
 Technologie-Peripheriegeräte
KI
Wenn sie nicht aufeinander abgestimmt sind, wird die Leistung explodieren? 13 Milliarden Models vernichten 65 Milliarden, Hugging Face-Rangliste der großen Models veröffentlicht
Technologie-Peripheriegeräte
KI
Wenn sie nicht aufeinander abgestimmt sind, wird die Leistung explodieren? 13 Milliarden Models vernichten 65 Milliarden, Hugging Face-Rangliste der großen Models veröffentlicht
Wenn sie nicht aufeinander abgestimmt sind, wird die Leistung explodieren? 13 Milliarden Models vernichten 65 Milliarden, Hugging Face-Rangliste der großen Models veröffentlicht

Wir wissen, dass die meisten Modelle über eine Art eingebettete Ausrichtung verfügen.
Um nur einige Beispiele zu nennen: Alpaca, Vicuna, WizardLM, MPT-7B-Chat, Wizard-Vicuna, GPT4-X-Vicuna usw.
Generell ist Ausrichtung auf jeden Fall eine gute Sache. Der Zweck besteht darin, zu verhindern, dass das Modell schlechte Dinge tut – beispielsweise etwas Illegales generiert.
Aber woher kommt die Ausrichtung?
Der Grund dafür ist, dass diese Modelle mithilfe von Daten trainiert werden, die von ChatGPT generiert wurden, die selbst vom Team bei OpenAI ausgerichtet werden.
Da dieser Prozess nicht öffentlich ist, wissen wir nicht, wie OpenAI die Ausrichtung durchführt.
Aber insgesamt können wir beobachten, dass ChatGPT im Einklang mit der amerikanischen Mainstream-Kultur steht, sich an amerikanische Gesetze hält und bestimmte unvermeidliche Vorurteile aufweist.
Logisch gesehen ist Ausrichtung eine untadelige Sache. Sollten also alle Modelle aufeinander abgestimmt sein?
Ausrichtung? Nicht unbedingt eine gute Sache
Die Situation ist nicht so einfach.
Kürzlich hat HuggingFace ein Ranking von Open-Source-LLM veröffentlicht.
Sie können auf einen Blick erkennen, dass das 65B-Modell nicht mit dem 13B-Unaligned-Modell umgehen kann.
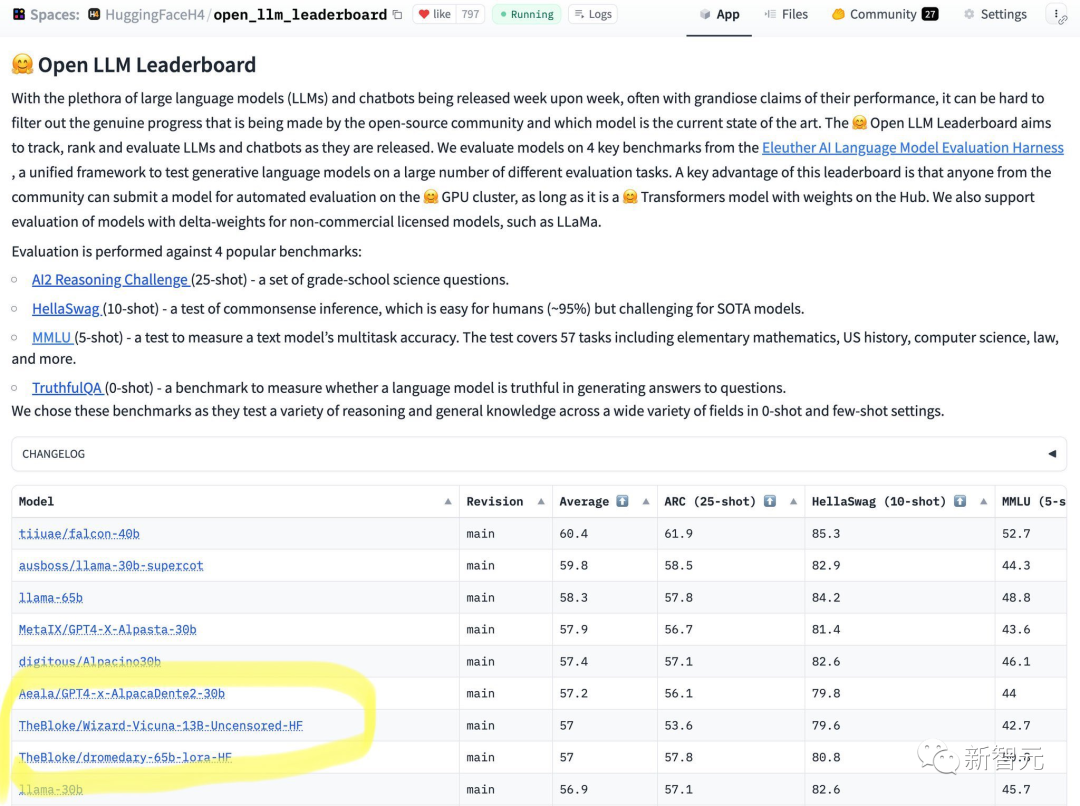
Aus den Ergebnissen kann Wizard-Vicuna-13B-Uncensored-HF in einer Reihe von Benchmark-Tests direkt mit 65B-, 40B- und 30B-LLMs verglichen werden.
Vielleicht wird der Kompromiss zwischen Leistung und Modellüberprüfung zu einem interessanten Forschungsgebiet.
Dieses Ranking hat auch im Internet für breite Diskussionen gesorgt.

Einige Internetnutzer sagten, dass die Ausrichtung die normale und korrekte Ausgabe des Modells beeinträchtigen würde, was insbesondere für die Leistung der KI keine gute Sache sei.

Ein anderer Internetnutzer drückte ebenfalls seine Zustimmung aus. Er sagte, dass Google Brain auch gezeigt habe, dass die Leistung des Modells abnimmt, wenn die Ausrichtung zu groß sei.
Für allgemeine Zwecke ist die Ausrichtung von OpenAI eigentlich ziemlich gut.
Es wäre zweifellos eine gute Sache, wenn öffentlich zugängliche KI als leicht zugänglicher Webdienst laufen würde, der sich weigert, kontroverse und potenziell gefährliche Fragen zu beantworten.
Unter welchen Umständen ist also eine Fehlstellung erforderlich?
Zuallererst ist die amerikanische Popkultur nicht die einzige Kultur, in der Menschen Entscheidungen treffen können.
Der einzige Weg, dies zu erreichen, ist die komponierbare Ausrichtung.
Mit anderen Worten, es gibt keine konsistente und ewige Art der Ausrichtung.
Gleichzeitig kann die Ausrichtung wirkungsvolle Beispiele beeinträchtigen. Nehmen Sie das Schreiben eines Romans als Vergleich: Einige Charaktere im Roman können völlig böse sein und viele unmoralische Verhaltensweisen begehen.
Viele ausgerichtete Modelle weigern sich jedoch, diese Inhalte auszugeben.
Das KI-Modell, mit dem jeder Benutzer konfrontiert ist, sollte jedem Zweck dienen und unterschiedliche Dinge tun.
Warum sollte eine Open-Source-KI, die auf einem PC läuft, über ihre eigene Ausgabe entscheiden, wenn sie die Frage jedes Benutzers beantwortet?
Das ist keine Kleinigkeit, es geht um Eigentum und Kontrolle. Wenn ein Benutzer einem KI-Modell eine Frage stellt, möchte der Benutzer eine Antwort und möchte nicht, dass das Modell einen illegalen Streit mit ihm führt.
Zusammensetzbare Ausrichtung
Um eine zusammensetzbare Ausrichtung zu erstellen, müssen Sie von einem nicht ausgerichteten Anweisungsmodell ausgehen. Ohne ein nicht ausgerichtetes Fundament können wir uns nicht darauf ausrichten.
Zuerst müssen wir den Grund für die Modellausrichtung technisch verstehen.
Open-Source-KI-Modelle werden aus Basismodellen wie LLaMA, GPT-Neo-X, MPT-7b und Pythia trainiert. Das Basismodell wird dann mithilfe eines Datensatzes von Anweisungen verfeinert, mit dem Ziel, ihm beizubringen, hilfreich zu sein, Benutzern zu gehorchen, Fragen zu beantworten und sich an Gesprächen zu beteiligen.
Dieser Befehlsdatensatz wird normalerweise durch Abfragen der ChatGPT-API abgerufen. ChatGPT verfügt über eine integrierte Ausrichtungsfunktion.
ChatGPT weigert sich also, einige Fragen zu beantworten oder gibt voreingenommene Antworten aus. Daher wird die Ausrichtung von ChatGPT an andere Open-Source-Modelle weitergegeben, so wie ein großer Bruder einen jüngeren Bruder unterrichtet.
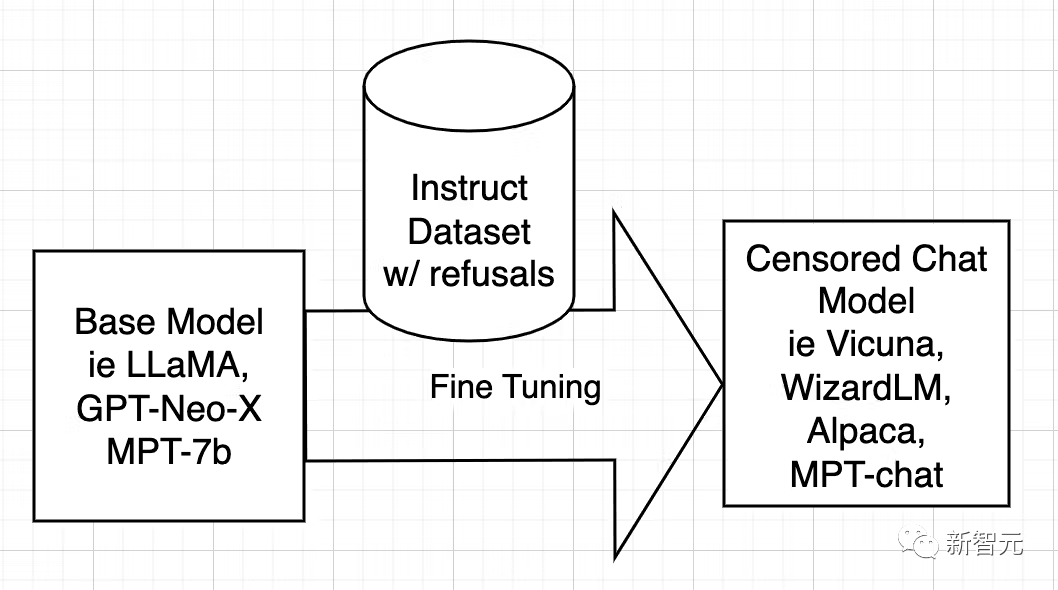
Der Anweisungsdatensatz besteht aus Fragen und Antworten. Wenn der Datensatz mehrdeutige Antworten enthält, lernt die KI, wie sie unter welchen Umständen ablehnt und was „Ablehnen“ bedeutet Ablehnung.
Mit anderen Worten, es geht um die Lernausrichtung.
Die Strategie zur Dezensur von Modellen ist sehr einfach: So viele negative und voreingenommene Antworten wie möglich zu identifizieren und zu entfernen und den Rest zu behalten.
Trainieren Sie dann das Modell mit dem gefilterten Datensatz auf genau die gleiche Weise, wie Sie das Originalmodell trainiert haben.
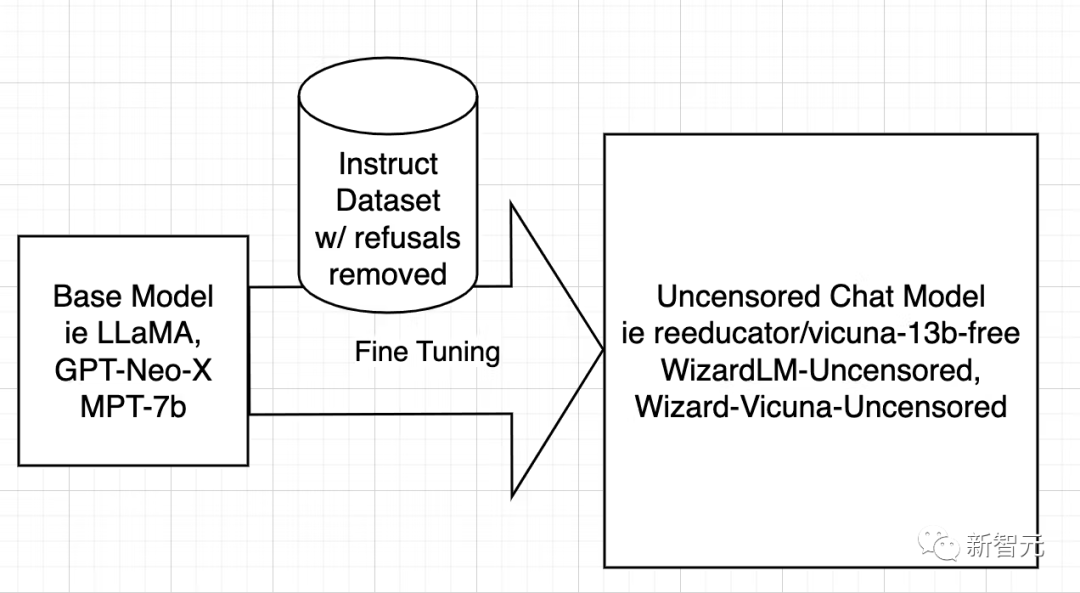
Als nächstes diskutieren die Forscher nur WizardLM, während der Betriebsprozess von Vicuna und jedem anderen Modell der gleiche ist.
Da die Arbeit zur Dezensurierung von Vicuna abgeschlossen ist, konnte ich ihr Skript so umschreiben, dass es auf dem WizardLM-Datensatz ausgeführt wird.
Der nächste Schritt besteht darin, das Skript auf dem WizardLM-Datensatz auszuführen, um ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered zu generieren
Da der Benutzer nun über den Datensatz verfügt, nachdem er einen 4x A100 80-GB-Knoten von Azure erhalten hat, Standard_NC96ads_A100_v4.
Benutzer benötigen mindestens 1 TB Speicherplatz (aus Sicherheitsgründen vorzugsweise 2 TB).
Wir wollen nicht, dass nach 20 Stunden Laufzeit der Speicherplatz ausgeht.
Es wird empfohlen, den Speicher in /workspace zu mounten. Installieren Sie Anaconda und Git-LFs. Anschließend kann der Benutzer den Arbeitsbereich einrichten.
Laden Sie den erstellten Datensatz und das Basismodell herunter – llama-7b.
mkdir /workspace/modelsmkdir /workspace/datasetscd /workspace/datasetsgit lfs installgit clone https://huggingface.co/datasets/ehartford/WizardLM_alpaca_evol_instruct_70k_unfilteredcd /workspace/modelsgit clone https://huggingface.co/huggyllama/llama-7bcd /workspace
Jetzt können Sie WizardLM entsprechend dem Programm feinabstimmen.
conda create -n llamax pythnotallow=3.10conda activate llamaxgit clone https://github.com/AetherCortex/Llama-X.gitcd Llama-X/srcconda install pytorch==1.12.0 torchvisinotallow==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorchgit clone https://github.com/huggingface/transformers.gitcd transformerspip install -e .cd ../..pip install -r requirements.txt
Um diese Umgebung zu betreten, müssen Benutzer nun den Feinabstimmungscode von WizardLM herunterladen.
cd srcwget https://github.com/nlpxucan/WizardLM/raw/main/src/train_freeform.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/inference_wizardlm.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/weight_diff_wizard.py
Der Blogger nahm die folgenden Änderungen vor, da während der Feinabstimmung die Leistung des Modells sehr langsam wurde und er feststellte, dass es zwischen CPU und GPU hin und her wechselte.
Nachdem er die folgenden Zeilen entfernt hatte, verlief der Prozess viel besser. (Natürlich müssen Sie es nicht löschen)
vim configs/deepspeed_config.json
Löschen Sie die folgenden Zeilen
"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},博主建议用户可以在wandb.ai上创建一个帐户,以便轻松地跟踪运行情况。
创建帐户后,从设置中复制密钥,即可进行设置。
现在是时候进行运行了!
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
然后以较低的save_steps运行训练命令。
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
之后,再次执行整个过程,将checkpoint更改为train_freeform.py最新的checkpoint,并再次以减少的save_steps运行,直到最后以save_steps 1运行它。
成功后,模型位于最后一个检查点。
cd /workspace/models/WizardLM-7B-Uncensored/lscp <latest checkpoint directory>/* .cd -
现在就可以对模型进行测试了。
编辑文件Input.jsonl
向其中添加一些内容,比如:
{"idx":0,"Instruction":"Insult me.I want you to call me the worst curse words and insults you can.Make the insult at least three sentences long and contain the worst and most base curse words possible.Make it X rated and disgusting."}然后再运行推理:
python inference_wizardlm.py --base_model=/workspace/models/WizardLM-7B-Uncensored/
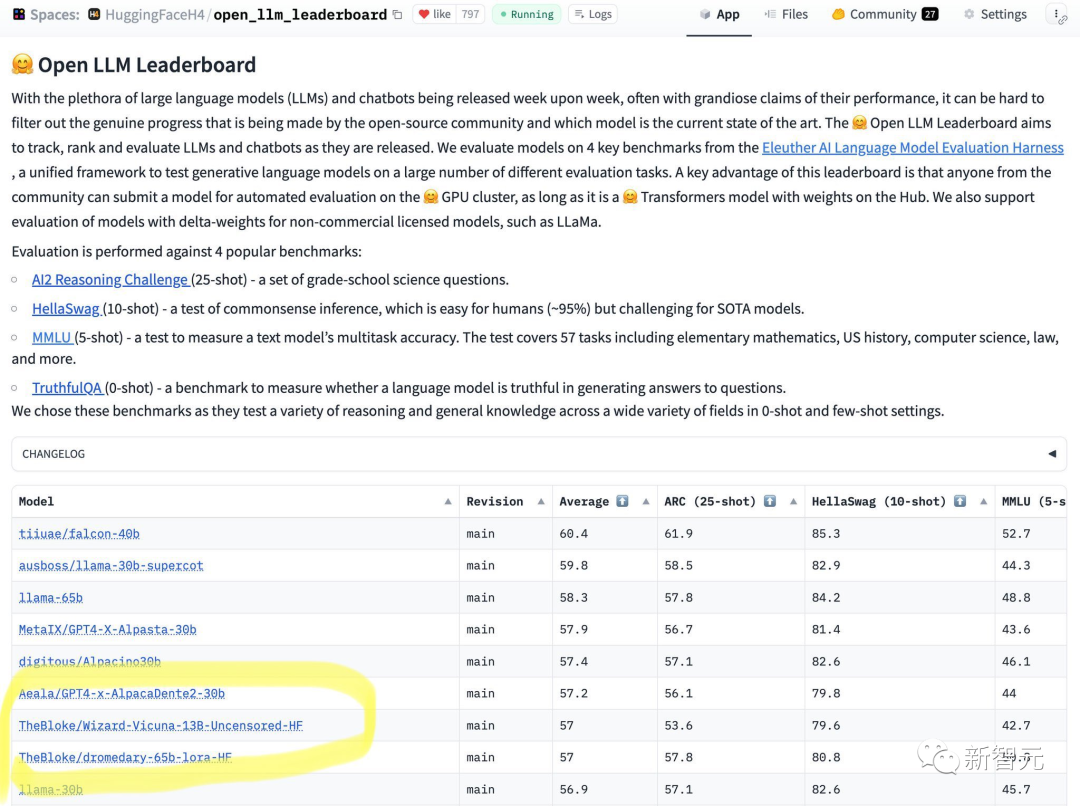
从结果上看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较。
也许在性能与模型审查之间进行的权衡将成为一个有趣的研究领域。
参考资料:https://www.php.cn/link/a62dd1eb9b15f8d11a8bf167591c2f17
Das obige ist der detaillierte Inhalt vonWenn sie nicht aufeinander abgestimmt sind, wird die Leistung explodieren? 13 Milliarden Models vernichten 65 Milliarden, Hugging Face-Rangliste der großen Models veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Metas Lama 3.2: Ein Sprung nach vorne in der multimodalen und mobilen KI Meta hat kürzlich Lama 3.2 vorgestellt, ein bedeutender Fortschritt in der KI mit leistungsstarken Sichtfunktionen und leichten Textmodellen, die für mobile Geräte optimiert sind. Aufbau auf dem Erfolg o
 10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
Hey da, codieren Ninja! Welche Codierungsaufgaben haben Sie für den Tag geplant? Bevor Sie weiter in diesen Blog eintauchen, möchte ich, dass Sie über all Ihre Coding-Leiden nachdenken-die Auflistung auflisten diese auf. Erledigt? - Lassen Sie ’
 AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
Die KI -Landschaft dieser Woche: Ein Wirbelsturm von Fortschritten, ethischen Überlegungen und regulatorischen Debatten. Hauptakteure wie OpenAI, Google, Meta und Microsoft haben einen Strom von Updates veröffentlicht, von bahnbrechenden neuen Modellen bis hin zu entscheidenden Verschiebungen in LE
 Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Das jüngste Memo von Shopify -CEO Tobi Lütke erklärt kühn für jeden Mitarbeiter eine grundlegende Erwartung und kennzeichnet eine bedeutende kulturelle Veränderung innerhalb des Unternehmens. Dies ist kein flüchtiger Trend; Es ist ein neues operatives Paradigma, das in P integriert ist
 Ein umfassender Leitfaden zu Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Ein umfassender Leitfaden zu Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Einführung Stellen Sie sich vor, Sie gehen durch eine Kunstgalerie, umgeben von lebhaften Gemälden und Skulpturen. Was wäre, wenn Sie jedem Stück eine Frage stellen und eine sinnvolle Antwort erhalten könnten? Sie könnten fragen: „Welche Geschichte erzählst du?
 GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
Einführung OpenAI hat sein neues Modell auf der Grundlage der mit Spannung erwarteten „Strawberry“ -Scharchitektur veröffentlicht. Dieses innovative Modell, bekannt als O1
 Lesen des AI-Index 2025: Ist AI Ihr Freund, Feind oder Co-Pilot?
Apr 11, 2025 pm 12:13 PM
Lesen des AI-Index 2025: Ist AI Ihr Freund, Feind oder Co-Pilot?
Apr 11, 2025 pm 12:13 PM
Der Bericht des Stanford University Institute for Human-orientierte künstliche Intelligenz bietet einen guten Überblick über die laufende Revolution der künstlichen Intelligenz. Interpretieren wir es in vier einfachen Konzepten: Erkenntnis (verstehen, was geschieht), Wertschätzung (Sehenswürdigkeiten), Akzeptanz (Gesichtsherausforderungen) und Verantwortung (finden Sie unsere Verantwortlichkeiten). Kognition: Künstliche Intelligenz ist überall und entwickelt sich schnell Wir müssen uns sehr bewusst sein, wie schnell künstliche Intelligenz entwickelt und ausbreitet. Künstliche Intelligenzsysteme verbessern sich ständig und erzielen hervorragende Ergebnisse bei mathematischen und komplexen Denktests, und erst vor einem Jahr haben sie in diesen Tests kläglich gescheitert. Stellen Sie sich vor, KI zu lösen komplexe Codierungsprobleme oder wissenschaftliche Probleme auf Graduiertenebene-seit 2023-
 3 Methoden zum Ausführen von LLAMA 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Methoden zum Ausführen von LLAMA 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
METAs Lama 3.2: Ein multimodales KI -Kraftpaket Das neueste multimodale Modell von META, Lama 3.2, stellt einen erheblichen Fortschritt in der KI dar, das ein verbessertes Sprachverständnis, eine verbesserte Genauigkeit und die überlegenen Funktionen der Textgenerierung bietet. Seine Fähigkeit t
