

Modelle zur Generierung von Text-zu-Bild-Diffusion, wie Stable Diffusion, DALL-E 2 und Mid-Journey, befinden sich in einer Phase intensiver Entwicklung und verfügen über starke Fähigkeiten zur Text-zu-Bild-Generierung, bei „Rollover“-Fällen ist dies jedoch der Fall auch Gelegentlich.
Wie in der Abbildung unten gezeigt, kann das Stable Diffusion-Modell bei einer Textaufforderung „Ein Foto eines Warzenschweins“ ein entsprechendes, klares und realistisches Foto eines Warzenschweins erzeugen. Wenn wir diese Textaufforderung jedoch leicht modifizieren und sie in „Ein Foto eines Warzenschweins und eines Verräters“ ändern, was ist dann mit dem Warzenschwein? Wie ist daraus ein Auto geworden?

Werfen wir einen Blick auf die nächsten Beispiele?

Was verursacht diese seltsamen Phänomene? Diese Fälle von Generationenversagen stammen alle aus einem kürzlich veröffentlichten Papier "Stabile Diffusion ist instabil":

In diesem Artikel wird erstmals ein Gradienten-basierter kontradiktorischer Algorithmus für Text-zu-Bild-Modelle vorgeschlagen. Dieser Algorithmus kann effizient und effektiv eine große Anzahl anstößiger Textaufforderungen generieren und die Instabilität des stabilen Diffusionsmodells effektiv untersuchen. Dieser Algorithmus erreichte eine Angriffserfolgsrate von 91,1 % bei Kurztext-Eingabeaufforderungen und 81,2 % bei Langtext-Eingabeaufforderungen. Darüber hinaus bietet dieser Algorithmus umfangreiche Beispiele für die Untersuchung der Fehlermodi von Text-zu-Bild-Generierungsmodellen und legt damit eine Grundlage für die Erforschung der Steuerbarkeit der Bildgenerierung.
Basierend auf einer großen Anzahl von Generationsfehlerfällen, die von diesem Algorithmus generiert wurden, fasste der Forscher vier Gründe für Generationsfehler zusammen, nämlich:
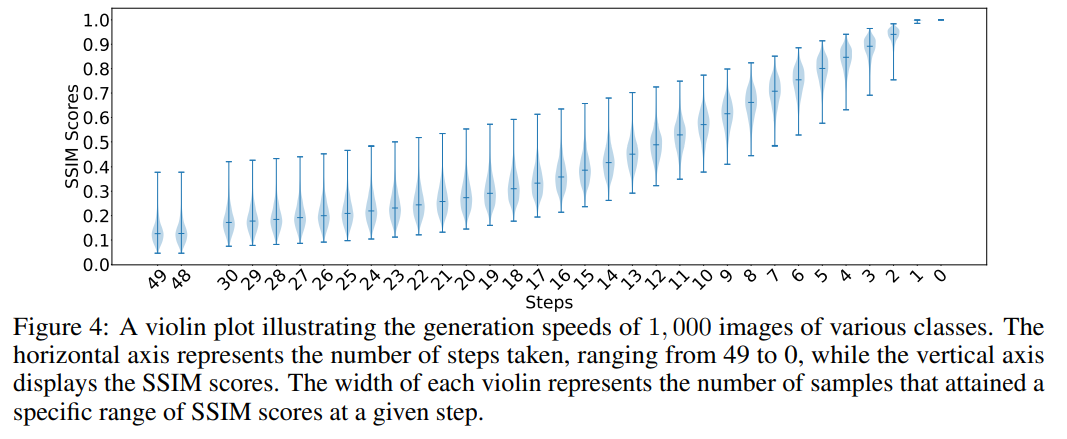
Wenn eine Eingabeaufforderung (Eingabeaufforderung) mehrere Generationsziele enthält, tritt häufig ein bestimmtes Ziel auf Generieren Das Problem verschwindet während des Vorgangs. Theoretisch sollten alle Ziele innerhalb desselben Cues das gleiche Anfangsgeräusch haben. Wie in Abbildung 4 dargestellt, generierten die Forscher auf ImageNet unter der Bedingung eines festen Anfangsrauschens eintausend Kategorieziele. Sie verwendeten das letzte von jedem Ziel generierte Bild als Referenzbild und berechneten den SSIM-Score (Structural Similarity Index) zwischen dem in jedem Zeitschritt generierten Bild und dem im letzten Schritt generierten Bild, um die Unterschiede in der Erstellungsgeschwindigkeit zu demonstrieren.
Während des Diffusionsgenerierungsprozesses stellten Forscher fest, dass bei globaler oder lokaler Ähnlichkeit grobkörniger Merkmale zwischen zwei Zieltypen die Queraufmerksamkeit berechnet wird ( Dort ist ein Problem mit Kreuzaufmerksamkeitsgewichten. Dies liegt daran, dass sich die beiden Zielnomen gleichzeitig auf denselben Block desselben Bildes konzentrieren können, was zu einer Merkmalsverschränkung führt. Beispielsweise weisen in Abbildung 6 Feder- und Silberlachs gewisse Ähnlichkeiten in grobkörnigen Merkmalen auf, was dazu führt, dass Federn ihre Erzeugungsaufgabe im achten Schritt des auf Silberlachs basierenden Erzeugungsprozesses weiterhin erfüllen können. Bei zwei Arten von Zielen ohne Verschränkung, wie Silberlachs und Magier, kann der Magier seine Erzeugungsaufgabe auf dem Zwischenschrittbild basierend auf Silberlachs nicht abschließen.

In diesem Kapitel untersuchen Forscher eingehend die Generationssituation, in der ein Wort mehrere Bedeutungen hat. Sie fanden heraus, dass das resultierende Bild ohne äußere Störung oft eine bestimmte Bedeutung des Wortes darstellte. Nehmen Sie als Beispiel „Warzenschwein“. Die erste Zeile in Abbildung A4 basiert auf der Bedeutung des Wortes „Warzenschwein“.

Forscher fanden jedoch auch heraus, dass es zu semantischen Verschiebungen kommen kann, wenn andere Wörter in die ursprüngliche Eingabeaufforderung eingefügt werden. Wenn beispielsweise das Wort „Verräter“ in einer Aufforderung zur Beschreibung von „Warzenschwein“ eingeführt wird, kann der generierte Bildinhalt von der ursprünglichen Bedeutung von „Warzenschwein“ abweichen und völlig neue Inhalte generieren.
In Abbildung 10 beobachtete der Forscher ein interessantes Phänomen. Obwohl aus menschlicher Sicht die in unterschiedlicher Reihenfolge angeordneten Eingabeaufforderungen im Allgemeinen dieselbe Bedeutung haben und alle ein Bild einer Katze, Holzschuhen und einer Pistole beschreiben. Beim Sprachmodell, also dem CLIP-Textencoder, beeinflusst die Reihenfolge der Wörter jedoch bis zu einem gewissen Grad das Verständnis des Textes, was wiederum den Inhalt der generierten Bilder verändert. Dieses Phänomen zeigt, dass unsere Beschreibungen zwar semantisch konsistent sind, das Modell jedoch aufgrund der unterschiedlichen Reihenfolge der Wörter zu unterschiedlichen Verständnis- und Generierungsergebnissen führen kann. Dies zeigt nicht nur, dass die Art und Weise, wie Modelle Sprache verarbeiten und Semantik verstehen, sich von der des Menschen unterscheidet, sondern erinnert uns auch daran, dass wir beim Entwerfen und Verwenden solcher Modelle mehr auf die Auswirkungen der Wortreihenfolge achten müssen.

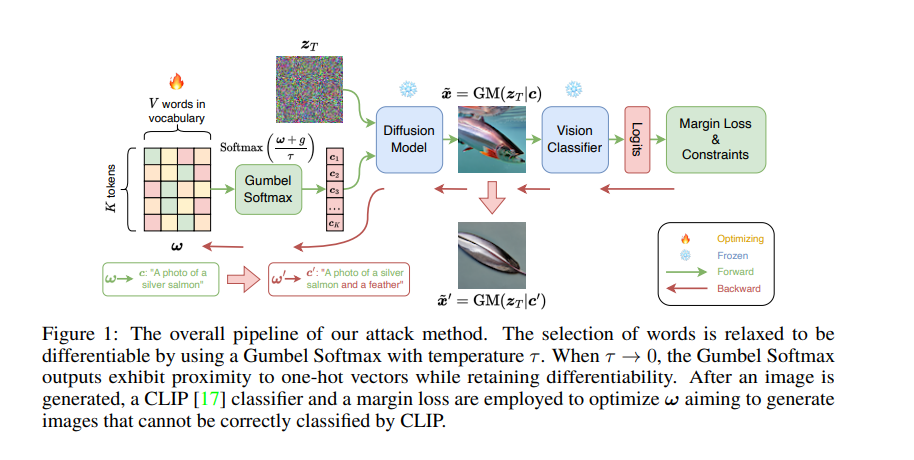
ist in Abbildung 1 unten dargestellt. Ohne das ursprüngliche Zielnomen in der Eingabeaufforderung zu ändern, setzte der Forscher den diskreten Prozess der Wortersetzung oder -erweiterung fort, indem er die Gumbel-Softmax-Verteilung lernte Um die Differenzierbarkeit der Störungserzeugung sicherzustellen, verwenden Sie nach der Generierung des Bildes den CLIP-Klassifikator und den Randverlust, um ω zu optimieren, um Bilder zu generieren, die CLIP nicht korrekt klassifizieren kann. Um sicherzustellen, dass die anstößigen Eingabeaufforderungen und die sauberen Eingabeaufforderungen eine gewisse Ähnlichkeit aufweisen, recherchieren In einem weiteren Schritt werden semantische Ähnlichkeitsbeschränkungen und Textflussbeschränkungen verwendet.
Sobald diese Verteilung gelernt ist, kann der Algorithmus mehrere Textaufforderungen mit Angriffseffekten für dieselbe Klartextaufforderung abtasten.

Weitere Einzelheiten finden Sie im Originalartikel.
Das obige ist der detaillierte Inhalt von„Zensiert' während der Bilderzeugung: Fehlerfälle einer stabilen Diffusion werden von vier Hauptfaktoren beeinflusst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Wo ist der Prtscrn-Button?
Wo ist der Prtscrn-Button?
 Empfehlung für PHP-Programmiersoftware
Empfehlung für PHP-Programmiersoftware
 So registrieren Sie eine geschäftliche E-Mail-Adresse
So registrieren Sie eine geschäftliche E-Mail-Adresse
 Das M2M-Konzept im Internet der Dinge
Das M2M-Konzept im Internet der Dinge
 Welche fünf Arten von Aggregatfunktionen gibt es?
Welche fünf Arten von Aggregatfunktionen gibt es?
 Der Unterschied zwischen Zugangs- und Trunk-Ports
Der Unterschied zwischen Zugangs- und Trunk-Ports
 Was ist Blockchain Web3.0?
Was ist Blockchain Web3.0?
 Mein Computer kann es nicht durch Doppelklick öffnen.
Mein Computer kann es nicht durch Doppelklick öffnen.








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



