
 Technologie-Peripheriegeräte
KI
65 Milliarden Parameter, 8 GPUs können alle Parameter feinabstimmen: Das Team von Qiu Xipeng hat den Schwellenwert für große Modelle gesenkt
Technologie-Peripheriegeräte
KI
65 Milliarden Parameter, 8 GPUs können alle Parameter feinabstimmen: Das Team von Qiu Xipeng hat den Schwellenwert für große Modelle gesenkt
65 Milliarden Parameter, 8 GPUs können alle Parameter feinabstimmen: Das Team von Qiu Xipeng hat den Schwellenwert für große Modelle gesenkt

In Richtung großer Modelle trainieren Technologiegiganten größere Modelle, während die Wissenschaft über Möglichkeiten nachdenkt, diese zu optimieren. In letzter Zeit hat die Methode zur Optimierung der Rechenleistung ein neues Niveau erreicht.
Groß angelegte Sprachmodelle (LLM) haben den Bereich der Verarbeitung natürlicher Sprache (NLP) revolutioniert und außergewöhnliche Fähigkeiten wie Emergenz und Epiphanie demonstriert. Wenn Sie jedoch ein Modell mit bestimmten allgemeinen Fähigkeiten erstellen möchten, werden Milliarden von Parametern benötigt, was die Schwelle für die NLP-Forschung erheblich erhöht. Der LLM-Modelloptimierungsprozess erfordert in der Regel teure GPU-Ressourcen, beispielsweise ein 8×80-GB-GPU-Gerät, was es für kleine Labore und Unternehmen schwierig macht, sich an der Forschung in diesem Bereich zu beteiligen.
In letzter Zeit werden Techniken zur Parametereffizienten Feinabstimmung (PEFT) wie LoRA und Präfix-Tuning untersucht, die Lösungen für die Optimierung von LLM mit begrenzten Ressourcen bieten. Allerdings bieten diese Methoden keine praktischen Lösungen für die vollständige Parameter-Feinabstimmung, die als leistungsfähigere Methode als die Parameter-effiziente Feinabstimmung gilt.
In dem Artikel „Full Parameter Fine-tuning for Large Language Models with Limited Resources“, der letzte Woche vom Qiu
Durch die Integration von LOMO in bestehende Speicherspartechniken reduziert der neue Ansatz die Speichernutzung auf 10,8 % im Vergleich zum Standardansatz (DeepSpeed-Lösung). Dadurch ermöglicht der neue Ansatz die vollständige Parameter-Feinabstimmung eines 65B-Modells auf einer Maschine mit 8×RTX 3090s, jeweils mit 24 GB Speicher.

Link zum Papier: https://arxiv.org/abs/2306.09782
In dieser Arbeit analysierte der Autor vier Aspekte der Speichernutzung in LLM: Aktivierung, Optimierungszustand, Gradient Tensor und Parameter und optimierte den Trainingsprozess in drei Aspekten:
- überlegte die Funktion des Optimierers aus algorithmischer Sicht und stellte fest, dass SGD eine gute Möglichkeit ist, die gesamten Parameter von LLM Substitute zu optimieren. Dadurch können die Autoren ganze Teile des Optimiererzustands löschen, da SGD keinen Zwischenzustand speichert.
- Der neu vorgeschlagene Optimierer LOMO reduziert die Speichernutzung von Gradiententensoren auf O(1), was der Speichernutzung des größten Gradiententensors entspricht.
- Um das gemischte Präzisionstraining mit LOMO zu stabilisieren, integrieren die Autoren Gradientennormalisierung und Verlustskalierung und konvertieren bestimmte Berechnungen während des Trainings in volle Präzision.
Neue Technologie macht die Speichernutzung gleich der Parameternutzung plus Aktivierung und maximalen Gradiententensoren. Die Speichernutzung der vollständigen Parameter-Feinabstimmung wird auf das Äußerste getrieben, was nur der Verwendung von Inferenz entspricht. Dies liegt daran, dass der Speicherbedarf des Vorwärts- und Rückwärtsprozesses nicht geringer sein sollte als der des Vorwärtsprozesses allein. Es ist erwähnenswert, dass bei der Verwendung von LOMO zum Speichern von Speicher die neue Methode sicherstellt, dass der Feinabstimmungsprozess nicht beeinträchtigt wird, da der Parameteraktualisierungsprozess immer noch dem SGD entspricht.
Diese Studie bewertet die Speicher- und Durchsatzleistung von LOMO und zeigt, dass Forscher mit LOMO ein 65B-Parametermodell auf 8 RTX 3090-GPUs trainieren können. Um außerdem die Leistung von LOMO bei nachgelagerten Aufgaben zu überprüfen, wendeten sie LOMO an, um alle Parameter von LLM auf die SuperGLUE-Datensatzsammlung abzustimmen. Die Ergebnisse belegen die Wirksamkeit von LOMO zur Optimierung von LLMs mit Milliarden von Parametern.
Einführung in die Methode
Im Methodenabschnitt stellt dieser Artikel LOMO (LOW-MEMORY OPTIMIZATION) ausführlich vor. Im Allgemeinen stellt der Gradiententensor den Gradienten eines Parametertensors dar und seine Größe entspricht der der Parameter, was zu einem größeren Speicheraufwand führt. Bestehende Deep-Learning-Frameworks wie PyTorch speichern Gradiententensoren für alle Parameter. Derzeit gibt es zwei Gründe für die Speicherung von Gradiententensoren: die Berechnung des Optimiererzustands und die Normalisierung von Gradienten.
Da in dieser Studie SGD als Optimierer verwendet wird, gibt es keinen Gradienten-abhängigen Optimiererstatus und es gibt einige Alternativen zur Gradientennormalisierung.
Sie schlugen LOMO vor. Wie in Algorithmus 1 gezeigt, integriert LOMO die Gradientenberechnung und Parameteraktualisierung in einem Schritt und vermeidet so die Speicherung von Gradiententensoren.
Die folgende Abbildung zeigt den Vergleich zwischen SGD und LOMO in den Phasen Backpropagation und Parameteraktualisierung. Pi ist der Modellparameter und Gi ist der zu Pi entsprechende Gradient. LOMO integriert die Gradientenberechnung und Parameteraktualisierung in einem einzigen Schritt, um den Gradiententensor zu minimieren. Pseudocode des entsprechenden Algorithmus von LOMO: Zunächst ein zweidimensionaler Schrittprozess Berechnen Sie den Gradienten und aktualisieren Sie dann die Parameter. Die Fusionsversion ist
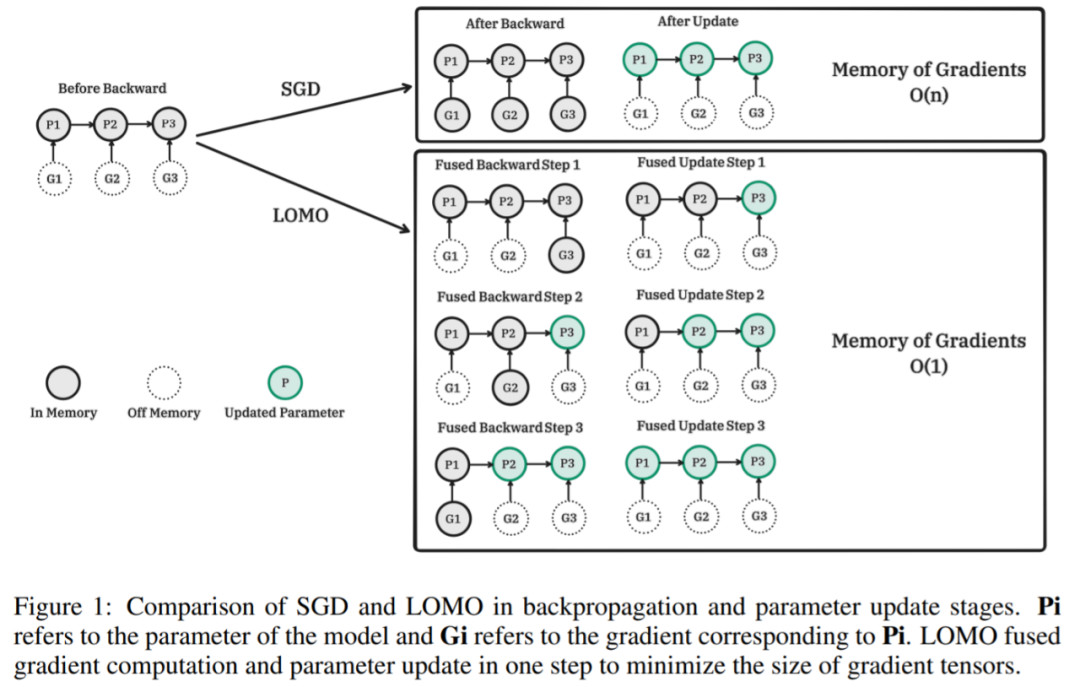
Der größte Teil der LOMO-Speichernutzung stimmt mit der Speichernutzung von Parameter-effizienten Feinabstimmungsmethoden überein, was darauf hinweist, dass die Kombination von LOMO mit diesen Methoden nur zu einer geringfügigen Erhöhung des vom Gradienten belegten Speichers führt. Dadurch können mehr Parameter für die PEFT-Methode abgestimmt werden.

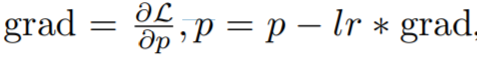
Speichernutzung
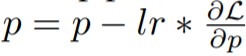 Die Forscher analysierten zunächst den Modellstatus und die aktivierte Speichernutzung während des Trainings unter verschiedenen Einstellungen. Wie in Tabelle 1 gezeigt, führt die Verwendung des LOMO-Optimierers zu einer deutlichen Reduzierung der Speichernutzung, von 102,20 GB auf 14,58 GB, während beim Training des LLaMA-7B-Modells die Speichernutzung sinkt von 51,99 GB auf 14,58 GB reduziert. Die deutliche Reduzierung der Speichernutzung ist hauptsächlich auf den geringeren Speicherbedarf für Farbverläufe und Optimiererzustände zurückzuführen. Daher wird der Speicher während des Trainingsprozesses hauptsächlich von Parametern belegt, was der Speichernutzung während der Inferenz entspricht.
Die Forscher analysierten zunächst den Modellstatus und die aktivierte Speichernutzung während des Trainings unter verschiedenen Einstellungen. Wie in Tabelle 1 gezeigt, führt die Verwendung des LOMO-Optimierers zu einer deutlichen Reduzierung der Speichernutzung, von 102,20 GB auf 14,58 GB, während beim Training des LLaMA-7B-Modells die Speichernutzung sinkt von 51,99 GB auf 14,58 GB reduziert. Die deutliche Reduzierung der Speichernutzung ist hauptsächlich auf den geringeren Speicherbedarf für Farbverläufe und Optimiererzustände zurückzuführen. Daher wird der Speicher während des Trainingsprozesses hauptsächlich von Parametern belegt, was der Speichernutzung während der Inferenz entspricht.
Wie in Abbildung 2 dargestellt, wird ein beträchtlicher Anteil des Speichers (73,7 %) dem Optimierungsstatus zugewiesen, wenn der AdamW-Optimierer für das LLaMA-7B-Training verwendet wird. Das Ersetzen des AdamW-Optimierers durch den SGD-Optimierer reduziert effektiv den Prozentsatz des vom Optimiererstatus belegten Speichers und verringert dadurch die GPU-Speichernutzung (von 102,20 GB auf 51,99 GB). Wenn LOMO verwendet wird, werden Parameteraktualisierungen und Rückwärtsvorgänge in einem einzigen Schritt zusammengeführt, wodurch der Speicherbedarf für den Optimiererstatus weiter entfällt.
Durchsatz
Die Forscher verglichen die Durchsatzleistung von LOMO, AdamW und SGD. Die Experimente wurden auf einem Server durchgeführt, der mit 8 RTX 3090-GPUs ausgestattet war.Für das 7B-Modell zeigt der Durchsatz von LOMO einen deutlichen Vorteil und übertrifft AdamW und SGD um etwa das Elffache. Diese deutliche Verbesserung ist auf die Fähigkeit von LOMO zurückzuführen, das 7B-Modell auf einer einzelnen GPU zu trainieren, was den Kommunikationsaufwand zwischen GPUs reduziert. Der etwas höhere Durchsatz von SGD im Vergleich zu AdamW ist darauf zurückzuführen, dass SGD die Berechnung von Impuls und Varianz ausschließt. Das 13B-Modell kann aufgrund von Speicherbeschränkungen nicht mit AdamW auf den vorhandenen 8 RTX 3090-GPUs trainiert werden. In diesem Fall ist Modellparallelität für LOMO erforderlich, das SGD hinsichtlich des Durchsatzes immer noch übertrifft. Dieser Vorteil wird auf die speichereffiziente Natur von LOMO und die Tatsache zurückgeführt, dass nur zwei GPUs erforderlich sind, um das Modell mit denselben Einstellungen zu trainieren, wodurch die Kommunikationskosten gesenkt und der Durchsatz verbessert werden. Darüber hinaus stieß SGD beim Training des 30B-Modells auf OOM-Probleme (Out-of-Memory) auf 8 RTX 3090-GPUs, während LOMO mit nur 4 GPUs eine gute Leistung erbrachte. Schließlich trainierte der Forscher das 65B-Modell erfolgreich mit 8 RTX 3090-GPUs und erreichte einen Durchsatz von 4,93 TGS. Mit dieser Serverkonfiguration und LOMO dauert der Trainingsprozess des Modells für 1000 Samples (jedes Sample enthält 512 Token) etwa 3,6 Stunden. Downstream-Leistung Um die Wirksamkeit von LOMO bei der Feinabstimmung großer Sprachmodelle zu bewerten, führten die Forscher eine umfangreiche Reihe von Experimenten durch. Sie verglichen LOMO mit zwei anderen Methoden: Die eine ist Zero-Shot, die keine Feinabstimmung erfordert, und die andere ist LoRA, eine beliebte Parameter-effiziente Feinabstimmungstechnik. 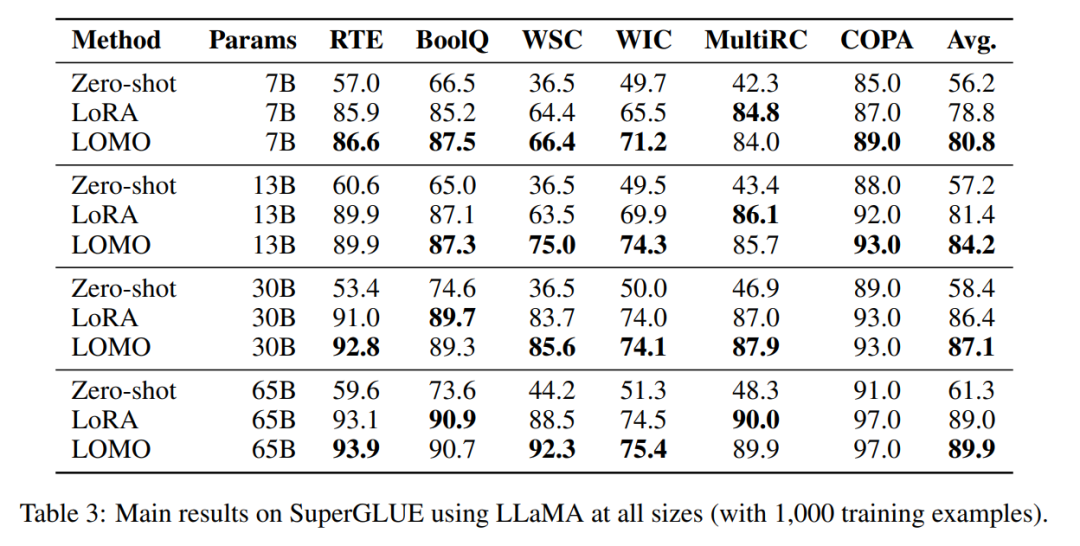
- LOMO schneidet deutlich besser ab als Zero-Shot;
- In den meisten Experimenten ist LOMO im Allgemeinen besser als LoRA; s skaliert auf 65 Milliarden Parameter.
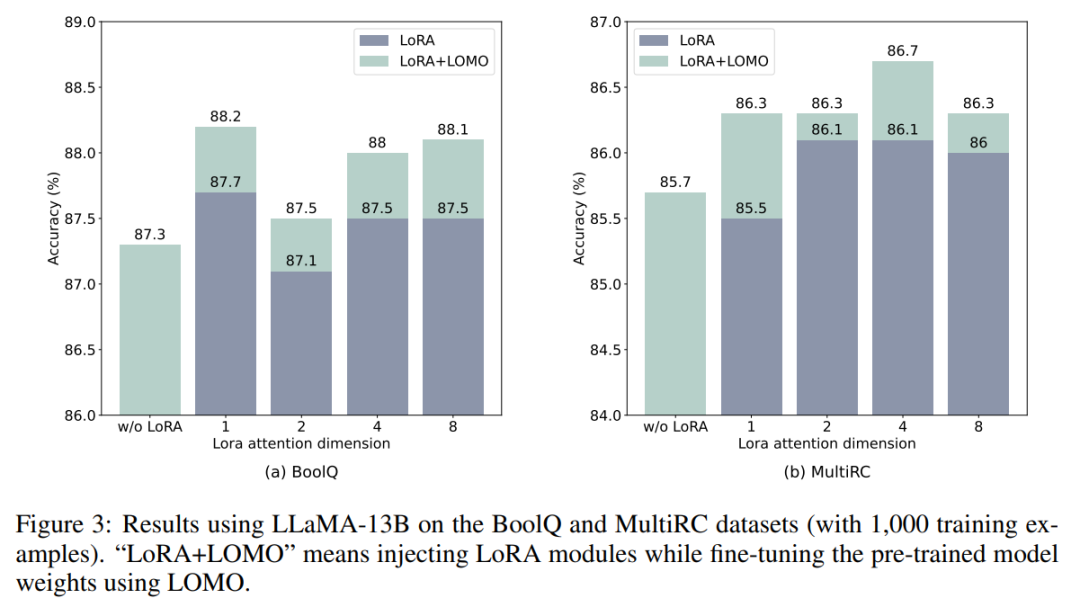
- LOMO und LoRA sind im Wesentlichen unabhängig voneinander. Um diese Aussage zu überprüfen, führten die Forscher Experimente mit BoolQ- und MultiRC-Datensätzen unter Verwendung von LLaMA-13B durch. Die Ergebnisse sind in Abbildung 3 dargestellt.
Sie fanden heraus, dass LOMO die Leistung von LoRA weiter steigerte, unabhängig davon, wie hoch die Ergebnisse waren, die LoRA erzielte. Dies zeigt, dass die verschiedenen Feinabstimmungsmethoden von LOMO und LoRA sich ergänzen. LOMO konzentriert sich insbesondere auf die Feinabstimmung der Gewichte des vorab trainierten Modells, während LoRA andere Module anpasst. Daher hat LOMO keinen Einfluss auf die Leistung von LoRA; stattdessen ermöglicht es eine bessere Modellabstimmung für nachgelagerte Aufgaben.
 Weitere Einzelheiten finden Sie im Originalpapier.
Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt von65 Milliarden Parameter, 8 GPUs können alle Parameter feinabstimmen: Das Team von Qiu Xipeng hat den Schwellenwert für große Modelle gesenkt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
