
 Technologie-Peripheriegeräte
KI
Prompt schaltet Funktionen zur Generierung von Sprachmodellen frei und SpeechGen implementiert die Sprachübersetzung und das Patchen mehrerer Aufgaben.
Technologie-Peripheriegeräte
KI
Prompt schaltet Funktionen zur Generierung von Sprachmodellen frei und SpeechGen implementiert die Sprachübersetzung und das Patchen mehrerer Aufgaben.
Prompt schaltet Funktionen zur Generierung von Sprachmodellen frei und SpeechGen implementiert die Sprachübersetzung und das Patchen mehrerer Aufgaben.

Link zur H-These: https://arxiv.org/pdf/2306.02207.pdf

- Demoseite: https://ga642381.github.io/speeeeeeeeeeeechgen.html
- Code: https:/ /github.com/ga642381/SpeechGen
- Einführung und MotivationGroße Sprachmodelle (LLMs) haben bei AIGC (Artificial Intelligence Generated Content) erhebliche Aufmerksamkeit erregt, insbesondere mit dem Aufkommen von ChatGPT.
Die Verarbeitung kontinuierlicher Sprache mit großen Sprachmodellen bleibt jedoch eine ungelöste Herausforderung, die die Anwendung großer Sprachmodelle bei der Sprachgenerierung behindert. Da Sprachsignale über reine Textdaten hinaus umfangreiche Informationen wie Sprecher und Emotionen enthalten, entstehen weiterhin sprachbasierte Sprachmodelle (Sprach-LM).
Obwohl sich Sprachmodelle im Vergleich zu textbasierten Sprachmodellen noch in einem frühen Stadium befinden, haben sie großes Potenzial und sind voller Erwartungen, da Sprachdaten umfangreichere Informationen enthalten als Text.
Forscher erforschen aktiv das Potenzial des Prompt-Paradigmas, um die Leistungsfähigkeit vorab trainierter Sprachmodelle freizusetzen. Diese Eingabeaufforderung leitet das vorab trainierte Sprachmodell an, bestimmte nachgelagerte Aufgaben durch Feinabstimmung einer kleinen Anzahl von Parametern auszuführen. Diese Technik ist im NLP-Bereich aufgrund ihrer Effizienz und Wirksamkeit beliebt. Im Bereich der Sprachverarbeitung hat SpeechPrompt erhebliche Verbesserungen der Parametereffizienz gezeigt und bei verschiedenen Sprachklassifizierungsaufgaben eine wettbewerbsfähige Leistung erzielt.
Ob Hinweise Sprachmodellen dabei helfen können, die Generierungsaufgabe zu erfüllen, ist jedoch noch offen. In diesem Artikel schlagen wir ein innovatives einheitliches Framework vor: SpeechGen, das darauf abzielt, das Potenzial von Sprachmodellen für Generierungsaufgaben freizusetzen. Wie in der folgenden Abbildung dargestellt, werden ein Sprachteil und eine bestimmte Eingabeaufforderung (Eingabeaufforderung) als Eingabe an den Sprach-LM weitergeleitet, und der Sprach-LM kann bestimmte Aufgaben ausführen. Wenn beispielsweise die rote Eingabeaufforderung als Eingabe verwendet wird, kann Sprach-LM die Aufgabe der Sprachübersetzung übernehmen.
Das von uns vorgeschlagene Framework hat die folgenden Vorteile:
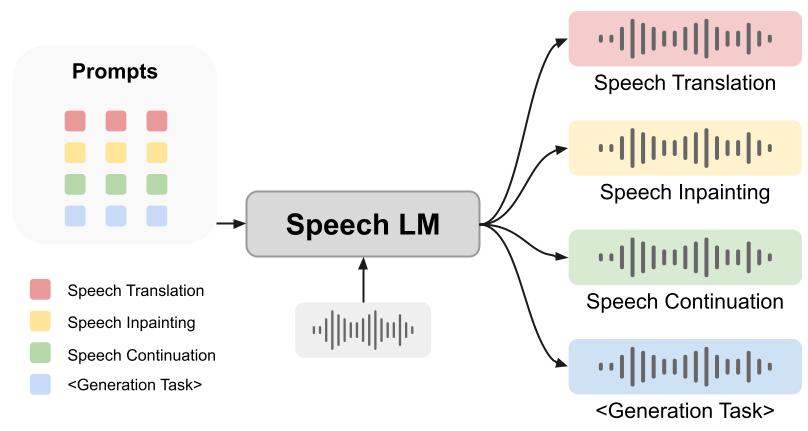 1. Textlos: Unser Framework und das darauf basierende Sprachsprachmodell sind unabhängig von Textdaten und haben einen unschätzbaren Wert. Schließlich ist der Prozess des Erhaltens markierter Text-zu-Sprache-Paare zeitaufwändig und mühsam, und in manchen Sprachen wird möglicherweise nicht einmal der richtige Text gefunden. Die textfreie Funktion ermöglicht es unseren leistungsstarken Sprachgenerierungsfunktionen, verschiedene Sprachbedürfnisse abzudecken, was der gesamten Menschheit zugute kommt.
1. Textlos: Unser Framework und das darauf basierende Sprachsprachmodell sind unabhängig von Textdaten und haben einen unschätzbaren Wert. Schließlich ist der Prozess des Erhaltens markierter Text-zu-Sprache-Paare zeitaufwändig und mühsam, und in manchen Sprachen wird möglicherweise nicht einmal der richtige Text gefunden. Die textfreie Funktion ermöglicht es unseren leistungsstarken Sprachgenerierungsfunktionen, verschiedene Sprachbedürfnisse abzudecken, was der gesamten Menschheit zugute kommt.
2. Vielseitigkeit: Das von uns entwickelte Framework ist äußerst vielseitig und kann auf eine Vielzahl von Sprachgenerierungsaufgaben angewendet werden. Die Experimente in der Arbeit verwenden als Beispiele Sprachübersetzung, Sprachwiederherstellung und Sprachkontinuität.
3. Einfach zu befolgen: Unser vorgeschlagenes Framework bietet eine allgemeine Lösung für verschiedene Sprachgenerierungsaufgaben und erleichtert das Entwerfen nachgelagerter Modelle und Verlustfunktionen.
4. Übertragbarkeit: Unser Framework ist nicht nur leicht an zukünftige Sprachmodelle anpassbar, sondern birgt auch großes Potenzial zur weiteren Verbesserung von Effizienz und Effektivität. Besonders spannend ist, dass unser Framework mit dem Aufkommen fortschrittlicher Sprachmodelle noch leistungsfähigere Entwicklungen einleiten wird.
5. Erschwinglichkeit: Unser Framework ist sorgfältig so konzipiert, dass nur eine kleine Anzahl von Parametern trainiert werden muss, anstatt ein ganzes riesiges Sprachmodell. Dadurch wird der Rechenaufwand erheblich reduziert und der Trainingsprozess kann auf einer GTX 2080-GPU durchgeführt werden. Auch Universitätslabore können sich einen solchen Rechenaufwand leisten.
SpeechGen-Einführung
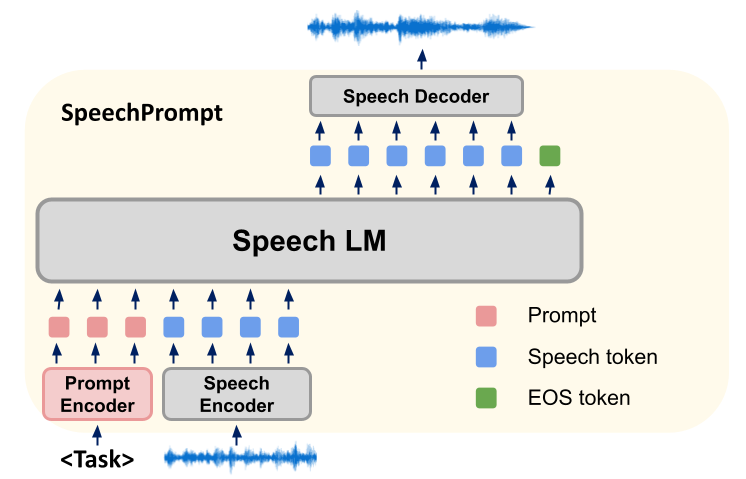
Unsere Forschungsmethode besteht darin, ein neues Framework SpeechGen zu entwickeln, das hauptsächlich Spoken Language Models (SLMs) verwendet, um verschiedene nachgelagerte Sprachgenerierungsaufgaben zu optimieren. Während des Trainings werden die Parameter von SLMs konstant gehalten und unsere Methode konzentriert sich auf das Lernen aufgabenspezifischer Eingabeaufforderungsvektoren. SLMs erzeugen effizient die für eine bestimmte Spracherzeugungsaufgabe erforderliche Ausgabe, indem sie gleichzeitig Cue-Vektoren und Eingabeeinheiten konditionieren. Diese diskreten Einheitsausgaben werden dann in einen einheitenbasierten Sprachsynthesizer eingegeben, der entsprechende Wellenformen erzeugt.
Unser SpeechGen-Framework besteht aus drei Elementen: Speech Encoder, SLM und Speech Decoder.
Zuerst nimmt der Sprachencoder eine Wellenform als Eingabe und wandelt sie in eine Folge von Einheiten um, die aus einem begrenzten Vokabular abgeleitet sind. Um die Sequenzlänge zu verkürzen, werden wiederholte aufeinanderfolgende Einheiten entfernt, um eine komprimierte Sequenz von Einheiten zu erzeugen. Der SLM fungiert dann als Sprachmodell für die Einheitenfolge und optimiert die Wahrscheinlichkeit durch Vorhersage der vorherigen Einheit und nachfolgender Einheiten der Einheitenfolge. Wir nehmen umgehend Anpassungen am SLM vor, um es bei der Generierung geeigneter Einheiten für die Aufgabe anzuleiten. Schließlich werden die vom SLM generierten Token von einem Sprachdecoder verarbeitet und wieder in Wellenformen umgewandelt. Bei unserer Cue-Tuning-Strategie werden Cue-Vektoren am Anfang der Eingabesequenz eingefügt, die die Richtung der SLMs während der Generierung vorgeben. Die genaue Anzahl der eingefügten Hinweise hängt von der Architektur der SLMs ab. In einem Sequenz-zu-Sequenz-Modell werden Hinweise sowohl zum Encoder-Eingang als auch zum Decoder-Eingang hinzugefügt, aber in einer Nur-Encoder- oder Nur-Decoder-Architektur wird nur ein Hinweis vor der Eingabesequenz hinzugefügt.
In Sequenz-zu-Sequenz-SLMs (wie mBART) verwenden wir selbstüberwachte Lernmodelle (wie HuBERT), um Eingaben zu verarbeiten und Sprache anzusprechen. Dadurch werden diskrete Einheiten für die Eingabe und entsprechende diskrete Einheiten für das Ziel generiert. Wir fügen Hinweisvektoren vor den Encoder- und Decoder-Eingängen hinzu, um die Eingabesequenz zu konstruieren. Darüber hinaus verbessern wir die Leitfähigkeit von Hinweisen weiter, indem wir Schlüssel-Wert-Paare im Aufmerksamkeitsmechanismus ersetzen.
Beim Modelltraining verwenden wir den Kreuzentropieverlust als Zielfunktion für alle Generierungsaufgaben und berechnen den Verlust durch Vergleich der Vorhersageergebnisse des Modells und der diskreten Zieleinheitenbezeichnungen. In diesem Prozess ist der Cue-Vektor der einzige Parameter im Modell, der trainiert werden muss, während die Parameter von SLMs während des Trainingsprozesses unverändert bleiben, was die Konsistenz des Modellverhaltens gewährleistet. Durch das Einfügen von Cue-Vektoren leiten wir SLMs an, aufgabenspezifische Informationen aus der Eingabe zu extrahieren und erhöhen die Wahrscheinlichkeit, eine Ausgabe zu erzeugen, die einer bestimmten Spracherzeugungsaufgabe entspricht. Dieser Ansatz ermöglicht es uns, das Verhalten von SLMs zu optimieren und anzupassen, ohne ihre zugrunde liegenden Parameter zu ändern.
Im Allgemeinen basiert unsere Forschungsmethode auf einem neuen Framework SpeechGen, das den Generierungsprozess des Modells durch das Training von Cue-Vektoren steuert und es ihm ermöglicht, effektiv Ausgaben zu erzeugen, die bestimmte Sprachgenerierungsaufgaben erfüllen.
Experimente
Unser Framework kann für jedes Sprach-LM und verschiedene Generierungsaufgaben verwendet werden und hat großes Potenzial. Da VALL-E und AudioLM in unseren Experimenten keine Open Source sind, entscheiden wir uns für die Verwendung von Unit mBART als Sprach-LM für die Fallstudie. Wir verwenden Sprachübersetzung, Sprachinpainting und Sprachfortsetzung als Beispiele, um die Fähigkeiten unseres Frameworks zu demonstrieren. Eine schematische Darstellung dieser drei Aufgaben ist unten dargestellt. Alle Aufgaben sind Spracheingabe, Sprachausgabe, keine Texthilfe erforderlich.
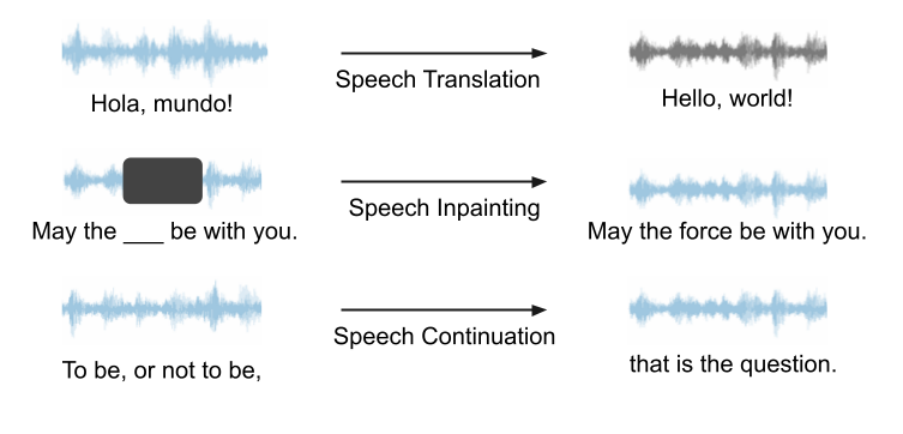
Sprachübersetzung
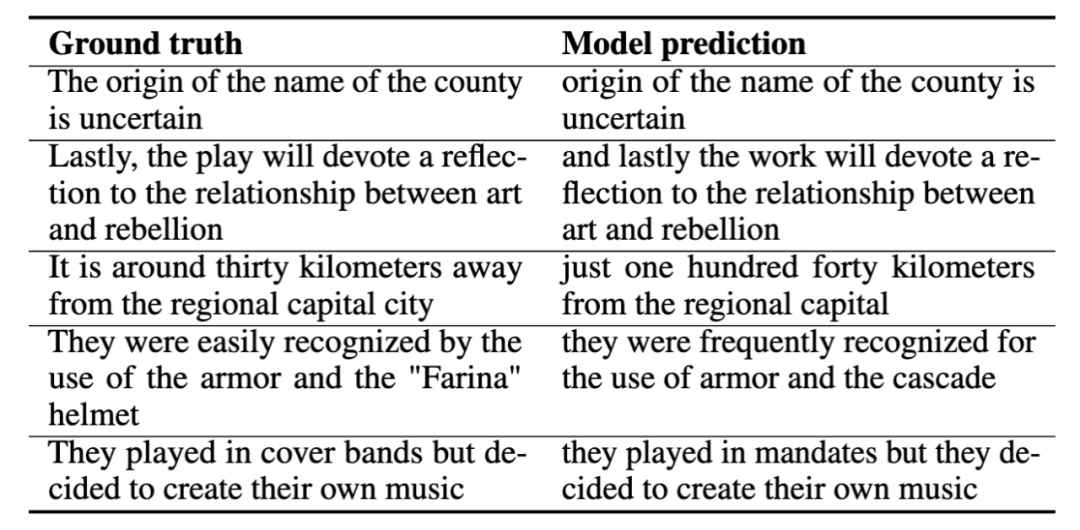
Wenn wir Sprachübersetzung (Sprachübersetzung) trainieren, verwenden wir die Aufgabe, Spanisch ins Englische umzuwandeln. Wir geben spanische Sprache in das Modell ein und hoffen, dass das Modell im gesamten Prozess englische Sprache ohne die Hilfe von Text erzeugt. Nachfolgend finden Sie einige Beispiele für Sprachübersetzungen, in denen wir die richtige Antwort (Ground Truth) und die Modellvorhersage (Model Prediction) zeigen. Diese Demonstrationsbeispiele zeigen, dass die Vorhersagen des Modells die Kernbedeutung der richtigen Antwort erfassen.
Sprach-Inpainting
In unseren Experimenten zum Sprach-Inpainting haben wir speziell Audioclips mit einer Länge von mehr als 2,5 Sekunden als Zielsprache für die anschließende Verarbeitung ausgewählt und durch einen zufälligen Auswahlprozess ein Segment ausgewählt. Sprachclips zwischen 0,8 und 0,8 Sekunden und 1,2 Sekunden lang. Anschließend maskieren wir die ausgewählten Segmente, um fehlende oder beschädigte Teile in einer Sprach-Inpainting-Aufgabe zu simulieren. Wir haben die Wortfehlerrate (WER) und die Zeichenfehlerrate (CER) als Messgrößen verwendet, um den Reparaturgrad beschädigter Segmente zu beurteilen.
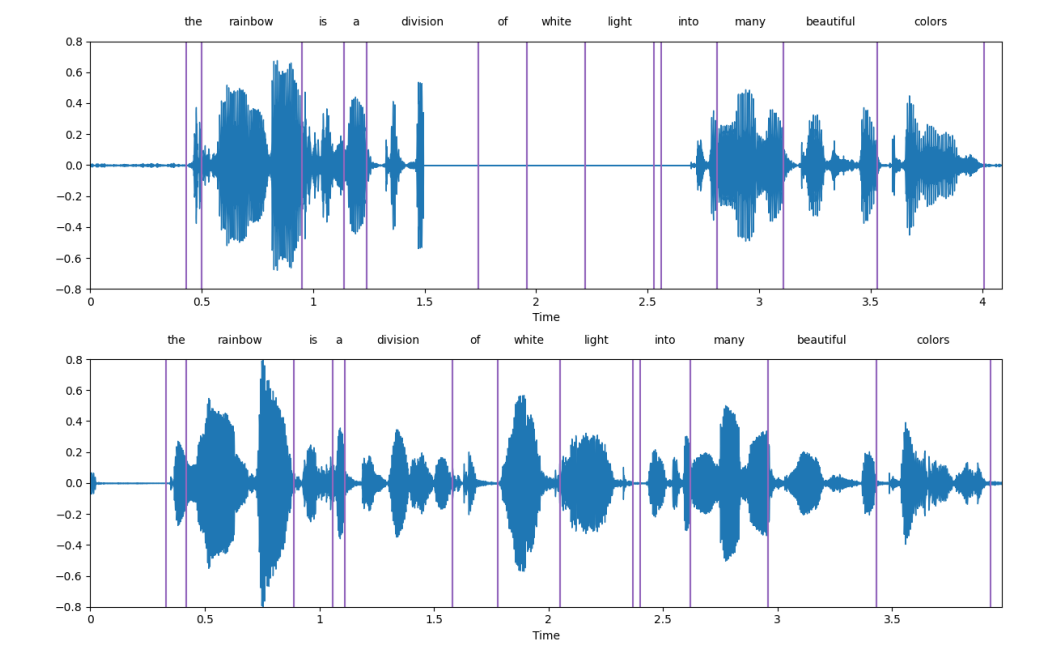
Vergleichende Analyse der von SpeechGen erzeugten Ausgabe und beschädigter Sprache. Unser Modell kann das gesprochene Vokabular erheblich rekonstruieren und WER von 41,68 % auf 28,61 % und CER von 25,10 % auf 10,75 % reduzieren, wie in der Tabelle unten gezeigt. Dies bedeutet, dass unsere vorgeschlagene Methode die Fähigkeit zur Sprachrekonstruktion erheblich verbessern und letztendlich die Genauigkeit und Verständlichkeit der Sprachausgabe fördern kann.

Das obere Unterbild ist die beschädigte Sprache und das untere Unterbild ist die von SpeechGen erzeugte Sprache sehr gut.
Sprachkontinuität
Wir demonstrieren die praktische Anwendung von Sprachfortsetzungsaufgaben durch LJSpeech. Während der Trainingsaufforderung (Eingabeaufforderung) besteht unsere Strategie darin, das Modell nur das Startsegment des Segments sehen zu lassen. Dieses Startsegment nimmt einen Teil der Gesamtlänge der Rede ein. Wir nennen dies das Bedingungsverhältnis (r). Das Modell generiert weiterhin nachfolgende Sprache.
Das Folgende sind einige Beispiele. Der schwarze Text stellt das Startsegment dar, und der rote Text ist der von SpeechGen generierte Satz (der Text wird hier zuerst durch Spracherkennung erhalten). Während des Trainings- und Inferenzprozesses ist das Modell vollständig verarbeitet wird, ist eine Speech-to-Speech-Aufgabe und erhält keinerlei Textinformationen). Verschiedene Bedingungsverhältnisse ermöglichen es SpeechGen, Sätze unterschiedlicher Länge zu generieren, um Kohärenz zu erreichen und einen vollständigen Satz zu vervollständigen. Aus qualitativer Sicht stimmen die generierten Sätze grundsätzlich syntaktisch mit den Seed-Fragmenten überein und sind semantisch verwandt. Allerdings kann die erzeugte Sprache immer noch keine vollständige Bedeutung vermitteln. Wir gehen davon aus, dass dieses Problem in Zukunft in leistungsfähigeren Sprachmodellen behoben wird.
Mängel und zukünftige Richtungen
Sprachmodelle und Sprachgenerierung boomen, und unser Framework bietet die Möglichkeit, leistungsstarke Sprachmodelle für die Sprachgenerierung geschickt zu nutzen. Dieses Rahmenwerk bietet jedoch noch Raum für Verbesserungen und es gibt viele Aspekte, die einer weiteren Untersuchung wert sind.
1. Im Vergleich zu textbasierten Sprachmodellen befinden sich Sprachsprachmodelle noch im Anfangsstadium der Entwicklung. Obwohl das von uns vorgeschlagene Aufforderungsframework das Sprachmodell dazu inspirieren kann, Aufgaben zur Sprachgenerierung auszuführen, kann es keine hervorragende Leistung erzielen. Mit der kontinuierlichen Weiterentwicklung von Sprachmodellen, beispielsweise der großen Wende von GSLM zu Unit mBART, hat sich die Leistung von Eingabeaufforderungen jedoch erheblich verbessert. Insbesondere Aufgaben, die für GSLM bisher eine Herausforderung darstellten, zeigen jetzt unter Unit mBART eine bessere Leistung. Wir gehen davon aus, dass in Zukunft fortschrittlichere Sprachmodelle entstehen werden.
2. Über Inhaltsinformationen hinaus: Aktuelle Sprachmodelle können Sprecher- und emotionale Informationen nicht vollständig erfassen, was die effektiven Verarbeitung dieser Informationen vor Herausforderungen für aktuelle Sprachanregungssysteme stellt. Um diese Einschränkung zu überwinden, führen wir Plug-and-Play-Module ein, die gezielt Sprecher- und Emotionsinformationen in das Framework einspeisen. Für die Zukunft gehen wir davon aus, dass zukünftige Sprachsprachmodelle darüber hinausgehende Informationen integrieren und nutzen werden, um die Leistung zu verbessern und sprecher- und emotionsbezogene Aspekte von Spracherzeugungsaufgaben besser zu bewältigen.
3. Möglichkeit der Prompt-Generierung: Für die Prompt-Generierung verfügen wir über flexible Möglichkeiten und können verschiedene Arten von Anweisungen integrieren, darunter Text- und Bildanweisungen. Stellen Sie sich vor, wir könnten ein neuronales Netzwerk trainieren, Bilder oder Text als Eingabe zu verwenden, anstatt trainierte Einbettungen als Hinweise zu verwenden, wie wir es in diesem Artikel getan haben. Dieses trainierte Netzwerk wird zum Hinweisgenerator und sorgt für Abwechslung im Framework. Dieser Ansatz wird die prompte Generierung interessanter und farbenfroher machen.
Fazit
In diesem Artikel haben wir die Verwendung von Hinweisen untersucht, um die Leistung von Sprachmodellen für eine Vielzahl generativer Aufgaben freizuschalten. Wir schlagen ein einheitliches Framework namens SpeechGen vor, das nur etwa 10 Millionen trainierbare Parameter hat. Unser vorgeschlagenes Framework weist mehrere wichtige Eigenschaften auf, darunter Textfreiheit, Vielseitigkeit, Effizienz, Übertragbarkeit und Erschwinglichkeit. Um die Fähigkeiten des SpeechGen-Frameworks zu demonstrieren, verwenden wir Unit mBART als Fallstudie und führen Experimente zu drei verschiedenen Spracherzeugungsaufgaben durch: Sprachübersetzung, Sprachreparatur und Sprachfortsetzung.
Als dieses Papier bei arXiv eingereicht wurde, schlug Google ein fortgeschritteneres Sprachmodell vor – SPECTRON, das uns die Möglichkeit von Sprachmodellen bei der Modellierung von Informationen wie Sprechern und Emotionen zeigte. Dies sind zweifellos aufregende Neuigkeiten. Da weiterhin fortschrittliche Sprachmodelle vorgeschlagen werden, verfügt unser einheitliches Framework über großes Potenzial.
Das obige ist der detaillierte Inhalt vonPrompt schaltet Funktionen zur Generierung von Sprachmodellen frei und SpeechGen implementiert die Sprachübersetzung und das Patchen mehrerer Aufgaben.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
Die Bewertung des Kosten-/Leistungsverhältnisses des kommerziellen Supports für ein Java-Framework umfasst die folgenden Schritte: Bestimmen Sie das erforderliche Maß an Sicherheit und Service-Level-Agreement-Garantien (SLA). Die Erfahrung und das Fachwissen des Forschungsunterstützungsteams. Erwägen Sie zusätzliche Services wie Upgrades, Fehlerbehebung und Leistungsoptimierung. Wägen Sie die Kosten für die Geschäftsunterstützung gegen Risikominderung und Effizienzsteigerung ab.
 Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Die Lernkurve eines PHP-Frameworks hängt von Sprachkenntnissen, Framework-Komplexität, Dokumentationsqualität und Community-Unterstützung ab. Die Lernkurve von PHP-Frameworks ist im Vergleich zu Python-Frameworks höher und im Vergleich zu Ruby-Frameworks niedriger. Im Vergleich zu Java-Frameworks haben PHP-Frameworks eine moderate Lernkurve, aber eine kürzere Einstiegszeit.
 Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Wie wirken sich die Lightweight-Optionen von PHP-Frameworks auf die Anwendungsleistung aus?
Jun 06, 2024 am 10:53 AM
Das leichte PHP-Framework verbessert die Anwendungsleistung durch geringe Größe und geringen Ressourcenverbrauch. Zu seinen Merkmalen gehören: geringe Größe, schneller Start, geringer Speicherverbrauch, verbesserte Reaktionsgeschwindigkeit und Durchsatz sowie reduzierter Ressourcenverbrauch. Praktischer Fall: SlimFramework erstellt eine REST-API, nur 500 KB, hohe Reaktionsfähigkeit und hoher Durchsatz
 Leistungsvergleich von Java-Frameworks
Jun 04, 2024 pm 03:56 PM
Leistungsvergleich von Java-Frameworks
Jun 04, 2024 pm 03:56 PM
Laut Benchmarks sind Quarkus (schneller Start, geringer Speicher) oder Micronaut (TechEmpower ausgezeichnet) für kleine, leistungsstarke Anwendungen die ideale Wahl. SpringBoot eignet sich für große Full-Stack-Anwendungen, weist jedoch etwas langsamere Startzeiten und Speichernutzung auf.
 Best Practices für die Dokumentation des Golang-Frameworks
Jun 04, 2024 pm 05:00 PM
Best Practices für die Dokumentation des Golang-Frameworks
Jun 04, 2024 pm 05:00 PM
Das Verfassen einer klaren und umfassenden Dokumentation ist für das Golang-Framework von entscheidender Bedeutung. Zu den Best Practices gehört die Befolgung eines etablierten Dokumentationsstils, beispielsweise des Go Coding Style Guide von Google. Verwenden Sie eine klare Organisationsstruktur, einschließlich Überschriften, Unterüberschriften und Listen, und sorgen Sie für eine Navigation. Bietet umfassende und genaue Informationen, einschließlich Leitfäden für den Einstieg, API-Referenzen und Konzepte. Verwenden Sie Codebeispiele, um Konzepte und Verwendung zu veranschaulichen. Halten Sie die Dokumentation auf dem neuesten Stand, verfolgen Sie Änderungen und dokumentieren Sie neue Funktionen. Stellen Sie Support und Community-Ressourcen wie GitHub-Probleme und Foren bereit. Erstellen Sie praktische Beispiele, beispielsweise eine API-Dokumentation.
 So wählen Sie das beste Golang-Framework für verschiedene Anwendungsszenarien aus
Jun 05, 2024 pm 04:05 PM
So wählen Sie das beste Golang-Framework für verschiedene Anwendungsszenarien aus
Jun 05, 2024 pm 04:05 PM
Wählen Sie das beste Go-Framework basierend auf Anwendungsszenarien aus: Berücksichtigen Sie Anwendungstyp, Sprachfunktionen, Leistungsanforderungen und Ökosystem. Gängige Go-Frameworks: Gin (Webanwendung), Echo (Webdienst), Fiber (hoher Durchsatz), gorm (ORM), fasthttp (Geschwindigkeit). Praktischer Fall: Erstellen einer REST-API (Fiber) und Interaktion mit der Datenbank (gorm). Wählen Sie ein Framework: Wählen Sie fasthttp für die Schlüsselleistung, Gin/Echo für flexible Webanwendungen und gorm für die Datenbankinteraktion.
 Detaillierte praktische Erklärung der Golang-Framework-Entwicklung: Fragen und Antworten
Jun 06, 2024 am 10:57 AM
Detaillierte praktische Erklärung der Golang-Framework-Entwicklung: Fragen und Antworten
Jun 06, 2024 am 10:57 AM
Bei der Go-Framework-Entwicklung treten häufige Herausforderungen und deren Lösungen auf: Fehlerbehandlung: Verwenden Sie das Fehlerpaket für die Verwaltung und Middleware zur zentralen Fehlerbehandlung. Authentifizierung und Autorisierung: Integrieren Sie Bibliotheken von Drittanbietern und erstellen Sie benutzerdefinierte Middleware zur Überprüfung von Anmeldeinformationen. Parallelitätsverarbeitung: Verwenden Sie Goroutinen, Mutexe und Kanäle, um den Ressourcenzugriff zu steuern. Unit-Tests: Verwenden Sie Gotest-Pakete, Mocks und Stubs zur Isolierung sowie Code-Coverage-Tools, um die Angemessenheit sicherzustellen. Bereitstellung und Überwachung: Verwenden Sie Docker-Container, um Bereitstellungen zu verpacken, Datensicherungen einzurichten und Leistung und Fehler mit Protokollierungs- und Überwachungstools zu verfolgen.
 Was sind die häufigsten Missverständnisse im Lernprozess des Golang-Frameworks?
Jun 05, 2024 pm 09:59 PM
Was sind die häufigsten Missverständnisse im Lernprozess des Golang-Frameworks?
Jun 05, 2024 pm 09:59 PM
Beim Go-Framework-Lernen gibt es fünf Missverständnisse: übermäßiges Vertrauen in das Framework und eingeschränkte Flexibilität. Wenn Sie die Framework-Konventionen nicht befolgen, wird es schwierig, den Code zu warten. Die Verwendung veralteter Bibliotheken kann zu Sicherheits- und Kompatibilitätsproblemen führen. Die übermäßige Verwendung von Paketen verschleiert die Codestruktur. Das Ignorieren der Fehlerbehandlung führt zu unerwartetem Verhalten und Abstürzen.
