
 Technologie-Peripheriegeräte
KI
Keine Angst mehr vor peinlichen „Videokonferenzen'! Google CHI wird ein neues Artefakt veröffentlichen: Visual Captions: Machen Sie Bilder zu Ihrem Untertitelassistenten
Technologie-Peripheriegeräte
KI
Keine Angst mehr vor peinlichen „Videokonferenzen'! Google CHI wird ein neues Artefakt veröffentlichen: Visual Captions: Machen Sie Bilder zu Ihrem Untertitelassistenten
Keine Angst mehr vor peinlichen „Videokonferenzen'! Google CHI wird ein neues Artefakt veröffentlichen: Visual Captions: Machen Sie Bilder zu Ihrem Untertitelassistenten

In den letzten Jahren hat der Anteil von „Videokonferenzen“ am Arbeitsplatz sukzessive zugenommen, und Hersteller haben auch verschiedene Technologien wie Echtzeit-Untertitel entwickelt, um die Kommunikation zwischen Menschen mit unterschiedlichen Sprachen in Besprechungen zu erleichtern.
Aber es gibt noch einen weiteren Schmerzpunkt, wenn im Gespräch einige Substantive erwähnt werden, die der anderen Partei unbekannt sind und sich nur schwer mit Worten beschreiben lassen, wie zum Beispiel das Essen „Sukiyaki“ oder „Ich bin in einen Park gegangen“. Urlaub letzte Woche“ „, ist es schwierig, der anderen Partei die wunderschöne Landschaft mit Worten zu beschreiben; selbst wenn man darauf hinweist, dass „Tokio in der Kanto-Region Japans liegt“ und eine Karte benötigt wird, um es zu zeigen, usw., wenn Sie Wenn Sie nur Worte verwenden, können Sie die andere Partei immer mehr verwirren.

Kürzlich hat Google auf der Top-Konferenz zur Mensch-Computer-Interaktion ACM CHI (Conference on Human Factors in Computing Systems) ein System für visuelle Untertitel vorgeführt und eine neue visuelle Lösung in Remote-Meetings vorgestellt, die Folgendes generieren kann: Rufen Sie Bilder im Kontext eines Gesprächs ab, um das Verständnis des anderen für komplexe oder unbekannte Konzepte zu verbessern.

Papierlink: https://research.google/pubs/pub52074/
Codelink: https://github.com/google/archat
Das Visual Captions-System basiert auf einem fein abgestimmten groß angelegten Sprachmodell, das relevante visuelle Elemente in Gesprächen mit offenem Vokabular proaktiv empfehlen kann und wurde in das Open-Source-Projekt ARChat integriert.

In der Benutzerumfrage luden die Forscher 26 Teilnehmer im Labor und 10 Teilnehmer außerhalb des Labors ein, um das System zu bewerten. Mehr als 80 % der Benutzer stimmten grundsätzlich zu, dass Videountertitel nützliche und aussagekräftige visuelle Darstellungen liefern können Empfehlungen in verschiedenen Szenarien und verbessern das Kommunikationserlebnis.
Designideen
Vor der Entwicklung luden die Forscher zunächst 10 interne Teilnehmer ein, darunter Softwareentwickler, Forscher, UX-Designer, bildende Künstler, Studenten und andere Praktiker mit technischem und nichttechnischem Hintergrund, um die spezifischen Bedürfnisse und Erwartungen zu besprechen für visuelle Verbesserungsdienste in Echtzeit.
Nach zwei Besprechungen wurde auf der Grundlage des vorhandenen Text-zu-Bild-Systems der grundlegende Entwurf des erwarteten Prototypsystems festgelegt, der hauptsächlich acht Dimensionen umfasste (bezeichnet als D1 bis D8).
D1: Timing, das visuelle Verbesserungssystem kann synchron oder asynchron mit dem Dialog angezeigt werden
D2: Thema, das zum Ausdrücken und Verstehen von Sprachinhalten verwendet werden kann
D3: Visuell, das verwendet werden kann eine große Auswahl an visuellen Inhalten und visuellen Typen sowie visuellen Quellen
D4: Skalierung, visuelle Verbesserungen können je nach Größe des Meetings variieren
D5: Raum, ob die Videokonferenz am gleichen Ort oder in einem anderen Raum stattfindet Remote-Einstellung
D6: Datenschutz, Diese Faktoren beeinflussen auch, ob Bilder privat angezeigt, unter den Teilnehmern geteilt oder für alle öffentlich gemacht werden sollen
D7: Ausgangszustand, Die Teilnehmer identifizierten auch verschiedene Möglichkeiten, wie sie dies gerne tun würden ,Beim Führen von Gesprächen mit dem System interagieren, zum Beispiel verschiedene Ebenen der „Initiative“, d zur Eingabe
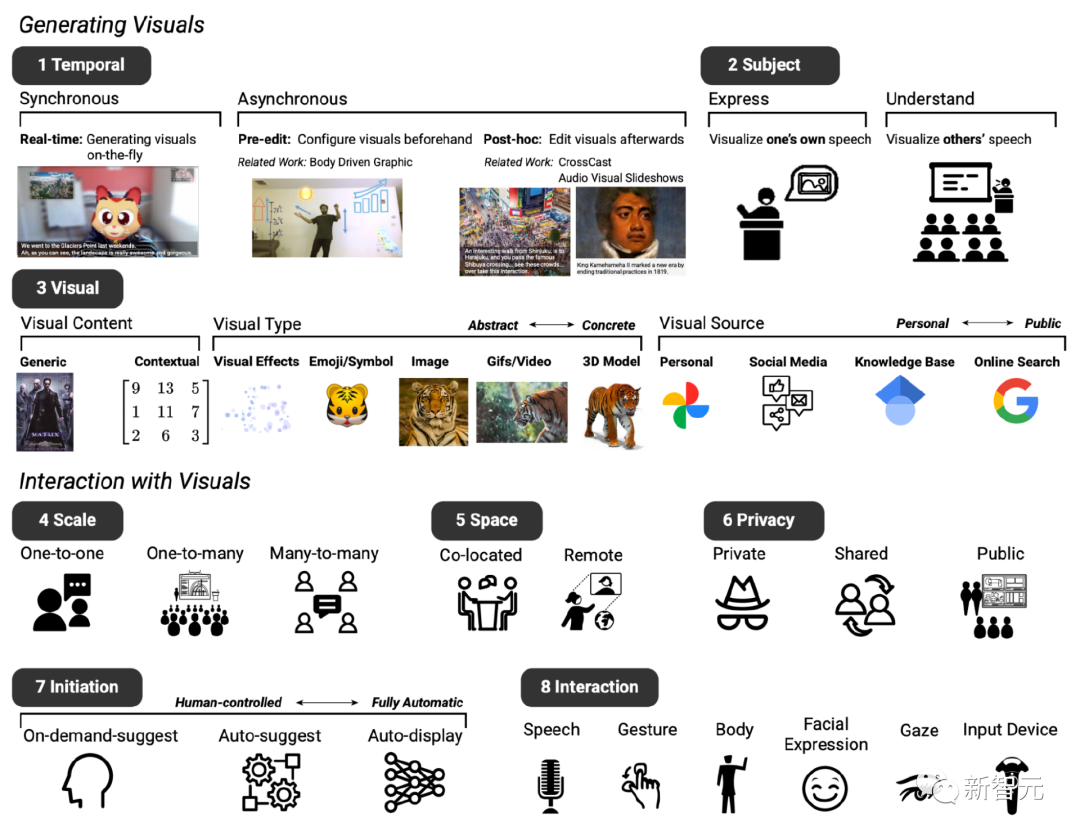
Verwenden Sie dynamische visuelle Effekte, um den Gestaltungsraum der Sprachkommunikation zu erweitern
Basierend auf vorläufigem Feedback haben die Forscher das Video-Caption-System so konzipiert, dass es sich auf die Erzeugung synchronisierter visueller Effekte semantisch relevanter visueller Inhalte, Art und Quelle konzentriert.
Während sich die meisten Ideen in Sondierungsmeetings auf Einzelgespräche aus der Ferne konzentrieren, können Videountertitel auch in Eins-zu-Viele- (z. B. Präsentation vor einem Publikum) und Viele-zu-Viele-Szenarien verwendet werden ( (mehrere Personen treffen sich, um den Einsatz zu besprechen).
Darüber hinaus hängen die visuellen Elemente, die das Gespräch am besten ergänzen, stark vom Kontext der Diskussion ab. Daher ist ein maßgeschneidertes Trainingsset erforderlich.
Die Forscher sammelten 1595 Quadrupel, darunter Sprache, visueller Inhalt, Typ, Quelle, und deckten verschiedene Kontextszenarien ab, darunter tägliche Gespräche, Vorträge, Reiseführer usw.
Zum Beispiel sagt der Benutzer „Ich würde es gerne sehen!“ (Ich würde es gerne sehen!), entsprechend dem visuellen Inhalt von „Gesicht lächelnd“, dem visuellen Typ „Emoji“ und „Visuelle Quelle“. für die öffentliche Suche.
„Hat sie dir von unserer Reise nach Mexiko erzählt?“ entspricht dem visuellen Inhalt von „Fotos von einer Reise nach Mexiko“, dem visuellen Typ von „Foto“ und der visuellen Quelle von „Persönliches Album“.
Der Datensatz VC 1.5K ist derzeit Open Source.
Datenlink: https://github.com/google/archat/tree/main/dataset
Visual Intent Prediction Model
Um vorherzusagen, welche visuellen Elemente das Gespräch ergänzen können, Die Forscher verwendeten den VC1.5K-Datensatz, um ein Modell zur Vorhersage visueller Absichten basierend auf einem großen Sprachmodell zu trainieren.
In der Trainingsphase wird jede visuelle Absicht in das Format „

Basierend auf diesem Format kann das System Konversationen mit offenem Vokabular und kontextbezogene Vorhersagen von visuellem Inhalt, visueller Quelle und visuellem Typ bewältigen.

Dieser Ansatz ist in der Praxis auch besser als der schlüsselwortbasierte Ansatz, da letzterer nicht mit offenen Vokabelbeispielen umgehen kann, wie zum Beispiel ein Benutzer könnte sagen: „Deine Tante Amy wird hier sein.“ Samstag“ „Besuch“, es werden keine passenden Schlüsselwörter gefunden und relevante visuelle Typen oder visuelle Quellen können nicht empfohlen werden.
Die Forscher verwendeten 1276 (80 %) Proben im VC1.5K-Datensatz zur Feinabstimmung des großen Sprachmodells und die restlichen 319 (20 %) Proben als Testdaten und verwendeten die Token-Genauigkeitsmetrik zur Messung der Leistung des fein abgestimmten Modells, d. h. der korrekte Prozentsatz der Token in den Stichproben, der vom Modell korrekt vorhergesagt wurde.
Das endgültige Modell kann eine Trainingstoken-Genauigkeit von 97 % und eine Verifizierungstoken-Genauigkeit von 87 % erreichen.
Praktische Umfrage
Um die Praktikabilität des trainierten visuellen Untertitelmodells zu bewerten, lud das Forschungsteam 89 Teilnehmer ein, 846 Aufgaben durchzuführen, und wurde gebeten, den Effekt zu bewerten, wobei 1 überhaupt nicht zustimmte und 7 völlig zustimmte.
Die experimentellen Ergebnisse zeigen, dass die meisten Teilnehmer es vorziehen, visuelle Effekte in Gesprächen zu sehen (Q1), und 83 % gaben eine Bewertung von 5 – stimme eher zu oder höher.
Darüber hinaus bewerteten die Teilnehmer die angezeigten Bilder als nützlich und informativ (Frage 2), wobei 82 % eine Bewertung von mehr als 5 Punkten gaben und von hoher Qualität (Frage 3), wobei 82 % sie mit mehr als 5 bewerteten -Punktbewertung; und bezogen auf die Originalstimme (Q4, 84 %).
Die Teilnehmer stellten außerdem fest, dass der vorhergesagte visuelle Typ (Q5, 87 %) und die visuelle Quelle (Q6, 86 %) im Kontext des entsprechenden Gesprächs korrekt waren.
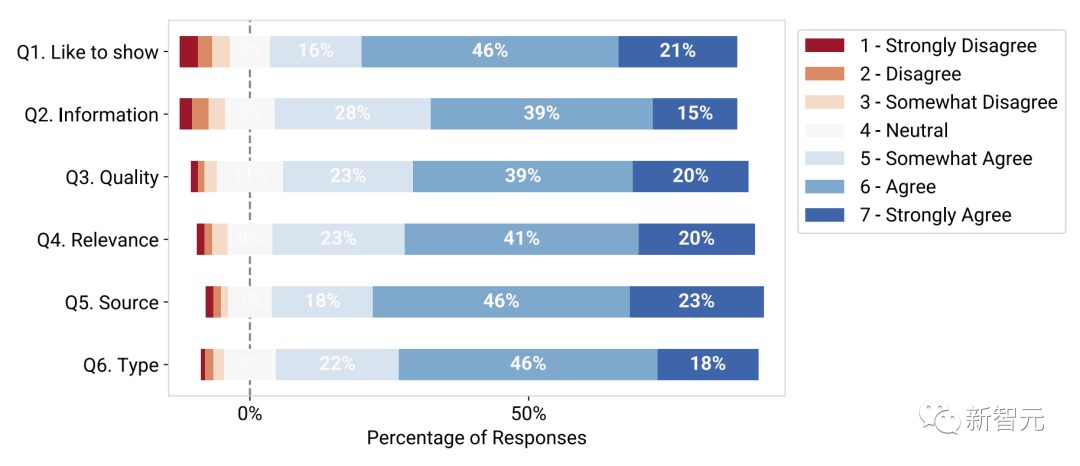
Studienteilnehmer bewerteten die technischen Bewertungsergebnisse des visuellen Vorhersagemodells
Basierend auf diesem fein abgestimmten Modell zur Vorhersage visueller Absichten entwickelten die Forscher visuelle Untertitel auf der ARChat-Plattform, die dies können Fügen Sie direkt neue interaktive Widgets zum Kamerastream von Videokonferenzplattformen wie Google Meet hinzu.
Im Systemworkflow können Videountertitel automatisch die Stimme des Benutzers erfassen, den letzten Satz abrufen, alle 100 Millisekunden Daten in das Modell zur Vorhersage der visuellen Absicht eingeben, relevante visuelle Effekte abrufen und dann empfohlene visuelle Effekte bereitstellen.
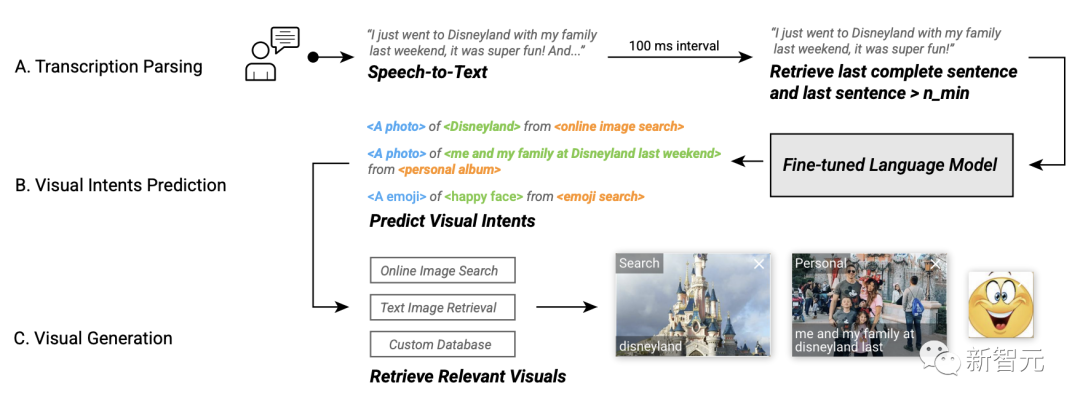
System-Workflow von Visual Captions
Visual Captions bietet drei Ebenen optionaler Initiative bei der Empfehlung von Bildmaterial:
Automatische Anzeige (hohe Initiative): Das System sucht selbstständig nach und zeigt diese an Visuals für alle Besprechungsteilnehmer öffentlich zugänglich machen, ohne Benutzerinteraktion.
Automatische Empfehlung (mittlere Initiative): Empfohlene Visuals werden in einer privaten Scroll-Ansicht angezeigt, und dann klickt der Benutzer auf ein Visual, um es öffentlich anzuzeigen; in diesem Modus empfiehlt das System aktiv Visuals, aber der Benutzer entscheidet, wann zeigen und was zeigen soll.
Vorschläge auf Abruf (geringe Initiative): Das System empfiehlt visuelle Effekte erst, nachdem der Benutzer die Leertaste drückt.
Forscher haben das Visual Captions-System in einer kontrollierten Laborstudie (n = 26) und einer Testphasen-Einsatzstudie (n = 10) evaluiert. Sie fanden heraus, dass Echtzeitvisualisierungen dazu beitrugen, unbekannte Konzepte zu erklären, sprachliche Unklarheiten zu lösen und das Leben zu erleichtern Gespräche, indem man sie spannender gestaltet.
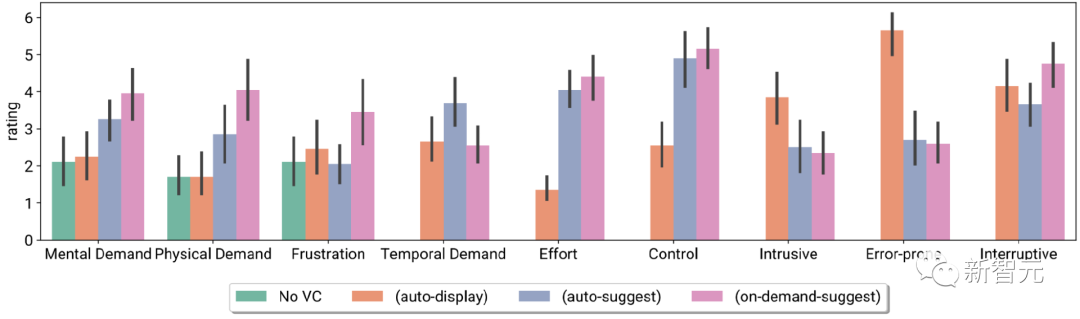
Aufgabenbelastungsindex der Teilnehmer und Likert-Skalenbewertungen, einschließlich keinem VC und VC mit drei verschiedenen Initiativen
Die Teilnehmer berichteten auch über Unterschiede in den Interaktionen auf der Systempräferenz vor Ort, d. h. bei der Verwendung verschiedener Ebenen der VC-Initiative in verschiedenen Besprechungsszenarien
Das obige ist der detaillierte Inhalt vonKeine Angst mehr vor peinlichen „Videokonferenzen'! Google CHI wird ein neues Artefakt veröffentlichen: Visual Captions: Machen Sie Bilder zu Ihrem Untertitelassistenten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1206
24
52
1206
24

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
 Bitget Trading Platform Offizielle App -Download- und Installationsadresse
Feb 25, 2025 pm 02:42 PM
Bitget Trading Platform Offizielle App -Download- und Installationsadresse
Feb 25, 2025 pm 02:42 PM
Dieser Leitfaden enthält detaillierte Download- und Installationsschritte für die offizielle Bitget Exchange -App, die für Android- und iOS -Systeme geeignet ist. Der Leitfaden integriert Informationen aus mehreren maßgeblichen Quellen, einschließlich der offiziellen Website, dem App Store und Google Play, und betont Überlegungen während des Downloads und des Kontoverwaltung. Benutzer können die App aus offiziellen Kanälen herunterladen, einschließlich App Store, offizieller Website APK Download und offizieller Website -Sprung sowie vollständige Registrierung, Identitätsüberprüfung und Sicherheitseinstellungen. Darüber hinaus deckt der Handbuch häufig gestellte Fragen und Überlegungen ab, wie z.
