
 Technologie-Peripheriegeräte
KI
Der „Track Everything'-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Hindernissen hat, ist da.
Technologie-Peripheriegeräte
KI
Der „Track Everything'-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Hindernissen hat, ist da.
Der „Track Everything'-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Hindernissen hat, ist da.

Vor einiger Zeit veröffentlichte Meta das KI-Modell „Segment Everything (SAM)“, das eine Maske für jedes Objekt in jedem Bild oder Video generieren kann, was Forscher im Bereich Computer Vision (CV) zum Ausruf veranlasste: „CV-Nr existiert nicht mehr.“ Danach gab es eine Welle der „sekundären Erstellung“ im Bereich CV. Einige Arbeiten kombinierten sukzessive Funktionen wie Zielerkennung und Bildgenerierung auf Basis der Segmentierung, die meisten Untersuchungen basierten jedoch auf statischen Bildern.
Jetzt schlägt eine neue Forschung mit dem Titel „Tracking Everything“ eine neue Methode zur Bewegungsschätzung in dynamischen Videos vor, mit der die Bewegungsbahn von Objekten genau und vollständig verfolgt werden kann.

Die Studie wurde von Forschern der Cornell University, Google Research und der UC Berkeley durchgeführt. Sie schlugen gemeinsam OmniMotion vor, eine vollständige und global konsistente Bewegungsdarstellung, und schlugen eine neue Methode zur Testzeitoptimierung vor, um eine genaue und vollständige Bewegungsschätzung für jedes Pixel im Video durchzuführen.

- Papieradresse: https://arxiv.org/abs/2306.05422
- Projekthomepage: https://omnimotion.github.io/
Einige Internetnutzer haben diese Studie auf Twitter weitergeleitet und sie erhielt an nur einem Tag mehr als 3.500 Likes. Der Forschungsinhalt wurde gut angenommen.

Der von der Studie veröffentlichten Demo nach zu urteilen, ist die Wirkung der Bewegungsverfolgung sehr gut, beispielsweise die Verfolgung der Bewegungsbahn eines springenden Kängurus:

Die Bewegungskurve eines Schaukel:

Sie können den Bewegungsverfolgungsstatus auch interaktiv anzeigen:

Die Bewegungsbahn kann auch dann verfolgt werden, wenn das Objekt blockiert ist, z. B. wenn ein Hund blockiert wird ein Baum beim Laufen:

Im Bereich Computer Vision gibt es zwei häufig verwendete Methoden zur Bewegungsschätzung: Spärliches Feature-Tracking und dichter optischer Fluss. Allerdings haben beide Methoden ihre eigenen Nachteile. Die Verfolgung von Sparse-Features kann nicht die Bewegung aller Pixel modellieren;
Das in dieser Forschung vorgeschlagene OmniMotion verwendet ein quasi-3D-kanonisches Volumen zur Darstellung des Videos und verfolgt jedes Pixel durch eine Bijektion zwischen lokalem Raum und kanonischem Raum. Diese Darstellung ermöglicht globale Konsistenz, ermöglicht Bewegungsverfolgung auch bei verdeckten Objekten und modelliert jede Kombination aus Kamera- und Objektbewegung. Diese Studie zeigt experimentell, dass die vorgeschlagene Methode bestehende SOTA-Methoden deutlich übertrifft.
Übersicht über die Methode
Diese Studie verwendet als Eingabe eine Sammlung von Bildern mit gepaarten Schätzungen verrauschter Bewegungen (z. B. optische Flussfelder), um eine vollständige, global konsistente Bewegungsdarstellung des gesamten Videos zu erstellen. Die Studie fügte dann einen Optimierungsprozess hinzu, der es ermöglichte, die Darstellung mit jedem Pixel in jedem Frame abzufragen, um im gesamten Video gleichmäßige, genaue Bewegungsbahnen zu erzeugen. Insbesondere kann diese Methode erkennen, wann Punkte im Rahmen verdeckt sind, und sogar Punkte durch Verdeckungen verfolgen.
OmniMotion-Charakterisierung
Herkömmliche Methoden zur Bewegungsschätzung (z. B. paarweiser optischer Fluss) verlieren die Verfolgung von Objekten, wenn sie verdeckt sind. Um auch unter Okklusion genaue und konsistente Bewegungstrajektorien bereitzustellen, schlägt diese Studie die globale Bewegungsdarstellung OmniMotion vor.
Diese Forschung versucht, reale Bewegungen ohne explizite dynamische 3D-Rekonstruktion genau zu verfolgen. Die OmniMotion-Darstellung stellt die Szene im Video als kanonisches 3D-Volumen dar, das in jedem Bild durch eine lokal-kanonische Bijektion auf ein lokales Volumen abgebildet wird. Lokale kanonische Bijektionen werden als neuronale Netze parametrisiert und erfassen Kamera- und Szenenbewegungen, ohne die beiden zu trennen. Basierend auf diesem Ansatz kann das Video als Rendering-Ergebnis aus dem lokalen Volumen einer festen statischen Kamera betrachtet werden.
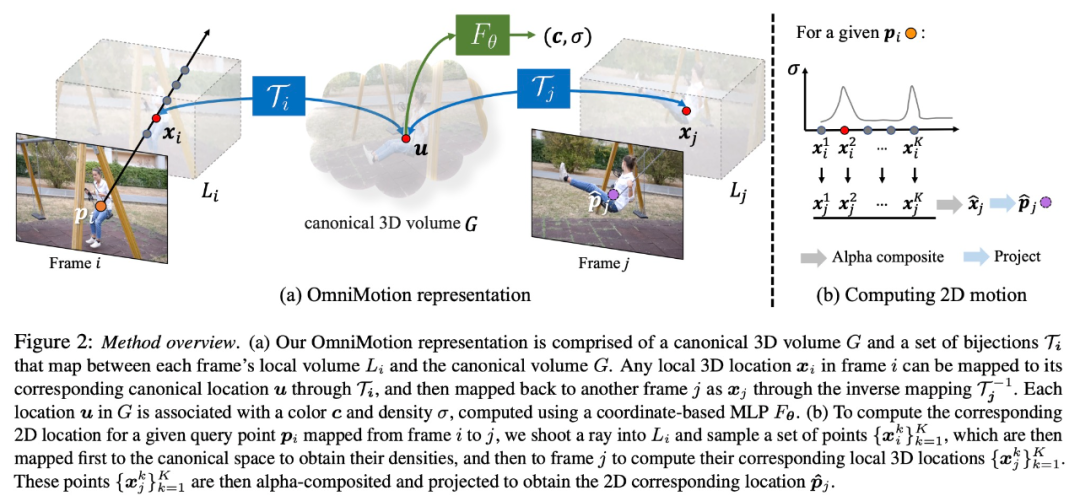
Da OmniMotion nicht klar zwischen Kamera- und Szenenbewegung unterscheidet, handelt es sich bei der erzeugten Darstellung nicht um eine physikalisch genaue 3D-Szenenrekonstruktion. Daher spricht die Studie von einer Quasi-3D-Charakterisierung.
OmniMotion speichert Informationen über alle auf jedes Pixel projizierten Szenenpunkte sowie deren relative Tiefenreihenfolge, sodass Punkte im Bild auch dann verfolgt werden können, wenn sie vorübergehend verdeckt sind.

Experimente und Ergebnisse
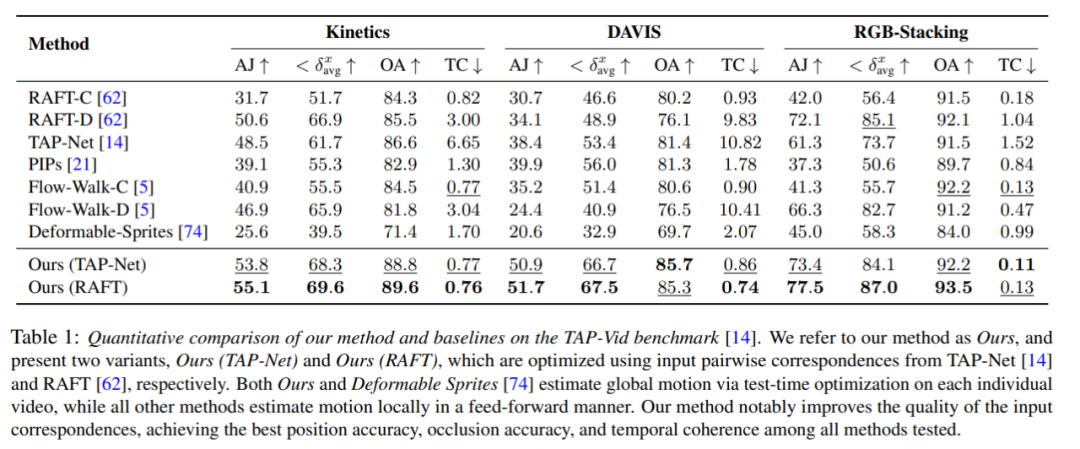
Quantitativer Vergleich
Die Forscher verglichen die vorgeschlagene Methode mit dem TAP-Vid-Benchmark und die Ergebnisse sind in Tabelle 1 dargestellt. Es ist ersichtlich, dass ihre Methode bei verschiedenen Datensätzen stets die beste Positionsgenauigkeit, Okklusionsgenauigkeit und Zeitkonsistenz erreicht. Ihre Methode verarbeitet die unterschiedlichen paarweisen Korrespondenzeingaben von RAFT und TAP-Net gut und bietet konsistente Verbesserungen gegenüber beiden Basismethoden.
Qualitativer Vergleich
Wie in Abbildung 3 dargestellt, führten die Forscher einen qualitativen Vergleich zwischen ihrer Methode und der Basismethode durch. Die neue Methode zeigt hervorragende Erkennungs- und Verfolgungsfähigkeiten bei (langen) Okklusionsereignissen, liefert gleichzeitig vernünftige Positionen für Punkte während Okklusionen und bewältigt große Kamerabewegungsparallaxen.

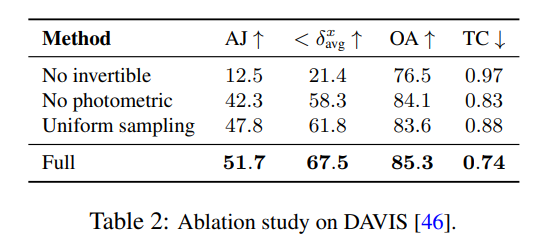
Ablationsexperimente und -analyse
Die Forscher verwendeten Ablationsexperimente, um die Wirksamkeit ihrer Designentscheidungen zu überprüfen. Die Ergebnisse sind in Tabelle 2 aufgeführt.
In Abbildung 4 zeigen sie Pseudotiefenkarten, die von ihrem Modell generiert wurden, um die erlernte Tiefenrangfolge zu demonstrieren.

Es ist zu beachten, dass diese Zahlen nicht der physikalischen Tiefe entsprechen. Sie zeigen jedoch die Fähigkeit der neuen Methode, die relative Ordnung zwischen verschiedenen Oberflächen nur mithilfe photometrischer und optischer Flusssignale effektiv zu bestimmen, was für die Verfolgung von Verdeckungen von entscheidender Bedeutung ist. Weitere Ablationsexperimente und Analyseergebnisse finden Sie im Zusatzmaterial.
Das obige ist der detaillierte Inhalt vonDer „Track Everything'-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Hindernissen hat, ist da.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wo werden Videodateien im Browser-Cache gespeichert?
Feb 19, 2024 pm 05:09 PM
Wo werden Videodateien im Browser-Cache gespeichert?
Feb 19, 2024 pm 05:09 PM
In welchem Ordner speichert der Browser das Video? Wenn wir den Internetbrowser täglich nutzen, schauen wir uns häufig verschiedene Online-Videos an, z. B. Musikvideos auf YouTube oder Filme auf Netflix. Diese Videos werden während des Ladevorgangs vom Browser zwischengespeichert, sodass sie bei späterer erneuter Wiedergabe schnell geladen werden können. Die Frage ist also: In welchem Ordner werden diese zwischengespeicherten Videos tatsächlich gespeichert? Verschiedene Browser speichern zwischengespeicherte Videoordner an unterschiedlichen Orten. Im Folgenden stellen wir einige gängige Browser und deren Funktionen vor
 So entfernen Sie Video-Wasserzeichen in Wink
Feb 23, 2024 pm 07:22 PM
So entfernen Sie Video-Wasserzeichen in Wink
Feb 23, 2024 pm 07:22 PM
Wie entferne ich Wasserzeichen aus Videos in Wink? Es gibt ein Tool zum Entfernen von Wasserzeichen aus Videos in Wink, aber die meisten Freunde wissen nicht, wie man Wasserzeichen aus Videos in Wink entfernt Vom Herausgeber bereitgestelltes Text-Tutorial, interessierte Benutzer kommen vorbei und schauen es sich an! So entfernen Sie das Video-Wasserzeichen in Wink: 1. Öffnen Sie zunächst die Wink-App und wählen Sie im Startseitenbereich die Funktion [Wasserzeichen entfernen] aus. 2. Wählen Sie dann das Video aus, bei dem Sie das Wasserzeichen entfernen möchten in der oberen rechten Ecke nach der Bearbeitung des Videos [√] 4. Klicken Sie abschließend auf [Ein-Klick-Drucken] und dann auf [Verarbeiten].
 Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Douyin zu einem unverzichtbaren Bestandteil des täglichen Lebens eines jeden geworden. Auf TikTok können wir interessante Videos aus aller Welt sehen. Manche Leute posten gerne die Videos anderer Leute, was die Frage aufwirft: Verstößt Douyin gegen das Posten der Videos anderer Leute? In diesem Artikel wird dieses Problem erörtert und Ihnen erklärt, wie Sie Videos ohne Rechtsverletzung bearbeiten und Probleme mit Rechtsverletzungen vermeiden können. 1. Verstößt es gegen Douyins Veröffentlichung von Videos anderer Personen? Gemäß den Bestimmungen des Urheberrechtsgesetzes meines Landes stellt die unbefugte Nutzung der Werke des Urheberrechtsinhabers ohne die Erlaubnis des Urheberrechtsinhabers einen Verstoß dar. Daher stellt das Posten von Videos anderer Personen auf Douyin ohne die Erlaubnis des ursprünglichen Autors oder Urheberrechtsinhabers einen Verstoß dar. 2. Wie bearbeite ich ein Video ohne Urheberrechtsverletzung? 1. Verwendung von gemeinfreien oder lizenzierten Inhalten: Öffentlich
 Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Douyin, die nationale Kurzvideoplattform, ermöglicht uns nicht nur, in unserer Freizeit eine Vielzahl interessanter und neuartiger Kurzvideos zu genießen, sondern gibt uns auch eine Bühne, um uns zu zeigen und unsere Werte zu verwirklichen. Wie kann man also Geld verdienen, indem man Videos auf Douyin veröffentlicht? Dieser Artikel wird diese Frage ausführlich beantworten und Ihnen dabei helfen, mit TikTok mehr Geld zu verdienen. 1. Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Nachdem Sie ein Video gepostet und eine bestimmte Anzahl an Aufrufen auf Douyin erreicht haben, haben Sie die Möglichkeit, am Werbe-Sharing-Plan teilzunehmen. Diese Einkommensmethode ist eine der bekanntesten unter Douyin-Benutzern und stellt auch für viele YouTuber die Haupteinnahmequelle dar. Douyin entscheidet anhand verschiedener Faktoren wie Kontogewicht, Videoinhalt und Publikumsfeedback, ob Möglichkeiten zum Teilen von Werbung bereitgestellt werden sollen. Die TikTok-Plattform ermöglicht es Zuschauern, ihre Lieblingsschöpfer durch das Versenden von Geschenken zu unterstützen.
 So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
1. Öffnen Sie zunächst Weibo auf Ihrem Mobiltelefon und klicken Sie unten rechts auf [Ich] (wie im Bild gezeigt). 2. Klicken Sie dann oben rechts auf [Zahnrad], um die Einstellungen zu öffnen (wie im Bild gezeigt). 3. Suchen und öffnen Sie dann [Allgemeine Einstellungen] (wie im Bild gezeigt). 4. Geben Sie dann die Option [Video Follow] ein (wie im Bild gezeigt). 5. Öffnen Sie dann die Einstellung [Video-Upload-Auflösung] (wie im Bild gezeigt). 6. Wählen Sie abschließend [Originalbildqualität] aus, um eine Komprimierung zu vermeiden (wie im Bild gezeigt).
 2 Möglichkeiten, Zeitlupe aus Videos auf dem iPhone zu entfernen
Mar 04, 2024 am 10:46 AM
2 Möglichkeiten, Zeitlupe aus Videos auf dem iPhone zu entfernen
Mar 04, 2024 am 10:46 AM
Auf iOS-Geräten können Sie mit der Kamera-App Zeitlupenvideos aufnehmen, oder sogar 240 Bilder pro Sekunde, wenn Sie das neueste iPhone besitzen. Mit dieser Funktion können Sie High-Speed-Aktionen detailreich erfassen. Aber manchmal möchten Sie vielleicht Zeitlupenvideos mit normaler Geschwindigkeit abspielen, damit Sie die Details und das Geschehen im Video besser wahrnehmen können. In diesem Artikel erklären wir alle Methoden zum Entfernen von Zeitlupe aus vorhandenen Videos auf dem iPhone. So entfernen Sie Zeitlupe aus Videos auf dem iPhone [2 Methoden] Sie können die Fotos-App oder die iMovie-App verwenden, um Zeitlupe aus Videos auf Ihrem Gerät zu entfernen. Methode 1: Mit der Fotos-App auf dem iPhone öffnen
 Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Xiaohongshu für viele Menschen zu einer Plattform geworden, auf der sie ihr Leben teilen, sich ausdrücken und Traffic gewinnen können. Auf dieser Plattform ist die Veröffentlichung von Videoarbeiten eine sehr beliebte Art der Interaktion. Wie veröffentlicht man also Xiaohongshu-Videoarbeiten? 1. Wie veröffentliche ich Xiaohongshu-Videowerke? Stellen Sie zunächst sicher, dass Sie einen Videoinhalt zum Teilen bereit haben. Sie können zum Fotografieren Ihr Mobiltelefon oder eine andere Kameraausrüstung verwenden, Sie müssen jedoch auf die Bildqualität und die Klarheit des Tons achten. 2. Bearbeiten Sie das Video: Um die Arbeit attraktiver zu gestalten, können Sie das Video bearbeiten. Sie können professionelle Videobearbeitungssoftware wie Douyin, Kuaishou usw. verwenden, um Filter, Musik, Untertitel und andere Elemente hinzuzufügen. 3. Wählen Sie ein Cover: Das Cover ist der Schlüssel, um Benutzer zum Klicken zu bewegen. Wählen Sie ein klares und interessantes Bild als Cover, um Benutzer zum Klicken zu bewegen.
 So konvertieren Sie vom UC-Browser heruntergeladene Videos in lokale Videos
Feb 29, 2024 pm 10:19 PM
So konvertieren Sie vom UC-Browser heruntergeladene Videos in lokale Videos
Feb 29, 2024 pm 10:19 PM
Wie wandele ich vom UC-Browser heruntergeladene Videos in lokale Videos um? Viele Mobiltelefonbenutzer verwenden gerne den UC-Browser. Sie können nicht nur im Internet surfen, sondern auch verschiedene Videos und Fernsehprogramme online ansehen und ihre Lieblingsvideos auf ihr Mobiltelefon herunterladen. Eigentlich können wir heruntergeladene Videos in lokale Videos konvertieren, aber viele Leute wissen nicht, wie das geht. Daher stellt Ihnen der Editor speziell eine Methode zur Verfügung, mit der Sie die vom UC-Browser zwischengespeicherten Videos in lokale Videos konvertieren können. Methode zum Konvertieren von im UC-Browser zwischengespeicherten Videos in lokale Videos 1. Öffnen Sie den UC-Browser und klicken Sie auf die Option „Menü“. 2. Klicken Sie auf „Download/Video“. 3. Klicken Sie auf „Video zwischengespeichert“. 4. Drücken Sie lange auf ein beliebiges Video. Wenn die Optionen angezeigt werden, klicken Sie auf „Verzeichnis öffnen“. 5. Markieren Sie diejenigen, die Sie herunterladen möchten
