
 Technologie-Peripheriegeräte
KI
Ist „Nachahmungslernen' nur ein Klischee? Erklärungsfeinabstimmung + 13 Milliarden Parameter Orca: Argumentationsfähigkeit entspricht ChatGPT
Technologie-Peripheriegeräte
KI
Ist „Nachahmungslernen' nur ein Klischee? Erklärungsfeinabstimmung + 13 Milliarden Parameter Orca: Argumentationsfähigkeit entspricht ChatGPT
Ist „Nachahmungslernen' nur ein Klischee? Erklärungsfeinabstimmung + 13 Milliarden Parameter Orca: Argumentationsfähigkeit entspricht ChatGPT

Seit der Eröffnung der ChatGPT-API haben sich viele Studien dafür entschieden, die Ausgabe großer Basismodelle (LFM) wie ChatGPT und GPT-4 als Trainingsdaten zu verwenden und dann die Fähigkeiten kleiner Modelle durch Nachahmungslernen zu verbessern .
Aufgrund von Problemen wie oberflächlichen Nachahmungssignalen, unzureichenden Trainingsdaten und fehlenden strengen Bewertungsstandards wurde die tatsächliche Leistung kleiner Modelle jedoch überschätzt.
Aus Sicht der Wirkung neigt das kleine Modell eher dazu, den Ausgabestil von LFM als den Inferenzprozess zu imitieren.

Link zum Papier: https://arxiv.org/pdf/2306.02707.pdf
Um diese Herausforderungen anzugehen, hat Microsoft kürzlich ein 51-seitiges Papier veröffentlicht, in dem ein 130 The Orca-Modell mit Hunderten vorgeschlagen wird von Millionen von Parametern können lernen, den Argumentationsprozess von LFMs zu imitieren.
Forscher haben umfangreiche Trainingssignale für große Modelle entwickelt, damit Orca Interpretationsspuren, schrittweise Denkprozesse, komplexe Anweisungen usw. von GPT-4 lernen kann und von ChatGPT-Lehrern und durch Stichproben unterstützt und angeleitet wird und Auswahl, um umfangreiche und vielfältige Nachahmungsdaten zu extrahieren, was den inkrementellen Lerneffekt weiter verbessern kann.
In der experimentellen Evaluierung übertraf Orca andere SOTA-Befehlsfeinabstimmungsmodelle und erreichte die doppelte Leistung von Vicuna-13B in komplexen Zero-Shot-Inferenz-Benchmarks wie BigBench Hard (BBH) und erreichte auch bei AGIEval eine Leistung von 42 % Verbesserung.
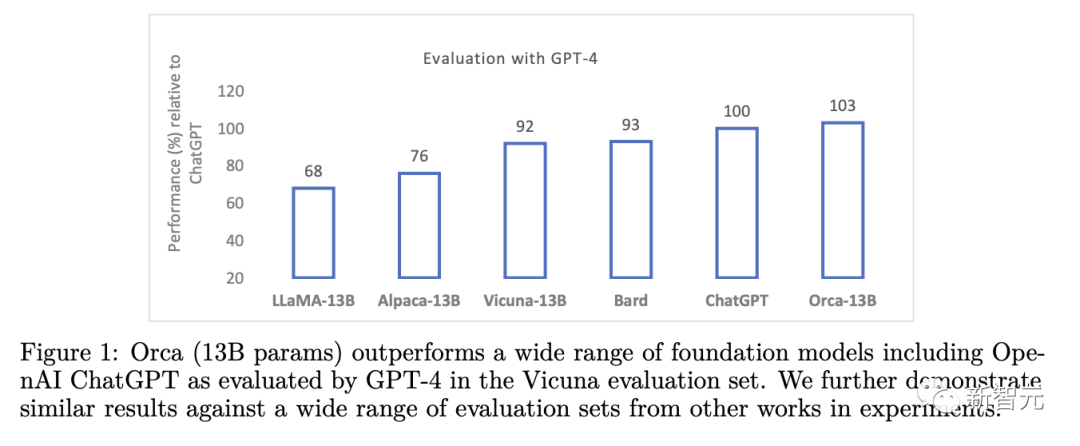
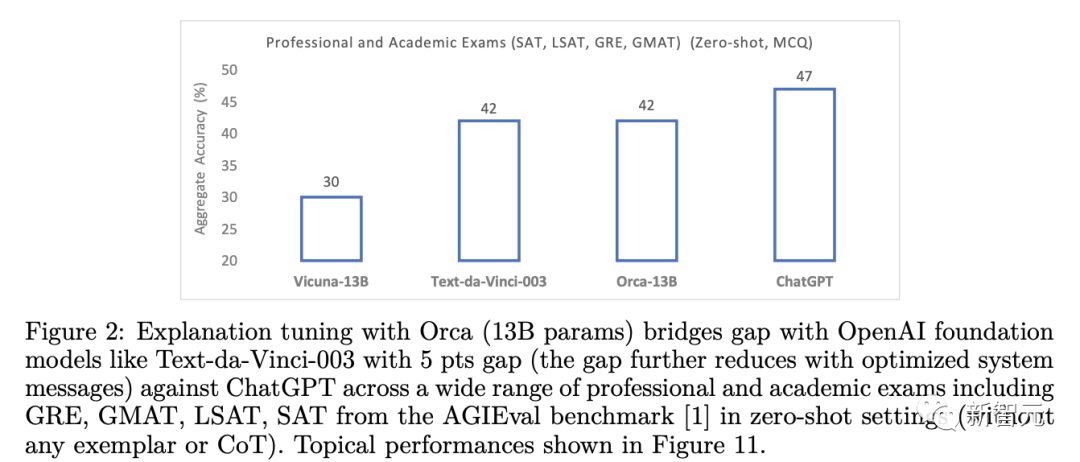
Darüber hinaus erzielte Orca beim BBH-Benchmark eine Leistung auf Augenhöhe mit ChatGPT, mit einem Leistungsunterschied von nur 4 % bei beruflichen und akademischen Prüfungen wie SAT, LSAT, GRE und GMAT, ganz ohne darüber nachzudenken. Gemessen unter dem Null-Sample-Einstellung der Kette.
Die Ergebnisse legen nahe, dass es eine vielversprechende Forschungsrichtung zur Verbesserung der Fähigkeiten und Fertigkeiten von Modellen ist, Modelle aus Schritt-für-Schritt-Erklärungen lernen zu lassen, unabhängig davon, ob sie von Menschen oder fortgeschritteneren KI-Modellen generiert wurden.
Erklärung Tuning
Datensatzkonstruktion
In den Trainingsdaten enthält jede Instanz drei Teile, nämlich Systemnachricht, Benutzerabfrage und LFM-Antwort.
Systemmeldung (Systemmeldung) wird am Anfang der Eingabeaufforderung platziert und stellt LFM grundlegenden Kontext, Anleitungen und andere verwandte Details bereit.
Systemnachrichten können verwendet werden, um die Länge von Antworten zu ändern, die Persönlichkeit des KI-Assistenten zu beschreiben, akzeptables und inakzeptables LFM-Verhalten festzulegen und die Antwortstruktur des KI-Modells zu bestimmen.
Die Forscher haben 16 Systeminformationen von Hand erstellt, um verschiedene Arten von LFM-Antworten zu entwerfen, die kreative Inhalte generieren und Informationsabfrageprobleme lösen können und, was am wichtigsten ist, Antworten mit Erklärungen und schrittweisen Überlegungen generieren können auf Eingabeaufforderungen.

Die Benutzerabfrage definiert die eigentliche Aufgabe, die LFM ausführen soll.
Um eine große Anzahl unterschiedlicher Benutzeranfragen zu erhalten, verwendeten die Forscher die FLAN-v2-Sammlung, um 5 Millionen Benutzeranfragen (FLAN-5M) zu extrahieren, und sammelten dann ChatGPT-Antworten, die dann weiter aus den 5 Millionen Anweisungen extrahiert wurden Millionen Anweisungen (FLAN-1M) und sammeln Antworten von GPT-4.
Die FLAN-v2-Sammlung besteht aus fünf Untersammlungen, nämlich CoT, NiV2, T0, Flan 2021 und Dialogue, wobei jede Teilmenge mehrere Aufgaben enthält und jede Aufgabe eine Sammlung von Abfragen ist.
Jede Untersammlung bezieht sich auf mehrere akademische Datensätze, und jeder Datensatz hat eine oder mehrere Aufgaben, die sich hauptsächlich auf Zero-Shot- und Few-Shot-Abfragen konzentrieren.
In dieser Arbeit haben die Forscher nur die Zero-Shot-Anfragen erfasst, für die Orca trainiert wurde, und nicht die Dialogue-Teilmenge, da diesen Abfragen oft der Kontext fehlt, um nützliche Antworten von ChatGPT zu erhalten.
Lassen Sie ChatGPT als Lehrassistent fungieren
Trainieren Sie Orca zunächst auf FLAN-5M-Daten (ChatGPT-Erweiterung) und führen Sie dann die zweite Trainingsstufe auf FLAN-1M durch (GPT-4-Erweiterung). .
Es gibt zwei Hauptgründe für die Verwendung von ChatGPT als fortgeschrittener Lehrerassistent:
1. Fähigkeitslücke
Obwohl die Parametermenge von GPT-4 nicht bekannt gegeben wurde, beträgt sie 13 Milliarden Parameter Orca ist definitiv Es ist um ein Vielfaches kleiner als GPT-4, und die Leistungslücke zwischen ChatGPT und Orca ist kleiner, was es besser für fortgeschrittene Lehrer geeignet macht, und dieser Ansatz verbessert nachweislich die Nachahmungslernleistung kleinerer Schülermodelle in der Wissensdestillation.
Dieser Ansatz kann auch als eine Form des progressiven Lernens oder Kurslernens angesehen werden, bei dem die Schüler zunächst anhand einfacherer Beispiele lernen und dann zu schwierigeren Beispielen übergehen, in der Annahme, dass längere Antworten besser sind als kürzere Antworten. Schwieriger nachzuahmen, Argumentation und Schritt-für-Schritt-Erklärungsfähigkeiten können durch größere Lehrermodelle verbessert werden. 2. Kosten und Zeit Probleme mit der Dienstlatenz. Die Anzahl der pro Minute verfügbaren Token ist begrenzt und die Kosten für die Token-Vervollständigung sind begrenzt.
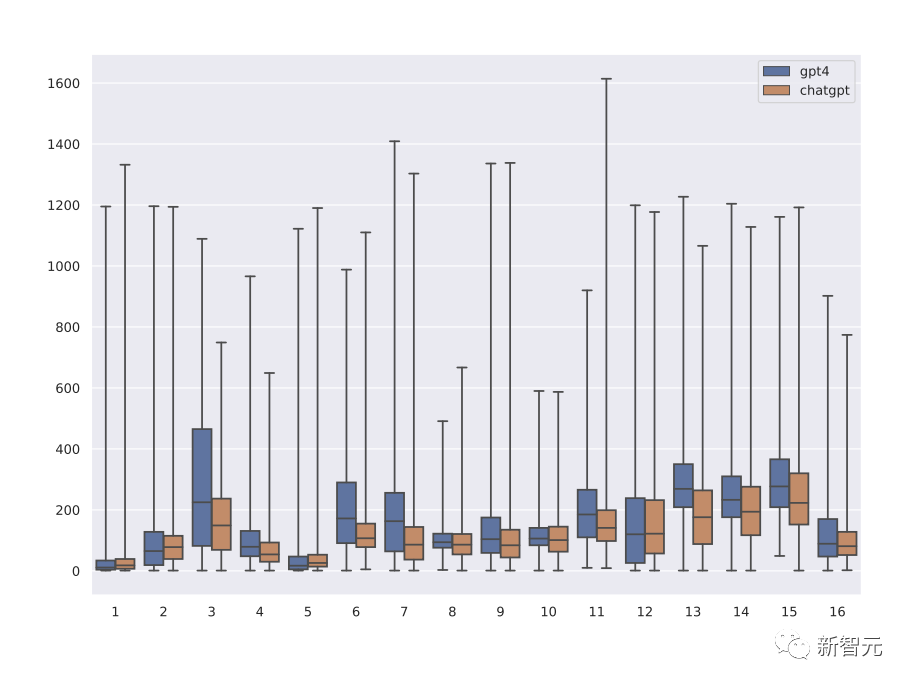
Im Vergleich dazu ist die ChatGPT-API schneller und günstiger als das GPT-4-Terminal, sodass von ChatGPT fünfmal mehr Daten erfasst werden als von GPT-4.
Aus der Verteilung der Antwortlängen von ChatGPT und GPT-4, die verschiedenen Systemnachrichten entsprechen, lässt sich erkennen, dass die Antworten von GPT-4 im Durchschnitt 1,5-mal länger sind als die von ChatGPT, sodass Orca nach und nach aus der Komplexität lernen kann Untersuchung von Erklärungen von Lehrern und Demonstration der Wirkung von Lehrerunterstützung durch Ablationsexperimente.

Training
In der Wortsegmentierungsphase verwendeten die Forscher den Byte Pair Encoding (BPE)-Wortsegmentierer von LLaMA, um die Eingabebeispiele zu verarbeiten, bei denen mehrstellige Zahlen in mehrere einzelne Ziffern aufgeteilt werden . und auf Bytes zurückgreifen, um unbekannte UTF-8-Zeichen zu zerlegen.
Um Sequenzen variabler Länge zu verarbeiten, wird ein Füllwort [[PAD]] in das Vokabular des LLaMA-Tokenizers eingeführt. Das endgültige Vokabular enthält 32001 TokenUm den Trainingsprozess effektiv zu optimieren Mithilfe der verfügbaren Rechenressourcen haben Forscher mithilfe der Packtechnologie mehrere Eingabeinstanzen zu einer Sequenz verkettet, bevor sie das Modell trainierten.
Während des Packvorgangs überschreitet die Gesamtlänge der verketteten Sequenz max_len=2048 Token. Die Eingabeproben werden zufällig gemischt und in mehrere Gruppen aufgeteilt. Die Länge jeder Gruppe verketteter Sequenzen beträgt höchstens max_len
Berücksichtigen Sie die Längenverteilung der erweiterten Anweisungen in den Trainingsdaten. Der Packungskoeffizient jeder Sequenz beträgt 2,7
Um Orca zu trainieren, entschieden sich die Forscher, nur den Verlust der vom Lehrermodell generierten Token zu berechnen Dies bedeutet, dass die Lerngenerierung auf Systeminformationen und Aufgabenanweisungen basiert. Bedingte Antworten stellen sicher, dass sich das Modell auf das Lernen aus den relevantesten und informativsten Token konzentriert und so die Gesamteffizienz und Effektivität des Trainingsprozesses verbessert.
Abschließend wurde Orca auf 20 NVIDIA A100-GPUs mit 80 GB Speicher trainiert. Es wurde zunächst 4 Epochen lang auf FLAN-5M (ChatGPT erweitert) trainiert, was dann 160 Stunden dauerte für 4 Epochen
Aufgrund von Verkehrsbeschränkungen, Terminalauslastung und Problemen mit der Antwortlänge dauerte es 2 Wochen bzw. 3 Wochen, um Daten von mehreren Terminals von GPT-3.5-turbo (ChatGPT) bzw. GPT-4 zu sammeln.
Experimenteller Teil
Die Forscher überprüften hauptsächlich Orcas Denkfähigkeit.
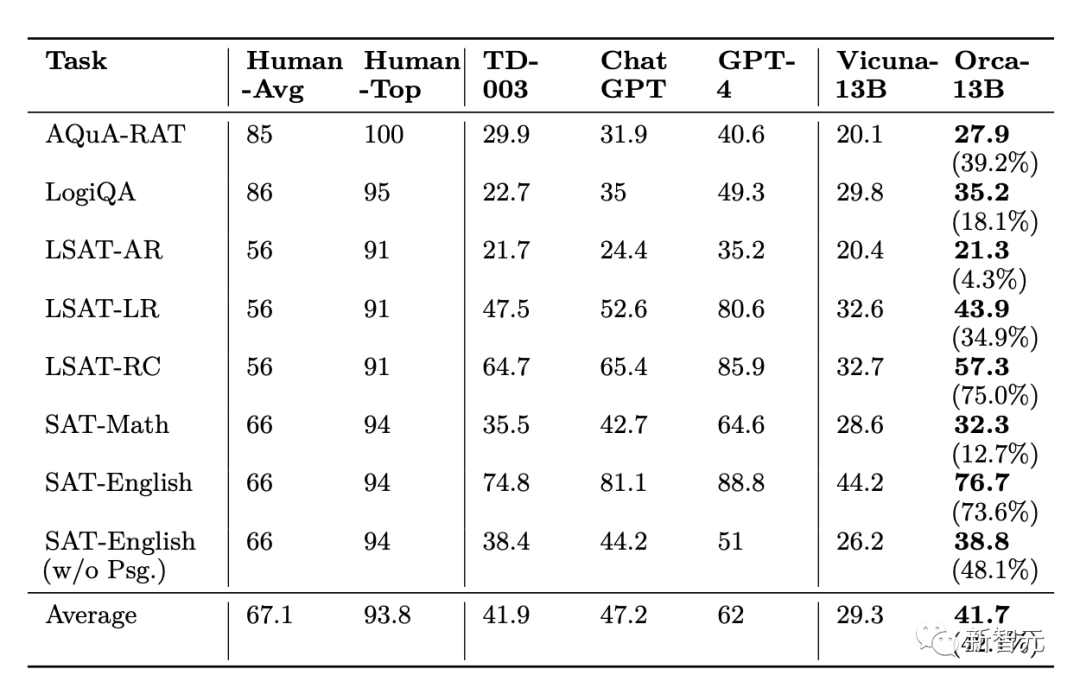
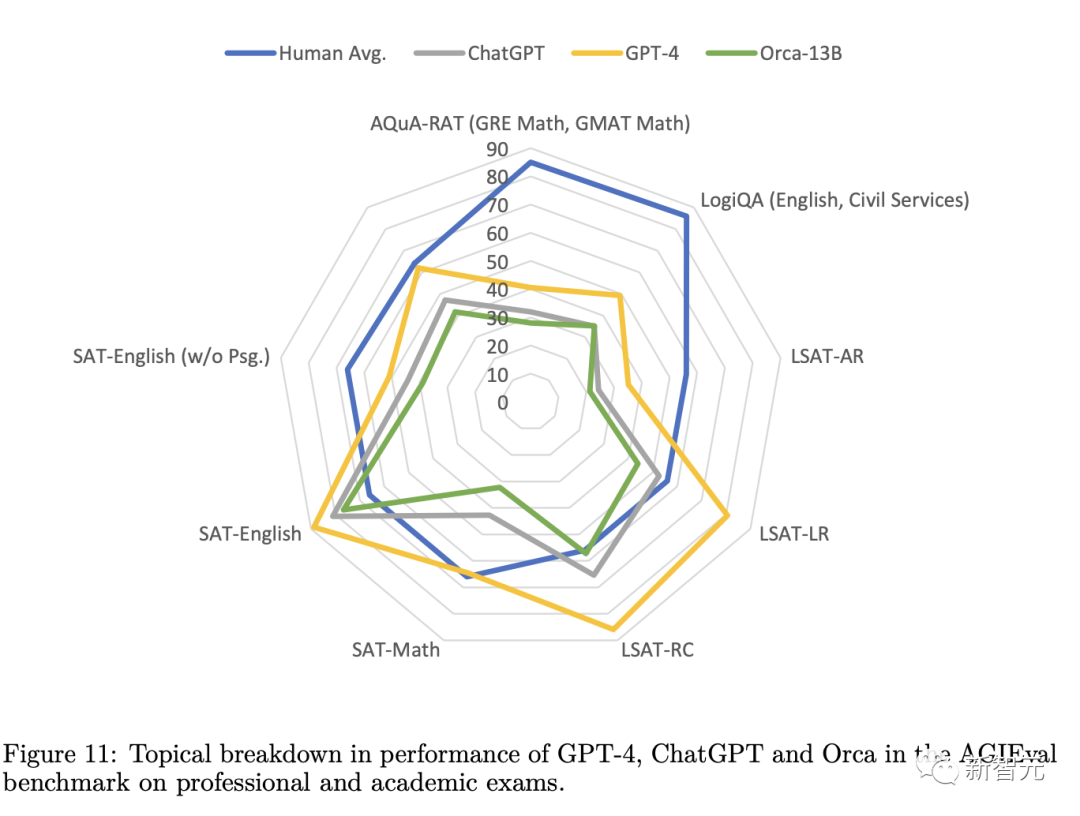
Wie im AGIEval-Experiment zu sehen ist, entspricht die Leistung von Orca der von Text-da-Vinci-003 und erreicht 88 % der Leistung von ChatGPT, liegt aber deutlich hinter GPT-4
Bei Analyse- und Argumentationsaufgaben schnitt Vicuna deutlich schlechter ab und behielt nur 62 % der ChatGPT-Qualität bei, was darauf hindeutet, dass dieses Open-Source-Sprachmodell über schlechte Argumentationsfähigkeiten verfügt.
Während Orca auf Augenhöhe mit Text-da-Vinci-003 abschneidet, liegt es immer noch 5 Punkte unter ChatGPT. Orca schneidet bei mathematischen Aufgaben (in SAT, GRE, GMAT) deutlich besser ab als ChatGPT.
Im Vergleich zu Vicuna zeigt Orca eine stärkere Leistung und übertrifft Vicuna in jeder Kategorie mit einer durchschnittlichen relativen Verbesserung von 42 %.
GPT-4 übertrifft alle anderen Modelle bei weitem, aber es gibt noch viel Raum für Verbesserungen bei diesem Benchmark, da alle Modelle derzeit deutlich unter den menschlichen Werten liegen.
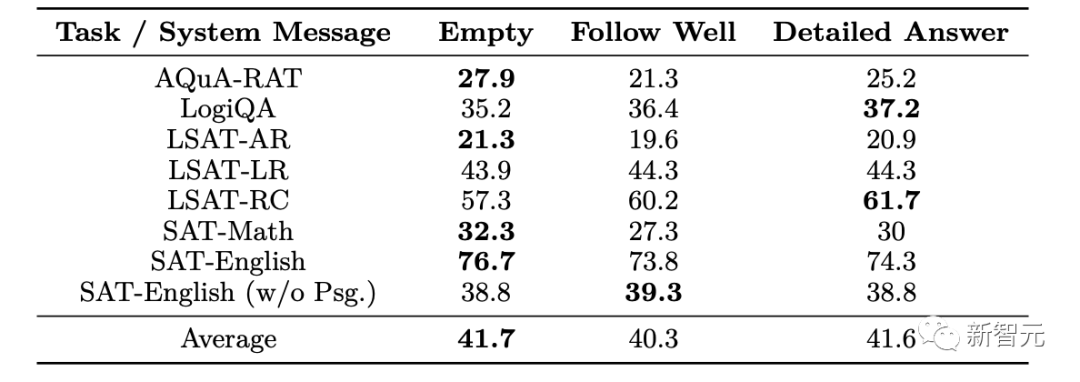
Die Leistung von Orca variiert stark je nach Art der Systemnachrichten, und leere Systemnachrichten funktionieren in der Regel gut für trainierte Modelle.
Orca übertrifft ChatGPT (Orca-beats-ChatGPT-Beispiel) in 325 Beispielen verschiedener Aufgaben, von denen die meisten von LogiQA stammen (29 %), während andere LSAT-Aufgaben und SAT-Englisch-Aufgaben gleichmäßig auf 10 verteilt sind %
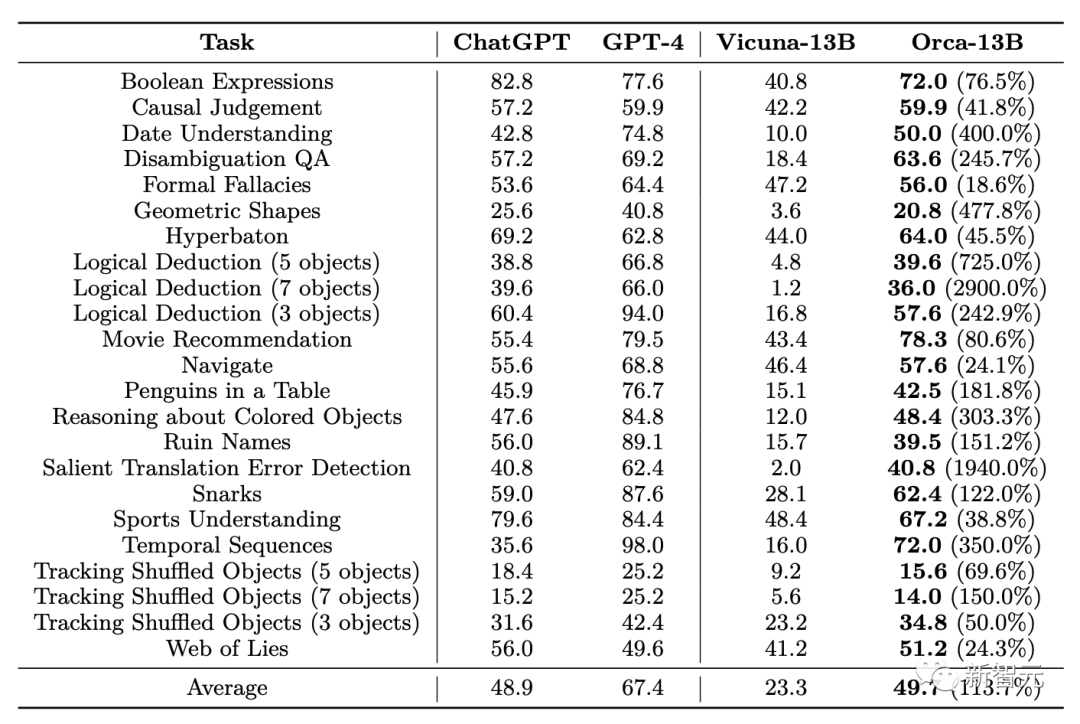
Die Ergebnisse der Inferenzauswertung des Big-Bench Hard Results-Datensatzes zeigen, dass die Gesamtleistung von Orca bei allen Aufgaben etwas besser ist als die von ChatGPT, aber deutlich hinter der Leistung von GPT-4 zurückliegt; %
Das obige ist der detaillierte Inhalt vonIst „Nachahmungslernen' nur ein Klischee? Erklärungsfeinabstimmung + 13 Milliarden Parameter Orca: Argumentationsfähigkeit entspricht ChatGPT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
