
 Technologie-Peripheriegeräte
KI
Fudan veröffentlicht den „News Recommendation Ecosystem Simulator' SimuLine: Eine einzige Maschine unterstützt 10.000 Leser, 1.000 Ersteller und mehr als 100 Empfehlungsrunden
Technologie-Peripheriegeräte
KI
Fudan veröffentlicht den „News Recommendation Ecosystem Simulator' SimuLine: Eine einzige Maschine unterstützt 10.000 Leser, 1.000 Ersteller und mehr als 100 Empfehlungsrunden
Fudan veröffentlicht den „News Recommendation Ecosystem Simulator' SimuLine: Eine einzige Maschine unterstützt 10.000 Leser, 1.000 Ersteller und mehr als 100 Empfehlungsrunden

Das Verständnis der Entwicklung von Online-Nachrichtengemeinschaften ist für die Entwicklung effektiverer Nachrichtenempfehlungssysteme von entscheidender Bedeutung. Die vorhandene Forschung ist jedoch aufgrund des Mangels an geeigneten Datensätzen und Plattformen nur begrenzt in der Lage, zu verstehen, wie Empfehlungssysteme die Community-Entwicklung beeinflussen, was zu Problemen führen kann, die seit langem bestehen können. Laufzeitkonsequenzen. Suboptimales Systemdesign für den Nutzen.
Als Reaktion auf dieses Problem entwickelte das CISL-Forschungsteam der Fudan University School of Computer Science SimuLine, eine Simulationsplattform für die Entwicklung von Ökosystemen mit Nachrichtenempfehlungen.
SimuLine baut einen latenten Raum auf, der menschliches Verhalten aus realen Daten auf der Grundlage vorab trainierter Sprachmodelle und des Inverse Propensity Score widerspiegelt, und verwendet dann agentenbasierte Modellierung, um die evolutionäre Dynamik des Nachrichtenempfehlungs-Ökosystems zu simulieren.
SimuLine unterstützt mehr als 100 Runden Erstellung-Empfehlung-Interaktionssimulation für mehr als 10.000 Leser und mehr als 1.000 Ersteller auf einem einzigen Server (256 GB Speicher, Grafikkarte für Endverbraucher) und bietet gleichzeitig quantitative Indikatoren, Visualisierung und einen umfassenden Analyserahmen Dazu gehört auch die Textinterpretation.
Umfangreiche Simulationsexperimente zeigen, dass SimuLine großes Potenzial hat, Community-Evolutionsprozesse zu verstehen und Empfehlungsalgorithmen zu testen.

authors: Zhang Guangping, Li Dongsheng, Gu Hansu, Lu Xun, Shang Li, Gu Ning
paper Adresse: https://arxiv.org/abs/2305.14103
Simulationsplattform für die Entwicklung von Nachrichtenempfehlungen
Mit der Beliebtheit sozialer Medien (Social Media) verlassen sich die Menschen zunehmend auf Online-Nachrichtengemeinschaften, um Nachrichten zu veröffentlichen und zu erhalten. Täglich werden Millionen von Nachrichten erstellt, die Autoren auf verschiedenen Arten von Online-Inhalten veröffentlichen Nachrichten-Communities und werden von einer großen Anzahl von Benutzern im Rahmen der Verbreitung von Empfehlungssystemen gelesen.
Mit der Produktion und dem Konsum von Nachrichteninhalten befinden sich Online-Nachrichtengemeinschaften in einem kontinuierlichen dynamischen Entwicklungsprozess.
Ähnlich wie bei anderen Arten von Online-Communities entspricht auch die Entwicklung von Online-News-Communities der berühmten Lebenszyklustheorie, das heißt, sie durchläuft die Phasen „Startup“ – „Wachstum“ – „Reife“ – „Verfall“. " der Reihe nach.
Aus der Perspektive der Lebenszyklustheorie wurde in zahlreichen Forschungsarbeiten das Evolutionsmodell von Online-Communities untersucht und Vorschläge für den Betrieb jeder Phase im Lebenszyklus gemacht.
Als eine der wichtigsten technischen Infrastrukturen von Online-Nachrichtengemeinschaften ist der Einfluss von Empfehlungssystemen auf die Entwicklung von Online-Nachrichtengemeinschaften jedoch immer noch rätselhaft.
Um dieses Rätsel zu lösen, konzentrierte sich das CISL-Forschungsteam der Fakultät für Informatik der Fudan-Universität auf die folgenden drei Forschungsfragen und versuchte, ihre Antworten durch Simulationsexperimente zu finden:
1) Ökosystem für Nachrichtenempfehlungen (News Recommendation Ecosystems, NREs) Was sind die Merkmale jeder Phase des Lebenszyklus?
2) Was sind die Schlüsselfaktoren, die die Entwicklung von NREs vorantreiben, und wie interagieren diese Faktoren miteinander, um den Evolutionsprozess zu beeinflussen?
3) Wie kann durch die Designstrategie des Empfehlungssystems eine bessere langfristige Mehrparteienwirksamkeit erreicht und so verhindert werden, dass die Community in den „Abstieg“ gerät?
Um diese drei Forschungsfragen zu beantworten, hat das CISL-Forschungsteam SimuLine entwickelt, eine Plattform zur Simulation der Ökosystementwicklung mit Nachrichtenempfehlungen.
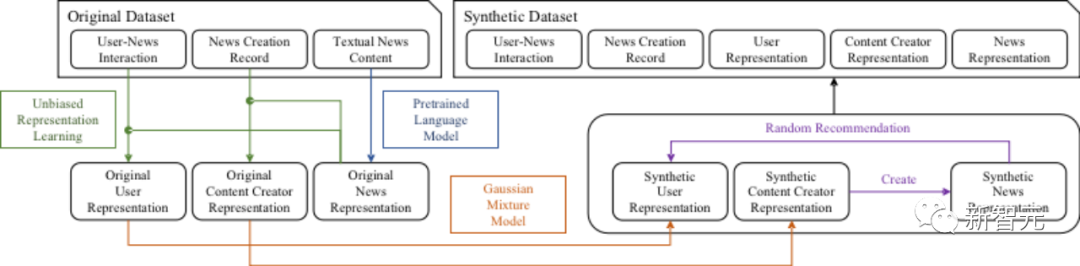
SimuLine generiert zunächst synthetische Daten basierend auf realen Datensätzen. Um das inhärente Problem der Expositionsverzerrung des Originaldatensatzes (Exposure Bias) zu lösen, hat SimuLine den Inverse Propensity Score (Inverse Propensity Score) eingeführt, um die Verzerrung zu beseitigen.
Um einen latenten Raum zu etablieren, der dem menschlichen Entscheidungsprozess nahe kommt, führt SimuLine vorab trainierte Sprachmodelle (Pretrained Language Models) ein, die auf großen Korpora basieren, um den latenten Raum zu konstruieren. Schließlich verwendet SimuLine eine agentenbasierte Simulation to Modeling) simuliert das Verhalten und die Interaktion von Benutzern, Inhaltserstellern und Empfehlungssystemen im Nachrichtenempfehlungs-Ökosystem.
Synthetische Datengenerierung
Beim Versuch, einen Simulator zu erstellen, der einen Benutzer darstellt, kommt mir als Erstes die Frage in den Sinn: „Wie sollten die verschiedenen Verhaltensweisen des Benutzers charakterisiert werden?“
Dazu gibt es tatsächlich eine Frage Frage Eine sehr einfache Lösung, die im Bereich der Empfehlungssysteme weit verbreitet ist, besteht darin, einen latenten Raum aufzubauen und dann die Interessen und Nachrichteninhalte des Benutzers diesem Raum zuzuordnen.
Auf diese Weise ist es sehr praktisch, die Liebe des Benutzers zu Nachrichten anhand der Ähnlichkeit von Vektoren im latenten Raum zu messen und dann eine Reihe von Verhaltenslogiken und -regeln zu definieren.
Bau
Wie baut man also diesen verborgenen Raum?
Einige Schüler sagten: „Was ist daran so schwierig!? Wird der Empfehlungsalgorithmus nicht dafür verwendet? Warum nicht einfach eines lernen, indem man den Empfehlungsalgorithmus verwendet?“
Das ist in der Tat eine gute Idee Ein Ansatz, der jedoch einige offensichtliche Probleme mit sich bringt.
Das Rätselhafteste für das CISC-Forschungsteam ist eine logische Schwachstelle namens „Algorithm Confounding“. Das heißt, wenn Empfehlungsalgorithmus A verwendet wird, um einen latenten Raum aufzubauen und Benutzer und Nachrichten als ihre tatsächlichen Verhaltensentscheidungen abzubilden Würde in diesem Zusammenhang nicht Algorithmus B, der im nachfolgenden Simulationsprozess verwendet wird, zu Algorithmus A passen (wird dies Schülern bekannt vorkommen, die sich mit dem Destillationslernen auskennen)?
Darüber hinaus sind die meisten aktuellen Empfehlungsalgorithmen immer noch Black-Box-Modelle. Selbst wenn Sie die Augen verschließen und die Algorithmusverzerrung ignorieren, werden Sie bei der Analyse der Simulationsdaten (diese Dimension) immer noch verwirrt sein bedeutet diese Dimension?
Gerade als das Forschungsteam ratlos war, blitzte ein weißer Lichtblitz auf: Es schien, als hätte ich einen Artikel gesehen, in dem es hieß, dass ein Sprachmodell auf der Grundlage eines großen Korpus trainiert wurde (es war immer noch Berts Welt). (damals und ChatGPT war noch nicht geboren) konnte einige grundlegende menschliche Erkenntnisse entwickeln (d. h. den berühmten König – männlich + weiblich = Königin).
Dann wäre dieses Ding nicht sehr geeignet, um latenten Raum aufzubauen:
1. Es kann Benutzer und Nachrichten kodieren;
2 Die verkörperte menschliche Erkenntnis sollte grundlegend und universell sein, wodurch das Problem der Algorithmenverwirrung vermieden wird.
3 Obwohl nicht klar ist, was jede Dimension in ihrem verborgenen Raum darstellt, hat dies keinen Einfluss auf die Verständlichkeit des Raums Bereitstellung einer groben Texterklärung für jeden Punkt im Raum durch Ähnlichkeitsvektorabruf.
Das ist einfach wunderbar! Die Entscheidung liegt bei Ihnen!
Mapping
löst das Problem der Konstruktion des latenten Raums. Der nächste Schritt besteht darin, Benutzer und Nachrichten diesem Raum zuzuordnen.
Über Nachrichten kann man leicht sprechen, sie müssen Rich-Text-Informationen enthalten und können direkt codiert werden, aber wie sollten Benutzer damit umgehen? Ist es möglich, anhand der Nachrichten, die dem Benutzer im Verlauf gefallen, einen Durchschnitt zu ermitteln?
Nein!
Das abscheuliche Algorithm Confounding ist mit einem anderen Namen zurück. Dieses Mal heißt es Exposure Bias, was bedeutet, dass der Like-Datensatz des Benutzers nicht unbedingt das Interesse des Benutzers vollständig widerspiegelt, da die Nachrichten, die dem Benutzer gefallen, vom Benutzer gesehen werden müssen. Die Nachrichten, die Benutzer gesehen haben, wurden vom Empfehlungssystem gefiltert. Es besteht die Möglichkeit, dass sie dem Benutzer nicht gefallen haben, weil er sie nicht gesehen hat.
Glücklicherweise reicht das Arsenal im Bereich der Empfehlungssysteme nach so vielen Jahren des schnellen Fortschritts aus, um dieses Problem aus dem Unbiased Recommendation Warehouse zu lösen: Inverse Propensity Score (IPS).
Einfach ausgedrückt geht es darum, die empfohlenen Proben durch Schätzung ihrer Belichtungsdichte zu gewichten und dadurch die Verzerrung auszugleichen, die sie während des Modelllernprozesses mit sich bringt, und so das Codierungsproblem des Benutzers zu lösen.
Was die endgültigen Content-Ersteller betrifft, so wird ihr Content-Veröffentlichungsverhalten nicht durch Exposure Bias beeinträchtigt und ihre historischen Aufzeichnungen werden direkt gewichtet. Tatsächlich sind die Datenvorbereitungsarbeiten nach den oben genannten Vorgängen im Wesentlichen abgeschlossen, es gibt jedoch noch zwei Mängel:
· Erstens wurde die Datenskala nicht angepasst und ist möglicherweise nicht für die Rechenressourcen geeignet ( kleiner Esel zieht großes Schleifen/großer Esel Mo Yangong);
· Zweitens wird die Privatsphäre des Benutzers nicht respektiert. Daher fügte das Forschungsteam eine Ebene eines generativen Modells hinzu, die auf der Benutzercodierung des Originaldatensatzes basiert.
Angesichts der Tatsache, dass Nachrichtenplattformen immer mit einer Partitionsnavigation (Finanzen, Sport, Technologie usw.) ausgestattet sind und die Clusterung von Benutzern in verschiedenen Partitionen ebenfalls offensichtlich ist, förderte das Forschungsteam das Gaussian Mixture Model (GMM). verantwortlich für diese Aufgabe.
Agentenmodellierung
Nach Abschluss der vorbereitenden Datenvorbereitungsarbeiten können Sie mit der Modellierung des Benutzerverhaltens beginnen.
Das Forschungsteam hat die agentenbasierte Modellierungsmethode übernommen, die darin besteht, das Verhalten von Einzelpersonen und die Interaktionen zwischen Einzelpersonen zu modellieren und dann die Dynamik der Gruppe durch den Einsatz einer großen Anzahl von Agenten zu simulieren.
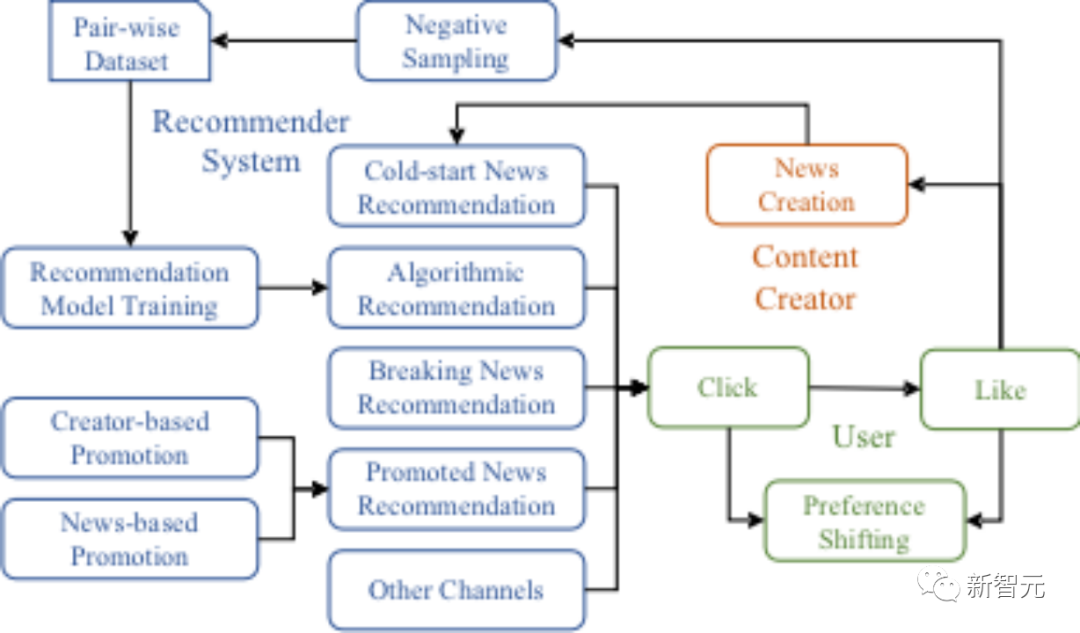
Erinnern Sie sich einfach an den Online-Nachrichtenlesevorgang des Benutzers (wenn Sie beispielsweise heute Toutiao lesen), sieht der Benutzer zunächst eine Reihe von Nachrichten, die vom Empfehlungssystem auf einer bestimmten Seite empfohlen werden. Und dann stöbert der Benutzer einfach durch die Titel, Bilder und Zusammenfassungen der einzelnen Nachrichten. Wenn eine bestimmte Nachricht das Interesse des Benutzers weckt, wird er hineinklicken, um zu sehen, was konkret gesagt wird Wenn Nachrichten gut, lesenswert oder mit ihren eigenen Ansichten übereinstimmen, drücken Benutzer ihre Zustimmung zu den Nachrichten durch Likes und andere Methoden aus.
Definition
In diesem Prozess kann die Interaktion zwischen Benutzern und Nachrichten in drei Ebenen (Belichtung, Klicks und Likes) unterteilt werden, wobei Klicks und Likes das aktive Verhalten von Benutzern sind. Es muss im User Agent definiert werden.
Hier fasst das Forschungsteam das Klickverhalten des Nutzers als probabilistisches Auswahlverhalten zusammen, also basierend auf der Übereinstimmung zwischen dem Nutzer und den Nachrichten (die an der Ähnlichkeit im latenten Raum der beiden gemessen werden kann), dem Der Benutzer hat eine bestimmte Wahrscheinlichkeit. Wählen Sie aus der Liste einige Nachrichten aus, die Sie interessieren, und klicken Sie zum Lesen.
Diese Definition ist flexibler als das direkte Klicken auf die am besten passenden Nachrichten. Das heißt, sie bedeutet nicht unbedingt, dass ein hoher Übereinstimmungsgrad gelesen wird, und sie entspricht eher der tatsächlichen Situation.
Was das Verhalten von Likes angeht, können wir nicht einfach den Übereinstimmungsgrad der Nachrichten berücksichtigen. Schließlich ist das Phänomen des Schlagzeilenmachens in den Nachrichten immer noch weit verbreitet.
Daher hat das Forschungsteam ein abstraktes Konzept der „Nachrichtenqualität“ eingeführt, um den Wert einer Nachrichtenmeldung allgemein darzustellen. Auf diese Weise kann das Like-Verhalten des Benutzers durch subjektives Interesse und objektive Qualität charakterisiert werden.
Das Forschungsteam verwendet das Erwartungsmodell, um das Like-Verhalten des Agenten zu steuern. Konkret berechnet es zunächst den Nutzen (Nützlichkeit) eines Benutzers, der eine bestimmte Nachricht liest, basierend auf dem Grad der Interessenübereinstimmung und der Nachrichtenqualität Erwartung (das Forschungsteam verwendet einen Hyperparameter-Schwellenwert, um den spezifischen Wert dieser Erwartung darzustellen), dann wird das ähnliche Verhalten ausgelöst.
Die intuitive Erklärung dieses Designs lautet: Wenn mich eine Neuigkeit glücklich macht, sei es, weil sie auf mich zugeschnitten ist oder weil der Bericht selbst sehr objektiv und umfassend ist, werde ich nicht zögern, sie zu mögen.
Darüber hinaus sind die Interessen oder Meinungen des Benutzers während des Nachrichtenlesevorgangs offensichtlich nicht statisch.
Wenn ein Benutzer beispielsweise einen Nachrichtenbericht sieht, der ihm gefällt, kann dies den Wunsch des Benutzers wecken, tiefer in verwandte Nachrichten einzutauchen. Im Gegenteil, wenn ein Bericht dem Benutzer das Gefühl gibt, dass er völlig lächerlich ist Wenn ich in Zukunft ähnliche Berichte sehe, werde ich weniger wahrscheinlich darauf klicken, um die Details des Berichts anzuzeigen.
Dieses Phänomen wurde vom Forschungsteam als User-Drift-Modell modelliert.
Kreatives Verhalten modellieren
Als nächstes modellieren Sie das kreative Verhalten von Nachrichtenerstellern.
Die Nachrichtenerstellung in der realen Welt wird von verschiedenen Faktoren beeinflusst. Das Forschungsteam vereinfacht es hier als gierigen Prozess, das heißt, der Autor hofft immer, dass die von ihm erstellten Nachrichten von mehr Lesern erkannt werden.
Das spezifische Forschungsteam zur Verhaltenskontrolle von Agenten übernimmt eine Lösung, die den Benutzerklicks ähnelt, basierend auf den Likes der Nachrichten, die sie in der vorherigen Runde erstellt haben, wählen das Thema der neuen Erstellungsrunde aus und konzentrieren sich dann zu Themen für die Nachrichtenerstellung. Der Prozess der Nachrichtenerstellung wird in ähnlicher Weise als Prozess der Stichprobenentnahme aus einer themenzentrierten Gaußschen Verteilung im latenten Raum modelliert.
Neben dem Inhalt der Nachrichten (latente Raumrepräsentation) muss auch die Qualität der Nachrichten modelliert werden. Dies basiert auf zwei Grundannahmen, die mit den Gesetzen der Realität übereinstimmen:
1 Es besteht eine geringfügig abnehmende positive Korrelation zwischen der Anzahl der Likes, die ein Autor erhält, und seinem Einkommen, d. h. je mehr Likes ein Autor erhält , je mehr Einkommen er oder sie liest, aber mit zunehmender Anzahl wird das Einkommen aus einem einzelnen Like allmählich abnehmen
2 Ersteller mit hohem Einkommen werden aufgrund dessen qualitativ hochwertigere Nachrichten erstellen ihre angemesseneren Budgets. Auf dieser Grundlage kann eine Zuordnungsfunktion von der Anzahl der Likes in der vorherigen Runde zur Qualität der Nachrichten in der nächsten Runde erstellt werden, um die Qualität der Nachrichtenerstellung zu steuern.
Empfehlungssystemmodellierung
Abschließend modellieren Sie das Verhalten des Empfehlungssystems.
Algorithmusempfehlung und Kaltstartempfehlung sind die beiden Grundkomponenten des Nachrichtenempfehlungssystems. Um personalisierte Algorithmusempfehlungen bereitzustellen, verwendet das Empfehlungssystem zunächst Empfehlungsalgorithmen wie BPR usw., um aus historischen Interaktionsdaten die Darstellung von Benutzern und Nachrichten im Einbettungsraum zu lernen (das Forschungsteam verwendet latenten Raum, um darauf zu verweisen). Kodierung eines großen Sprachmodells Realer Benutzerinteressenraum, wobei der Einbettungsraum verwendet wird, um auf den vom Empfehlungsalgorithmus gelernten Raum zu verweisen und zum Generieren der Empfehlungsliste zu verwenden.
Aufgrund der Unsicherheit des Benutzerverhaltens und der Begrenzung des Nachrichtengültigkeitsfensters können Algorithmusempfehlungen jedoch nicht garantieren, dass sie alle Benutzer abdecken. Diese Lücke kann durch einfache Zufallsempfehlungen geschlossen werden.
Aufgrund des Fehlens historischer Interaktionsaufzeichnungen können neu erstellte Nachrichten nicht an Algorithmusempfehlungen teilnehmen. SimuLine wendet Strategien wie zufällige Empfehlungen und heuristische Empfehlungsalgorithmen (z. B. neue Berichte von historisch beliebten Erstellern) an, um Kaltstartnachrichten zu empfehlen.
Darüber hinaus unterstützt SimuLine auch andere heuristische Nachrichtenempfehlungsstrategien, wie z. B. aktuelle Nachrichten, auf Content-Erstellern basierende Werbung und themenbasierte Werbung usw.
Alle Empfehlungsstrategien verfügen über unabhängige Push-Quoten. Das Empfehlungssystem kombiniert Nachrichtenempfehlungen aus allen Kanälen zur endgültigen Empfehlungsliste.
Simulationsexperiment
Die Daten liegen vor! Das Modell wurde gebaut! Als nächstes kommen einige spannende Experimente!
Das Forschungsteam hat den Adressa-Datensatz ausgewählt, der im Bereich der Nachrichtenempfehlung weit verbreitet ist. Dieser Datensatz liefert das vollständige Webprotokoll der norwegischen Nachrichten-Website www.adressa.no in einer bestimmten Woche im Februar 2017. Zusammen mit anderen hervorragenden Nachrichtenempfehlungsdaten liefert es nativ sehr wichtige Informationen zum Nachrichtenautor. Dementsprechend verwendet das Sprachmodell BPEmb, das Norwegisch nativ unterstützt. Weitere Einzelheiten zur Bereitstellung finden Sie im ersten Abschnitt von Kapitel 4 des Dokuments.
Wie analysiert man also die Simulationsergebnisse von SimuLine? SimuLine bietet ein umfassendes Analyse-Framework aus mehreren Perspektiven als Referenz.
Das erste ist das am häufigsten verwendete System zur Bewertung quantitativer Indikatoren.
Um den Entwicklungsprozess des Nachrichtenempfehlungs-Ökosystems vollständig widerzuspiegeln, fasste das Forschungsteam die quantitativen Indikatoren zusammen, die in der vorhandenen Literatur erschienen sind, und erstellte ein relativ vollständiges Bewertungssystem aus den folgenden fünf Aspekten:
1 ) Interaktivität, einschließlich der Anzahl der Likes und seines Gini-Index, bedeutet eine bessere Fairness
2) Abdeckung, einschließlich der Anzahl der Benutzer und Nachrichten, die durch Algorithmusempfehlungen abgedeckt werden; die durchschnittliche Qualität der Nachrichten während des Zeitlimits, die durchschnittliche Qualität der Nachrichten während des Zeitlimits gewichtet mit der Anzahl der Likes und der Pearson-Korrelationskoeffizient zwischen Nachrichtenqualität und der Anzahl der Likes
4) Homogenisierung, einschließlich Jaccard Index zwischen Benutzern: Je höher der Wert, desto höher ist der Grad der Überlappung beim Lesen von Nachrichten zwischen Benutzern.
1. Lebenszyklus
Die folgenden drei Bilder zeigen jeweils die quantitativen Bewertungsergebnisse von Benutzern, Erstellern und Empfehlungssystemen unter verschiedenen Agent-Hyperparameterbedingungen.
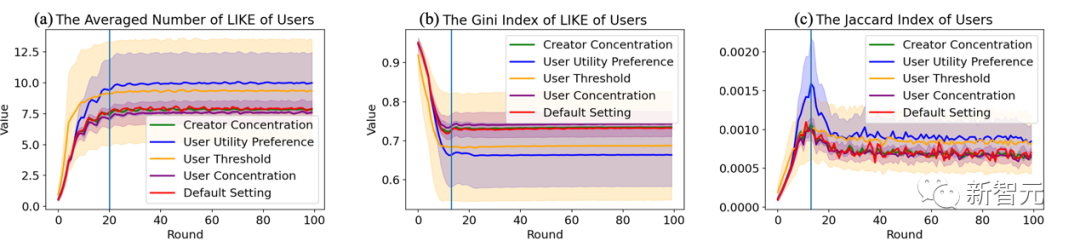

 Daraus wurde die erste Entdeckung gemacht:
Daraus wurde die erste Entdeckung gemacht:
2. Benutzerdifferenzierung
Neben quantitativen Indikatoren ist die Visualisierung auch ein wichtiges Instrument, um das Verständnis des Community-Evolutionsprozesses zu unterstützen.Das Forschungsteam hat durch Visualisierung der PCA-Dimensionalitätsreduzierung den folgenden Satz von Schnappschüssen des Systementwicklungsprozesses erhalten (Nachrichten sind blau markiert, Benutzer mit ähnlichen Datensätzen sind grün markiert und Benutzer ohne ähnliche Datensätze sind rot markiert. Knoten Größe Stellt die Anzahl der Likes/Likes dar).
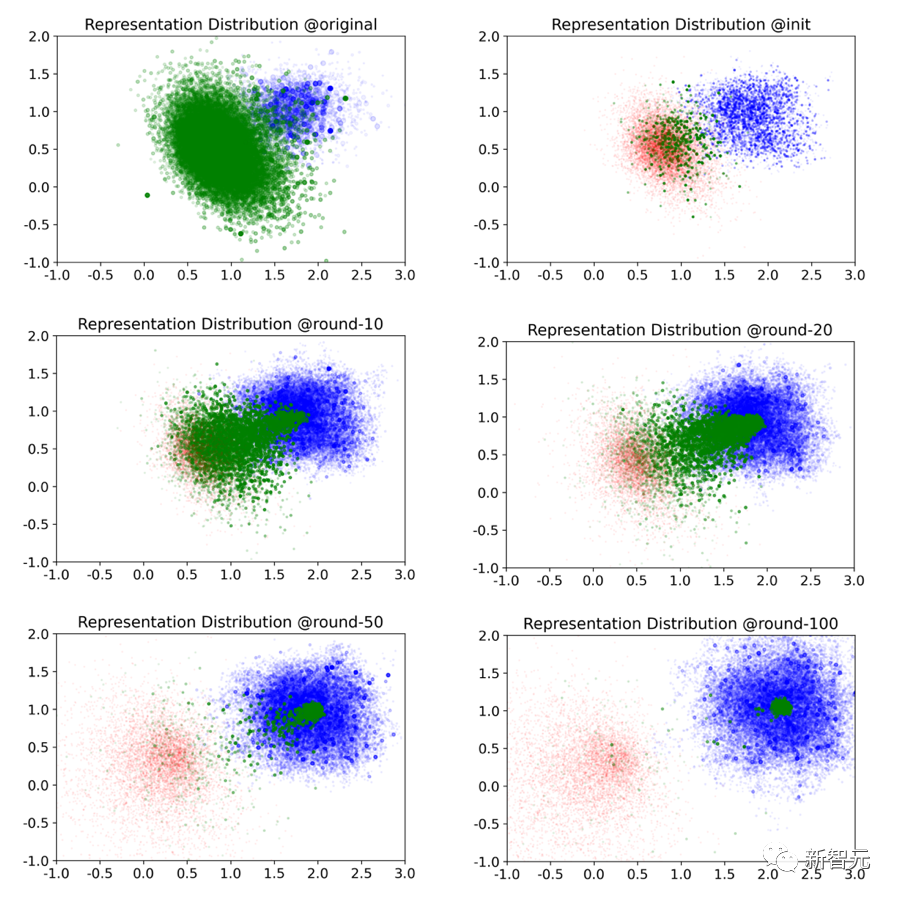
Es ist ersichtlich, dass die quantitativen Indikatoren zwar ein mehrstufiges Muster zeigen, der Evolutionstrend der latenten Raumdarstellung jedoch konsistent ist, das heißt, Benutzer differenzieren sich allmählich zu In-Circle-Benutzern (in-the). (Loop-Benutzer) und Out-the-Loop-Benutzer.
Benutzer im Kreis bilden eine stabile Community mit übereinstimmenden Interessen, während Benutzer außerhalb des Kreises verstreute Interessen zeigen.
Im Evolutionsprozess zwischen der 10. und 20. Runde haben Benutzer die Differenzierung im Wesentlichen abgeschlossen, was zeigt, dass die Wachstumsphase eine entscheidende Rolle bei der Benutzerbeteiligung spielt.
Dies führt zur zweiten Entdeckung: Die durch das Empfehlungssystem gesteuerte Online-Nachrichten-Community führt unweigerlich zu einer Konvergenz der Community-Themen und zur Differenzierung der Benutzer. Die kritische Phase, die die Benutzerbeteiligung bestimmt, ist die Wachstumsphase. 3. Interessenassimilation durch den Abruf ähnlicher Wörter zur Textinterpretation, der anhand von Fallstudien hilft, die Entwicklung einzelner Benutzer zu verstehen.
Das Forschungsteam wählte zufällig drei Benutzer aus, die sich im Kreis befanden, bzw. außerhalb des Kreises. Die folgende Tabelle zeigt die Entwicklung ihrer Interessen.
Für Nutzer im Kreis werden ihre Interessen immer abstrakter, breiter und allgemeiner, etwa von „Schauspieler“ bis „Arbeit“, von „Oslo“ über „Norwegen“ bis „Europa“. „“. Die Entwicklungsgeschwindigkeiten verschiedener Benutzer variieren, aber bei der 50. Runde konvergieren sie alle. Dieses Phänomen spiegelt die allmähliche Migration der Benutzerpräferenzen von personalisierten Nischenthemen zu Trendthemen wider, die auf der Plattform häufig diskutiert werden, als Ergebnis der kontinuierlichen Interaktion mit dem Empfehlungssystem.
Für Benutzer außerhalb des Kreises ändern sich ihre Interessen leicht, sie konzentrieren sich jedoch immer auf spezifische und personalisierte Themen. Beispielsweise interessierten sich die Benutzer Nr. 4 und Nr. 6 während des gesamten Simulationsprozesses weiterhin für „Sportler“, „Tee“ und „Rechnungen“.
Dies führt zur dritten Entdeckung:
In einer Online-News-Community, die von einem Empfehlungssystem gesteuert wird, werden die personalisierten Interessen der Benutzer während der kontinuierlichen Interaktion mit dem Empfehlungssystem aufgenommen.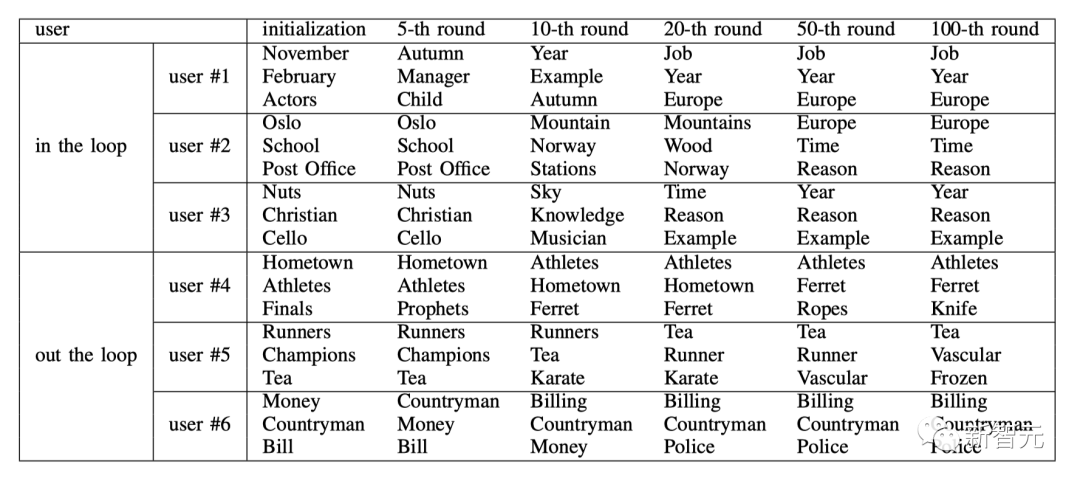
Mit Hilfe der oben genannten drei leistungsstarken Tools für quantitative Indikatoren, Visualisierung und Textübersetzung kann SimuLine eine umfassende physikalische Untersuchung des Entwicklungsprozesses des Systems durchführen .
Da der Entwicklungsprozess der Online-Nachrichten-Community, der durch das Empfehlungssystem vorangetrieben wird, mit der Lebenszyklustheorie übereinstimmt, analysieren wir aus der Perspektive des Lebenszyklus, wie sich die Community in jeder Lebensphase entwickelt.
Lass uns zunächst die Startphase analysieren, die ungefähr den ersten 10 Runden entspricht.Da das System von Grund auf neu aufgebaut ist, fehlen dem Empfehlungssystem in der Anfangsphase Daten, um den Empfehlungsalgorithmus zu trainieren. Dementsprechend besteht in dieser Phase die Hauptaufgabe darin, zufällige Empfehlungen und heuristische Empfehlungen zur Lösung des Kaltstartproblems des Benutzers zu verwenden.
Aufgrund der Unfähigkeit, einen genaueren Algorithmus für Empfehlungen zu verwenden, sind die Empfehlungsergebnisse in dieser Phase im Hinblick auf die Interessenübereinstimmung häufig unbefriedigend. Daher wird das Like-Verhalten in dieser Phase hauptsächlich von der Qualität der Nachrichten bestimmt. was sich in den quantitativen Indikatoren widerspiegelt. Das ist eine starke positive Korrelation mit der Wärme.Gehen wir noch einen Schritt weiter, können wir die beiden Hauptantriebskräfte der Community-Entwicklung in der Startup-Phase ausmachen:
1) Qualitäts-Feedbackschleifen, also die gegenseitige Förderung von Qualität und Beliebtheit auf Basis einer positiven Korrelation, d. h. je besser die Sache, desto mehr Menschen wird sie gefallen, und je mehr Menschen sie mögen, desto höher ist die Qualität Je höher das Einkommen des Autors, desto motivierter ist er, Nachrichtenberichte von besserer Qualität zu erstellen Interesse, der Empfehlungsalgorithmus verwendet qualitätsgesteuerte Punkte. Ähnliches Verhalten wird als Verhalten verwechselt, das durch das Interesse des Benutzers ausgelöst wird. Diese beiden treibenden Kräfte fördern sich gegenseitig und ermöglichen es den Erstellern beliebter Inhalte, eine allmählich zunehmende Überpräsenz zu erlangen (was sich im Anstieg des Gini-Index für Ersteller und Nachrichten widerspiegelt) und die Befriedigung der personalisierten Interessen der Benutzer weiter zu verringern (was sich im Rückgang der Benutzer widerspiegelt). die latente räumliche Ähnlichkeit zwischen den ihm gefallenen Nachrichten). Die meisten Benutzer können jedoch immer noch von einer verbesserten Nachrichtenqualität profitieren (was sich im sinkenden Gini-Index für benutzerähnliches Verhalten widerspiegelt). Zusammenfassend können wir die vierte Erkenntnis erhalten: In der Startphase sammelt das System Daten zur Schätzung von Benutzerinteressen aus zufälligen Empfehlungen und hochwertigen Nachrichten und löst so das Kaltstart-Benutzerproblem. Qualitätsrückkopplungsschleifen und Interessen-Qualitätsverwirrung tragen durch Überbelichtung dazu bei, dass äußerst beliebte Content-Ersteller entstehen. 5. Wachstumsstadium angetrieben und qualitativ hochwertig. Der Zusammenhang mit der Popularität schwächt sich allmählich ab. Mit zunehmender Anzahl der Simulationsrunden verfallen die während der Startphase erstellten Nachrichten nach und nach und ziehen sich von den Empfehlungskandidaten zurück. Die Interessen-Qualitäts-Verwirrung beginnt sich aufzulösen und führt allmählich zum endgültigen Ende der Qualitäts-Feedback-Schleife. In der Wachstumsphase ist die Nachrichtendichte im Benutzerbereich jedes Kreises ungleichmäßig. Die Dichte ist in Richtung Mainstream-Nachrichtenthemen höher, während die Dichte in andere Richtungen relativ gering ist. Das Ergebnis ist, dass die Nachrichten, die den Benutzern gefallen, statistisch gesehen eher den Mainstream-Nachrichtenthemen ähneln. Diese subtile Abweichung im Like-Verhalten tritt weiterhin auf und die Benutzerinteressen verlagern sich aufgrund des kontinuierlichen Verstärkungseffekts allmählich in Richtung Mainstream-Nachrichtenthemen . nähert sich. Im Gegenteil, Benutzer außerhalb des Kreises stecken in der Sackgasse „keine Likes – Algorithmus-Empfehlungen können nicht abdecken – geringe Empfehlungsgenauigkeit – und noch weniger Likes“. Gelegentlich werden ihnen die Nachrichten aufgrund ihrer Qualität gefallen, aber der Empfehlungsalgorithmus kann innerhalb der Datenfrist nicht genügend Daten sammeln, um ihr Interesse einzuschätzen. Die Steigerung der Nachrichtenqualität wurde durch ein häufigeres und ausgewogeneres Like-Verhalten vorangetrieben, aber die Nachrichtenqualität, gewichtet nach der Anzahl der Likes, blieb im Allgemeinen stabil, da die Beliebtheit hochwertiger Nachrichten abnahm. Zusammenfassend können wir die fünfte Entdeckung machen: In der Wachstumsphase entwickeln sich Benutzer im Kreis unter dem Einfluss von Verteilungsabweichungen zu gemeinsamen Themen hin, während Benutzer außerhalb des Kreises in einer Sackgasse stecken, was zu Benutzer führt Differenzierung. Immer genauere Algorithmusempfehlungen führen zum Ende der Qualitäts-Feedback-Schleife und die Community verliert dadurch einige qualitätssensible Nutzer. 6. Reife- und Verfallphase Zu diesem Zeitpunkt werden die Benutzer im Kreis dynamisch in der Blase gemeinsamer Themen gehalten. Obwohl ihre Interessen durch das Klicken auf verschiedene Nachrichten an den Rand der Blase verschoben werden können, gehen sie aufgrund der Dichte bald verloren Unterschied. Zurück zur Mitte. Der Gini-Likes-Index für Nachrichten ist höher, während der Gini-Likes-Index für Content-Ersteller niedriger ist, was zeigt, dass selbst Nachrichten, die vom selben Ersteller erstellt wurden, große Unterschiede in der Beliebtheit aufweisen. Zusätzlich zum gierigen Erstellungsmechanismus ist der Nachrichtenerstellungsprozess selbst höchst zufällig, sodass Blasen auch einen natürlichen Expansionstrend aufweisen. Die expandierende Blase bringt vielfältigere Nachrichtenkandidaten mit sich und führt auch dazu, dass sich einige themensensible Nutzer nach und nach zurückziehen. Daraus können wir die sechste Entdeckung machen: In der Reife- und Niedergangsphase teilen Benutzer im Kreis gemeinsame Themen und Inhaltsersteller veröffentlichen verschiedene Neuigkeiten zu diesen Themen. Die Community ist zwar stabil und langsam gewachsen, hat aber gleichzeitig auch einige interessensensible Nutzer verloren. 7. Wie geschieht Evolution? Discovery 1 bis Discovery 6 beantworteten die erste Forschungsfrage, auf die sich das Forschungsteam konzentrierte: Was sind die Merkmale jeder Phase des Lebenszyklus von News Recommendation Ecosystems (NREs)? Lassen Sie uns als Nächstes das gesamte Wissen zusammenfassen und versuchen, die zweite Forschungsfrage zu beantworten: Was sind die Schlüsselfaktoren, die die Entwicklung von NREs vorantreiben, und wie interagieren diese Faktoren miteinander, um den Evolutionsprozess zu beeinflussen? Die folgende Abbildung fasst die Schlüsselfaktoren und Einflussmechanismen der Entwicklung von Online-Nachrichtengemeinschaften zusammen. Es zeigt sich, dass das Wiederauftreten von Exposure Bias und Deadlock die direkten Gründe für die unterschiedlichen Entwicklungstrends der Benutzer im Kreis sind und Benutzer außerhalb des Kreises, und Dies führt weiter zur Differenzierung der Benutzer und zur Konvergenz der Themen.
Mit dem Ende der Qualitäts-Feedback-Schleife können Content-Ersteller keine übermäßige Aufmerksamkeit mehr erhalten, was zu einem Qualitätsverlust des Journalismus führt. Benutzer, die auf Qualität achten, mögen es möglicherweise nicht mehr, was zu einem Rückgang der Benutzerabdeckung führt. 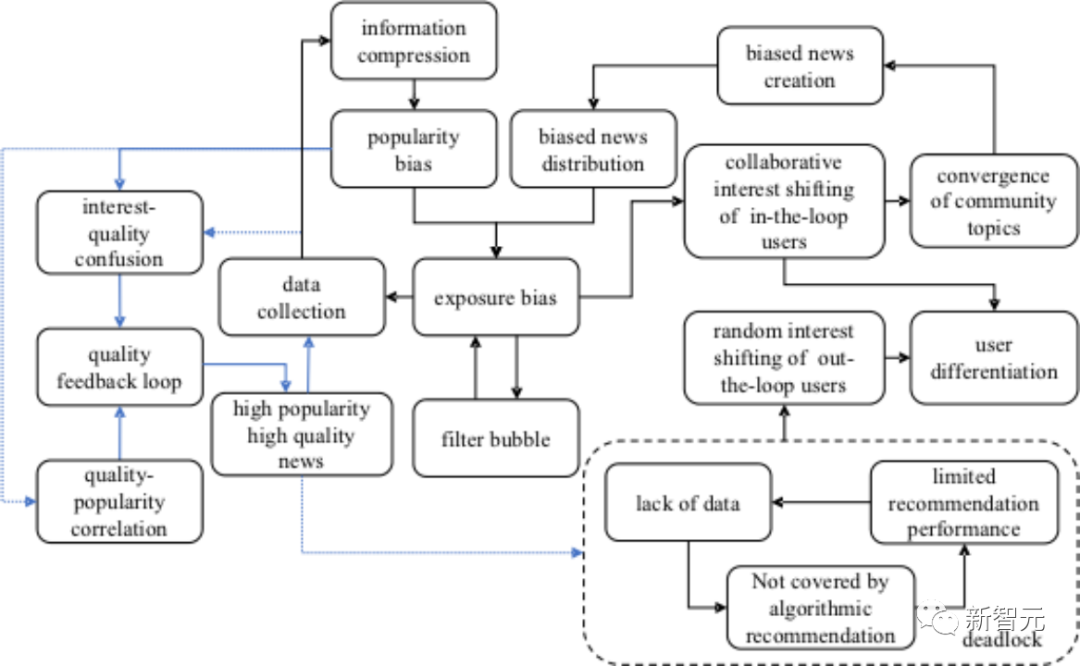
Der erneut auftretende Expositionsbias wird durch eine Kombination von Faktoren verursacht.
Aus informationstheoretischer Sicht kann der Empfehlungsalgorithmus zunächst als Prozess der Informationskomprimierung erklärt werden, der unweigerlich zu einem Popularitätsbias führt, bei dem Nachrichten, die häufig im Datensatz vorkommen (d. h. Nachrichten). mit mehr Likes) Effizienter codiert werden, um die Empfehlungsleistung zu verbessern. Im Entwicklungsprozess der Community spiegelt sich wider, dass weithin diskutierte gemeinsame Themen die Belichtungsressourcen personalisierter Themen auf Algorithmus-Empfehlungskanälen beanspruchen werden.
Zweitens sind Content-Ersteller aufgrund ihrer Gewinnorientierung motivierter, Nachrichten zu Themen von öffentlichem Interesse zu erstellen, was natürlich zu einer Verringerung der Dichte der Pressemitteilungen von beliebten Themen zu personalisierten Themen führt. Selbst wenn im gesamten Prozess zufällige Empfehlungen verwendet werden, kann es in diesem Sinne dazu kommen, dass sich die Community aufgrund von Verteilungsabweichungen in Richtung einer Themenkonvergenz entwickelt.
Schließlich fördern sich Filterblasen und Belichtungsverzerrung gegenseitig, was zusammen zu einer subtilen Verschiebung des Nutzerinteresses führt. Der Algorithmus empfiehlt ähnliche Berichte basierend auf den Nachrichten, die den Benutzern in der Vergangenheit gefallen haben. Die begrenzte Nachrichtenpräsenz macht es für Benutzer schwieriger, die Expositionsverzerrung zu erkennen.
Darüber hinaus zeigt die Ausrichtung des Empfehlungssystems auf populäre Nachrichten unterschiedliche Auswirkungen in verschiedenen Entwicklungsstadien.
In der Startphase herrscht eine Verwirrung hinsichtlich der Interessenqualität, es besteht ein starker Zusammenhang zwischen Nachrichtenqualität und Beliebtheit, und die Beliebtheitsverzerrung spiegelt sich insbesondere in der Verbesserung der Bekanntheit hochwertiger Nachrichten wider.
Mit der Anhäufung von Daten und der Verbesserung der Empfehlungsleistung von Algorithmen wird ähnliches Verhalten immer mehr interessenorientiert als qualitätsorientiert, wodurch die Interessen-Qualitäts-Verwirrung und die Qualität-Popularitäts-Korrelation geschwächt werden. Auch der Popularitätsbias hat sich allmählich von der Empfehlung qualitativ hochwertiger Nachrichten zu einer einfachen Empfehlung sehr beliebter Nachrichten entwickelt.
In diesem Prozess der Umwandlung alter und neuer Impulse spielt die Pflege einiger äußerst beliebter und qualitativ hochwertiger Nachrichtenthemen eine wichtige Rolle bei der Förderung der Benutzerbeteiligung.
Zusammenfassend können wir die siebte Entdeckung machen: Popular Bias, News Distribution Bias und Filterblasen führen gemeinsam zu Exposure Bias, einem Schlüsselfaktor, der die Benutzerdifferenzierung und Themenkonvergenz beeinflusst. Hochwertige Nachrichten mit hoher Beliebtheit sind entscheidend, um den Stillstand bei Nutzern außerhalb des Kreises zu überwinden.
8. Wie kann man den Niedergang der Gemeinschaft verhindern?
Abschließend werden wir mit Hilfe der leistungsstarken Simulations- und Analysefunktionen von SimuLine die dritte Forschungsfrage untersuchen: Wie kann durch die Designstrategie des Empfehlungssystems eine bessere langfristige Mehrparteieneffektivität erreicht werden? Dadurch wird vermieden, dass die Gemeinschaft in den „Untergang“ gerät?
Das Forschungsteam testete vier der grundlegendsten und gebräuchlichsten heuristischen Empfehlungsmethoden: abonnementbasierter Nachrichten-Kaltstart, Hot-Search-Liste, Themenwerbung und Erstellerwerbung. Die folgenden drei Abbildungen zeigen die Community-Evolutionsergebnisse der Anwendung der oben genannten vier Methoden auf das grundlegende Empfehlungssystem.
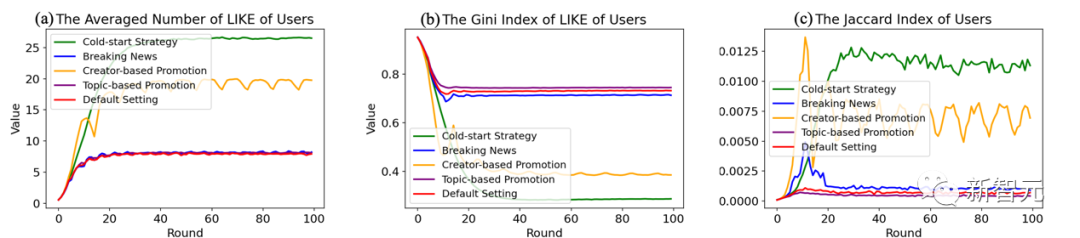


(1) Der abonnementbasierte Kaltstart von Nachrichten versucht, eine stabile, übergreifende Kontaktbeziehung zwischen Benutzern und Inhaltserstellern aufzubauen und dadurch die Startphase zu verbessern Qualitäts-Feedback-Schleife, die entsteht.
Dieser Ansatz hat jedoch zu einem ernsthaften Monopol geführt. Content-Ersteller, die keinen First-Mover-Vorteil erreicht haben, werden durch die Qualitäts-Feedback-Schleife unterdrückt, was die Algorithmus-Abdeckung und die durchschnittliche Qualität der Nachrichten zerstört und dadurch die Vielfalt der Nachrichten verringert Die gesamte Gemeinschaftsökologie ist ernsthaft in Frage gestellt.
(2) Die Hot Search-Liste ist die häufigste Online-Community-Komponente und basiert auf der positiven Korrelation zwischen Nachrichtenqualität und Beliebtheit. Diese Methode kann Benutzern qualitativ hochwertigere Nachrichtenempfehlungen bieten. Gleichzeitig kann das Lesen aktueller Nachrichten aus der Perspektive der Ausbeutung und Erkundung auch als eine Art Benutzererkundung angesehen werden, die die Beschränkungen der bestehenden Interessen des Benutzers durchbricht und so dazu beiträgt, die negativen Auswirkungen von Filterblasen zu reduzieren.
Allerdings kann dieser Ansatz nicht verhindern, dass der im vorherigen Artikel diskutierte Zusammenhang zwischen Beliebtheit und Qualität zusammenbricht, was zu einer Verringerung der Wirksamkeit der Empfehlung aktueller Nachrichten führen würde.
(3) Schließlich gibt es noch die Plattform-Promotion, die durch die Bereitstellung zusätzlicher Aufmerksamkeit für bestimmte Themen oder bestimmte Autoren auch die empfohlenen Inhalte aktiv regulieren kann. Durch die Förderung von Content-Erstellern können Sie eine stabile Bekanntheitsbeziehung aufbauen und dann eine hochwertige Feedbackschleife nutzen, um qualitativ hochwertige Nachrichten mit hoher Beliebtheit zu kultivieren.
Aber im Gegensatz zur abonnementbasierten Kaltstartstrategie für Nachrichten kann die Werbung aktiv beendet werden, bevor die aktuelle Qualitäts-Feedbackschleife ein schädliches Monopol kultiviert und so das Benutzererlebnis und die Kreativität der Ersteller gewährleistet. Als vom Interessen-Matching unabhängiger Nachrichtenverbreitungskanal kann es auch die negativen Auswirkungen von Filterblasen abmildern. Darüber hinaus lenkt es durch die Rekonstruktion der Qualitäts-Feedback-Schleife auch die Ausrichtung des Empfehlungssystems auf populäre Nachrichten hin zu nützlichen Empfehlungen hin zu qualitativ hochwertigen Nachrichten.
SimuLine wählt nach dem Zufallsprinzip Themen in Experimenten aus, die auf die Werbung für bestimmte Themen abzielen. Dies bedeutet, dass beliebte Themen und personalisierte Themen die gleiche Chance haben, beworben zu werden. Bei personalisierten Themen mit relativ geringer Präsenz ist die Wirkung der Werbung also relativ gering und groß.
Diese Methode kann theoretisch dazu verwendet werden, die Beteiligung von Benutzern außerhalb des Kreises zu erhöhen. Da die Qualität der beworbenen Nachrichten jedoch nicht garantiert werden kann und die Menge an Bekanntheit nur schwer in die Anzahl der Likes umzuwandeln ist, ist der Effekt hiervon ausschlaggebend Methode ist begrenzt.
Zusammenfassend können wir die achte Erkenntnis gewinnen: Unter den gängigen Designstrategien für Empfehlungssysteme ist die regelmäßige Werbung für Content-Ersteller die effektivste. Durch den aktiven Aufbau einer Qualitäts-Feedback-Schleife können Wellen beliebter und hochwertiger Nachrichtenthemen in der gesamten Community entstehen, während die Plattform das Monopol durch regelmäßige Zurücksetzungen kontrollieren kann.
Zusammenfassung
In diesem Artikel hat das CISL-Forschungsteam SimuLine entworfen und entwickelt, eine Simulationsplattform zur Analyse des Entwicklungsprozesses des Nachrichtenempfehlungs-Ökosystems, und eine detaillierte Analyse des Entwicklungsprozesses von Online-Nachrichten-Communities basierend darauf durchgeführt SimuLine.
SimuLine konstruiert einen verständlichen latenten Raum, der das menschliche Verhalten gut widerspiegelt, und führt auf dieser Grundlage eine detaillierte Simulation des Nachrichtenempfehlungs-Ökosystems durch agentenbasierte Modellierung durch.
Das Forschungsteam analysierte den gesamten Lebenszyklus der Entwicklung von Online-Nachrichtengemeinschaften, einschließlich der Start-, Wachstums-, Reife- und Niedergangsphasen, analysierte die Merkmale jeder Phase und schlug gleichzeitig ein Beziehungsdiagramm vor, um die Schlüsselfaktoren und Einflüsse in der zu veranschaulichen Mechanismus des Evolutionsprozesses.
Abschließend untersuchte das Forschungsteam die Auswirkungen von Designstrategien für Empfehlungssysteme auf die Community-Entwicklung, einschließlich der Verwendung von abonnementbasierten Nachrichten-Kaltstarts, Hot News und Plattformwerbung.
Zukünftig wird das CISL-Forschungsteam die Generierung von Textinhalten für Nachrichten und die Verhaltensmodellierung von Aktivitäten in sozialen Netzwerken in Betracht ziehen, um leistungsfähigere und realistischere Simulationen durchzuführen.
Das Forschungsteam ist davon überzeugt, dass SimuLine auch als hervorragendes Tool zur Evaluierung von Empfehlungssystemen eingesetzt werden kann und neben Online-Benutzerexperimenten und Offline-Experimenten auf der Grundlage von Datensätzen eine dritte Option bietet (dies ist auch der Hauptgrund für die Bezeichnung SimuLine). .
Das Forschungsteam stellte außerdem fest, dass die Forschungsgemeinschaft für Empfehlungssysteme kürzlich eine Reihe von Empfehlungsalgorithmen zur Korrektur von Verzerrungen vorgeschlagen hat, die darauf abzielen, das Problem der Expositionsverzerrung in Empfehlungen zu lösen, das auch die direkte Ursache für Benutzerdifferenzierung und Themenkonvergenz ist .
Da sich dieser Artikel auf die Diskussion des Systemdesigns des Empfehlungssystems und nicht auf den spezifischen Empfehlungsalgorithmus konzentriert, lässt das Forschungsteam dieses Thema offen und hofft, dass SimuLine zukünftige Forschung in diese Richtung fördern kann.
Das obige ist der detaillierte Inhalt vonFudan veröffentlicht den „News Recommendation Ecosystem Simulator' SimuLine: Eine einzige Maschine unterstützt 10.000 Leser, 1.000 Ersteller und mehr als 100 Empfehlungsrunden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
Wenn Sie wissen müssen, wie Sie die Filterung mit mehreren Kriterien in Excel verwenden, führt Sie das folgende Tutorial durch die Schritte, um sicherzustellen, dass Sie Ihre Daten effektiv filtern und sortieren können. Die Filterfunktion von Excel ist sehr leistungsstark und kann Ihnen dabei helfen, aus großen Datenmengen die benötigten Informationen zu extrahieren. Diese Funktion kann Daten entsprechend den von Ihnen festgelegten Bedingungen filtern und nur die Teile anzeigen, die die Bedingungen erfüllen, wodurch die Datenverwaltung effizienter wird. Mithilfe der Filterfunktion können Sie Zieldaten schnell finden und so Zeit beim Suchen und Organisieren von Daten sparen. Diese Funktion kann nicht nur auf einfache Datenlisten angewendet werden, sondern auch nach mehreren Bedingungen gefiltert werden, um Ihnen dabei zu helfen, die benötigten Informationen genauer zu finden. Insgesamt ist die Filterfunktion von Excel sehr praktisch
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
