

Zwischenspeichern begrenzter Datensätze in der Java-Caching-Technologie

Da die Komplexität moderner Anwendungen immer weiter zunimmt, steigen auch die Anforderungen an Datendurchsatz und Verfügbarkeit. Um diese Probleme zu lösen, wurde nach und nach die Anwendung der Caching-Technologie weit verbreitet.
In der Java-Caching-Technologie ist das Zwischenspeichern begrenzter Datensätze ein besonders häufiges Szenario. Das Zwischenspeichern begrenzter Datensätze bedeutet normalerweise, dass einige Datensätze (z. B. Datenbankabfrage-Ergebnissätze) im Speicher zwischengespeichert werden, um die Geschwindigkeit und Reaktionsfähigkeit des Datenzugriffs zu verbessern, und die Größe des zwischengespeicherten Datensatzes ist auch auf einen bestimmten Bereich begrenzt Ist das Limit erreicht, werden einige zwischengespeicherte Datensätze nach bestimmten Strategien gelöscht, um Platz für neue Datensätze zu schaffen.
Lassen Sie uns besprechen, wie das Caching begrenzter Datensätze in der Java-Caching-Technologie implementiert wird.
- Auswahl der Cache-Datenstruktur
In der Java-Cache-Technologie gibt es zwei Haupt-Cache-Datenstrukturen: Hash-Tabelle und Rot-Schwarz-Baum.
Das Merkmal der Hash-Tabelle besteht darin, die gespeicherten Daten über die Hash-Funktion zu verteilen, um den Zweck zu erreichen, die Daten schnell zu finden und darauf zuzugreifen. Da die Suchgeschwindigkeit der Hash-Tabelle sehr hoch ist, wird sie häufig in Szenarios zum Zwischenspeichern von Datensätzen verwendet.
Im Gegensatz dazu besteht die Eigenschaft des Rot-Schwarz-Baums darin, die Daten kontinuierlich zu sortieren und auszugleichen, um sicherzustellen, dass im schlimmsten Fall eine schnelle Suchgeschwindigkeit aufrechterhalten werden kann. Obwohl der Rot-Schwarz-Baum nicht so schnell ist wie die Hash-Tabelle, weist er eine bessere Universalität und Stabilität auf und ist flexibler in der Verwendung.
Je nach unterschiedlichen Anforderungen können wir eine geeignete Datenstruktur als Speicherstruktur für zwischengespeicherte Daten auswählen. Wenn wir Daten schnell finden müssen, ist es besser, eine Hash-Tabelle zu wählen. Wenn wir die Bereichssuche, Sortierung und andere Vorgänge unterstützen müssen, ist es besser, einen Rot-Schwarz-Baum zu wählen.
- Auswahl der Cache-Strategie
Die Cache-Strategie bezieht sich darauf, wie ein Teil des zwischengespeicherten Datensatzes gelöscht werden soll, nachdem der Cache eine bestimmte Größenbeschränkung erreicht hat, um genügend Platz zum Speichern neuer Daten zu lassen.
Es gibt drei gängige Caching-Strategien: First-In-First-Out (FIFO), LRU (Least-Recent-Used) und LFU (Least-Recent-Used).
- Die First-In-First-Out-Strategie (FIFO) ist eine relativ einfache Strategie, bei der der früheste Datensatz, der zuerst in den Cache gelangt, eliminiert wird. Diese Strategie ist jedoch anfällig für Situationen, in denen neue Dateneinträge alte Dateneinträge überfordern.
- Die am wenigsten kürzlich verwendete Strategie (LRU) ist eine häufig verwendete Strategie. Diese Strategie wählt die am längsten verwendeten Datensätze zur Eliminierung aus. Dadurch wird sichergestellt, dass die Datensätze im Cache häufig verwendet werden und nicht einige selten verwendete Datensätze.
- Die LFU-Strategie (Least Used) ist eine Strategie zur Eliminierung basierend auf der Häufigkeit, mit der ein Datensatz verwendet wird. Diese Strategie wählt die am wenigsten häufig verwendeten Datensätze zur Eliminierung aus. Diese Strategie erfordert normalerweise die Aufzeichnung der Häufigkeit, mit der jeder Datensatz verwendet wird, und ist daher relativ komplex umzusetzen.
Je nach unterschiedlichen Anwendungsszenarien und Anforderungen können Sie eine geeignete Caching-Strategie für die Implementierung auswählen.
- Automatischer Lademechanismus
Wie soll der Datensatz geladen und gespeichert werden, wenn der abzufragende Datensatz nicht im Cache vorhanden ist? Dies erfordert die Implementierung des automatischen Lademechanismus.
Der automatische Lademechanismus kann Datensätze automatisch laden, indem Parameter voreingestellt, asynchron geladen und im Cache gespeichert werden. Wenn der Datensatz das nächste Mal benötigt wird, kann er auf diese Weise direkt aus dem Cache abgerufen werden, um den Datenzugriff zu beschleunigen.
Es ist zu beachten, dass Sie beim automatischen Laden das Gleichgewicht zwischen Ladeparametern und Cache-Größe beherrschen müssen, um zu vermeiden, dass der Datensatz zu stark geladen wird, was zu einer übermäßig großen Cache-Größe führt, oder dass der Datensatz zu wenig geladen wird bei geringer Trefferquote.
- Parallelitätskontrolle
Parallelitätskontrolle ist auch eines der wichtigen Themen in der Caching-Technologie. Wenn mehrere Threads gleichzeitig den Cache betreiben, kann es zu Problemen beim gleichzeitigen Lesen und Schreiben kommen, was zu Dateninkonsistenzen führt.
Um das Parallelitätsproblem zu lösen, können verschiedene Methoden verwendet werden, wie z. B. Sperrmechanismen, CAS-Mechanismen (Compare And Swap) usw.
Der Sperrmechanismus ist eine der gebräuchlichsten Methoden. Sie können Lese-/Schreibsperren, pessimistische Sperren, optimistische Sperren usw. verwenden. Das Merkmal der Lese-/Schreibsperre besteht darin, dass sie das gleichzeitige Lesen unterstützt, das Merkmal der pessimistischen Sperre jedoch darin besteht, dass standardmäßig ein Problem mit der Parallelität vorliegt und das Merkmal der optimistischen Sperre gesperrt werden muss Bei der Sperre wird standardmäßig davon ausgegangen, dass es kein Problem mit der Parallelität gibt. Nicht gesperrt.
Je nach tatsächlicher Parallelitätssituation und Anwendungsszenario können Sie eine geeignete Parallelitätskontrollmethode auswählen, um die Richtigkeit und Verfügbarkeit des Caches sicherzustellen.
Zusammenfassend lässt sich sagen, dass das Zwischenspeichern begrenzter Datensätze in der Java-Caching-Technologie die Berücksichtigung mehrerer Aspekte erfordert, wie z. B. die Auswahl der Cache-Datenstruktur, die Auswahl der Caching-Strategie, den automatischen Lademechanismus und die Parallelitätskontrolle. Nur durch die Einführung einer geeigneten Implementierungsmethode basierend auf den tatsächlichen Anforderungen kann der Cache seine maximale Rolle spielen und die Gesamtleistung und Verfügbarkeit der Anwendung verbessern.
Das obige ist der detaillierte Inhalt vonZwischenspeichern begrenzter Datensätze in der Java-Caching-Technologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Bildklassifizierung mit Fow-Shot-Learning mit PyTorch
Apr 09, 2023 am 10:51 AM
Bildklassifizierung mit Fow-Shot-Learning mit PyTorch
Apr 09, 2023 am 10:51 AM
In den letzten Jahren haben Deep-Learning-basierte Modelle bei Aufgaben wie der Objekterkennung und Bilderkennung gute Leistungen erbracht. Bei anspruchsvollen Bildklassifizierungsdatensätzen wie ImageNet, das 1.000 verschiedene Objektklassifizierungen enthält, übertreffen einige Modelle mittlerweile das menschliche Niveau. Diese Modelle basieren jedoch auf einem überwachten Trainingsprozess, sie werden erheblich von der Verfügbarkeit gekennzeichneter Trainingsdaten beeinflusst und die Klassen, die die Modelle erkennen können, sind auf die Klassen beschränkt, auf denen sie trainiert wurden. Da während des Trainings nicht genügend beschriftete Bilder für alle Klassen vorhanden sind, sind diese Modelle in realen Umgebungen möglicherweise weniger nützlich. Und wir möchten, dass das Modell Klassen erkennen kann, die es während des Trainings nicht gesehen hat, da es fast unmöglich ist, auf Bildern aller potenziellen Objekte zu trainieren. Wir werden aus einigen Beispielen lernen
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Implementierung von OpenAI CLIP für benutzerdefinierte Datensätze
Sep 14, 2023 am 11:57 AM
Implementierung von OpenAI CLIP für benutzerdefinierte Datensätze
Sep 14, 2023 am 11:57 AM
Im Januar 2021 kündigte OpenAI zwei neue Modelle an: DALL-E und CLIP. Bei beiden Modellen handelt es sich um multimodale Modelle, die Text und Bilder auf irgendeine Weise verbinden. Der vollständige Name von CLIP lautet Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), eine Vortrainingsmethode, die auf kontrastierenden Text-Bild-Paaren basiert. Warum CLIP einführen? Denn die derzeit beliebte StableDiffusion ist kein einzelnes Modell, sondern besteht aus mehreren Modellen. Eine der Schlüsselkomponenten ist der Text-Encoder, der zur Codierung der Texteingabe des Benutzers verwendet wird. Dieser Text-Encoder ist der Text-Encoder CL im CLIP-Modell.
 Google AI-Video ist wieder großartig! VideoPrism, ein universeller visueller All-in-One-Encoder, aktualisiert 30 SOTA-Leistungsfunktionen
Feb 26, 2024 am 09:58 AM
Google AI-Video ist wieder großartig! VideoPrism, ein universeller visueller All-in-One-Encoder, aktualisiert 30 SOTA-Leistungsfunktionen
Feb 26, 2024 am 09:58 AM
Nachdem das KI-Videomodell Sora populär wurde, traten große Unternehmen wie Meta und Google zurück, um Forschung zu betreiben und OpenAI nachzuholen. Kürzlich haben Forscher des Google-Teams einen universellen Video-Encoder vorgeschlagen – VideoPrism. Es kann verschiedene Videoverständnisaufgaben über ein einziges eingefrorenes Modell bewältigen. Adresse des Bildpapiers: https://arxiv.org/pdf/2402.13217.pdf VideoPrism kann beispielsweise die Person, die im folgenden Video Kerzen ausbläst, klassifizieren und lokalisieren. Bild-Video-Text-Abruf: Basierend auf dem Textinhalt kann der entsprechende Inhalt im Video abgerufen werden. Beschreiben Sie als weiteres Beispiel das folgende Video: Ein kleines Mädchen spielt mit Bauklötzen. Fragen und Antworten zur Qualitätssicherung sind ebenfalls verfügbar.
 Wie teile ich einen Datensatz richtig auf? Zusammenfassung von drei gängigen Methoden
Apr 08, 2023 pm 06:51 PM
Wie teile ich einen Datensatz richtig auf? Zusammenfassung von drei gängigen Methoden
Apr 08, 2023 pm 06:51 PM
Die Zerlegung des Datensatzes in einen Trainingssatz hilft uns, das Modell zu verstehen, was wichtig für die Verallgemeinerung des Modells auf neue, unsichtbare Daten ist. Ein Modell lässt sich möglicherweise nicht gut auf neue, noch nicht sichtbare Daten verallgemeinern, wenn es überangepasst ist. Daher können keine guten Vorhersagen getroffen werden. Eine geeignete Validierungsstrategie ist der erste Schritt zur erfolgreichen Erstellung guter Vorhersagen und zur Nutzung des Geschäftswerts von KI-Modellen. In diesem Artikel wurden einige gängige Strategien zur Datenaufteilung zusammengestellt. Eine einfache Trainings- und Testaufteilung unterteilt den Datensatz in Trainings- und Validierungsteile, wobei 80 % Training und 20 % Validierung erfolgen. Sie können dies mithilfe der Zufallsstichprobe von Scikit tun. Zunächst muss der Zufallsstartwert festgelegt werden, da sonst die gleiche Datenaufteilung nicht verglichen werden kann und die Ergebnisse beim Debuggen nicht reproduziert werden können. Wenn der Datensatz
 Vollständiges Codebeispiel für das parallele PyTorch-Training DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Vollständiges Codebeispiel für das parallele PyTorch-Training DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Das Problem, große tiefe neuronale Netze (DNN) mithilfe großer Datensätze zu trainieren, ist eine große Herausforderung im Bereich Deep Learning. Mit zunehmender DNN- und Datensatzgröße steigen auch die Rechen- und Speicheranforderungen für das Training dieser Modelle. Dies macht es schwierig oder sogar unmöglich, diese Modelle auf einer einzelnen Maschine mit begrenzten Rechenressourcen zu trainieren. Zu den größten Herausforderungen beim Training großer DNNs mithilfe großer Datensätze gehören: Lange Trainingszeit: Der Trainingsprozess kann je nach Komplexität des Modells und Größe des Datensatzes Wochen oder sogar Monate dauern. Speicherbeschränkungen: Große DNNs benötigen möglicherweise viel Speicher, um alle Modellparameter, Verläufe und Zwischenaktivierungen während des Trainings zu speichern. Dies kann zu Speichermangel führen und die Möglichkeiten des Trainings auf einem einzelnen Computer einschränken.
 Berechnung der CO2-Kosten künstlicher Intelligenz
Apr 12, 2023 am 08:52 AM
Berechnung der CO2-Kosten künstlicher Intelligenz
Apr 12, 2023 am 08:52 AM
Wenn Sie auf der Suche nach interessanten Themen sind, wird Sie Künstliche Intelligenz (KI) nicht enttäuschen. Künstliche Intelligenz umfasst eine Reihe leistungsstarker, umwerfender statistischer Algorithmen, die Schach spielen, schlampige Handschriften entziffern, Sprache verstehen, Satellitenbilder klassifizieren und vieles mehr können. Die Verfügbarkeit riesiger Datensätze zum Trainieren von Modellen für maschinelles Lernen war einer der Schlüsselfaktoren für den Erfolg der künstlichen Intelligenz. Aber all diese Rechenarbeit ist nicht kostenlos. Einige KI-Experten sind zunehmend besorgt über die Umweltauswirkungen, die mit der Entwicklung neuer Algorithmen einhergehen, und die Debatte hat neue Ideen hervorgebracht, wie der CO2-Fußabdruck von KI verringert werden kann, indem Maschinen effizienter lernen. Zurück auf der Erde Um ins Detail zu gehen, müssen wir zunächst die Tausenden von Rechenzentren (über die ganze Welt verstreut) betrachten, die unsere Rechenanfragen rund um die Uhr bearbeiten.
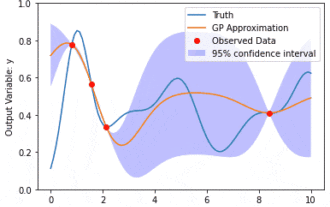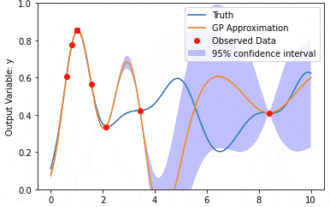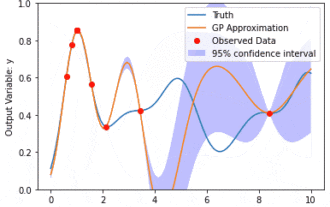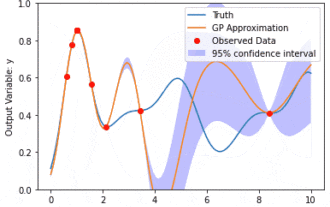 Datenmodellierung mit Kernel Model Gaußian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Datenmodellierung mit Kernel Model Gaußian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Kernel Model Gaussian Processes (KMGPs) sind hochentwickelte Werkzeuge zur Bewältigung der Komplexität verschiedener Datensätze. Es erweitert das Konzept traditioneller Gaußscher Prozesse um Kernelfunktionen. In diesem Artikel werden die theoretischen Grundlagen, praktischen Anwendungen und Herausforderungen von KMGPs ausführlich erörtert. Der Gaußsche Prozess des Kernelmodells ist eine Erweiterung des traditionellen Gaußschen Prozesses und wird beim maschinellen Lernen und in der Statistik verwendet. Bevor Sie kmgp verstehen, müssen Sie die Grundkenntnisse des Gaußschen Prozesses beherrschen und dann die Rolle des Kernelmodells verstehen. Gaußsche Prozesse (GPs) Gaußsche Prozesse sind Sätze von Zufallsvariablen mit einer endlichen Anzahl von Variablen, die durch die Gaußsche Verteilung gemeinsam verteilt werden, und werden zur Definition von Funktionswahrscheinlichkeitsverteilungen verwendet. Gaußsche Prozesse werden häufig bei Regressions- und Klassifizierungsaufgaben beim maschinellen Lernen verwendet und können zur Anpassung der Wahrscheinlichkeitsverteilung von Daten verwendet werden. Ein wichtiges Merkmal von Gaußschen Prozessen ist ihre Fähigkeit, Unsicherheitsschätzungen und -vorhersagen zu liefern
