
 Technologie-Peripheriegeräte
KI
NetEase Yidun AI Lab-Artikel für ICASSP 2023 ausgewählt! Die schwarze Technologie macht die Spracherkennung „zuhörender' und genauer
Technologie-Peripheriegeräte
KI
NetEase Yidun AI Lab-Artikel für ICASSP 2023 ausgewählt! Die schwarze Technologie macht die Spracherkennung „zuhörender' und genauer
NetEase Yidun AI Lab-Artikel für ICASSP 2023 ausgewählt! Die schwarze Technologie macht die Spracherkennung „zuhörender' und genauer

2023-06-07 17:42:41 Autor: Li Wenwen
Jeder Science-Fiction-Fan sehnt sich nach der Zukunft, in der er mit nur wenigen Worten ein interstellares Raumschiff starten und die Sterne und das Meer erobern kann, so als würde er mit einem alten Freund sprechen, oder nach Jarvis, dem Butler mit künstlicher Intelligenz, der erschaffen kann Eine Welt mit nur wenigen Dialogworten. Tatsächlich ist dieses Bild nicht weit von uns entfernt – es ist uns so nah wie Siri im iPhone. Dahinter steckt die automatische Spracherkennung. Diese Schlüsseltechnologie kann Sprache in Text oder Befehle umwandeln, die von Computern erkannt werden können, und so eine bequeme, effiziente und intelligente Interaktion zwischen Mensch und Computer ermöglichen.
Mit der Entwicklung von KI-Technologien wie Deep Learning hat die Spracherkennungstechnologie enorme Fortschritte gemacht – nicht nur die Erkennungsgenauigkeit wurde erheblich verbessert, sondern sie kann auch Probleme wie Akzente, Lärm und Hintergrundgeräusche besser bewältigen. Da die Technologie jedoch weiterhin im Leben und in der Wirtschaft Anwendung findet, wird es immer noch zu Engpässen kommen. Schließlich gibt es zu viele praktische Faktoren, die von der theoretischen Forschung bis zur praktischen Anwendung, von Papieren bis hin zu Produkten, berücksichtigt werden müssen. Wie kann die Spracherkennung die Inhaltsüberprüfung besser unterstützen? Wie kann die Erkennungsaktion selbst wie das menschliche Gehirn auf dem Verständnis des Kontexts basieren und genauere Antworten zu geringeren Kosten geben? Yidun AI Lab, eine Tochtergesellschaft von NetEase Intelligence, hat einen neuen Ansatz verfolgt.
Yidun hat eine weitere schwarze Technologie und das intelligente Unternehmen ist auf dem Weg in die Welt!
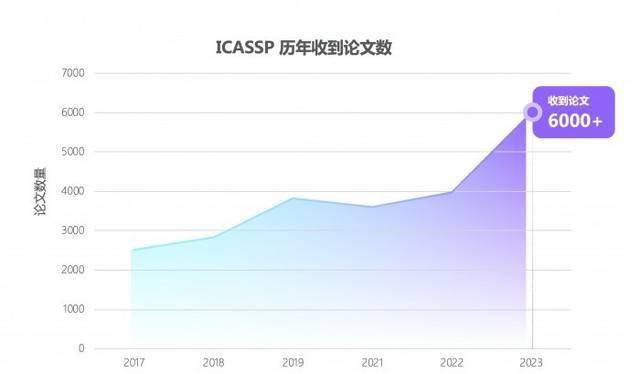
Kürzlich hat die globale Sprach- und Akustikkonferenz ICASSP 2023 die Liste der ausgewählten Beiträge bekannt gegeben, und der von Yidun AI Lab, einer Tochtergesellschaft von NetEase Intelligence Enterprise, eingereichte Beitrag wurde erfolgreich angenommen. Dieses Jahr findet die 48. ICASSP-Konferenz statt und es ist auch die erste Offline-Konferenz nach der Epidemie. Obwohl die Konferenzbeamten die endgültige Anzahl der angenommenen Beiträge noch nicht bekannt gegeben haben, ist die Anzahl der eingereichten Beiträge im Vergleich zu den Vorjahren um 50 % gestiegen erstaunliche 6.000+.
Angesichts eines solch harten Wettbewerbs verlässt sich das NetEase Yidun AILab-Team auf einen Artikel zur Spracherkennung „Verbesserung von CTC-basierten ASRModels mit Gated Interplayer Collaboration (CTC-basierte Modellverbesserung zur Erzielung einer stärkeren Modellstruktur)“ Er stach hervor und habe erfolgreich ein Ticket für die Teilnahme an der Offline-Konferenz in Rhodos, Griechenland, erhalten.
„GIC“ hilft der Spracherkennung, noch weiter zu gehen
Spracherkennung ist im Wesentlichen die Umwandlung von Sprachsequenzen in Textsequenzen normalerweise werden drei Arten von Modellen verwendet: CTC, Aufmerksamkeitsbasierter und RNN-Transducer. Sie verwenden unterschiedliche Methoden, um die Aufgabe abzuschließen.
CTC: Basierend auf dem neuronalen Netzwerkmodell werden die Modellparameter während des Trainingsprozesses durch Backpropagation aktualisiert, um die Verlustfunktion zu minimieren. Dieser Algorithmus führt „Leerzeichen“ ein, um bedeutungslose Zeichen oder Leerzeichen darzustellen. CTC eignet sich für die Verarbeitung von Daten mit großen Unterschieden in der Eingabe- und Ausgabelänge, z. B. für die Zuordnung akustischer Merkmale zu Text bei der Spracherkennung
Aufmerksamkeitsbasiert: Der Aufmerksamkeitsmechanismus basiert ebenfalls auf dem neuronalen Netzwerkmodell und verwendet eine Technologie namens „Aufmerksamkeit“, um die Eingabe zu gewichten. Bei jedem Zeitschritt berechnet das Modell einen verteilten Gewichtsvektor basierend auf dem aktuellen Status und allen Eingaben und wendet ihn auf alle Eingaben an, um einen gewichteten Durchschnitt als Ausgabe zu erzeugen. Diese Methode ermöglicht es dem Modell, sich besser auf einige Informationen im Zusammenhang mit der aktuellen Vorhersage zu konzentrieren
RNN-Transducer: Transkriptor, dieser Algorithmus kombiniert das Encoder-Decoder-Framework und autoregressive Modellierungsideen und berücksichtigt gleichzeitig die Interaktion zwischen den Sätzen in der Ausgangssprache und den generierten Teilsätzen in der Zielsprache, wenn er die Zielsequenz generiert. Im Gegensatz zu den beiden anderen Methoden unterscheidet RNN-Transducer nicht klar zwischen den Encoder- und Decoderstufen und konvertiert direkt von der Quellsprache in die Zielsprache, sodass gleichzeitig die Interaktion zwischen Sätzen in der Quellsprache und generierten Teilsätzen in der Zielsprache berücksichtigt werden kann Zeiteffekt.
Im Vergleich zu den beiden letztgenannten hat CTC zwar natürliche nicht-autoregressive Dekodierungseigenschaften und eine relativ schnellere Dekodierungsgeschwindigkeit, weist jedoch dennoch Leistungsnachteile auf:
1. Der CTC-Algorithmus legt die bedingte Unabhängigkeitsannahme fest, das heißt, CTC geht davon aus, dass die Ausgaben jedes Zeitschritts unabhängig sind. Dies ist für Spracherkennungsaufgaben nicht sinnvoll. Wenn die Aussprache „ji rou“ ausgesprochen wird, sollte der vorhergesagte Textinhalt in verschiedenen Kontexten unterschiedlich sein. Wenn der obige Satz „Ich esse gerne“ lautet, sollte die Wahrscheinlichkeit für „Huhn“ höher sein. Wenn der obige Satz „Er hat Arme“ lautet, sollte die Wahrscheinlichkeit für „Muskel“ höher sein. Wenn Sie mit CTC trainieren, ist es leicht, lustige Texte wie „Ich esse gerne Muskeln“ auszugeben, während Sie das oben Gesagte ignorieren
2. Aus Modellierungssicht sagen das Aufmerksamkeitsmodell und das RNN-Transducer-Modell die Ausgabe des aktuellen Zeitschritts basierend auf der Eingabe und der Ausgabe des vorherigen Zeitschritts voraus, während das CTC-Modell nur die Eingabe zur Vorhersage verwendet Die aktuelle Ausgabe im CTC-Modell Im Modellierungsprozess werden Textinformationen nur als Überwachungssignal an das Netzwerk zurückgegeben und dienen nicht als Eingabe für das Netzwerk, um die Vorhersage des Modells explizit zu fördern.
Wir hoffen, die beiden oben genannten Nachteile so weit wie möglich zu lösen und gleichzeitig die Effizienz der CTC-Dekodierung beizubehalten. Daher möchten wir vom CTC-Modell selbst ausgehen und ein leichtes Modul entwerfen, um Textinformationen in das CTC-basierte Modell einzuführen, damit das Modell akustische und Textinformationen integrieren, die Interaktion zwischen Textsequenzkontexten erlernen und dadurch das Problem lindern kann CTC-Algorithmus. Die bedingte Unabhängigkeitsannahme von . Dabei sind wir jedoch auf zwei Probleme gestoßen: Wie fügt man Textinformationen in das CTC-Modell (Encoder + CTC-Struktur) ein? Wie lassen sich Textmerkmale und akustische Merkmale adaptiv verschmelzen?
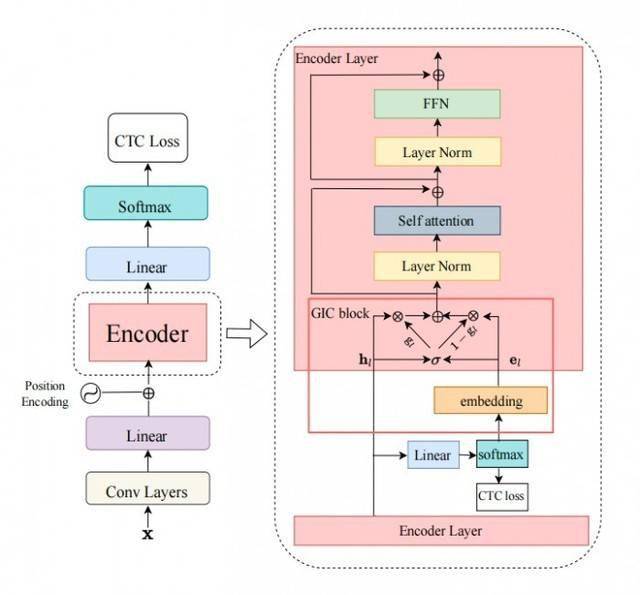
Um die oben genannten Ziele zu erreichen,haben wir den Gated Interlayer Collaboration (GIC)-Mechanismus entwickelt. Das GIC-Modul umfasst hauptsächlich eine Einbettungsschicht und eine Gate-Einheit. Unter anderem wird die Einbettungsschicht verwendet, um Textinformationen für jeden Audioeingaberahmen zu generieren, und die Gating-Einheit wird verwendet, um Textinformationen und akustische Informationen adaptiv zu verschmelzen.
Konkret basiert unsere Methode auf dem Multi-Task-Learning-Framework und verwendet die Ausgabe der mittleren Schicht des Encoder-Moduls (Encoder), um den Hilfs-CTC-Verlust zu berechnen. Die Zielfunktion des gesamten Netzwerks ist die letzte Schicht der CTC-Verluste und die mittlere Hilfsschicht. Gewichtete Summe der CTC-Verluste. GIC verwendet die Vorhersage der mittleren Schicht des Netzwerks, dh die Wahrscheinlichkeitsverteilung der Softmax-Ausgabe, als Soft-Label jedes Frames und die Summe der Punktprodukt-Einbettungsschichtmatrizen als Textdarstellung jedes Frames.Schließlich werden die generierte Textdarstellung und die akustische Darstellung durch eine Gating-Einheit adaptiv verschmolzen und zu einer neuen Funktionseingabe für die nächste Ebene. Die neuen Funktionen kombinieren derzeit Textfunktionen und akustische Funktionen, sodass die nächste Ebene des Encoder-Moduls akustische Sequenzkontextinformationen und Textsequenzkontextinformationen lernen kann. Der Rahmen des gesamten Modells ist in der folgenden Abbildung dargestellt:
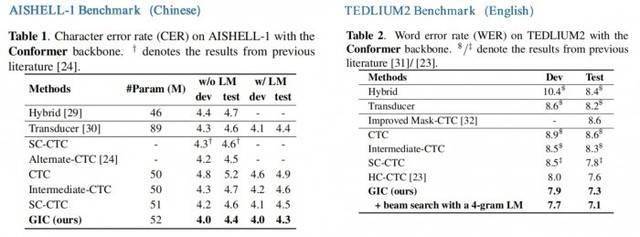
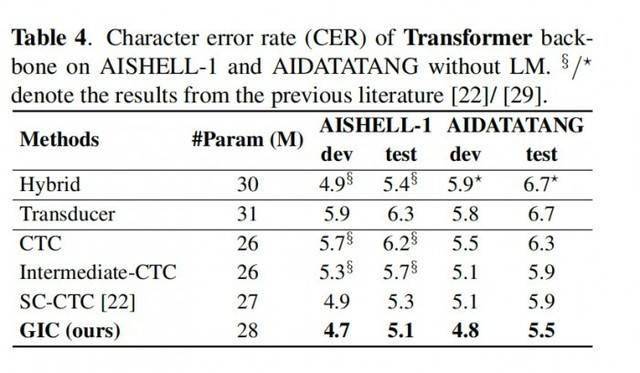
Experimente mit den Conformer- und Transformer-Modellen zeigen:1. GIC
unterstützt die Szenenerkennung sowohl auf Chinesisch als auch auf Englisch und hat erhebliche Leistungsverbesserungen bei der Genauigkeit erzielt;
2. Die Leistung des GIC-Modells übertrifft die von Aufmerksamkeits- und RNN-Transducer-Modellen mit der gleichen Parameterskala und hat den Vorteil der nicht-autoregressiven Dekodierung, was zu einer um ein Vielfaches verbesserten Dekodierungsgeschwindigkeit führt3. Im Vergleich zum ursprünglichen CTC-Modell weist GIC eine relative Leistungsverbesserung von weit mehr als 10 % in mehreren Open-Source-Datensätzen auf.
ConformerFazit unter dem Modell
Transformer Fazit zum Modell
GIC bringt große Verbesserungen der Leistung von CTC-Modellen. Im Vergleich zum ursprünglichen CTC-Modell bringt das GIC-Modul etwa 2 Millionen zusätzliche Parameter mit. Darunter wird die lineare Schicht, die zur Berechnung des Hilfs-CTC-Verlusts der mittleren Schicht verwendet wird, mit der letzten Schicht geteilt und bringt keine zusätzlichen Parameter mit. Mehrere mittlere Schichten teilen sich die Einbettungsschicht, was 256 * 5000 Parameter ergibt, was ungefähr 1,3 Millionen entspricht. Darüber hinaus beträgt die Menge an zusätzlichen Parametern, die für mehrere Control-Gate-Einheiten erforderlich sind, 256*256*2*k, also insgesamt etwa 0,6 Millionen. Führende Technologie schafft fortschrittliches Geschäft
Der GIC im Dokument wurde im Content-Review-Geschäft von NetEase Yidun angewendet.
Als One-Stop-Marke für die Risikokontrolle digitaler Inhalte unter NetEase Intelligence konzentriert sich Yidun seit langem auf Technologieforschung und -entwicklung sowie Innovationen in den Bereichen Risikokontrolle digitaler Inhalte und Anti-Spam-Informationen. Unter anderem bietet Yidun für digitale Inhalte, die Ton als Träger verwenden, eine Vielzahl von Audio-Content-Audit-Engines an, darunter verschiedene Arten von Audioinhalten wie Lieder, Radio, Fernsehprogramme, Live-Übertragungen usw., um Inhalte umgehend zu erkennen und zu filtern die sensible, illegale und vulgäre Inhalte enthalten, wodurch die sozialen Auswirkungen schlechter Inhalte verringert und eine gute Netzwerkumgebung geschaffen werden. Für Audio mit spezifischem semantischen Inhalt verwendet Yidun Spracherkennungstechnologie, um den Sprachinhalt in der Audiodatei in Textinhalt zu transkribieren, und verwendet dann das Erkennungsmodul, um den Text zu analysieren und zu verarbeiten, wodurch eine automatische Überprüfung und Filterung des Audioinhalts realisiert wird.
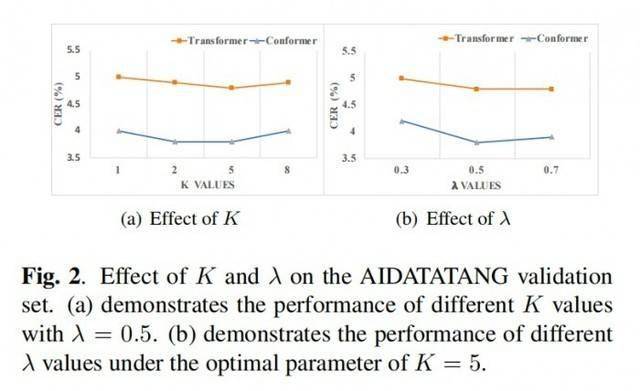
Daher hängt die Genauigkeit der Spracherkennung eng mit der Effizienz und Genauigkeit der Überprüfung von Audioinhalten zusammen und wirkt sich direkt auf die Sicherheit und Stabilität des Geschäftsbetriebs der Kunden aus. Die Anwendung von GIC in der Arbeit hat zu einer deutlichen Verbesserung der Inhaltsüberprüfung geführt.Im eigentlichen Anwendungsprozess müssen zwei Hyperparameter debuggt werden, nämlich der Multitask-Lernkoeffizient Lambda und die Anzahl der Zwischenschichten k. In der 18-schichtigen Encoderstruktur haben wir festgestellt, dass k = 5 und Lambda = 0,5 bessere experimentelle Ergebnisse liefern. Wir beginnen dann mit dieser Einstellung und optimieren sie, um die optimalen Hyperparameter zu bestimmen. ?
Der Held hinter den Kulissen: NetEase Zhiqi Yidun AI Lab
Dies ist nicht das erste Mal, dass das Team des Yidun AI Lab mit solchen Spezifikationen geehrt wird.
Als technisches Team von NetEase Intelligence, das seit jeher an der Spitze der Forschung im Bereich der künstlichen Intelligenz steht, ist Yidun AI Lab bestrebt, umfassende, strenge, sichere und vertrauenswürdige KI-Technologiefähigkeiten rund um Verfeinerung, Leichtbau und Agilität aufzubauen und digitale Inhalte kontinuierlich zu verbessern Servicelevel der Risikokontrolle. Zuvor hat das -Team mehrere Meisterschaften im KI-Algorithmus-Wettbewerb und wichtige Auszeichnungen gewonnen:
Der erste China-Wettbewerb für künstliche Intelligenz im Jahr 2019, das am weitesten fortgeschrittene A-Level-Zertifikat im Bereich Flaggenerkennung
Der 2. China-Wettbewerb für künstliche Intelligenz im Jahr 2020, das höchste A-Level-Zertifikat im Video-Deep-Forgery-Detection-Track Der 3. China-Wettbewerb für künstliche Intelligenz im Jahr 2021, die beiden fortschrittlichsten A-Level-Zertifikate für Video-Deepfake-Erkennung und Audio-Deepfake-Erkennungsspuren 2021 „Innovation Star“ und „Innovative Figure“ der China Artificial Intelligence Industry Development Alliance Die 16. Nationale Akademische Konferenz für Mensch-Computer-Sprachkommunikation 2021 (NCMMSC2021) „Wettbewerb zur mehrsprachigen multimodalen Erkennung langer und kurzer Videos“ – Chinesischer Doppelsieger für lange und kurze Video-Live-Voice-Keywords (VKW) Gewann den ersten Preis des von der Provinzregierung Zhejiang im Jahr 2021 verliehenen Science and Technology Progress Award Der ICPR-Wettbewerb zur multimodalen Untertitelerkennung 2022 (MSR-Wettbewerb, der erste inländische multimodale Untertitelerkennungswettbewerb) zeichnet sich durch drei Gewinner des „Multimodalen Untertitelerkennungssystems, das Bild und Audio integriert“ aus Die Zukunft ist da und die Zeit für das KI-gestützte iPhone ist gekommen. Yidun hat heute erfolgreich die akademische Halle der Phonetik betreten, und in Zukunft wird die Technologie Errungenschaften und Fortschritte in allen Bereichen des Geschäftslebens bringen, und Yidun wird immer an Ihrer Seite sein. 
Das obige ist der detaillierte Inhalt vonNetEase Yidun AI Lab-Artikel für ICASSP 2023 ausgewählt! Die schwarze Technologie macht die Spracherkennung „zuhörender' und genauer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Erste Schritte mit Meta Lama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Metas Lama 3.2: Ein Sprung nach vorne in der multimodalen und mobilen KI Meta hat kürzlich Lama 3.2 vorgestellt, ein bedeutender Fortschritt in der KI mit leistungsstarken Sichtfunktionen und leichten Textmodellen, die für mobile Geräte optimiert sind. Aufbau auf dem Erfolg o
 Beste AI -Chatbots verglichen (Chatgpt, Gemini, Claude & amp; mehr)
Apr 02, 2025 pm 06:09 PM
Beste AI -Chatbots verglichen (Chatgpt, Gemini, Claude & amp; mehr)
Apr 02, 2025 pm 06:09 PM
Der Artikel vergleicht Top -KI -Chatbots wie Chatgpt, Gemini und Claude und konzentriert sich auf ihre einzigartigen Funktionen, Anpassungsoptionen und Leistung in der Verarbeitung und Zuverlässigkeit natürlicher Sprache.
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
Top -KI -Schreibassistenten, um Ihre Inhaltserstellung zu steigern
Apr 02, 2025 pm 06:11 PM
In dem Artikel werden Top -KI -Schreibassistenten wie Grammarly, Jasper, Copy.ai, Writesonic und RYTR erläutert und sich auf ihre einzigartigen Funktionen für die Erstellung von Inhalten konzentrieren. Es wird argumentiert, dass Jasper in der SEO -Optimierung auszeichnet, während KI -Tools dazu beitragen, den Ton zu erhalten
 Top 7 Agentenlagersystem zum Aufbau von KI -Agenten
Mar 31, 2025 pm 04:25 PM
Top 7 Agentenlagersystem zum Aufbau von KI -Agenten
Mar 31, 2025 pm 04:25 PM
2024 veränderte sich von einfacher Verwendung von LLMs für die Erzeugung von Inhalten zum Verständnis ihrer inneren Funktionsweise. Diese Erkundung führte zur Entdeckung von AI -Agenten - autonome Systeme zur Handhabung von Aufgaben und Entscheidungen mit minimalem menschlichen Eingreifen. Bauen
 AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
AV -Bytes: META ' S Lama 3.2, Googles Gemini 1.5 und mehr
Apr 11, 2025 pm 12:01 PM
Die KI -Landschaft dieser Woche: Ein Wirbelsturm von Fortschritten, ethischen Überlegungen und regulatorischen Debatten. Hauptakteure wie OpenAI, Google, Meta und Microsoft haben einen Strom von Updates veröffentlicht, von bahnbrechenden neuen Modellen bis hin zu entscheidenden Verschiebungen in LE
 Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Verkauf von KI -Strategie an Mitarbeiter: Shopify -CEO Manifesto
Apr 10, 2025 am 11:19 AM
Das jüngste Memo von Shopify -CEO Tobi Lütke erklärt kühn für jeden Mitarbeiter eine grundlegende Erwartung und kennzeichnet eine bedeutende kulturelle Veränderung innerhalb des Unternehmens. Dies ist kein flüchtiger Trend; Es ist ein neues operatives Paradigma, das in P integriert ist
