
 Datenbank
MySQL-Tutorial
MySQL-Clusterverwaltung: So verwalten Sie die verteilte Bereitstellung mehrerer Maschinen effizient
Datenbank
MySQL-Tutorial
MySQL-Clusterverwaltung: So verwalten Sie die verteilte Bereitstellung mehrerer Maschinen effizient
MySQL-Clusterverwaltung: So verwalten Sie die verteilte Bereitstellung mehrerer Maschinen effizient

Als eine der derzeit beliebtesten relationalen Open-Source-Datenbanken spielt MySQL eine sehr wichtige Rolle in Unternehmensanwendungen. Es verfügt nicht nur über ein breites Anwendungsspektrum, sondern verfügt auch über eine starke Skalierbarkeit, was bedeutet, dass wir MySQL problemlos verwenden können zum Aufbau von High-End-Datenbanken.
Gleichzeitig bringt es jedoch auch einige Verwaltungsherausforderungen mit sich, z. B. wie kann der MySQL-Cluster besser verwaltet werden, um seine Stabilität und Zuverlässigkeit sicherzustellen? Wie kann die Datenkonsistenz sichergestellt werden, wenn MySQL auf mehreren Servern bereitgestellt wird? Dies sind alles Probleme, die bei der MySQL-Clusterverwaltung berücksichtigt werden müssen.
Wie kann man MySQL-Cluster effizient verwalten? In diesem Artikel stellen wir die Verwaltungsmethode des MySQL-Clusters unter den Aspekten Datenbankreplikation, Multi-Master-Replikation, Partitionierung usw. vor.
1. Datenbankreplikation
Im MySQL-Cluster ist die Datenbankreplikation die grundlegendste Verwaltungsmethode. Unter Datenbankreplikation versteht man das Kopieren von Datenbankdaten von einem Server auf einen anderen Server, sodass die Daten zwischen den beiden Servern synchronisiert bleiben. Diese Methode eignet sich für Systeme mit geringen Anforderungen an hohe Zuverlässigkeit und Fehlertoleranz.
Konkret basiert die Datenbankreplikation von MySQL auf Binärprotokollen. Der Master-Server zeichnet Daten und Änderungen in einer binären Protokolldatei auf, und der Slave-Server repliziert Daten, indem er die binäre Protokolldatei des Master-Servers liest.
2. Multi-Master-Replikation
Die Einschränkung der Datenbankreplikation besteht darin, dass bei einem Ausfall des Master-Servers das gesamte System nicht verfügbar ist. Um die Zuverlässigkeit des MySQL-Clusters zu verbessern, muss daher die Multi-Master-Replikation verwendet werden.
Multi-Master-Replikation bedeutet, dass mehrere MySQL-Server geänderte Daten empfangen und verarbeiten können und diese Server Daten und Änderungen miteinander synchronisieren. Bei einem Ausfall kann das System automatisch auf andere verfügbare Server umschalten, um die Datenverfügbarkeit und -zuverlässigkeit sicherzustellen.
3. Partitionierung
Partitionierung ist eine Technologie, die eine Datenbanktabelle in mehrere kleine Tabellen aufteilt. Mit dieser Methode können Daten auf verschiedenen Servern gespeichert werden, wodurch die Effizienz der Abfrage und Datenverarbeitung verbessert wird. Gleichzeitig kann die Partitionierung auch große Datenbanktabellen in kleinere Tabellen aufteilen, um die Verwaltung und Wartung der Datenbank zu verbessern.
Nach der Partitionierung kann jede Partition Abfrageanforderungen unabhängig verarbeiten, wodurch die Belastung jedes Servers verringert und die Abfrageeffizienz verbessert wird. Darüber hinaus kann die Partitionierung eine bessere Skalierbarkeit bieten und das Hinzufügen oder Entfernen von Servern zum Cluster erleichtern.
Zusammenfassung
MySQL-Cluster-Management ist ein wichtiges Thema, das sich ständig weiterentwickelt und verändert. In diesem Artikel haben wir drei Möglichkeiten zur Verwaltung von MySQL Cluster vorgestellt: Datenbankreplikation, Multi-Master-Replikation und Partitionierung. Mithilfe dieser Technologien können Sie Ihren MySQL-Cluster effizienter verwalten und seine Zuverlässigkeit und Verfügbarkeit verbessern.
Abschließend wird empfohlen, eine geeignete Verwaltungsmethode basierend auf der tatsächlichen Situation in der tatsächlichen Produktionsumgebung auszuwählen, um die Stabilität und Zuverlässigkeit des MySQL-Clusters sicherzustellen.
Das obige ist der detaillierte Inhalt vonMySQL-Clusterverwaltung: So verwalten Sie die verteilte Bereitstellung mehrerer Maschinen effizient. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

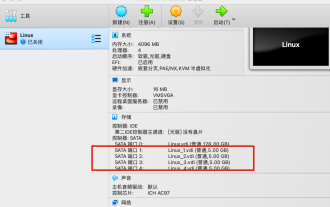 Wie erstellt man 4 virtuelle Festplatten, um einen verteilten MinIO-Cluster unter Linux aufzubauen?
Feb 10, 2024 pm 04:48 PM
Wie erstellt man 4 virtuelle Festplatten, um einen verteilten MinIO-Cluster unter Linux aufzubauen?
Feb 10, 2024 pm 04:48 PM
Da ich seit Kurzem für den Aufbau, die Stabilität, den Betrieb und die Wartung von Objektspeichersystemen verantwortlich bin, muss ich als Neuling im Bereich „Objektspeicher“ mein Wissen in diesem Bereich vertiefen. Da das Unternehmen derzeit MinIO zum Aufbau des Objektspeichersystems des Unternehmens verwendet, werde ich in Zukunft nach und nach meine Lernerfahrungen zu MinIO teilen. Jeder ist herzlich eingeladen, weiterhin darauf zu achten. In diesem Artikel wird hauptsächlich die Einrichtung von MinIO in einer Testumgebung vorgestellt. Dies ist auch der grundlegendste Schritt beim Aufbau einer MinIO-Lernumgebung. 1. Bereiten Sie die experimentelle Umgebung mit der virtuellen Maschine OracleVMVirtualBox vor, installieren Sie eine Mindestversion von Linux und fügen Sie dann 4 virtuelle Festplatten hinzu, die als virtuelle MinIO-Festplatten dienen. Die experimentelle Umgebung ist wie folgt: Als nächstes möchte ich sie Ihnen kurz vorstellen
 Aufbau eines hochverfügbaren MySQL-Clusters: Best-Practice-Leitfaden für Master-Slave-Replikation und Lastausgleich
Sep 09, 2023 am 10:57 AM
Aufbau eines hochverfügbaren MySQL-Clusters: Best-Practice-Leitfaden für Master-Slave-Replikation und Lastausgleich
Sep 09, 2023 am 10:57 AM
Aufbau eines hochverfügbaren MySQL-Clusters: Best-Practice-Leitfaden für Master-Slave-Replikation und Lastausgleich In den letzten Jahren hat sich die Datenbank mit der rasanten Entwicklung des Internets zu einem der zentralen Datenspeicher- und Verarbeitungs-Engines für die meisten Webanwendungen entwickelt. In diesem Szenario sind Hochverfügbarkeit und Lastausgleich zu wichtigen Überlegungen beim Entwurf der Datenbankarchitektur geworden. Als eine der beliebtesten relationalen Open-Source-Datenbanken hat die Cluster-Bereitstellungslösung von MySQL große Aufmerksamkeit auf sich gezogen. In diesem Artikel wird erläutert, wie Sie einen hochverfügbaren Datenbankcluster durch MySQL-Master-Slave-Replikation und Lastausgleich implementieren.
 Verwenden Sie das Gin-Framework, um verteilte Bereitstellungs- und Verwaltungsfunktionen zu implementieren
Jun 22, 2023 pm 11:39 PM
Verwenden Sie das Gin-Framework, um verteilte Bereitstellungs- und Verwaltungsfunktionen zu implementieren
Jun 22, 2023 pm 11:39 PM
Mit der Entwicklung und Anwendung des Internets haben verteilte Systeme immer mehr Aufmerksamkeit und Aufmerksamkeit erregt. In verteilten Systemen ist die schnelle Bereitstellung und bequeme Verwaltung zu einer notwendigen Technologie geworden. In diesem Artikel wird erläutert, wie Sie mit dem Gin-Framework die Bereitstellungs- und Verwaltungsfunktionen verteilter Systeme implementieren. 1. Bereitstellung verteilter Systeme Die Bereitstellung verteilter Systeme umfasst hauptsächlich Codebereitstellung, Umgebungsbereitstellung, Konfigurationsverwaltung und Dienstregistrierung. Diese Aspekte werden im Folgenden einzeln vorgestellt. Die Codebereitstellung ist ein wichtiges Glied in einem verteilten System.
 So erstellen Sie einen hochverfügbaren MySQL-Cluster mithilfe einer verteilten Datenbankarchitektur
Aug 02, 2023 pm 04:29 PM
So erstellen Sie einen hochverfügbaren MySQL-Cluster mithilfe einer verteilten Datenbankarchitektur
Aug 02, 2023 pm 04:29 PM
So nutzen Sie eine verteilte Datenbankarchitektur zum Aufbau eines hochverfügbaren MySQL-Clusters. Mit der Entwicklung des Internets wird die Nachfrage nach Hochverfügbarkeit und Skalierbarkeit von Datenbanken immer größer. Die verteilte Datenbankarchitektur ist zu einer der effektivsten Möglichkeiten zur Lösung dieser Anforderungen geworden. In diesem Artikel wird erläutert, wie mithilfe einer verteilten Datenbankarchitektur ein hochverfügbarer MySQL-Cluster erstellt wird, und es werden relevante Codebeispiele bereitgestellt. Erstellen eines MySQL-Master-Slave-Replikationsclusters Die MySQL-Master-Slave-Replikation ist die grundlegende Hochverfügbarkeitslösung von MySQL. Durch Master-Slave-Replikation können Daten sein
 Entmystifizierung der Website-Performance-Optimierung: Beherrschen Sie diese Methoden, um die Geschwindigkeit Ihrer Website zu steigern!
Feb 03, 2024 am 08:00 AM
Entmystifizierung der Website-Performance-Optimierung: Beherrschen Sie diese Methoden, um die Geschwindigkeit Ihrer Website zu steigern!
Feb 03, 2024 am 08:00 AM
Website-Performance-Optimierung enthüllt: Beherrschen Sie diese Methoden, um Ihre Website zum Erfolg zu bringen! Mit der rasanten Entwicklung des Internets sind Websites zu einem wichtigen Kanal für Unternehmenswerbung, Produktpräsentation sowie Kommunikation und Interaktion geworden. Wenn Benutzer jedoch die Website besuchen und die Ladegeschwindigkeit zu langsam und die Reaktionszeit zu lang ist, wird das Benutzererlebnis erheblich beeinträchtigt und kann sogar direkt dazu führen, dass Benutzer die Website verlassen. Daher wird die Optimierung der Website-Performance immer wichtiger. Was ist also Website-Performance-Optimierung? Einfach ausgedrückt besteht die Optimierung der Website-Leistung darin, die Ladegeschwindigkeit der Website durch eine Reihe von Methoden und technischen Mitteln zu verbessern.
 Was Sie bei der Entwicklung von ThinkPHP beachten sollten: Richtige Verwendung verteilter Bereitstellungslösungen
Nov 22, 2023 pm 12:30 PM
Was Sie bei der Entwicklung von ThinkPHP beachten sollten: Richtige Verwendung verteilter Bereitstellungslösungen
Nov 22, 2023 pm 12:30 PM
ThinkPHP ist ein beliebtes PHP-Entwicklungsframework, das einfach zu verwenden, effizient und stabil ist. Daher müssen Sie während des Entwicklungsprozesses auf einige Details achten, insbesondere wenn Sie eine verteilte Bereitstellungslösung verwenden. In diesem Artikel werden einige Probleme erörtert, auf die bei der Entwicklung von ThinkPHP geachtet werden muss, sowie Methoden zur rationellen Verwendung verteilter Bereitstellungslösungen. 1. Verstehen Sie die Grundkonzepte der verteilten Bereitstellung. Unter verteilter Bereitstellung versteht man die Bereitstellung verschiedener Funktionsmodule des Systems auf verschiedenen Servern, um eine höhere Leistung und Verfügbarkeit zu erzielen. In ThinkPHP
 Welche Software ist Redis
Apr 07, 2024 am 10:36 AM
Welche Software ist Redis
Apr 07, 2024 am 10:36 AM
Redis ist eine speicherresidente Schlüsselwertdatenbank mit den folgenden Merkmalen: speicherresidentes Hochgeschwindigkeitslesen und -schreiben; Speicherung von Schlüsselwertpaaren mit eindeutigen Schlüsseln, die einer Vielzahl von Datenstrukturen entsprechen; unterschiedliche Anforderungen; hohe Verfügbarkeit, unterstützt Replikation und verteilte Bereitstellung, Verarbeitung großer Datenmengen und hohe Parallelität.
 So führen Sie eine verteilte Bereitstellung und Clusterverwaltung von Java-Entwicklungsprojekten durch
Nov 02, 2023 am 08:44 AM
So führen Sie eine verteilte Bereitstellung und Clusterverwaltung von Java-Entwicklungsprojekten durch
Nov 02, 2023 am 08:44 AM
So führen Sie die verteilte Bereitstellung und Clusterverwaltung von Java-Entwicklungsprojekten durch. Mit der rasanten Entwicklung des Internets ist die Java-Entwicklung für viele Unternehmen und Entwickler zur bevorzugten Sprache geworden. In großen Anwendungsumgebungen sind verteilte Bereitstellung und Clusterverwaltung zu einem unverzichtbaren Bestandteil von Java-Entwicklungsprojekten geworden. In diesem Artikel wird erläutert, wie die verteilte Bereitstellung und Clusterverwaltung von Java-Entwicklungsprojekten durchgeführt wird, um Entwicklern dabei zu helfen, die Anforderungen an hohe Parallelität und hohe Verfügbarkeit besser zu bewältigen. Zunächst müssen wir verstehen, was verteilte Bereitstellung und Clusterverwaltung sind. Die verteilte Bereitstellung ist eine
