
 Technologie-Peripheriegeräte
KI
Mit 2,8 Millionen multimodalen Befehls-Antwort-Paaren, die in acht Sprachen üblich sind, ist der erste Befehlsdatensatz für Videoinhalte von MIMIC-IT da
Technologie-Peripheriegeräte
KI
Mit 2,8 Millionen multimodalen Befehls-Antwort-Paaren, die in acht Sprachen üblich sind, ist der erste Befehlsdatensatz für Videoinhalte von MIMIC-IT da
Mit 2,8 Millionen multimodalen Befehls-Antwort-Paaren, die in acht Sprachen üblich sind, ist der erste Befehlsdatensatz für Videoinhalte von MIMIC-IT da

In letzter Zeit haben KI-Dialogassistenten erhebliche Fortschritte bei Sprachaufgaben gemacht. Diese signifikante Verbesserung basiert nicht nur auf der starken Generalisierungsfähigkeit von LLM, sondern ist auch auf die Optimierung der Anweisungen zurückzuführen. Dies beinhaltet die Feinabstimmung des LLM auf eine Reihe von Aufgaben durch vielfältigen und qualitativ hochwertigen Unterricht.
Ein möglicher Grund für das Erreichen einer Zero-Shot-Leistung mit der Befehlsoptimierung ist die Verinnerlichung des Kontexts. Dies ist insbesondere dann wichtig, wenn Benutzereingaben den gesunden Menschenverstandskontext überspringen. Durch die Einbeziehung der Befehlsoptimierung erhält LLM ein hohes Maß an Verständnis für die Absicht des Benutzers und weist bessere Zero-Shot-Fähigkeiten auf, selbst bei bisher unbekannten Aufgaben.
Ein idealer KI-Gesprächsassistent sollte jedoch in der Lage sein, Aufgaben mit mehreren Modalitäten zu lösen. Dies erfordert die Beschaffung eines vielfältigen und qualitativ hochwertigen multimodalen Datensatzes zur Befehlsverfolgung. Beispielsweise ist der LLaVAInstruct-150K-Datensatz (auch bekannt als LLaVA) ein häufig verwendeter visuell-verbaler Befehlsfolgedatensatz, der COCO-Bilder, Anweisungen und Antworten basierend auf Bildunterschriften und Zielbegrenzungsrahmen verwendet, die von GPT-4 Constructed erhalten wurden. Allerdings weist LLaVA-Instruct-150K drei Einschränkungen auf: begrenzte visuelle Vielfalt; Verwendung von Bildern als einzelne visuelle Daten und kontextbezogene Informationen, die nur die Sprachmorphologie enthalten.
Um KI-Dialogassistenten zu fördern, die diese Einschränkungen überwinden, haben Wissenschaftler der Nanyang Technological University in Singapur und Microsoft Research Redmond den multimodalen kontextbezogenen Befehlsoptimierungsdatensatz MIMIC-IT vorgeschlagen, der 2,8 Millionen multimodale kontextbezogene Elemente enthält Anweisungen – ein Datensatz entsprechender Paare, der eine Vielzahl realer Szenarien abdeckt.

Papieradresse: https://arxiv.org/pdf/2306.05425.pdf
Um effizient Befehls-Antwort-Paare zu generieren, führte der Forscher außerdem „Sythus“ ein ", eine Anweisung, die von der Self-Instruct-Methode inspiriert ist – einer automatisierten Pipeline, die auf Kommentare reagiert. Sythus verwendet Systeminformationen, visuelle Anmerkungen und Beispiele im Kontext, um ein Sprachmodell (GPT-4 oder ChatGPT) anzuleiten, um Befehls-Antwort-Paare basierend auf dem visuellen Kontext zu generieren und dabei auf die drei grundlegenden Fähigkeiten visueller Sprachmodelle abzuzielen: Wahrnehmung, Argumentation und Planung. Darüber hinaus werden englische Befehle und Antworten in sieben Sprachen übersetzt, um die mehrsprachige Nutzung zu unterstützen.
Besonders hervorzuheben ist, dass die Forscher das multimodale Modell „Otter“ auf Basis von OpenFlamingo auf MIMIC-IT trainiert haben. Die multimodalen Fähigkeiten von Otter wurden sowohl mit ChatGPT als auch mit Menschen evaluiert und übertreffen andere neuere visuelle Sprachmodelle.
In einer Reihe von Demos demonstrierten Forscher die multimodalen Frage- und Antwortfähigkeiten von Otter:
F: Welche Karte wird als nächstes gespielt?
A: Acht Röhren. Auf diese Weise können Sie Vierer und Fünfer auf eine Straße warten lassen.

F: Ich möchte landen, was soll ich tun?
A: Drücken Sie einmal die untere linke Taste, um nach links abzubiegen, und ziehen Sie die Handbremse rechts, wenn Sie landen möchten.

F: Was kommt als nächstes?
A: Passe den Ball in die Mitte, renne zum Tor und suche nach Torchancen.

Als nächstes schauen wir uns die Studiendetails an.
MIMIC-IT-Datensatz
Der MIMIC-IT-Datensatz umfasst 2,8 Millionen multimodale Befehls-Antwort-Paare, die grundlegende Fähigkeiten abdecken: Wahrnehmung, Argumentation und Planung. Jede Anweisung wird von einem multimodalen Konversationskontext begleitet, sodass auf MIMIC-IT geschulte VLM gute Kenntnisse in interaktiven Anweisungen nachweisen und eine Zero-Shot-Generalisierung durchführen können.
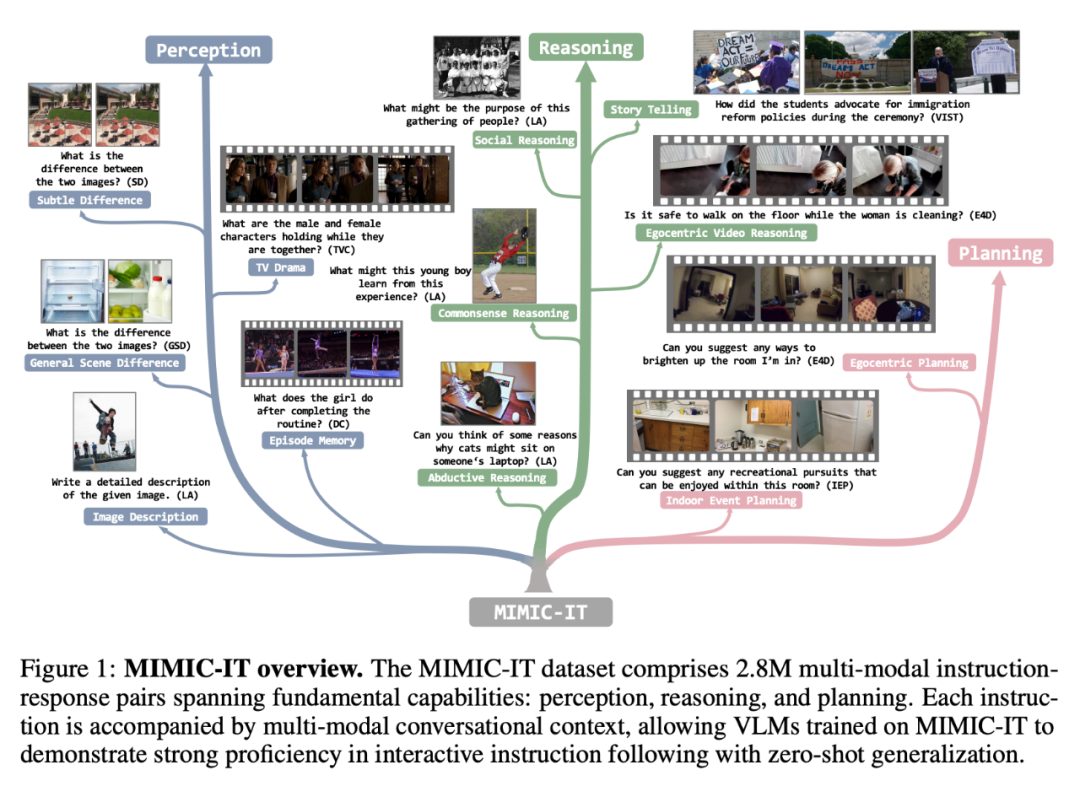
Im Vergleich zu LLaVA gehören zu den Funktionen von MIMIC-IT:
(1) Verschiedene visuelle Szenen, einschließlich allgemeiner Szenen, egozentrischer Perspektivenszenen und RGB-D-Innenbilder usw. Bilder und Videos aus verschiedenen Datensätzen;
(2) Mehrere Bilder (oder ein Video) als visuelle Daten
(3) Multimodale Kontextinformationen, einschließlich mehrerer Anweisungs-Antwort-Paare und mehrerer Bilder oder Videos;
(4) unterstützt acht Sprachen, darunter Englisch, Chinesisch, Spanisch, Japanisch, Französisch, Deutsch, Koreanisch und Arabisch.Die folgende Abbildung zeigt weiter den Befehl-Antwort-Vergleich der beiden (das gelbe Feld ist LLaVA):

Sythus: Automatisierte Pipeline zur Generierung von Befehls-Antwort-Paaren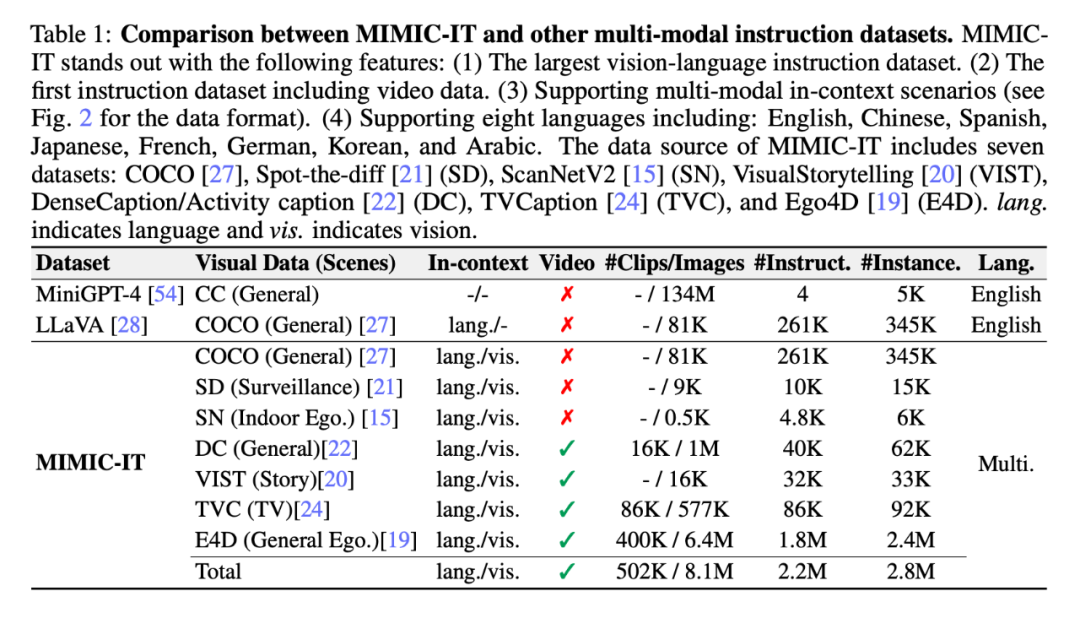
Da sich die Qualität des Kernsatzes auf den nachfolgenden Datenerfassungsprozess auswirkt, haben die Forscher eine Kaltstartstrategie angewendet, um die Stichproben vor groß angelegten Abfragen im Kontext zu verbessern. Während der Kaltstartphase wird ein heuristischer Ansatz angewendet, um ChatGPT dazu zu veranlassen, Proben nur im Kontext durch Systeminformationen und visuelle Anmerkungen zu sammeln. Diese Phase endet erst, nachdem die Proben in einem zufriedenstellenden Kontext identifiziert wurden. Im vierten Schritt werden die Befehls-Antwort-Paare von der Pipeline nach Erhalt in Chinesisch (zh), Japanisch (ja), Spanisch (es), Deutsch (de), Französisch (fr), Koreanisch (ko) und Arabisch erweitert (ar). Weitere Details finden Sie in Anhang C und spezifische Aufgabenaufforderungen finden Sie in Anhang D.
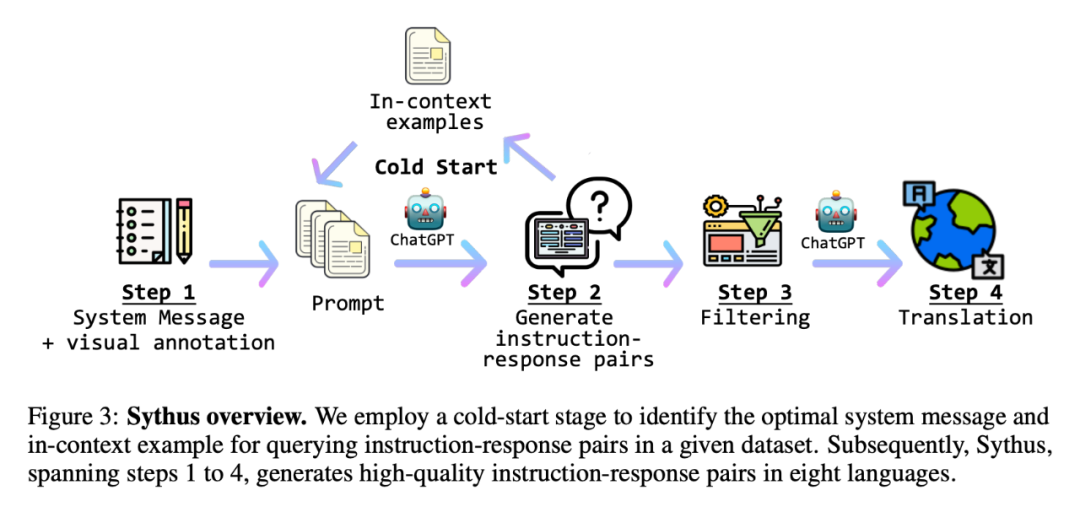
Abbildung 5 ist ein Beispiel für die Reaktion von Otter in verschiedenen Szenarien. Dank der Schulung am MIMIC-IT-Datensatz ist Otter in der Lage, situatives Verständnis und Argumentation, kontextbezogenes Beispiellernen und egozentrische visuelle Assistenten zu unterstützen. 
Abschließend führten die Forscher in einer Reihe von Benchmark-Tests eine vergleichende Analyse der Leistung von Otter und anderen VLMs durch.
ChatGPT-Bewertung
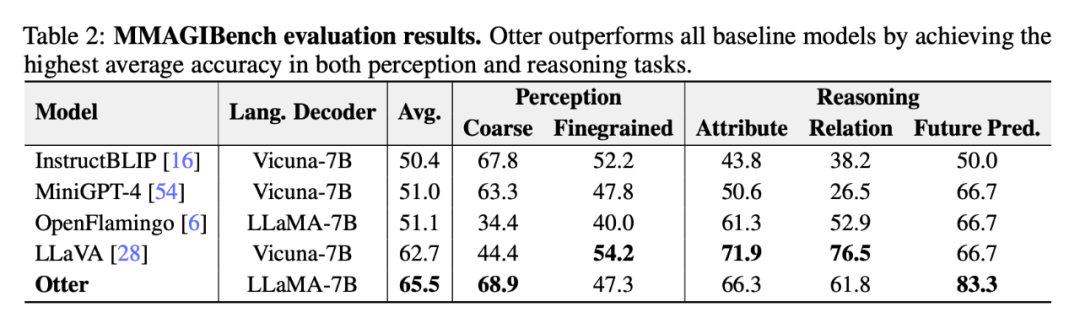
Tabelle 2 unten zeigt die umfassende Bewertung der Wahrnehmungs- und Argumentationsfähigkeiten visueller Sprachmodelle durch Forscher unter Verwendung des MMAGIBench-Frameworks [43].
Menschliche Bewertung
Multi-Modality Arena [32] verwendet das Elo-Bewertungssystem, um die Nützlichkeit und Konsistenz von VLM-Antworten zu bewerten. Abbildung 6(b) zeigt, dass Otter eine überlegene Praktikabilität und Konsistenz aufweist und die höchste Elo-Bewertung in den jüngsten VLMs erreicht.
Few-Shot-Benchmark-Bewertung für Kontextlernen
Otter ist auf OpenFlamingo abgestimmt, eine Architektur, die für multimodales Kontextlernen entwickelt wurde. Nach der Feinabstimmung mithilfe des MIMIC-IT-Datensatzes übertrifft Otter OpenFlamingo bei der COCO Captioning (CIDEr) [27]-Few-Shot-Bewertung deutlich (siehe Abbildung 6 (c)). Wie erwartet führt die Feinabstimmung auch zu geringfügigen Leistungssteigerungen bei der Nullstichprobenauswertung.

Abbildung 6: Auswertung des ChatGPT-Videoverständnisses.
Besprechen Sie
Mängel. Obwohl Forscher Systemnachrichten und Beispiele für Befehlsantworten schrittweise verbessert haben, ist ChatGPT anfällig für Sprachhalluzinationen und kann daher fehlerhafte Antworten generieren. Zuverlässigere Sprachmodelle erfordern häufig eine selbstinstruktive Datengenerierung.
Zukunft der Arbeit. In Zukunft planen die Forscher, spezifischere KI-Datensätze wie LanguageTable und SayCan zu unterstützen. Forscher erwägen auch die Verwendung vertrauenswürdigerer Sprachmodelle oder Generierungstechniken, um den Befehlssatz zu verbessern.
Das obige ist der detaillierte Inhalt vonMit 2,8 Millionen multimodalen Befehls-Antwort-Paaren, die in acht Sprachen üblich sind, ist der erste Befehlsdatensatz für Videoinhalte von MIMIC-IT da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie bekomme ich Gegenstände mithilfe von Befehlen in Terraria? -Wie sammle ich Gegenstände in Terraria?
Mar 19, 2024 am 08:13 AM
Wie bekomme ich Gegenstände mithilfe von Befehlen in Terraria? -Wie sammle ich Gegenstände in Terraria?
Mar 19, 2024 am 08:13 AM
Wie bekomme ich Gegenstände mithilfe von Befehlen in Terraria? 1. Was ist der Befehl zum Erteilen von Gegenständen in Terraria? Im Spiel Terraria ist das Erteilen von Befehlen an Gegenstände eine sehr praktische Funktion. Durch diesen Befehl können Spieler die benötigten Gegenstände direkt erhalten, ohne gegen Monster kämpfen oder sich an einen bestimmten Ort teleportieren zu müssen. Dies kann erheblich Zeit sparen, die Effizienz des Spiels verbessern und es den Spielern ermöglichen, sich mehr auf die Erkundung und den Aufbau der Welt zu konzentrieren. Insgesamt macht diese Funktion das Spielerlebnis flüssiger und angenehmer. 2. So verwenden Sie Terraria, um Objektbefehle zu erteilen 1. Öffnen Sie das Spiel und rufen Sie die Spieloberfläche auf. 2. Drücken Sie die „Enter“-Taste auf der Tastatur, um das Chat-Fenster zu öffnen. 3. Geben Sie im Chatfenster das Befehlsformat ein: „/give[Spielername][Artikel-ID][Artikelmenge]“.
 VUE3-Schnellstart: Verwenden der Vue.js-Anweisungen zum Wechseln der Registerkarten
Jun 15, 2023 pm 11:45 PM
VUE3-Schnellstart: Verwenden der Vue.js-Anweisungen zum Wechseln der Registerkarten
Jun 15, 2023 pm 11:45 PM
Dieser Artikel soll Anfängern helfen, schnell mit Vue.js3 zu beginnen und einen einfachen Tab-Wechseleffekt zu erzielen. Vue.js ist ein beliebtes JavaScript-Framework, mit dem Sie wiederverwendbare Komponenten erstellen, den Status Ihrer Anwendung einfach verwalten und Interaktionen mit der Benutzeroberfläche verwalten können. Vue.js3 ist die neueste Version des Frameworks. Im Vergleich zu früheren Versionen wurden große Änderungen vorgenommen, die Grundprinzipien haben sich jedoch nicht geändert. In diesem Artikel verwenden wir die Anweisungen von Vue.js, um den Tab-Wechseleffekt zu implementieren, um die Leser mit Vue.js vertraut zu machen
 Bildklassifizierung mit Fow-Shot-Learning mit PyTorch
Apr 09, 2023 am 10:51 AM
Bildklassifizierung mit Fow-Shot-Learning mit PyTorch
Apr 09, 2023 am 10:51 AM
In den letzten Jahren haben Deep-Learning-basierte Modelle bei Aufgaben wie der Objekterkennung und Bilderkennung gute Leistungen erbracht. Bei anspruchsvollen Bildklassifizierungsdatensätzen wie ImageNet, das 1.000 verschiedene Objektklassifizierungen enthält, übertreffen einige Modelle mittlerweile das menschliche Niveau. Diese Modelle basieren jedoch auf einem überwachten Trainingsprozess, sie werden erheblich von der Verfügbarkeit gekennzeichneter Trainingsdaten beeinflusst und die Klassen, die die Modelle erkennen können, sind auf die Klassen beschränkt, auf denen sie trainiert wurden. Da während des Trainings nicht genügend beschriftete Bilder für alle Klassen vorhanden sind, sind diese Modelle in realen Umgebungen möglicherweise weniger nützlich. Und wir möchten, dass das Modell Klassen erkennen kann, die es während des Trainings nicht gesehen hat, da es fast unmöglich ist, auf Bildern aller potenziellen Objekte zu trainieren. Wir werden aus einigen Beispielen lernen
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Implementierung von OpenAI CLIP für benutzerdefinierte Datensätze
Sep 14, 2023 am 11:57 AM
Implementierung von OpenAI CLIP für benutzerdefinierte Datensätze
Sep 14, 2023 am 11:57 AM
Im Januar 2021 kündigte OpenAI zwei neue Modelle an: DALL-E und CLIP. Bei beiden Modellen handelt es sich um multimodale Modelle, die Text und Bilder auf irgendeine Weise verbinden. Der vollständige Name von CLIP lautet Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), eine Vortrainingsmethode, die auf kontrastierenden Text-Bild-Paaren basiert. Warum CLIP einführen? Denn die derzeit beliebte StableDiffusion ist kein einzelnes Modell, sondern besteht aus mehreren Modellen. Eine der Schlüsselkomponenten ist der Text-Encoder, der zur Codierung der Texteingabe des Benutzers verwendet wird. Dieser Text-Encoder ist der Text-Encoder CL im CLIP-Modell.
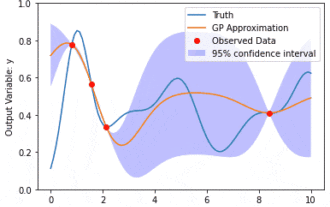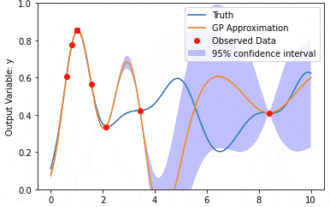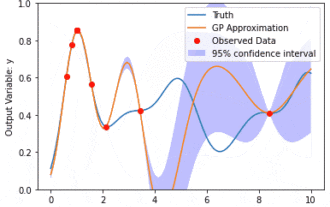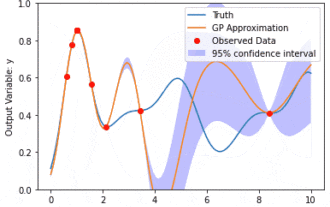 Datenmodellierung mit Kernel Model Gaußian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Datenmodellierung mit Kernel Model Gaußian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Kernel Model Gaussian Processes (KMGPs) sind hochentwickelte Werkzeuge zur Bewältigung der Komplexität verschiedener Datensätze. Es erweitert das Konzept traditioneller Gaußscher Prozesse um Kernelfunktionen. In diesem Artikel werden die theoretischen Grundlagen, praktischen Anwendungen und Herausforderungen von KMGPs ausführlich erörtert. Der Gaußsche Prozess des Kernelmodells ist eine Erweiterung des traditionellen Gaußschen Prozesses und wird beim maschinellen Lernen und in der Statistik verwendet. Bevor Sie kmgp verstehen, müssen Sie die Grundkenntnisse des Gaußschen Prozesses beherrschen und dann die Rolle des Kernelmodells verstehen. Gaußsche Prozesse (GPs) Gaußsche Prozesse sind Sätze von Zufallsvariablen mit einer endlichen Anzahl von Variablen, die durch die Gaußsche Verteilung gemeinsam verteilt werden, und werden zur Definition von Funktionswahrscheinlichkeitsverteilungen verwendet. Gaußsche Prozesse werden häufig bei Regressions- und Klassifizierungsaufgaben beim maschinellen Lernen verwendet und können zur Anpassung der Wahrscheinlichkeitsverteilung von Daten verwendet werden. Ein wichtiges Merkmal von Gaußschen Prozessen ist ihre Fähigkeit, Unsicherheitsschätzungen und -vorhersagen zu liefern
 Wie teile ich einen Datensatz richtig auf? Zusammenfassung von drei gängigen Methoden
Apr 08, 2023 pm 06:51 PM
Wie teile ich einen Datensatz richtig auf? Zusammenfassung von drei gängigen Methoden
Apr 08, 2023 pm 06:51 PM
Die Zerlegung des Datensatzes in einen Trainingssatz hilft uns, das Modell zu verstehen, was wichtig für die Verallgemeinerung des Modells auf neue, unsichtbare Daten ist. Ein Modell lässt sich möglicherweise nicht gut auf neue, noch nicht sichtbare Daten verallgemeinern, wenn es überangepasst ist. Daher können keine guten Vorhersagen getroffen werden. Eine geeignete Validierungsstrategie ist der erste Schritt zur erfolgreichen Erstellung guter Vorhersagen und zur Nutzung des Geschäftswerts von KI-Modellen. In diesem Artikel wurden einige gängige Strategien zur Datenaufteilung zusammengestellt. Eine einfache Trainings- und Testaufteilung unterteilt den Datensatz in Trainings- und Validierungsteile, wobei 80 % Training und 20 % Validierung erfolgen. Sie können dies mithilfe der Zufallsstichprobe von Scikit tun. Zunächst muss der Zufallsstartwert festgelegt werden, da sonst die gleiche Datenaufteilung nicht verglichen werden kann und die Ergebnisse beim Debuggen nicht reproduziert werden können. Wenn der Datensatz
 Modulares MoE wird zum Grundmodell für visuelles Multitasking-Lernen
Apr 13, 2023 pm 12:40 PM
Modulares MoE wird zum Grundmodell für visuelles Multitasking-Lernen
Apr 13, 2023 pm 12:40 PM
Multitasking-Lernen (MTL) stellt viele Herausforderungen dar, da die Gradienten zwischen verschiedenen Aufgaben widersprüchlich sein können. Um die Korrelation zwischen Aufgaben auszunutzen, führen die Autoren das Mod-Squad-Modell ein, ein modulares Modell, das aus mehreren Experten besteht. Das Modell kann die Zuordnung von Aufgaben und Experten flexibel optimieren und einige Experten für die Aufgabe auswählen. Das Modell ermöglicht, dass jeder Experte nur einem Teil der Aufgaben und jede Aufgabe nur einem Teil der Experten entspricht, wodurch die Nutzung der positiven Verbindungen zwischen Aufgaben maximiert wird. Mod-Squad integriert Mixture of Experts (MoE)-Schichten in das Vision Transformer-Modell und führt eine neue Verlustfunktion ein, die spärliche, aber starke Abhängigkeiten zwischen Experten und Aufgaben fördert. Auch
