
 Technologie-Peripheriegeräte
KI
Der Roboterhund von Tencent entwickelt sich weiter: Beherrschung autonomer Entscheidungsfähigkeiten durch tiefes Lernen
Technologie-Peripheriegeräte
KI
Der Roboterhund von Tencent entwickelt sich weiter: Beherrschung autonomer Entscheidungsfähigkeiten durch tiefes Lernen
Der Roboterhund von Tencent entwickelt sich weiter: Beherrschung autonomer Entscheidungsfähigkeiten durch tiefes Lernen

Am 14. Juni wurde Tencent Robotics erheblich verbessert.
Roboterhunde so flexibel und stabil wie Menschen und Tiere zu machen, war ein langfristiges Ziel im Bereich der Robotikforschung. Die kontinuierliche Weiterentwicklung der Deep-Learning-Technologie ermöglicht es Maschinen, relevante Fähigkeiten durch „Lernen“ zu beherrschen und zu lernen, mit komplexen und komplexen Situationen umzugehen veränderliche Umgebungen werden machbar.
Einführung vor dem Training und Verstärkungslernen: Den Roboterhund agiler machen
Tencent Robotics Sie müssen nicht neu lernen, aber Sie können das bereits erlernte mehrstufige Wissen über Körperhaltung, Umweltwahrnehmung und strategische Planung wiederverwenden und aus einem Beispiel Rückschlüsse ziehen, um flexibel mit komplexen Umgebungen umzugehen


Diese Lernreihe ist in drei Phasen unterteilt:
In der ersten Phase sammelte der Forscher mithilfe des Bewegungserfassungssystems, das häufig in der Spieletechnologie verwendet wird, die Bewegungshaltungsdaten echter Hunde, einschließlich Gehen, Laufen, Springen, Stehen und anderer Aktionen, und nutzte diese Daten, um eine Nachahmungslernaufgabe zu erstellen im Simulator, und dann werden die Informationen in diesen Daten abstrahiert und in tiefe neuronale Netzwerkmodelle komprimiert. Diese Modelle können nicht nur die gesammelten Informationen zur Tierbewegungshaltung genau abdecken, sondern weisen auch eine hohe Interpretierbarkeit auf.
Tencent Robotics Diese Technologien und Daten spielen eine gewisse Hilfsrolle bei der auf physikalischen Simulationen basierenden Agentenschulung und der Umsetzung realer Roboterstrategien.
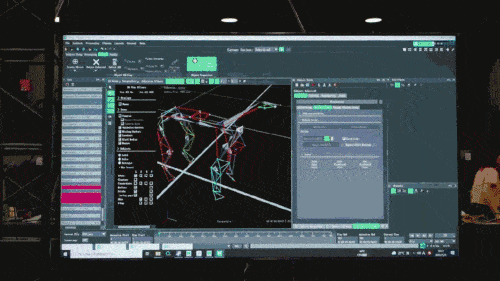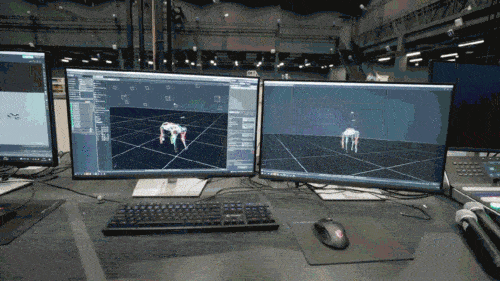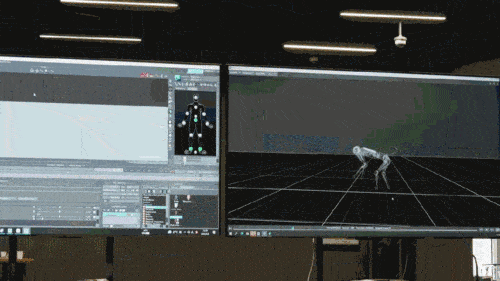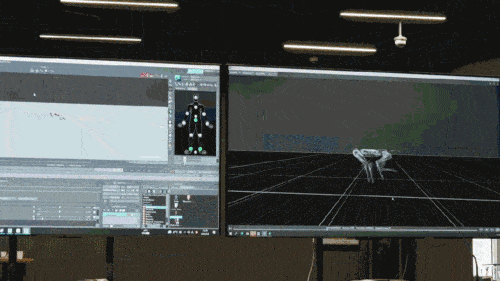
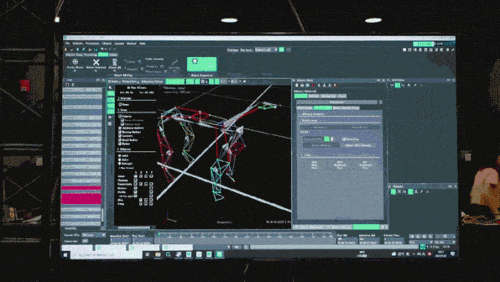

Das neuronale Netzwerkmodell akzeptiert nur die propriozeptiven Informationen des Roboterhundes (z. B. den motorischen Status) als Eingabe und wird auf eine imitierende Lernweise trainiert. Im nächsten Schritt bezieht das Modell sensorische Daten aus der Umgebung ein, beispielsweise durch die Verwendung anderer Sensoren zur Erkennung von Hindernissen unter den Füßen.
In der zweiten Stufe werden zusätzliche Netzwerkparameter verwendet, um die in der ersten Stufe erlernte intelligente Haltung des Roboterhundes mit der Außenwahrnehmung zu verbinden, sodass der Roboterhund durch die erlernte intelligente Haltung auf die äußere Umgebung reagieren kann. Wenn sich der Roboterhund an eine Vielzahl komplexer Umgebungen anpasst, wird auch das Wissen, das intelligente Körperhaltungen mit der Außenwahrnehmung verknüpft, gefestigt und in der neuronalen Netzwerkstruktur gespeichert.



In der dritten Stufe verfügt der Roboterhund unter Verwendung des in den beiden oben genannten Vortrainingsstufen erhaltenen neuronalen Netzwerks über die Voraussetzungen und die Möglichkeit, sich auf die Lösung des politischen Lernproblems der obersten Ebene zu konzentrieren, und verfügt schließlich über die Fähigkeit, komplexe Aufgaben zu lösen -zu Ende. In der dritten Phase werden weitere Netzwerke hinzugefügt, um Daten im Zusammenhang mit komplexen Aufgaben zu sammeln, beispielsweise um Informationen über Gegner und Flaggen im Spiel zu erhalten. Darüber hinaus lernt das für das Strategielernen verantwortliche neuronale Netzwerk durch eine umfassende Analyse aller Informationen übergeordnete Strategien für die Aufgabe, z. B. die Richtung, in die es laufen soll, das Vorhersagen des Verhaltens des Gegners, um zu entscheiden, ob die Verfolgung fortgesetzt werden soll usw.
Das in jeder der oben genannten Stufen erlernte Wissen kann ohne erneutes Lernen erweitert und angepasst werden, sodass es kontinuierlich angesammelt und kontinuierlich erlernt werden kann.
Robot Dog Obstacle Chase-Wettbewerb: Besitz autonomer Entscheidungs- und Kontrollfähigkeiten
Um diese von Max erworbenen neuen Fähigkeiten zu testen, ließ sich der Forscher vom Hindernisjagdspiel „World Chase Tag“ inspirieren und entwarf ein Hindernisjagdspiel für zwei Hunde. World Chase Tag ist eine 2014 im Vereinigten Königreich gegründete Wettbewerbsorganisation zur Hindernisjagd. Sie basiert auf beliebten Verfolgungsspielen für Kinder. Im Allgemeinen treten in jeder Runde des Hindernisjagd-Wettbewerbs zwei Athleten gegeneinander an. Einer ist der Verfolger (genannt Angreifer) und der andere ist der Ausweichmanöver (genannt Verteidiger). einen Punkt, wenn sie ihrem Gegner während der Verfolgungsrunde (d. h. 20 Sekunden) erfolgreich ausweichen (d. h. es kommt zu keinem Kontakt). Das Team, das in der vorgegebenen Anzahl an Verfolgungsrunden die meisten Punkte erzielt, gewinnt das Spiel.
Die Größe des Veranstaltungsortes für den Roboterhund-Hindernisjagd-Wettbewerb beträgt 4,5 x 4,5 Meter, wobei einige Hindernisse darauf verstreut sind. Zu Beginn des Spiels werden zwei MAX-Roboterhunde an zufälligen Orten auf dem Feld platziert, und einem Roboterhund wird zufällig die Rolle eines Verfolgers und dem anderen die eines Ausreißers zugewiesen. Gleichzeitig wird eine Flagge platziert an einer zufälligen Stelle im Feld.
Das Ziel des Dodgers ist es, so nah wie möglich an die Flagge heranzukommen, ohne vom Verfolger erwischt zu werden. Die Aufgabe des Verfolgers besteht darin, den Ausreißer zu fangen. Wenn es dem Dodger gelingt, die Flagge zu berühren, bevor er gefangen wird, wechseln die Rollen der beiden Roboterhunde sofort und die Flagge erscheint an einer anderen zufälligen Stelle wieder. Das Spiel endet, wenn der Ausweichmanöver vom aktuellen Verfolger gefangen wird und der Roboterhund, der die Rolle des Verfolgers spielt, gewinnt. In allen Spielen ist die durchschnittliche Vorwärtsgeschwindigkeit der beiden Roboterhunde auf 0,5 m/s begrenzt.
Aus diesem Spiel, das auf dem vorab trainierten Modell basiert, verfügt der Roboterhund durch tiefes Verstärkungslernen bereits über bestimmte Denk- und Entscheidungsfähigkeiten:
Wenn der Verfolger beispielsweise merkt, dass er den Ausweichmanöver nicht mehr einholen kann, bevor er die Flagge berührt, gibt er die Verfolgung auf und entfernt sich stattdessen vom Ausweichmanöver, um auf das nächste Zurücksetzen zu warten. Die Flagge erscheint .
Außerdem springt der Verfolger, wenn er im letzten Moment dabei ist, den Ausweichenden zu fangen, gerne auf und führt eine „Sprung“-Aktion auf den Ausweichenden aus, was dem Verhalten von Tieren beim Beutefang sehr ähnlich ist Wenn der Dodger dabei ist, die Flagge zu berühren, zeigt er das gleiche Verhalten. Dies alles sind proaktive Beschleunigungsmaßnahmen, die der Roboterhund ergreift, um seinen Sieg zu sichern.
Berichten zufolge handelt es sich bei allen Kontrollstrategien der Roboterhunde im Spiel um neuronale Netzwerkstrategien. Sie werden in Simulationen und durch Zero-Shot-Transfer (Zero-Adjustment-Transfer) erlernt, wodurch das neuronale Netzwerk menschliche Denkmethoden simulieren kann Entdecken Sie Dinge, die noch nie zuvor gesehen wurden, und wenden Sie dieses Wissen an echte Roboterhunde an. Wie in der folgenden Abbildung gezeigt, wird beispielsweise das Wissen über das Vermeiden von Hindernissen, das der Roboterhund im Vortrainingsmodell gelernt hat, im Spiel verwendet, auch wenn die Szenen mit Hindernissen nicht in der virtuellen Welt von Chase Tag Game trainiert werden ( (nur in der virtuellen Welt) Nach dem Training in Spielszenen auf ebenem Boden kann der Roboterhund die Aufgabe auch erfolgreich lösen.
Tencent Robotics Die Einführung im Roboterbereich verbessert die Steuerungsfähigkeiten von Robotern und macht sie flexibler. Dies schafft auch eine solide Grundlage dafür, dass Roboter in das wirkliche Leben eintreten und Menschen dienen können.
Das obige ist der detaillierte Inhalt vonDer Roboterhund von Tencent entwickelt sich weiter: Beherrschung autonomer Entscheidungsfähigkeiten durch tiefes Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
In der heutigen Welle rasanter technologischer Veränderungen sind künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) wie helle Sterne und führen die neue Welle der Informationstechnologie an. Diese drei Wörter tauchen häufig in verschiedenen hochaktuellen Diskussionen und praktischen Anwendungen auf, aber für viele Entdecker, die neu auf diesem Gebiet sind, sind ihre spezifische Bedeutung und ihre internen Zusammenhänge möglicherweise noch immer rätselhaft. Schauen wir uns also zunächst dieses Bild an. Es ist ersichtlich, dass zwischen Deep Learning, maschinellem Lernen und künstlicher Intelligenz ein enger Zusammenhang und eine fortschreitende Beziehung besteht. Deep Learning ist ein spezifischer Bereich des maschinellen Lernens und des maschinellen Lernens
 Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Fast 20 Jahre sind vergangen, seit das Konzept des Deep Learning im Jahr 2006 vorgeschlagen wurde. Deep Learning hat als Revolution auf dem Gebiet der künstlichen Intelligenz viele einflussreiche Algorithmen hervorgebracht. Was sind Ihrer Meinung nach die zehn besten Algorithmen für Deep Learning? Im Folgenden sind meiner Meinung nach die besten Algorithmen für Deep Learning aufgeführt. Sie alle nehmen hinsichtlich Innovation, Anwendungswert und Einfluss eine wichtige Position ein. 1. Hintergrund des Deep Neural Network (DNN): Deep Neural Network (DNN), auch Multi-Layer-Perceptron genannt, ist der am weitesten verbreitete Deep-Learning-Algorithmus. Als er erstmals erfunden wurde, wurde er aufgrund des Engpasses bei der Rechenleistung in Frage gestellt Jahre, Rechenleistung, Der Durchbruch kam mit der Datenexplosion. DNN ist ein neuronales Netzwerkmodell, das mehrere verborgene Schichten enthält. In diesem Modell übergibt jede Schicht Eingaben an die nächste Schicht und
 Der Speicheroptimierungsfortschritt der Tencent QQ NT-Architekturversion wurde angekündigt, Chat-Szenen werden innerhalb von 300 MB gesteuert
Mar 05, 2024 pm 03:52 PM
Der Speicheroptimierungsfortschritt der Tencent QQ NT-Architekturversion wurde angekündigt, Chat-Szenen werden innerhalb von 300 MB gesteuert
Mar 05, 2024 pm 03:52 PM
Es wird davon ausgegangen, dass der Tencent QQ-Desktop-Client einer Reihe drastischer Reformen unterzogen wurde. Als Reaktion auf Benutzerprobleme wie hohe Speichernutzung, übergroße Installationspakete und langsamer Start hat das QQ-Technikteam spezielle Optimierungen am Speicher vorgenommen und schrittweise Fortschritte erzielt. Kürzlich hat das QQ-Technikteam einen Einführungsartikel zur InfoQ-Plattform veröffentlicht, in dem es über die schrittweisen Fortschritte bei der speziellen Speicheroptimierung berichtet. Berichten zufolge spiegeln sich die Speicherherausforderungen der neuen Version von QQ hauptsächlich in den folgenden vier Aspekten wider: Produktform: Es besteht aus einem komplexen großen Panel (über 100 Module unterschiedlicher Komplexität) und einer Reihe unabhängiger Funktionsfenster. Es besteht eine Eins-zu-eins-Entsprechung zwischen Fenstern und Renderprozessen. Die Anzahl der Fensterprozesse hat großen Einfluss auf die Speichernutzung von Electron. Für dieses komplexe große Panel gibt es einmal keine
 Tencent Photon H Studio sucht in Hangzhou nach Mitarbeitern und plant die Entwicklung eines 3A-Open-World-Rollenspiels
Feb 05, 2024 pm 01:45 PM
Tencent Photon H Studio sucht in Hangzhou nach Mitarbeitern und plant die Entwicklung eines 3A-Open-World-Rollenspiels
Feb 05, 2024 pm 01:45 PM
Kürzlich veröffentlichte Tencent Interactive Entertainment Recruitment eine Rekrutierungsinformation, aus der hervorgeht, dass sich Photon H Studio der Entwicklung eines inhaltsreichen Open-World-RPG-Projekts auf AAA-Niveau verschrieben hat. Die begehrten Stellen decken mehrere Bereiche ab, wie z. B. UE5-Ingenieure, Backend, Level-Design, Action-Szenen-Design, Charaktermodellierung, Spezialeffekte und Vertrieb. Der angestrebte Arbeitsort dieser Positionen ist Hangzhou, wo NetEase seinen Hauptsitz hat.
 AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
Herausgeber | Rettichhaut Seit der Veröffentlichung des leistungsstarken AlphaFold2 im Jahr 2021 verwenden Wissenschaftler Modelle zur Proteinstrukturvorhersage, um verschiedene Proteinstrukturen innerhalb von Zellen zu kartieren, Medikamente zu entdecken und eine „kosmische Karte“ jeder bekannten Proteininteraktion zu zeichnen. Gerade hat Google DeepMind das AlphaFold3-Modell veröffentlicht, das gemeinsame Strukturvorhersagen für Komplexe wie Proteine, Nukleinsäuren, kleine Moleküle, Ionen und modifizierte Reste durchführen kann. Die Genauigkeit von AlphaFold3 wurde im Vergleich zu vielen dedizierten Tools in der Vergangenheit (Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion, Antikörper-Antigen-Vorhersage) deutlich verbessert. Dies zeigt, dass dies innerhalb eines einzigen einheitlichen Deep-Learning-Frameworks möglich ist
 Up-Besitzer haben bereits begonnen, mit Tencents Open-Source-Programm „AniPortrait' herumzuspielen, um Fotos zum Singen und Sprechen zu bringen.
Apr 07, 2024 am 09:01 AM
Up-Besitzer haben bereits begonnen, mit Tencents Open-Source-Programm „AniPortrait' herumzuspielen, um Fotos zum Singen und Sprechen zu bringen.
Apr 07, 2024 am 09:01 AM
AniPortrait-Modelle sind Open Source und können frei gespielt werden. „Ein neues Produktivitätstool für Xiaopozhan Ghost Zone.“ Kürzlich erhielt ein neues von Tencent Open Source veröffentlichtes Projekt eine solche Bewertung auf Twitter. Bei diesem Projekt handelt es sich um AniPortrait, das hochwertige animierte Porträts basierend auf Audio und einem Referenzbild generiert. Werfen wir ohne Umschweife einen Blick auf die Demo, vor der vielleicht ein Anwaltsbrief warnt: Auch Anime-Bilder können leicht sprechen: Bereits wenige Tage nach dem Start erntete das Projekt breites Lob: Die Zahl der GitHub-Stars hat zugenommen 2.800 überschritten. Werfen wir einen Blick auf die Innovationen von AniPortrait. Titel des Papiers: AniPortrait:Audio-DrivenSynthesisof
