistisch ist, Chinesisch unterstützt und der Fiat -Währungstransaktionsprozess intuitiv ist. Binance (vereinfachte Version) Core -Vorteil ist, dass das Handelsvolumen der Welt das erste der Welt ist und das einfache Versionsmodell nur den Spot -Handel behält. OKX (Hong Kong Version) Kernvorteil ist, dass die Schnittstelle einfach ist, Kantonesisch/Mandarin unterstützt und einen niedrigen Schwellenwert für Derivathandel hat. Der Kernvorteil von Huobi Global Station (Hong Kong Version) ist, dass es sich um eine alte Börse handelt, die ein Meta-Universitäts-Handelsterminal startet. Der Kernvorteil von Kucoin (Chinesische Community Edition) ist, dass es 800 Währungen unterstützt und die Schnittstelle die WeChat -Interaktion übernimmt. Der Kernvorteil von Kraken (Hong Kong Version) ist, dass es sich um einen alten amerikanischen Austausch handelt, der eine SVF -Lizenz in Hongkong hält und eine einfache Schnittstelle hat. Hashkey Exchange (Hong Kong Lizenzed) Kernvorteil ist ein bekannter lizenzierter Austausch in Hongkong, der das Gesetz unterstützt
 Tipps und Empfehlungen für die zehn wichtigsten Marktwebsites im Währungskreis 2025
Apr 22, 2025 am 08:03 AM
Tipps und Empfehlungen für die zehn wichtigsten Marktwebsites im Währungskreis 2025
Apr 22, 2025 am 08:03 AM
In den inländischen Benutzeranpassungslösungen werden Konformitätskanäle und Lokalisierungstools gehören. 1. Compliance -Kanäle: Franchise -Währungsaustausch über OTC -Plattformen wie Circle Trade, im Inland müssen sie durch Hongkong- oder Überseeplattformen gehen. 2. Lokalisierungsinstrumente: Verwenden Sie das Währungskreisnetz, um chinesische Informationen zu erhalten, und die Huobi Global Station bietet ein Handelsanschluss von Meta-Universitäten.
 Zusammenfassung der Top Ten Apple -Version Download -Portale für digitale Währungsaustausch -Apps herunterladen
Apr 22, 2025 am 09:27 AM
Zusammenfassung der Top Ten Apple -Version Download -Portale für digitale Währungsaustausch -Apps herunterladen
Apr 22, 2025 am 09:27 AM
Bietet eine Vielzahl komplexer Handelsinstrumente und Marktanalysen. Es deckt mehr als 100 Länder ab, hat ein durchschnittliches tägliches Derivatvolumen von über 30 Milliarden US -Dollar, unterstützt mehr als 300 Handelspaare und den 200 -fachen Hebel, hat eine starke technische Stärke, eine riesige globale Benutzerbasis, bietet professionelle Handelsplattformen, sichere Speicherlösungen und reichhaltige Handelspaare.
