
 Technologie-Peripheriegeräte
KI
6. Transformers-Jubiläum: Selbst das NeurIPS Oral gab es damals noch nicht, aber 8 Autoren haben mehrere KI-Einhörner gegründet
Technologie-Peripheriegeräte
KI
6. Transformers-Jubiläum: Selbst das NeurIPS Oral gab es damals noch nicht, aber 8 Autoren haben mehrere KI-Einhörner gegründet
6. Transformers-Jubiläum: Selbst das NeurIPS Oral gab es damals noch nicht, aber 8 Autoren haben mehrere KI-Einhörner gegründet

Von ChatGPT bis zur KI-Zeichentechnologie – diese jüngste Welle von Durchbrüchen im Bereich der künstlichen Intelligenz ist möglicherweise Transformer zu verdanken.
Heute ist der sechste Jahrestag der Einreichung des berühmten Transformer Papers.

Link zum Papier: https://arxiv.org/abs/1706.03762
Vor sechs Jahren wurde ein Papier mit einem etwas hochtrabenden Namen auf die Preprint-Papierplattform arXiv hochgeladen, das Der Satz „xx is All You Need“ wurde von Entwicklern im KI-Bereich immer wieder wiederholt und ist sogar zu einem Trend in Papiertiteln geworden. Transformer bedeutet nicht mehr Transformers, sondern stellt jetzt die fortschrittlichste Technologie im KI-Bereich dar . Technologie.
Sechs Jahre später, wenn wir auf dieses Papier zurückblicken, können wir viele interessante oder wenig bekannte Aspekte finden, wie der NVIDIA-KI-Wissenschaftler Jim Fan zusammenfasste.
„Aufmerksamkeitsmechanismus“ ist nicht das, was der Autor von Transformer vorgeschlagen hat
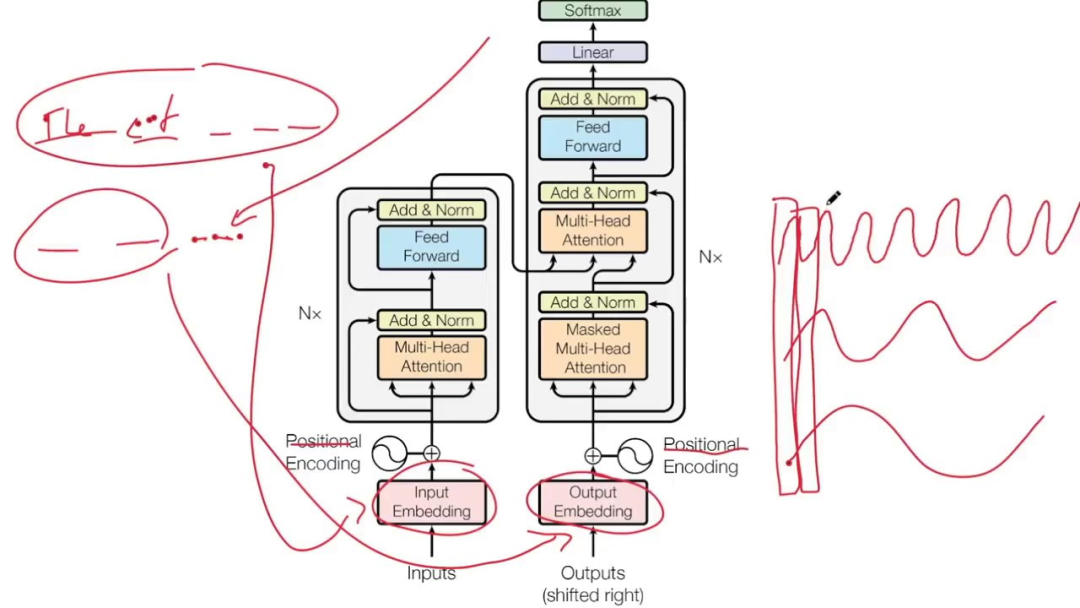
Das Transformer-Modell verzichtet auf die traditionellen CNN- und RNN-Einheiten und die gesamte Netzwerkstruktur besteht vollständig aus dem Aufmerksamkeitsmechanismus.
Obwohl der Name des Transformer-Papiers „Aufmerksamkeit ist alles, was Sie brauchen“ lautet und wir den Aufmerksamkeitsmechanismus deswegen weiterhin loben, achten Sie bitte auf eine interessante Tatsache: Es waren nicht die Forscher von Transformer, die die Aufmerksamkeit erfunden haben. aber Sie haben diesen Mechanismus auf die Spitze getrieben.
Der Aufmerksamkeitsmechanismus wurde 2014 von einem Team unter der Leitung des Deep-Learning-Pioniers Yoshua Bengio vorgeschlagen:
„Neural Machine Translation by Jointly Learning to Align and Translate“, der Titel ist relativ einfach.
In diesem ICLR-Artikel von 2015 schlugen Bengio et al. eine Kombination aus RNN + „Kontextvektor“ (d. h. Aufmerksamkeit) vor. Obwohl es einer der größten Meilensteine auf dem Gebiet des NLP ist, ist es weitaus weniger bekannt als Transformer. Der Artikel des Bengio-Teams wurde bisher 29.000 Mal zitiert, Transformer sogar 77.000 Mal.
Der Aufmerksamkeitsmechanismus von KI ist auf natürliche Weise der visuellen Aufmerksamkeit des Menschen nachempfunden. Das menschliche Gehirn verfügt über eine angeborene Fähigkeit: Wenn wir ein Bild betrachten, scannen wir das Bild zunächst schnell und fokussieren uns dann auf den Zielbereich, auf den wir fokussieren möchten.
Wenn Sie keine Teilinformationen loslassen, werden Sie unweigerlich viel nutzlose Arbeit leisten, was dem Überleben nicht förderlich ist. Ebenso kann die Einführung ähnlicher Mechanismen in Deep-Learning-Netzwerke Modelle vereinfachen und Berechnungen beschleunigen. Im Wesentlichen besteht die Aufmerksamkeit darin, aus einer großen Informationsmenge eine kleine Menge wichtiger Informationen herauszufiltern und sich auf diese wichtigen Informationen zu konzentrieren, während die meisten unwichtigen Informationen ignoriert werden.
In den letzten Jahren wurden Aufmerksamkeitsmechanismen in verschiedenen Bereichen des Deep Learning weit verbreitet eingesetzt, beispielsweise zur Erfassung rezeptiver Felder auf Bildern in Richtung Computer Vision oder zur Lokalisierung wichtiger Token oder Funktionen im NLP. Eine große Anzahl von Experimenten hat gezeigt, dass Modelle mit Aufmerksamkeitsmechanismen erhebliche Leistungsverbesserungen bei Aufgaben wie der Bildklassifizierung, -segmentierung, -verfolgung und -verbesserung sowie der Erkennung natürlicher Sprache, dem Verstehen, der Beantwortung von Fragen und der Übersetzung erzielt haben.
Das Transformer-Modell, das den Aufmerksamkeitsmechanismus einführt, kann als Allzweck-Sequenzcomputer betrachtet werden. Der Aufmerksamkeitsmechanismus ermöglicht es dem Modell, bei der Verarbeitung der Eingabesequenz unterschiedliche Aufmerksamkeitsgewichte zuzuweisen ermöglicht es dem Transformer, Abhängigkeiten und Kontextinformationen über große Entfernungen zu erfassen und so den Effekt der Sequenzverarbeitung zu verbessern.
Aber zu dieser Zeit sprachen weder Transformer noch das ursprüngliche Aufmerksamkeitspapier von universellen Sequenzcomputern. Stattdessen sehen die Autoren darin einen Mechanismus zur Lösung eines engen und spezifischen Problems – der maschinellen Übersetzung. Wenn wir also in Zukunft den Ursprung von AGI zurückverfolgen, können wir ihn möglicherweise auf das „bescheidene“ Google Translate zurückführen.
Obwohl es von NeurIPS 2017 angenommen wurde, erhielt es nicht einmal eine mündliche
Transformer Obwohl dieser Artikel mittlerweile sehr einflussreich ist, erhielt er nicht einmal eine mündliche Stellungnahme auf NeurIPS 2017, der weltweit führenden KI-Konferenz. , geschweige denn einen Preis gewinnen. Die Konferenz erhielt in diesem Jahr insgesamt 3240 Beiträge, von denen 678 als Konferenzbeiträge ausgewählt wurden. Unter diesen Beiträgen waren 40 mündliche Beiträge, 112 Spotlight-Beiträge und 3 die besten „Thesis“, ein „Test of Time“-Preis, Transformer ist für den Preis nicht berechtigt.
Obwohl ich den NeurIPS 2017 Paper Award verpasst habe, ist der Einfluss von Transformer für alle offensichtlich.
Jim Fan kommentierte: Es ist nicht die Schuld der Jury, dass es für die Menschen schwierig ist, die Bedeutung einer einflussreichen Studie zu erkennen, bevor sie einflussreich wird. Es gibt jedoch auch Artikel, die das Glück haben, sofort entdeckt zu werden. Beispielsweise gewann ResNet, vorgeschlagen von He Yuming und anderen, den besten Artikel des CVPR 2016. Diese Forschung ist wohlverdient und wurde von der führenden KI-Konferenz zu Recht anerkannt. Doch zum jetzigen Zeitpunkt im Jahr 2017 sind sehr kluge Forscher möglicherweise nicht in der Lage, die durch LLM hervorgerufenen Veränderungen vorherzusagen. Genau wie in den 1980er Jahren konnten nur wenige Menschen den Tsunami vorhersehen, der seit 2012 durch Deep Learning verursacht wurde. „Acht Autoren, jeder mit einem wundervollen Leben“ ursprüngliche Institutionen.
Am 26. April 2022 wurde ein Unternehmen namens „Adept“ offiziell gegründet. Es gibt 9 Mitbegründer, darunter Ashish Vaswani und Niki Parmar, zwei Autoren des Transformer-Papiers.? Tiefe Frühe Anwendungen des Lernens in der Sprachmodellierung. Im Jahr 2016 wechselte er zu Google Brain und leitete die Transformer-Forschung, bevor er Google im Jahr 2021 verließ.
Niki Parmar
schloss ihr Masterstudium an der University of Southern California ab und kam 2016 zu Google. Dort entwickelte sie einige erfolgreiche Q&A- und Textähnlichkeitsmodelle für die Google-Suche und -Anzeigen. Sie leitete frühe Arbeiten zur Erweiterung des Transformer-Modells auf Bereiche wie Bilderzeugung, Computer Vision und mehr. Im Jahr 2021 verließ sie auch Google. 
Im März 2023 gab Adept den Abschluss einer Serie-B-Finanzierung in Höhe von 350 Millionen US-Dollar bekannt. Die Bewertung des Unternehmens überstieg 1 Milliarde US-Dollar und machte es zu einem Einhorn. Als Adept jedoch öffentlich Gelder sammelte, hatten Niki Parmar und Ashish Vaswani Adept bereits verlassen und gründeten ihr eigenes neues KI-Unternehmen. Dieses neue Unternehmen ist jedoch weiterhin vertraulich und wir können keine detaillierten Informationen über das Unternehmen erhalten. Ein weiterer Papierautor Noam Shazeer ist einer der wichtigsten frühen Mitarbeiter von Google. Ende 2000 kam er zu Google, bis er 2021 endgültig ausschied und dann CEO eines Start-ups namens „Character.AI“ wurde. Der Gründer von Character.AI ist neben Noam Shazeer Daniel De Freitas, beide aus dem LaMDA-Team von Google. Zuvor haben sie LaMDA entwickelt, ein Sprachmodell, das Konversationsprogramme bei Google unterstützt. Im März dieses Jahres gab Character.AI den Abschluss einer Finanzierung in Höhe von 150 Millionen US-Dollar mit einer Bewertung von 1 Milliarde US-Dollar bekannt. Es ist eines der wenigen Startups mit dem Potenzial, mit OpenAI, der Organisation, der ChatGPT gehört, zu konkurrieren , und es ist auch selten, nur 16 zu verwenden. Ein Unternehmen, das sich in nur wenigen Monaten zu einem Einhorn entwickelt hat. Seine Anwendung, Character.AI, ist ein Chatbot mit neuronalem Sprachmodell, der menschenähnliche Textantworten generieren und kontextbezogene Gespräche führen kann. Character.AI wurde am 23. Mai 2023 im Apple App Store und Google Play Store veröffentlicht und in der ersten Woche mehr als 1,7 Millionen Mal heruntergeladen. Im Mai 2023 fügte der Dienst ein kostenpflichtiges Abonnement für 9,99 $ pro Monat namens c.ai+ hinzu, das Benutzern unter anderem bevorzugten Chat-Zugriff, schnellere Reaktionszeiten und frühen Zugriff auf neue Funktionen ermöglicht. 
Aidan N. Gomez verließ Google 2019, arbeitete dann als Forscher bei FOR.ai und ist jetzt Mitbegründer und CEO von Cohere.
Cohere ist ein generatives KI-Startup, das 2019 gegründet wurde. Zu seinem Kerngeschäft gehört die Bereitstellung von NLP-Modellen und die Unterstützung von Unternehmen bei der Verbesserung der Mensch-Computer-Interaktion. Die drei Gründer sind Ivan Zhang, Nick Frosst und Aidan Gomez, darunter Gomez und Frosst ehemalige Mitglieder des Google Brain-Teams. Im November 2021 kündigte Google Cloud eine Partnerschaft mit Cohere an, wobei Google Cloud seine robuste Infrastruktur für den Betrieb der Cohere-Plattform nutzt und Cohere die TPUs von Cloud für die Entwicklung und Bereitstellung seiner Produkte nutzt.
Es ist erwähnenswert, dass Cohere gerade eine Serie-C-Finanzierung in Höhe von 270 Millionen US-Dollar erhalten hat und sich damit zu einem Einhorn mit einer Marktkapitalisierung von 2,2 Milliarden US-Dollar entwickelt hat.

Łukasz Kaiser verließ Google im Jahr 2021, arbeitete 7 Jahre und 9 Monate bei Google und ist jetzt Forscher bei OpenAI. Während seiner Tätigkeit als Forschungswissenschaftler bei Google war er am Entwurf neuronaler SOTA-Modelle für maschinelle Übersetzung, Analyse und andere Algorithmen- und Generierungsaufgaben beteiligt. Er war Mitautor des TensorFlow-Systems und der Tensor2Tensor-Bibliothek.

Jakob Uszkoreit verließ Google im Jahr 2021 und arbeitete 13 Jahre bei Google, bevor er als Mitbegründer zu Inceptive kam. Inceptive ist ein KI-Pharmaunternehmen, das sich der Nutzung von Deep Learning zur Entwicklung von RNA-Medikamenten widmet.
Während seiner Arbeit bei Google war Jakob Uszkoreit an der Bildung des Sprachverständnisteams von Google Assistant beteiligt und arbeitete in der Anfangszeit auch an Google Translate.

Illia Polosukhin verließ Google im Jahr 2017 und ist jetzt Mitbegründerin und CTO von NEAR.AI (einem Unternehmen für Blockchain-Technologie).

Der Einzige, der noch bei Google bleibt, ist Llion Jones, dies ist sein 9. Jahr bei Google.

Jetzt sind 6 Jahre vergangen, seit der Artikel „Attention Is All You Need“ veröffentlicht wurde, und einige entschieden sich, bei Google zu bleiben Der Einfluss von Transformer hält immer noch an.
Das obige ist der detaillierte Inhalt von6. Transformers-Jubiläum: Selbst das NeurIPS Oral gab es damals noch nicht, aber 8 Autoren haben mehrere KI-Einhörner gegründet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
Unter Verwendung von OpenSSL für die digitale Signaturüberprüfung im Debian -System können Sie folgende Schritte befolgen: Vorbereitung für die Installation von OpenSSL: Stellen Sie sicher, dass Ihr Debian -System OpenSSL installiert hat. Wenn nicht installiert, können Sie den folgenden Befehl verwenden, um es zu installieren: sudoaptupdatesudoaptininTallopenSSL, um den öffentlichen Schlüssel zu erhalten: Die digitale Signaturüberprüfung erfordert den öffentlichen Schlüssel des Unterzeichners. In der Regel wird der öffentliche Schlüssel in Form einer Datei wie Public_key.pe bereitgestellt
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
