
 Technologie-Peripheriegeräte
KI
Tian Yuandongs neues Werk: Beim Öffnen der ersten Schicht der Transformer-Blackbox ist der Aufmerksamkeitsmechanismus nicht so mysteriös
Technologie-Peripheriegeräte
KI
Tian Yuandongs neues Werk: Beim Öffnen der ersten Schicht der Transformer-Blackbox ist der Aufmerksamkeitsmechanismus nicht so mysteriös
Tian Yuandongs neues Werk: Beim Öffnen der ersten Schicht der Transformer-Blackbox ist der Aufmerksamkeitsmechanismus nicht so mysteriös

Die Transformer-Architektur hat viele Bereiche erfasst, darunter die Verarbeitung natürlicher Sprache, Computer Vision, Sprache, Multimodalität usw. Allerdings sind die experimentellen Ergebnisse derzeit sehr beeindruckend und die relevante Forschung zum Funktionsprinzip von Transformer ist noch sehr begrenzt .
Das größte Rätsel ist, warum Transformer effiziente Darstellungen aus der Dynamik des Gradiententrainings hervorbringen kann, indem er sich nur auf einen „einfachen Vorhersageverlust“ verlässt?
Kürzlich gab Dr. Tian Yuandong die neuesten Forschungsergebnisse seines Teams bekannt. Auf mathematisch strenge Weise analysierte er die SGD-Trainingsdynamik eines 1-Schicht-Transformators (eine Selbstaufmerksamkeitsschicht plus eine Decoderschicht). nächste Token-Vorhersageaufgabe.
... und enthüllt die Natur einer möglichen induktiven Verzerrung.

: Ausgehend von der einheitlichen Aufmerksamkeit konzentriert sich das Modell für die Vorhersage eines bestimmten nächsten Tokens schrittweise auf verschiedene Schlüssel-Token und schenkt denjenigen, die in mehreren Fenstern für nächste Token erscheinen, weniger Aufmerksamkeit. Gemeinsame Token
Für verschiedene Token gilt: Das Modell reduziert die Aufmerksamkeitsgewichtung schrittweise und folgt dabei der Reihenfolge von niedrigem bis hohem gleichzeitigem Auftreten zwischen Schlüssel-Tokens und Abfrage-Tokens im Trainingssatz.
Interessanterweise führt dieser Prozess nicht zu einem Winner-Take-All, sondern wird durch einen Phasenübergang, der durch die zweischichtige Lernrate gesteuert wird, verlangsamt und wird schließlich zu einer (fast) festen Token-Kombination, sowohl auf synthetischer als auch auf synthetischer Basis und reale Daten werden ebenfalls überprüft.
Dr. Tian Yuandong ist Forscher und Forschungsmanager am Meta Artificial Intelligence Research Institute und Leiter des Go AI-Projekts. Seine Forschungsrichtungen sind Deep Reinforcement Learning und seine Anwendung in Spielen sowie die theoretische Analyse von Deep-Learning-Modelle. Er erhielt seinen Bachelor- und Master-Abschluss 2005 und 2008 von der Shanghai Jiao Tong University und promovierte 2013 am Robotics Institute der Carnegie Mellon University in den Vereinigten Staaten.
Gewann die 2013 International Conference on Computer Vision (ICCV) Marr Prize Honourable Mentions (Marr Prize Honourable Mentions) und den ICML2021 Outstanding Paper Honourable Mention Award.
Nach seinem Abschluss als Ph.D. veröffentlichte er die Reihe „Five-Year Doctoral Summary“, die die Gedanken und Erfahrungen der Ph.D.-Karriere unter Aspekten wie Auswahl der Forschungsrichtung, Anhäufung von Lektüre und Zeit zusammenfasst Management, Arbeitseinstellung, Einkommen und nachhaltige Karriereentwicklung.
Enthüllung des 1-Schicht-TransformersAuf der Transformer-Architektur basierende Pre-Training-Modelle umfassen normalerweise nur sehr einfache Überwachungsaufgaben, wie das Vorhersagen des nächsten Wortes, das Ausfüllen der Lücken usw., können aber sehr umfangreich sein Darstellungen für nachgelagerte Aufgaben, was wirklich beeindruckend ist.
Obwohl frühere Arbeiten bewiesen haben, dass Transformer im Wesentlichen ein universeller Approximator ist, sind zuvor häufig verwendete Modelle für maschinelles Lernen wie kNN, Kernel-SVM, mehrschichtiges Perzeptron usw. tatsächlich universelle Approximatoren Es besteht ein großer Leistungsunterschied zwischen diesen beiden Modelltypen.
Forscher glauben, dass es wichtig ist, die Trainingsdynamik von Transformer zu verstehen, also wie sich die lernbaren Parameter im Laufe der Zeit während des Trainingsprozesses ändern.
Der Artikel verwendet zunächst eine strenge mathematische Definition, um die Trainingsdynamik von SGD eines schichtlosen Positionscodierungstransformators bei der nächsten Token-Vorhersage (ein häufig verwendetes Trainingsparadigma für Modelle der GPT-Serie) formal zu beschreiben.
Der 1-Schicht-Transformer enthält eine Softmax-Selbstaufmerksamkeitsschicht und eine Decoderschicht, die den nächsten Token vorhersagt.
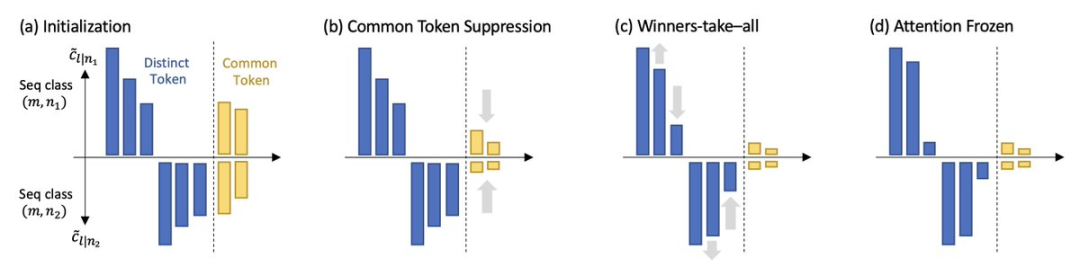
Unter der Annahme, dass die Sequenz lang ist und der Decoder schneller lernt als die Selbstaufmerksamkeitsschicht, wird das dynamische Verhalten der Selbstaufmerksamkeit während des Trainings demonstriert:
1. Häufigkeit Bias
Das Modell achtet nach und nach auf diejenigen Schlüsseltoken, die in großer Zahl gleichzeitig mit dem Abfragetoken auftreten, und verringert die Aufmerksamkeit auf diejenigen Token, die weniger gleichzeitig auftreten.
2. Diskriminative Verzerrung
Das Modell schenkt den eindeutigen Token mehr Aufmerksamkeit, die nur im nächsten vorherzusagenden Token erscheinen, und verliert an Interesse an den gemeinsamen Token, die in mehreren nächsten Token erscheinen.
Diese beiden Merkmale weisen darauf hin, dass die Selbstaufmerksamkeit implizit einen diskriminierenden Scan-Algorithmus ausführt und eine induktive Tendenz aufweist, d Obwohl die Selbstaufmerksamkeitsschicht während des Trainings tendenziell dünner wird, wie die Frequenzabweichung impliziert, bricht das Modell aufgrund von Phasenübergängen in der Trainingsdynamik nicht zusammen.
 Die letzte Lernphase konvergiert nicht zu einem Sattelpunkt, an dem der Gradient Null ist, sondern gelangt in einen Bereich, in dem sich die Aufmerksamkeit langsam ändert (d. h. logarithmisch über die Zeit) und Parameter eingefroren und gelernt werden.
Die letzte Lernphase konvergiert nicht zu einem Sattelpunkt, an dem der Gradient Null ist, sondern gelangt in einen Bereich, in dem sich die Aufmerksamkeit langsam ändert (d. h. logarithmisch über die Zeit) und Parameter eingefroren und gelernt werden.
Die Forschungsergebnisse zeigen außerdem, dass der Beginn des Phasenübergangs durch die Lernrate gesteuert wird: Eine große Lernrate erzeugt spärliche Aufmerksamkeitsmuster, während bei einer festen Selbstaufmerksamkeits-Lernrate eine große Decoder-Lernrate resultiert schnellere Phasenübergänge und intensivere Aufmerksamkeitsmuster.
Die Forscher nannten die in ihrer Arbeit entdeckte SGD-Dynamik „Scan und Snap“:
Scan-Phase:
Die Selbstaufmerksamkeit konzentriert sich auf Schlüsseltoken, die unterschiedlich sind und oft mit den nächsten Vorhersagetoken in Zusammenhang stehen erscheinen gleichzeitig; alle anderen Token verlieren die Aufmerksamkeit.Snap-Phase:
Die Aufmerksamkeit ist fast eingefroren und die Token-Kombination steht fest.
 Dieses Phänomen wurde auch in einfachen realen Datenexperimenten bestätigt. Mithilfe von SGD kann die niedrigste Selbstaufmerksamkeitsschicht der auf WikiText trainierten 1-Schicht- und 3-Schicht-Transformatoren beobachtet werden stellte fest, dass die Lernrate während des gesamten Trainings konstant bleibt und die Aufmerksamkeit irgendwann während des Trainings einfriert und spärlich wird.
Dieses Phänomen wurde auch in einfachen realen Datenexperimenten bestätigt. Mithilfe von SGD kann die niedrigste Selbstaufmerksamkeitsschicht der auf WikiText trainierten 1-Schicht- und 3-Schicht-Transformatoren beobachtet werden stellte fest, dass die Lernrate während des gesamten Trainings konstant bleibt und die Aufmerksamkeit irgendwann während des Trainings einfriert und spärlich wird.
Das obige ist der detaillierte Inhalt vonTian Yuandongs neues Werk: Beim Öffnen der ersten Schicht der Transformer-Blackbox ist der Aufmerksamkeitsmechanismus nicht so mysteriös. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie zeige ich die lokal installierte 'Jingnan Mai Round Body' auf der Webseite richtig?
Apr 05, 2025 pm 10:33 PM
Wie zeige ich die lokal installierte 'Jingnan Mai Round Body' auf der Webseite richtig?
Apr 05, 2025 pm 10:33 PM
Mit lokal installierten Schriftdateien auf Webseiten kürzlich habe ich eine kostenlose Schriftart aus dem Internet heruntergeladen und sie erfolgreich in mein System installiert. Jetzt...
 Wo kann man das Material für die H5 -Seitenproduktion erhalten
Apr 05, 2025 pm 11:33 PM
Wo kann man das Material für die H5 -Seitenproduktion erhalten
Apr 05, 2025 pm 11:33 PM
Die Hauptquellen von H5 -Seitenmaterialien sind: 1. professionelle Material -Website (bezahlt, hoher Qualität, klares Urheberrecht); 2. hausgemachtes Material (hohe Einzigartigkeit, aber zeitaufwändig); 3. Open Source Material Library (kostenlos, muss sorgfältig abgeschrieben werden); 4. Bild-/Video -Website (Urheberrecht verifiziert ist erforderlich). Darüber hinaus sind ein einheitlicher Materialstil, Größenanpassung, Kompressionsverarbeitung und Urheberrechtsschutz wichtige Punkte, die beachtet werden müssen.
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Wie wähle ich ein untergeordnetes Element mit dem erstklassigen Namen über CSS aus?
Apr 05, 2025 pm 11:24 PM
Wie wähle ich ein untergeordnetes Element mit dem erstklassigen Namen über CSS aus?
Apr 05, 2025 pm 11:24 PM
Wenn die Anzahl der Elemente nicht festgelegt ist, wählen Sie das erste untergeordnete Element des angegebenen Klassennamens über CSS aus. Bei der Verarbeitung der HTML -Struktur begegnen Sie häufig auf verschiedene Elemente ...
 Wie verwendet ich CSS und Flexbox, um das reaktionsschnelle Layout von Bildern und Text in verschiedenen Bildschirmgrößen zu implementieren?
Apr 05, 2025 pm 06:06 PM
Wie verwendet ich CSS und Flexbox, um das reaktionsschnelle Layout von Bildern und Text in verschiedenen Bildschirmgrößen zu implementieren?
Apr 05, 2025 pm 06:06 PM
Implementieren von Responsive Layouts mit CSS, wenn wir Layoutänderungen unter verschiedenen Bildschirmgrößen im Webdesign, CSS ...
 Welche Anwendungsszenarien eignen sich für die H5 -Seitenproduktion
Apr 05, 2025 pm 11:36 PM
Welche Anwendungsszenarien eignen sich für die H5 -Seitenproduktion
Apr 05, 2025 pm 11:36 PM
H5 (HTML5) eignet sich für leichte Anwendungen wie Marketingkampagnen, Produktdisplayseiten und Micro-Websites für Unternehmenswerbung. Seine Vorteile liegen in plattformartigen und reichhaltigen Interaktivität, aber seine Einschränkungen liegen in komplexen Interaktionen und Animationen, lokalen Ressourcenzugriff und Offline-Funktionen.
 Wie verwendet ich das Formattribut von CSS, um den Anzeigeeffekt von schrittweisen Verkürzung von Text zu erzielen?
Apr 05, 2025 pm 10:54 PM
Wie verwendet ich das Formattribut von CSS, um den Anzeigeeffekt von schrittweisen Verkürzung von Text zu erzielen?
Apr 05, 2025 pm 10:54 PM
Implementieren Sie den Anzeigeeffekt von schrittweisen Verkürzungen von Text im Webdesign, wie Sie einen speziellen Text -Display -Effekt erzielen, um die Textlänge allmählich zu verkürzen? Dieser Effekt ...
 Warum wirkt sich negative Margen in einigen Fällen nicht wirksam? Wie löst ich dieses Problem?
Apr 05, 2025 pm 10:18 PM
Warum wirkt sich negative Margen in einigen Fällen nicht wirksam? Wie löst ich dieses Problem?
Apr 05, 2025 pm 10:18 PM
Warum werden negative Margen in einigen Fällen nicht wirksam? Während der Programmierung negative Margen in CSS (negativ ...
