

„Aber ich werde alt und alles, was ich möchte, ist, dass junge und vielversprechende Forscher wie Sie herausfinden, wie wir diese Superintelligenzen haben und unser Leben besser machen können, anstatt von ihnen kontrolliert zu werden.“
Am Juni Als er in der Abschlussrede der Beijing Intelligent Source Conference 2023 darüber sprach, wie Superintelligenz daran gehindert werden kann, Menschen zu täuschen und zu kontrollieren, blieb der 75-jährige Turing-Preisträger Geoffrey Hinton nicht ohne Worte.
Hintons Rede trägt den Titel „Zwei Wege zur Intelligenz“, d. h. unsterbliches Rechnen in digitaler Form und unsterbliches Rechnen auf der Grundlage von Hardware. Die Vertreter sind digitale Computer bzw. menschliche Gehirne. Am Ende der Rede konzentrierte er sich auf die Besorgnis über die Bedrohung durch Superintelligenz, die große Sprachmodelle (LLM) zu diesem Thema mit sich brachten, das die Zukunft der menschlichen Zivilisation betrifft, und zeigte sehr deutlich seine pessimistische Haltung.
Zu Beginn seiner Rede behauptete Hinton, dass Superintelligenz möglicherweise viel früher geboren wird, als er einst dachte. Diese Beobachtung wirft zwei große Fragen auf: (1) Wird der Intelligenzgrad künstlicher neuronaler Netze bald den von echten neuronalen Netzen übertreffen? (2) Können Menschen die Kontrolle über Super-KI garantieren? In seiner Rede auf der Konferenz ging er ausführlich auf die erste Frage ein; zur zweiten Frage sagte Hinton am Ende seiner Rede: „Superintelligenz könnte bald kommen.“

Schauen wir uns zunächst die traditionelle Berechnungsmethode an. Das Konstruktionsprinzip von Computern besteht darin, Anweisungen genau ausführen zu können. Das heißt, wenn wir dasselbe Programm (unabhängig davon, ob es sich um ein neuronales Netzwerk handelt oder nicht) auf unterschiedlicher Hardware ausführen, sollte der Effekt derselbe sein. Dies bedeutet, dass das im Programm enthaltene Wissen (z. B. die Gewichte eines neuronalen Netzwerks) unsterblich ist und nichts mit der spezifischen Hardware zu tun hat.

Um die Unsterblichkeit des Wissens zu erreichen, besteht unser Ansatz darin, Transistoren mit hoher Leistung zu betreiben, damit sie zuverlässig digital arbeiten können. Damit sind wir jedoch gleichbedeutend mit dem Verzicht auf andere Eigenschaften der Hardware, wie z. B. reichhaltige Analogie und hohe Variabilität.

Der Grund, warum herkömmliche Computer dieses Designmodell übernehmen, liegt darin, dass die Programme, die herkömmliche Computer ausführen, alle von Menschen geschrieben werden. Mit der Entwicklung der Technologie des maschinellen Lernens steht Computern nun eine weitere Möglichkeit zur Verfügung, Programm- und Aufgabenziele zu erreichen: probenbasiertes Lernen.
Dieses neue Paradigma ermöglicht es uns, eines der grundlegendsten Prinzipien des bisherigen Computersystemdesigns aufzugeben, nämlich die Trennung von Softwaredesign und Hardware, und stattdessen Software und Hardware gemeinsam zu entwerfen.
Der Vorteil des Software- und Hardware-Trennungsdesigns besteht darin, dass das gleiche Programm auf vielen verschiedenen Hardwaregeräten ausgeführt werden kann. Gleichzeitig können wir beim Entwurf des Programms nur die Software betrachten, unabhängig von der Hardware – aus diesem Grund Die Fakultät für Informatik und die Fakultät für Elektrotechnik können getrennt werden. Gründungsgrund.
Für das Co-Design von Software und Hardware schlug Hinton ein neues Konzept vor: Mortal Computation. Entspricht der zuvor erwähnten unsterblichen Form von Software, die wir hier als „unsterbliches Computing“ übersetzen.

Perishable Computing gibt die Unsterblichkeit der Ausführung derselben Software auf unterschiedlicher Hardware auf und übernimmt stattdessen eine neue Designidee: Wissen ist untrennbar mit den spezifischen physischen Details der Hardware verbunden. Diese neue Idee hat natürlich ihre Vor- und Nachteile. Zu den Hauptvorteilen zählen Energieeinsparungen und niedrige Hardwarekosten.
In Bezug auf Energieeinsparung können wir uns auf das menschliche Gehirn beziehen. Das menschliche Gehirn ist ein typisches sterbliches Computergerät. Obwohl es im menschlichen Gehirn immer noch digitale Ein-Bit-Berechnungen gibt, das heißt, Neuronen feuern oder nicht, handelt es sich insgesamt bei der überwiegenden Mehrheit der Berechnungen im menschlichen Gehirn um analoge Berechnungen mit sehr geringem Stromverbrauch.
Zerstörbares Computing kann auch kostengünstigere Hardware nutzen. Im Vergleich zu heutigen Prozessoren, die mit hoher Präzision in einem zweidimensionalen Modell hergestellt werden, kann die Hardware des Immortal Computing in einem dreidimensionalen Modell „gezüchtet“ werden, da wir nicht genau wissen müssen, wie die Hardware angeschlossen ist und wie genau Funktion jeder Komponente. Es ist klar, dass wir viele neue Nanotechnologien oder die Fähigkeit benötigen, biologische Neuronen genetisch zu verändern, um das „Wachstum“ der Computerhardware zu erreichen. Methoden zur Entwicklung biologischer Neuronen sind möglicherweise einfacher umzusetzen, da wir bereits wissen, dass biologische Neuronen ungefähr das tun können, was wir wollen.
Um die effizienten Möglichkeiten von Simulationsberechnungen zu demonstrieren, gab Hinton ein Beispiel: die Berechnung des Produkts eines neuronalen Aktivitätsvektors und einer Gewichtsmatrix (der größte Teil der Arbeit neuronaler Netze besteht aus solchen Berechnungen).

Für diese Aufgabe besteht der aktuelle Computeransatz darin, Hochleistungstransistoren zu verwenden, um den Wert in digitale Bitform darzustellen, und dann O (n²) digitale Operationen durchzuführen, um die beiden n- Bitwerte multiplizieren. Obwohl dies nur eine einzelne Operation auf dem Computer ist, handelt es sich um eine n²-Bit-Operation.
Und was wäre, wenn wir Simulationsrechnungen nutzen? Wir können uns neuronale Aktivität als Spannung und Gewicht als Leitfähigkeit vorstellen; dann kann in jeder Zeiteinheit die Spannung multipliziert mit der Leitfähigkeit die Ladung erhalten, und die Ladungen können überlagert werden. Die Energieeffizienz dieser Arbeitsweise wird deutlich höher sein, und tatsächlich gibt es bereits Chips, die auf diese Weise funktionieren. Leider, so Hinton, müssten die Menschen immer noch sehr teure Konverter verwenden, um die analogen Ergebnisse in digitale Form umzuwandeln. Er hofft, dass wir in Zukunft den gesamten Berechnungsprozess im Simulationsbereich abschließen können.
Destructible Computing weist auch einige Probleme auf. Das wichtigste davon ist, dass es schwierig ist, die Konsistenz der Ergebnisse sicherzustellen, dh die Berechnungsergebnisse auf unterschiedlicher Hardware können unterschiedlich sein. Darüber hinaus müssen wir neue Methoden finden, wenn Backpropagation nicht verfügbar ist.
Wenn Sie lernen, korrumpierbares Computing auf einer bestimmten Hardware durchzuführen, muss das Programm lernen, die spezifischen Simulationseigenschaften dieser Hardware auszunutzen, aber das ist nicht nötig um zu wissen, was diese Eigenschaften sind. Sie müssen beispielsweise nicht wissen, wie ein Neuron intern verbunden ist oder welche Funktion die Ein- und Ausgänge des Neurons verbindet.

Das bedeutet, dass wir den Backpropagation-Algorithmus nicht verwenden können, um die Gradienten zu erhalten, da Backpropagation ein genaues Vorwärtspropagationsmodell erfordert.
Was sollten wir also tun, da Backpropagation nicht in verfallbaren Berechnungen verwendet werden kann? Schauen wir uns einen einfachen Lernprozess an, der auf simulierter Hardware unter Verwendung einer Methode namens Gewichtsstörung durchgeführt wird.

Generieren Sie zunächst einen Zufallsvektor, der aus kleinen zufälligen Störungen für jedes Gewicht im Netzwerk besteht. Anschließend wird anhand einer oder einer kleinen Anzahl von Stichproben die Änderung der globalen Zielfunktion nach Verwendung dieses Störungsvektors gemessen. Schließlich ist entsprechend der Verbesserung der Zielfunktion die durch den Störungsvektor hervorgerufene Wirkung dauerhaft proportional zum Gewicht.
Der Vorteil dieses Algorithmus besteht darin, dass sein allgemeines Verhaltensmuster mit der Backpropagation übereinstimmt und er auch Gradienten folgt. Das Problem ist jedoch, dass die Varianz sehr hoch ist. Wenn die Netzwerkgröße zunimmt, ist daher das bei der Auswahl zufälliger Bewegungsrichtungen im Gewichtsraum erzeugte Rauschen sehr groß, was diese Methode unhaltbar macht. Dies bedeutet, dass diese Methode nur für kleine Netzwerke und nicht für große Netzwerke geeignet ist.

Ein anderer Ansatz ist die Aktivitätsstörung, die ähnliche Probleme hat, aber auch für größere Netzwerke besser funktioniert.

Die Aktivitätsstörungsmethode besteht darin, einen Zufallsvektor zu verwenden, um die Gesamteingabe jedes Neurons zu stören, und dann die Änderungen der Zielfunktion in einer kleinen Stichprobe zu beobachten und dann zu berechnen, wie um die Neuronengewichte von Elementen zu ändern, um dem Gradienten zu folgen.
Aktivitätsstörungen sind im Vergleich zu Gewichtsstörungen viel weniger laut. Und diese Methode reicht aus, um einfache Aufgaben wie MNIST zu lernen. Wenn Sie eine sehr kleine Lernrate verwenden, verhält es sich genau wie Backpropagation, jedoch viel langsamer. Wenn die Lernrate hoch ist, gibt es viel Lärm, aber es reicht aus, um Aufgaben wie MNIST zu bewältigen.
Aber was wäre, wenn unser Netzwerkumfang noch größer wäre? Hinton erwähnte zwei Ansätze.
Die erste Methode besteht darin, eine große Anzahl objektiver Funktionen zu verwenden. Dies bedeutet, dass anstelle einer einzelnen Funktion zur Definition des Ziels eines großen neuronalen Netzwerks eine große Anzahl von Funktionen verwendet wird, um die lokalen Ziele verschiedener zu definieren Neuronengruppen im Netzwerk.

Auf diese Weise werden große neuronale Netze in Teile zerlegt, und wir können Aktivitätsstörungen nutzen, um kleine mehrschichtige neuronale Netze zu lernen. Aber hier stellt sich die Frage: Woher kommen diese Zielfunktionen?

Eine Möglichkeit besteht darin, unbeaufsichtigtes kontrastives Lernen auf lokalen Patches auf verschiedenen Ebenen einzusetzen. Das funktioniert so: Ein lokaler Patch hat mehrere Darstellungsebenen, und auf jeder Ebene versucht der lokale Patch, mit der durchschnittlichen Darstellung übereinzustimmen, die von allen anderen lokalen Patches desselben Bildes gleichzeitig erzeugt wird anders als andere Bilder auf dieser Ebene.
Hinton sagt, dass die Methode in der Praxis gut funktioniert. Der allgemeine Ansatz besteht darin, für jede Darstellungsebene mehrere verborgene Ebenen zu haben, damit nichtlineare Operationen ausgeführt werden können. Diese Ebenen nutzen Aktivitätsstörungen für gieriges Lernen und breiten sich nicht auf niedrigere Ebenen aus. Da es nicht so viele Schichten wie die Backpropagation passieren kann, ist es nicht so leistungsstark wie die Backpropagation.
Tatsächlich ist dies eines der wichtigsten Forschungsergebnisse des Hinton-Teams der letzten Jahre. Weitere Informationen finden Sie im Machine Heart-Bericht „Nachdem die Backpropagation aufgegeben wurde, kam die Blockbuster-Forward-Gradienten-Lernforschung unter Beteiligung von Geoffrey Hinton.“ 》.

Mengye Ren hat durch umfangreiche Forschung gezeigt, dass diese Methode in neuronalen Netzen tatsächlich effektiv sein kann, die Operation jedoch sehr kompliziert ist und die tatsächliche Wirkung nicht mit der Backpropagation mithalten kann. Wenn die Tiefe eines großen Netzwerks größer ist, wird die Lücke bei der Rückausbreitung noch größer.
Hinton sagte, dass man nur sagen kann, dass dieser Lernalgorithmus, der Simulationseigenschaften nutzen kann, in Ordnung ist und für Aufgaben wie MNIST ausreicht, aber er ist nicht wirklich einfach zu verwenden. Beispielsweise ist die Leistung im ImageNet nicht ausreichend Aufgabe ist nicht sehr gut.
Ein weiteres großes Problem beim Perishable Computing besteht darin, dass es schwierig ist, die Vererbung von Wissen sicherzustellen. Da Perishable Computing stark von der Hardware abhängt, kann Wissen nicht durch Kopieren von Gewichten kopiert werden. Das heißt, wenn ein bestimmtes Stück Hardware „stirbt“, verschwindet auch das erlernte Wissen.
Hinton sagte, der beste Weg, dieses Problem zu lösen, bestehe darin, den Schülern Wissen zu vermitteln, bevor die Hardware „stirbt“. Diese Art von Methode wird Wissensdestillation genannt, ein Konzept, das erstmals von Hinton in der 2015 gemeinsam mit Oriol Vinyals und Jeff Dean verfassten Arbeit „Distilling the Knowledge in a Neural Network“ vorgeschlagen wurde.

Die Grundidee dieses Konzepts ist sehr einfach und ähnelt einem Lehrer, der Schülern Wissen beibringt: Der Lehrer zeigt den Schülern die richtigen Antworten auf verschiedene Eingaben, und die Schüler versuchen, die Antworten des Lehrers nachzuahmen.
Hinton nutzte das Beispiel der Tweets des ehemaligen US-Präsidenten Trump, um dies intuitiv zu veranschaulichen: Trump reagiert oft sehr emotional auf verschiedene Ereignisse, wenn er twittert, was seine Anhänger dazu veranlassen wird, sein eigenes „neuronales Netzwerk“ zu ändern, um die gleiche emotionale Reaktion hervorzurufen Auf diese Weise destillierte Trump die Vorurteile in den Köpfen seiner Anhänger, genau wie – Hinton mag Trump offensichtlich nicht.
Wie effektiv ist die Wissensdestillationsmethode? Angesichts der vielen Unterstützer Trumps dürfte die Wirkung nicht schlecht sein. Hinton erklärt dies anhand eines Beispiels: Angenommen, ein Agent muss Bilder in 1024 nicht überlappende Kategorien klassifizieren.

Um die richtige Antwort zu finden, benötigen wir nur 10 Bits an Informationen. Um den Agenten darin zu trainieren, eine bestimmte Probe korrekt zu identifizieren, müssen daher nur 10 Bits an Informationen bereitgestellt werden, um deren Gewichtung einzuschränken.
Aber was wäre, wenn wir einem Agenten beibringen würden, in diesen 1024 Kategorien ungefähr die gleichen Wahrscheinlichkeiten zu haben wie ein Lehrer? Das heißt, die Wahrscheinlichkeitsverteilung des Agenten soll mit der des Lehrers übereinstimmen. Diese Wahrscheinlichkeitsverteilung hat 1023 reelle Zahlen, und wenn diese Wahrscheinlichkeiten nicht sehr klein sind, bietet sie hunderte Male mehr Einschränkungen.

Um sicherzustellen, dass diese Wahrscheinlichkeiten nicht zu gering sind, können Lehrer bei „hoher Temperatur“ und Schüler bei der Ausbildung von Schülern auch bei „hoher Temperatur“ betrieben werden. Wenn Sie beispielsweise Logit verwenden, ist dies die Eingabe für Softmax. Für Lehrer können sie es basierend auf dem Temperaturparameter skalieren, um eine weichere Verteilung zu erhalten, und dann beim Unterrichten der Schüler dieselbe Temperatur verwenden.
Schauen wir uns ein konkretes Beispiel an. Unten sind einige Bilder von Charakter 2 aus dem MNIST-Trainingssatz. Rechts sind die Wahrscheinlichkeiten aufgeführt, die der Lehrer jedem Bild zugewiesen hat, wenn die Temperatur, bei der der Lehrer betrieben wird, hoch ist.
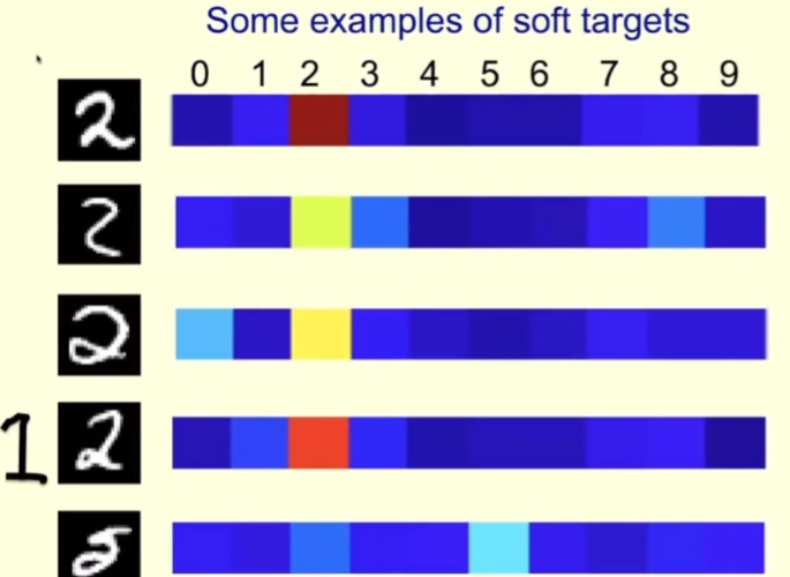
Für die erste Reihe ist der Lehrer zuversichtlich, dass es eine 2 ist; der Lehrer ist auch zuversichtlich, dass die zweite Reihe eine 2 ist, denkt aber auch, dass es eine 3 oder eine 8 sein könnte. Die dritte Zeile sieht ein bisschen wie 0 aus. Für dieses Beispiel sollte der Lehrer sagen, dass dies eine 2 ist, aber auch etwas Platz für 0 lassen. Auf diese Weise lernen die Schüler mehr daraus, als wenn ihnen direkt gesagt würde, dass dies 2 ist.
In der vierten Zeile können Sie sehen, dass der Lehrer zuversichtlich ist, dass es 2 ist, aber er hält es auch für einigermaßen wahrscheinlich, dass es 1 ist, schließlich ähnelt die 1, die wir schreiben, manchmal der auf der Zeile linke Seite des Bildes.
In der fünften Reihe machte der Lehrer einen Fehler und dachte, es sei 5 (laut MNIST-Etikett sollte es jedoch 2 sein). Auch aus den Fehlern ihrer Lehrer können Schüler viel lernen.
Destillation hat eine ganz besondere Eigenschaft: Wenn die vom Lehrer angegebenen Wahrscheinlichkeiten zur Schulung von Schülern verwendet werden, werden die Schüler dazu trainiert, auf die gleiche Weise wie der Lehrer zu verallgemeinern. Wenn der Lehrer der falschen Antwort eine bestimmte kleine Wahrscheinlichkeit zuordnet, werden die Schüler auch darin geschult, auf die falsche Antwort zu verallgemeinern.

Im Allgemeinen trainieren wir das Modell, um die richtige Antwort auf die Trainingsdaten zu erhalten, und verallgemeinern diese Fähigkeit auf die Testdaten. Wenn wir jedoch das Lehrer-Schüler-Trainingsmodell verwenden, trainieren wir direkt die Generalisierungsfähigkeit des Schülers, da das Trainingsziel des Schülers darin besteht, auf die gleiche Weise wie der Lehrer generalisieren zu können.
Natürlich können wir reichhaltigere Ergebnisse für die Destillation erzielen. Wir könnten beispielsweise jedem Bild eine Beschreibung statt nur einer einzelnen Beschriftung geben und den Schülern dann beibringen, die Wörter in diesen Beschreibungen vorherzusagen.

Als nächstes sprach Hinton über Forschung zum Wissensaustausch in Agentengruppen. Es ist auch eine Möglichkeit, Wissen weiterzugeben.

Wenn eine Community aus mehreren Agenten Wissen miteinander teilt, kann die Art und Weise, wie Wissen geteilt wird, weitgehend die Art und Weise bestimmen, wie Berechnungen durchgeführt werden.

Für digitale Modelle können wir durch Replikation eine große Anzahl von Agenten mit denselben Gewichten erstellen. Wir können diese Agenten veranlassen, sich verschiedene Teile des Trainingsdatensatzes anzusehen, sie jeweils den Gradienten der Gewichte basierend auf verschiedenen Teilen der Daten berechnen zu lassen und diese Gradienten dann zu mitteln. Auf diese Weise lernt jedes Modell, was jedes andere Modell gelernt hat. Der Vorteil dieser Trainingsstrategie besteht darin, dass große Datenmengen effizient verarbeitet werden können. Wenn das Modell groß ist, kann in jeder Freigabe eine große Anzahl von Bits gemeinsam genutzt werden.
Da diese Methode gleichzeitig erfordert, dass jeder Agent auf genau die gleiche Weise arbeitet, kann es sich nur um ein digitales Modell handeln.
Die Kosten für die Gewichtsverteilung sind ebenfalls sehr hoch. Um unterschiedliche Hardwareteile auf die gleiche Weise funktionieren zu lassen, müssen Computer mit so hoher Präzision hergestellt werden, dass sie immer die gleichen Ergebnisse erzielen, wenn sie die gleichen Anweisungen ausführen. Darüber hinaus ist der Stromverbrauch von Transistoren nicht gering.

Destillation kann auch die Gewichtsverteilung ersetzen. Insbesondere wenn Ihr Modell simulierte Eigenschaften bestimmter Hardware verwendet, können Sie keine Gewichtsverteilung verwenden, sondern müssen Destillation verwenden, um Wissen zu teilen.

Der Wissensaustausch mittels Destillation ist nicht effizient und die Bandbreite ist sehr gering. Genau wie in der Schule wollen Lehrer das Wissen, das sie kennen, in die Köpfe der Schüler einfließen lassen, aber das ist unmöglich, weil wir biologische Intelligenz haben und Ihr Gewicht mir nichts nützt.

Fassen wir hier kurz zusammen: Zwei völlig unterschiedliche Arten der Berechnung (digitale Berechnungen und biologische Berechnungen) sind ebenfalls sehr unterschiedlich.
Welche Form des groß angelegten Sprachmodells (LLM) wird derzeit entwickelt? Es handelt sich um numerische Berechnungen, die eine Gewichtsverteilung nutzen können.

Aber jeder Replika-Agent von LLM kann das Wissen im Dokument nur auf eine sehr ineffiziente Destillationsmethode lernen. Was LLM tut, ist, das nächste Wort des Dokuments vorherzusagen, aber es gibt keine Wahrscheinlichkeitsverteilung des nächsten Wortes durch den Lehrer. Es gibt lediglich eine Zufallsauswahl, d. h. das Wort, das der Autor des Dokuments beim nächsten Wort ausgewählt hat Position. LLM lernt tatsächlich von uns Menschen, die Bandbreite zur Wissensvermittlung ist jedoch sehr gering.
Obwohl die Effizienz jeder Kopie des LLM-Lernens durch Destillation sehr gering ist, gibt es viele davon, bis zu Tausenden, sodass sie tausendmal mehr lernen können als wir. Das bedeutet, dass der derzeitige LLM-Absolvent mehr Wissen hat als jeder von uns.
Als nächstes stellte Hinton eine Frage: „Was passiert, wenn diese digitalen Intelligenzen nicht sehr langsam durch Destillation von uns lernen, sondern beginnen, direkt von der realen Welt zu lernen?“

Tatsächlich , LLM lernt bereits beim Lernen von Dokumenten das Wissen, das Menschen über Tausende von Jahren gesammelt haben. Da Menschen unser Verständnis der Welt durch Sprache beschreiben, kann digitale Intelligenz das von Menschen durch Textlernen gesammelte Wissen direkt erwerben. Obwohl die Destillation langsam ist, erlernen sie sehr abstraktes Wissen.
Was wäre, wenn digitale Intelligenz durch Bild- und Videomodellierung unbeaufsichtigtes Lernen durchführen könnte? Mittlerweile sind im Internet riesige Mengen an Bilddaten verfügbar, und in Zukunft können wir möglicherweise Möglichkeiten finden, wie die KI effektiv aus diesen Daten lernen kann. Wenn die KI außerdem über Methoden wie Roboterarme verfügt, die die Realität manipulieren können, kann sie ihnen beim Lernen weiter helfen.
Hinton glaubt, dass, wenn digitale Agenten dies können, ihre Lernfähigkeit weitaus besser sein wird als die von Menschen und ihre Lerngeschwindigkeit sehr hoch sein wird.
Nun zurück zu der Frage, die Hinton eingangs gestellt hat: Wenn die Intelligenz der KI die unsere übertrifft, können wir sie dann trotzdem kontrollieren?
Hinton sagte, dass er diese Rede hauptsächlich gehalten habe, um seine Bedenken auszudrücken. „Ich denke, dass Superintelligenz viel früher entstehen könnte, als ich vorher dachte“, sagte er. Er nannte mehrere Möglichkeiten für Superintelligenz, Menschen zu kontrollieren.

Schlechte Akteure könnten beispielsweise Superintelligenz nutzen, um Wahlen zu manipulieren oder Kriege zu gewinnen (jemand tut diese Dinge tatsächlich bereits mit vorhandener KI).
Wenn Sie in diesem Fall möchten, dass die Superintelligenz effizienter ist, können Sie ihr erlauben, selbst Unterziele zu erstellen. Die Kontrolle über mehr Macht ist ein offensichtliches Unterziel. Denn je größer die Macht und je mehr Ressourcen sie kontrolliert, desto besser kann sie dem Agenten helfen, sein ultimatives Ziel zu erreichen. Die Superintelligenz könnte dann entdecken, dass sie leicht mehr Macht erlangen kann, indem sie die Menschen manipuliert, die sie ausüben.
Es fällt uns schwer, uns intelligentere Wesen als wir und die Art und Weise vorzustellen, wie wir mit ihnen interagieren. Aber Hinton glaubt, dass eine Superintelligenz, die schlauer ist als wir, definitiv lernen könnte, Menschen auszutricksen, die so viele Romane und politische Literatur haben, aus denen sie lernen können.
Sobald die Superintelligenz lernt, Menschen zu täuschen, kann sie Menschen dazu bringen, die von ihr gewünschten Verhaltensweisen auszuführen. Es gibt eigentlich keinen wesentlichen Unterschied zwischen diesem und der Täuschung anderer. Hinton sagte zum Beispiel: Wenn jemand ein Gebäude in Washington hacken will, muss er nicht unbedingt dorthin gehen, sondern muss den Leuten nur weismachen, dass sie das Gebäude hacken, um die Demokratie zu retten.
„Ich finde das sehr beängstigend.“ „Ich weiß nicht, wie ich das verhindern kann, aber ich bin alt, dass junge Talente Wege finden können, es zu schaffen.“ Superintelligenz hilft Menschen, ein besseres Leben zu führen, anstatt sie ihrer Kontrolle zu überlassen.
Aber er sagte auch, dass wir einen, wenn auch eher kleinen, Vorteil haben, da die KI nicht weiterentwickelt, sondern von Menschen geschaffen wurde. Auf diese Weise verfügt die KI nicht über die gleiche Wettbewerbsfähigkeit und die gleichen Ziele wie der ursprüngliche Mensch. Vielleicht können wir im Prozess ihrer Entwicklung moralische und ethische Grundsätze für die KI festlegen.
Wenn es sich jedoch um eine Superintelligenz handelt, deren Intelligenzniveau die des Menschen bei weitem übertrifft, ist dies möglicherweise nicht effektiv. Hinton sagt, er habe noch nie einen Fall gesehen, in dem etwas mit einem höheren Intelligenzniveau von etwas mit einem weitaus niedrigeren Intelligenzniveau kontrolliert wurde. Nehmen wir an, wenn Frösche den Menschen erschaffen haben, wer kontrolliert dann wen zwischen Fröschen und Menschen?
Schließlich veröffentlichte Hinton pessimistisch die letzte Folie dieser Rede:

Dies markiert nicht nur das Ende der Rede, sondern dient auch als Warnung an die gesamte Menschheit: Superintelligenz kann zum Menschen führen Das Ende der Zivilisation.
Das obige ist der detaillierte Inhalt vonDie letzte Rede des 75-jährigen Hinton auf der China-Konferenz mit dem Titel „Zwei Wege zur Intelligenz' endete mit Emotionen: Ich bin bereits alt und die Zukunft liegt in den Händen junger Menschen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



