
 Technologie-Peripheriegeräte
KI
Echtzeitschutz vor Gesichtsblockierungsangriffen im Web (basierend auf maschinellem Lernen)
Technologie-Peripheriegeräte
KI
Echtzeitschutz vor Gesichtsblockierungsangriffen im Web (basierend auf maschinellem Lernen)
Echtzeitschutz vor Gesichtsblockierungsangriffen im Web (basierend auf maschinellem Lernen)

Verhindern Sie Face-Blocking-Sperrfeuer, das heißt, dass eine große Anzahl von Sperrfeuern vorbeischwebt, aber blockieren Sie nicht die Charaktere auf dem Videobildschirm, sodass es so aussieht, als würden sie hinter den Charakteren schweben.
Maschinelles Lernen ist seit mehreren Jahren beliebt, aber viele Leute wissen nicht, dass diese Funktionen auch in Browsern ausgeführt werden können.
Dieser Artikel stellt den praktischen Optimierungsprozess von Videosperren vor Wo diese Lösung anwendbar ist, werden aufgelistet, in der Hoffnung, einige Ideen zu eröffnen.
mediapipe-Demo (https://google.github.io/mediapipe/) zeigt
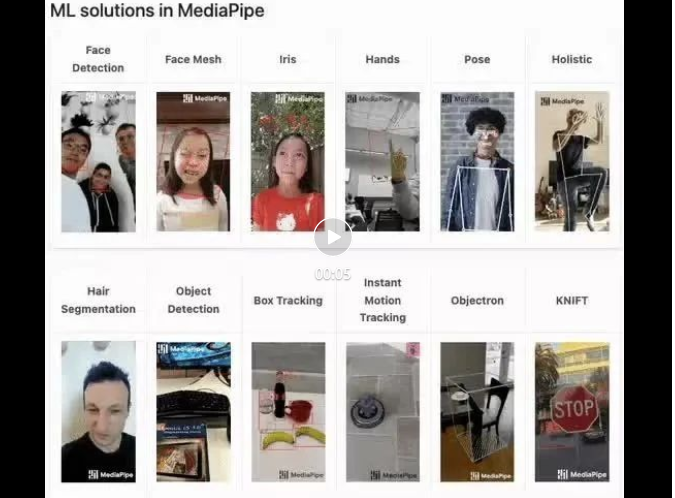
Implementierungsprinzip des Mainstream-Anti-Face-Barrages
On-Demand
Video hochladen
Server-Hintergrundberechnung zum Extrahieren der Inhalt im Hochformat des Videobildschirms, in SVG-Speicher umgewandelt
Während der Client das Video abspielt, wird das SVG vom Server heruntergeladen und mit dem Sperrfeuer kombiniert. Das Sperrfeuer wird nicht im Hochformatbereich angezeigt
Live-Übertragung
- Wenn der Anker den Stream verschiebt, wird er in Echtzeit vom Bildschirm extrahiert (Ankergerät). Porträtbereich, in SVG umgewandelt.
- SVG-Daten in den Videostream (SEI) zusammenführen und den Stream an den Server übertragen. Der Client spielt gleichzeitig das Video ab, analysiert die SVG-Datei aus dem Videostream (SEI)
- Svg mit Barrage synthetisieren, im Porträtbereich wird Barrage nicht angezeigt
- Der Implementierungsplan dieses Artikels
Während der Client das Video abspielt , werden die Porträtbereichsinformationen in Echtzeit vom Bildschirm extrahiert und die Porträtbereichsinformationen in ein Bild exportiert und mit dem Sperrfeuer kombiniert, und das Sperrfeuer wird nicht im Porträtbereich angezeigt.
Implementierungsprinzip
Verwendung von Open-Source-Bibliotheken für maschinelles Lernen, um Porträtumrisse aus Videomaterial in Echtzeit zu extrahieren, wie z. B. Körpersegmentierung (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation /README.md)- Exportieren Sie den Porträtumriss in ein Bild und legen Sie das Maskenbild der Sperrschicht fest (https://developer.mozilla.org/zh-CN/docs/Web/CSS/mask-image)
- Im Vergleich zur herkömmlichen Lösung (Live-Übertragung von SEI in Echtzeit)
Vorteile:
Einfach zu implementieren; erfordert nur einen Parameter des Video-Tags, keine Multi-End-Koordination erforderlich- Kein Netzwerkbandbreitenverbrauch
- Nachteile:
Es ist bekannt, dass JavaScript eine schlechte Leistung aufweist und daher nicht für die Verarbeitung CPU-intensiver Aufgaben geeignet ist. Von der offiziellen Demo bis zur technischen Praxis ist die Leistung die größte Herausforderung.
Diese Vorgehensweise optimierte schließlich die CPU-Auslastung auf etwa 5 % (2020 M1 Macbook) und erreichte einen produktionsbereiten Zustand.
Praktischer Abstimmungsprozess
Wählen Sie ein Modell für maschinelles Lernen
BodyPix (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/src/body_pix/README.md)
Auch Genauigkeit Schlecht, das Gesicht ist schmal und es gibt offensichtliche Überlappungen zwischen den Rändern des Sperrfeuers und dem Gesicht des Charakters
 BlazePose (https://github.com/tensorflow/tfjs-models/blob/master/pose-detection /src/ blazepose_mediapipe/README.md)
BlazePose (https://github.com/tensorflow/tfjs-models/blob/master/pose-detection /src/ blazepose_mediapipe/README.md)
Hervorragende Genauigkeit und Bereitstellung von Körperpunktinformationen, aber schlechte Leistung
 Beispiel für eine Rückgabedatenstruktur
Beispiel für eine Rückgabedatenstruktur
[{score: 0.8,keypoints: [{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},...],keypoints3D: [{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},...],segmentation: {maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}}]MediaPipe SelfieSegmentation (https://github.com/tensorflow/tfjs -models /blob/master/body-segmentation/src/selfie_segmentation_mediapipe/README.md)
Die Genauigkeit ist ausgezeichnet (wie beim BlazePose-Modell), die CPU-Auslastung ist etwa 15 % geringer als beim BlazePose-Modell und die Leistung ist überlegen , aber die zurückgegebenen Daten stellen keine Gliedmaßenpunktinformationen bereit.
Beispiel für die Datenstruktur zurückgeben /body-segmentation/README.md #bodysegmentationdrawmask), ohne Optimierung beansprucht die CPU etwa 70 %
{maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}Reduzieren Sie die Extraktionsfrequenz und gleichen Sie das Leistungserlebnis aus
Allgemeines Video 30FPS, probieren Sie die Sperrmaske aus (im Folgenden als bezeichnet). Maske), um die Aktualisierungsfrequenz auf 15 FPS zu reduzieren, ist die Erfahrung gut. Es ist immer noch akzeptabel Ich habe festgestellt, dass der Leistungsengpass in toBinaryMask und toDataURL liegt Modell. Versuchen Sie, Ihren eigenen Code zu schreiben, um eine ImageBitmap in eine Maske zu konvertieren, anstatt die von der Open-Source-Bibliothek bereitgestellte Standardimplementierung zu verwenden.
Implementierungsprinzip
const canvas = document.createElement('canvas')canvas.width = videoEl.videoWidthcanvas.height = videoEl.videoHeightasync function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl)const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }const backgroundColor = { r: 0, g: 0, b: 0, a: 255 } const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor) await drawMask(canvas, canvas, mask, 1, 9)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 33)} detect().catch(console.error)Schritte 2 und 3 entsprechen dem Füllen des Inhalts außerhalb des Porträtbereichs mit Schwarz (umgekehrtes Füllen von ImageBitmap), um mit CSS (Maskenbild) zusammenzuarbeiten, andernfalls ist er nur beim Sperren sichtbar schwebt in den Porträtbereich (genau das Gegenteil des Zieleffekts).
globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此时,CPU 占用 33% 左右
多线程优化
我原先认为toDataURL是由浏览器内部实现的,无法再进行优化,现在只有优化toDataURL这个耗时操作了。
虽没有替换实现,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,将耗时任务转移到 Worker 中去, 避免占用主线程,就不会影响用户体验了。
并且ImageBitmap实现了Transferable接口,可被转移所有权,跨 Worker 传递也没有性能损耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以转移到 Worker 中// 用 OffscreenCanvas 实现, 此处略过 const reader = new FileReaderSync()// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替offsecreenCvsEl.convertToBlob({type: 'image/png',quality: 0}).then((blob) => {const dataURL = reader.readAsDataURL(blob)self.postMessage({msgType: 'mask',val: dataURL})}).catch(console.error)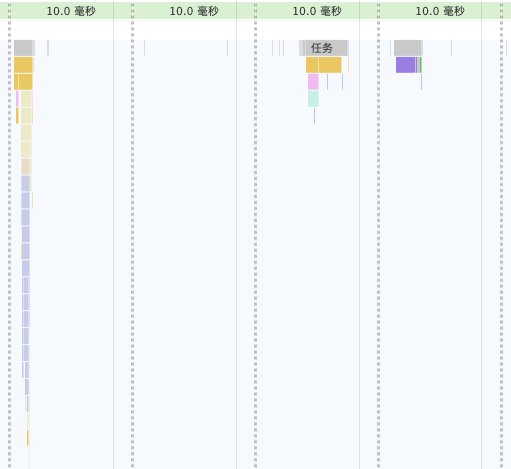
可以看到两个耗时的操作消失了
此时,CPU 占用 15% 左右
降低分辨率
继续分析,上图重新计算样式(紫色部分)耗时约 3ms
Demo 足够简单很容易推测到是这行代码导致的,发现 imgStr 大概 100kb 左右(视频分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通过canvas缩小图片尺寸(360P甚至更低),再进行推理。
优化后,导出的 imgStr 大概 12kb,重新计算样式耗时约 0.5ms。
此时,CPU 占用 5% 左右

启动条件优化
虽然提取 Mask 整个过程的 CPU 占用已优化到可喜程度。
当在画面没人的时候,或没有弹幕时候,可以停止计算,实现 0 CPU 占用。
无弹幕判断比较简单(比如 10s 内收超过两条弹幕则启动计算),也不在该 SDK 实现范围,略过
判定画面是否有人
第一步中为了高性能,选择的模型只有ImageBitmap,并没有提供肢体点位信息,所以只能使用getImageData返回的像素点值来判断画面是否有人。
画面无人时,CPU 占用接近 0%
发布构建优化
依赖包的提交较大,构建出的 bundle 体积:684.75 KiB / gzip: 125.83 KiB
所以,可以进行异步加载SDK,提升页面加载性能。
- 分别打包一个 loader,一个主体
- 由业务方 import loader,首次启用时异步加载主体
这个两步前端工程已经非常成熟了,略过细节。
运行效果

总结
过程
- 选择高性能模型后,初始状态 CPU 70%
- 降低 Mask 刷新频率(15FPS),CPU 50%
- 重写开源库实现(toBinaryMask),CPU 33%
- 多线程优化,CPU 15%
- 降低分辨率,CPU 5%
- 判断画面是否有人,无人时 CPU 接近 0%
CPU 数值指主线程占用
注意事项
- 兼容性:Chrome 79及以上,不支持 Firefox、Safari。因为使用了OffscreenCanvas
- 不应创建多个或多次创建segmenter实例(bodySegmentation.createSegmenter),如需复用请保存实例引用,因为:
- 创建实例时低性能设备会有明显的卡顿现象
- 会内存泄露;如果无法避免,这是mediapipe 内存泄露 解决方法(https://github.com/google/mediapipe/issues/2819#issuecomment-1160335349)
经验
- 优化完成之后,提取并应用 Mask 关键计算量在 GPU (30%左右),而不是 CPU
- 性能优化需要业务场景分析,防挡弹幕场景可以使用低分辨率、低刷新率的 mask-image,能大幅减少计算量
- 该方案其他应用场景:
- 替换/模糊人物背景
- 人像马赛克
- 人像抠图
- 卡通头套,虚拟饰品,如猫耳朵、兔耳朵、带花、戴眼镜什么的(换一个模型,略改)
- 关注Web 神经网络 API (https://mp.weixin.qq.com/s/v7-xwYJqOfFDIAvwIVZVdg)进展,以后实现相关功能也许会更简单
本期作者

刘俊
Leitender Entwicklungsingenieur bei Bilibili
Das obige ist der detaillierte Inhalt vonEchtzeitschutz vor Gesichtsblockierungsangriffen im Web (basierend auf maschinellem Lernen). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Die Methode zur Anpassung der Größe der Größe der Größe der Größe in CSS ist mit Hintergrundfarben einheitlich. In der täglichen Entwicklung begegnen wir häufig Situationen, in denen wir die Details der Benutzeroberfläche wie Anpassung anpassen müssen ...
 Wie zeige ich die lokal installierte 'Jingnan Mai Round Body' auf der Webseite richtig?
Apr 05, 2025 pm 10:33 PM
Wie zeige ich die lokal installierte 'Jingnan Mai Round Body' auf der Webseite richtig?
Apr 05, 2025 pm 10:33 PM
Mit lokal installierten Schriftdateien auf Webseiten kürzlich habe ich eine kostenlose Schriftart aus dem Internet heruntergeladen und sie erfolgreich in mein System installiert. Jetzt...
 Der Text unter Flex -Layout wird weggelassen, aber der Behälter wird geöffnet? Wie löst ich es?
Apr 05, 2025 pm 11:00 PM
Der Text unter Flex -Layout wird weggelassen, aber der Behälter wird geöffnet? Wie löst ich es?
Apr 05, 2025 pm 11:00 PM
Das Problem der Containeröffnung aufgrund einer übermäßigen Auslassung von Text unter Flex -Layout und Lösungen werden verwendet ...
 Warum wird ein bestimmtes Div -Element im Edge -Browser nicht angezeigt? Wie löst ich dieses Problem?
Apr 05, 2025 pm 08:21 PM
Warum wird ein bestimmtes Div -Element im Edge -Browser nicht angezeigt? Wie löst ich dieses Problem?
Apr 05, 2025 pm 08:21 PM
Wie löst ich das durch User Agent Style Sheets verursachte Anzeigeproblem? Bei Verwendung des Edge -Browsers kann ein Div -Element im Projekt nicht angezeigt werden. Nachdem ich nachgesehen hatte, habe ich gepostet ...
 Wie verwende ich lokal installierte Schriftdateien auf Webseiten?
Apr 05, 2025 pm 10:57 PM
Wie verwende ich lokal installierte Schriftdateien auf Webseiten?
Apr 05, 2025 pm 10:57 PM
So verwenden Sie lokal installierte Schriftartdateien auf Webseiten. Wenn Sie diese Situation in der Webseitenentwicklung gestoßen haben: Sie haben eine Schriftart auf Ihrem Computer installiert ...
 Warum wirkt sich negative Margen in einigen Fällen nicht wirksam? Wie löst ich dieses Problem?
Apr 05, 2025 pm 10:18 PM
Warum wirkt sich negative Margen in einigen Fällen nicht wirksam? Wie löst ich dieses Problem?
Apr 05, 2025 pm 10:18 PM
Warum werden negative Margen in einigen Fällen nicht wirksam? Während der Programmierung negative Margen in CSS (negativ ...
 Wie steuern Sie die obere und das Ende der Seiten in den Browser -Druckeinstellungen über JavaScript oder CSS?
Apr 05, 2025 pm 10:39 PM
Wie steuern Sie die obere und das Ende der Seiten in den Browser -Druckeinstellungen über JavaScript oder CSS?
Apr 05, 2025 pm 10:39 PM
So verwenden Sie JavaScript oder CSS, um die obere und das Ende der Seite in den Druckeinstellungen des Browsers zu steuern. In den Druckeinstellungen des Browsers gibt es eine Option, um zu steuern, ob das Display ist ...
 Warum können benutzerdefinierte Stilblätter auf lokalen Webseiten in Safari, nicht jedoch auf Baidu -Seiten wirksam?
Apr 05, 2025 pm 05:15 PM
Warum können benutzerdefinierte Stilblätter auf lokalen Webseiten in Safari, nicht jedoch auf Baidu -Seiten wirksam?
Apr 05, 2025 pm 05:15 PM
Diskussion über die Verwendung benutzerdefinierter Stylesheets in Safari heute Wir werden eine Frage zur Anwendung von benutzerdefinierten Stylesheets für Safari Browser diskutieren. Front-End-Anfänger ...
