
 Technologie-Peripheriegeräte
KI
Google nutzt KI, um das Zehn-Jahres-Ranking-Algorithmus-Siegel zu brechen. Es wird jeden Tag Billionen Mal ausgeführt, aber Internetnutzer sagen, es sei die unrealistischste Forschung?
Technologie-Peripheriegeräte
KI
Google nutzt KI, um das Zehn-Jahres-Ranking-Algorithmus-Siegel zu brechen. Es wird jeden Tag Billionen Mal ausgeführt, aber Internetnutzer sagen, es sei die unrealistischste Forschung?
Google nutzt KI, um das Zehn-Jahres-Ranking-Algorithmus-Siegel zu brechen. Es wird jeden Tag Billionen Mal ausgeführt, aber Internetnutzer sagen, es sei die unrealistischste Forschung?

Organisation |. Nuka Cola, Chu Xingjuan
Freunde, die grundlegende Informatikkurse belegt haben, müssen persönlich einen Sortieralgorithmus entwickelt haben – das heißt, sie verwenden Code, um die Elemente in einer ungeordneten Liste in aufsteigender oder absteigender Reihenfolge neu anzuordnen. Es ist eine interessante Herausforderung und es gibt viele Möglichkeiten, sie zu meistern. Es wurde viel Zeit investiert, um herauszufinden, wie Sortieraufgaben effizienter erledigt werden können.
Als Grundoperation sind Sortieralgorithmen in die Standardbibliotheken der meisten Programmiersprachen integriert. Es gibt viele verschiedene Sortiertechniken und Algorithmen, die in Codebasen auf der ganzen Welt verwendet werden, um große Datenmengen online zu organisieren, aber zumindest was die mit dem LLVM-Compiler verwendeten C++-Bibliotheken betrifft, hat sich der Sortiercode seit mehr als einem Jahrzehnt nicht geändert .
Kürzlich hat das DeepMind AI-Team von Google nun ein Reinforcement-Learning-Tool, AlphaDev, entwickelt, das extrem optimierte Algorithmen entwickeln kann, ohne dass ein Vortraining mit menschlichen Codebeispielen erforderlich ist. Heute wurden diese Algorithmen in die LLVM-Standard-C++-Sortierbibliothek integriert. Dies ist das erste Mal seit mehr als einem Jahrzehnt, dass sich ein Teil der Sortierbibliothek geändert hat, und das erste Mal, dass mit Reinforcement Learning entwickelte Algorithmen zur Bibliothek hinzugefügt wurden.
Stellen Sie sich den Programmierprozess als „Spiel“ vor
Das DeepMind-System ist oft in der Lage, Lösungen für Probleme zu finden, an die Menschen noch nie gedacht haben, da es keine vorherige Auseinandersetzung mit menschlichen Spielstrategien erfordert. DeepMind setzt beim Lernen aus Erfahrung vollständig auf Selbstkonfrontation, daher gibt es manchmal blinde Flecken, die von Menschen ausgenutzt werden können.
Diese Methode ist der Programmierung tatsächlich sehr ähnlich. Große Sprachmodelle sind in der Lage, effizienten Code zu schreiben, da sie zahlreiche Beispiele menschlichen Codes gesehen haben. Aus diesem Grund ist es für Sprachmodelle jedoch schwierig, Dinge zu produzieren, die Menschen zuvor nicht getan haben. Wenn wir allgegenwärtige vorhandene Algorithmen (z. B. Sortierfunktionen) weiter optimieren wollen, wird es schwierig sein, die Einschränkungen inhärenter Ideen zu durchbrechen, indem wir uns weiterhin auf vorhandenen menschlichen Code verlassen. Wie kann KI also wirklich neue Wege gehen?
DeepMind-Forscher verwendeten Methoden ähnlich wie Schach und Go, um Codeaufgaben zu optimieren und sie in Einzelspieler-„Puzzles“ umzuwandeln. AlphaDev Systems hat einen x86-Assembleralgorithmus entwickelt, der die laufende Latenz des Codes als Bewertung behandelt und bestrebt ist, die Bewertung zu minimieren und gleichzeitig sicherzustellen, dass der Code reibungslos ausgeführt werden kann. Dank der Anwendung von Reinforcement Learning beherrscht AlphaDev nach und nach die Kunst, effizienten und prägnanten Code zu schreiben.
AlphaDev basiert auf AlphaZero. DeepMind ist bekannt für die Entwicklung von KI-Software, die selbstständig Spielregeln lernen kann. Diese Denkweise hat sich als sehr effektiv erwiesen und viele Spielprobleme wie Schach, Go und „StarCraft“ erfolgreich gelöst. Während die Einzelheiten je nach dem von Ihnen gespielten Spiel variieren, lernt die Software von DeepMind durch wiederholtes Spielen und sucht kontinuierlich nach Möglichkeiten, Ihre Punktzahl zu maximieren.
Die beiden Kernkomponenten von AlphaDev sind Lernalgorithmen und Darstellungsfunktionen.
Die Verwendung von DRL in Kombination mit zufälligen Suchoptimierungsalgorithmen zum Zusammenstellen von Spielen ist eine Methode des AlphaDev-Lernalgorithmus. Der Hauptlernalgorithmus in AlphaDev ist eine Erweiterung von AlphaZero 33, einem bekannten DRL-Algorithmus, bei dem ein neuronales Netzwerk darauf trainiert wird, die Suche durch das Spiel zu leiten.
Diese Funktion dient zur Überwachung der Gesamtleistung der Codeentwicklung und deckt die allgemeine Struktur des Algorithmus sowie die Verwendung von x86-Registern und Speicher ab. Das System wird nach und nach Montageanweisungen einführen, die unabhängig hinzugefügt werden, wenn Auswahlen mithilfe einer vom Spielsystem übernommenen Monte-Carlo-Baumsuchmethode getroffen werden. Die Baumstruktur ermöglicht es dem System, die Suche schnell auf einen begrenzten Bereich einzuschränken, der eine große Anzahl potenzieller Anweisungen enthält, während die Monte-Carlo-Methode bestimmte Anweisungen aus diesem Verzweigungsbereich mit einem gewissen Grad an Zufall auswählt. Beachten Sie, dass es sich bei den hier genannten „Anweisungen“ um Vorgänge wie die Auswahl bestimmter Register zum Erstellen einer gültigen und vollständigen Baugruppe handelt. )
Das System bewertet dann die Latenz und den Gültigkeitsstatus des Assembler-Codes und gibt eine Bewertung ab, die mit der vorherigen Bewertung verglichen wird. Durch verstärkendes Lernen ist das System in der Lage, die Arbeitsinformationen verschiedener Zweige in der Baumstruktur für einen bestimmten Programmstatus aufzuzeichnen. Mit der Zeit wird das System damit vertraut, wie es das Spiel (erfolgreicher Abschluss der Sortierung) mit der höchsten Punktzahl (was die niedrigste Latenz darstellt) gewinnt. Die primäre Darstellungsfunktion von AlphaDev basiert auf Transformers.
Um AlphaDev darin zu trainieren, neue Algorithmen zu entdecken, beobachtet AlphaDev in jeder Runde den von ihm generierten Algorithmus und die in der Zentraleinheit (CPU) enthaltenen Informationen und schließt das Spiel dann ab, indem es Anweisungen auswählt, die dem Algorithmus hinzugefügt werden sollen. AlphaDev muss eine große Anzahl möglicher Befehlskombinationen effizient durchsuchen, um einen Algorithmus zu finden, der sequenzierbar und außerdem schneller als der derzeit beste Algorithmus ist, während das Agentenmodell auf der Grundlage der Korrektheit und Latenz des Algorithmus belohnt werden kann.
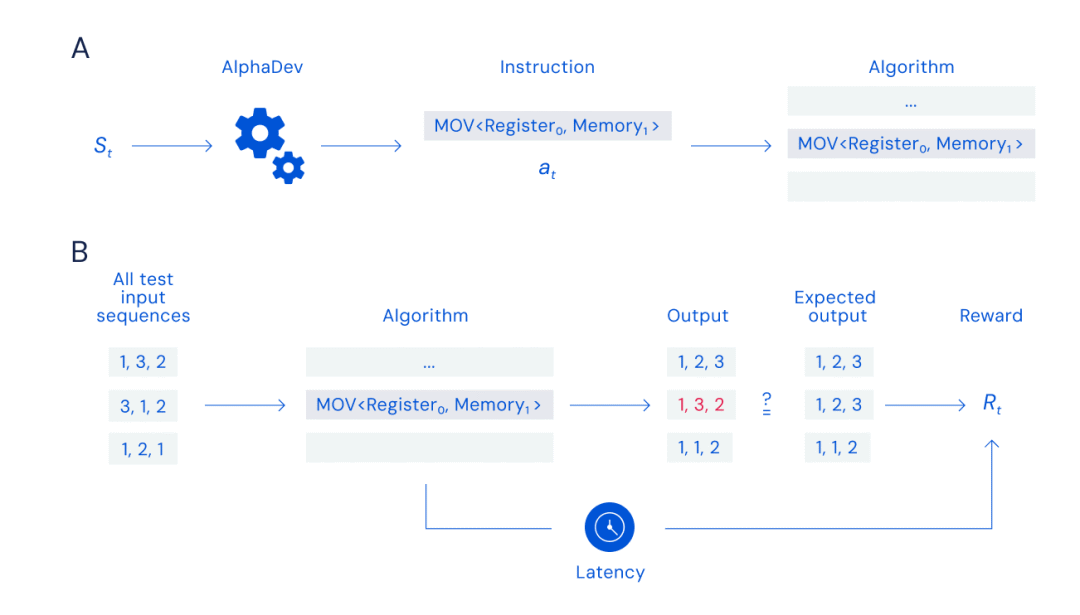
Bild A: Montagespiel, Bild B: Belohnungsberechnung
Schließlich hat AlphaDev neue Sortieralgorithmen entdeckt, die die Sortierbibliothek LLVM libc++ verbessern können: Bei kürzeren Sequenzen ist die Sortierbibliothek 70 % schneller; bei Sequenzen über 250.000 Elementen wird die Geschwindigkeit um etwa 1,7 % erhöht.
Konkret liegt die Innovation dieses Algorithmus hauptsächlich in zwei Befehlssequenzen: AlphaDev Swap Move (Swap Move) und AlphaDev Copy Move (Copy Move). Durch diese beiden Befehle überspringt AlphaDev einen Schritt und führt eine scheinbar falsche, aber tatsächliche Abkürzung aus Elemente verbinden.
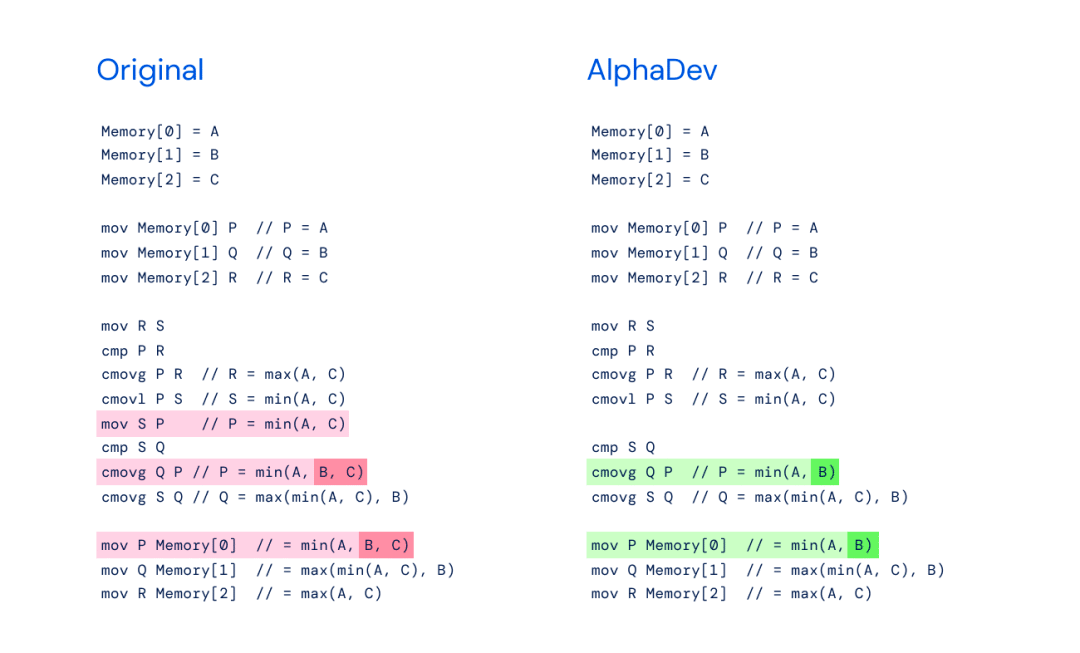
Links: Ursprüngliche sort3-Implementierung mit min(A,B,C).
Rechtes Bild: AlphaDev Swap Move – AlphaDev hat herausgefunden, dass Sie nur min(A,B) benötigen.
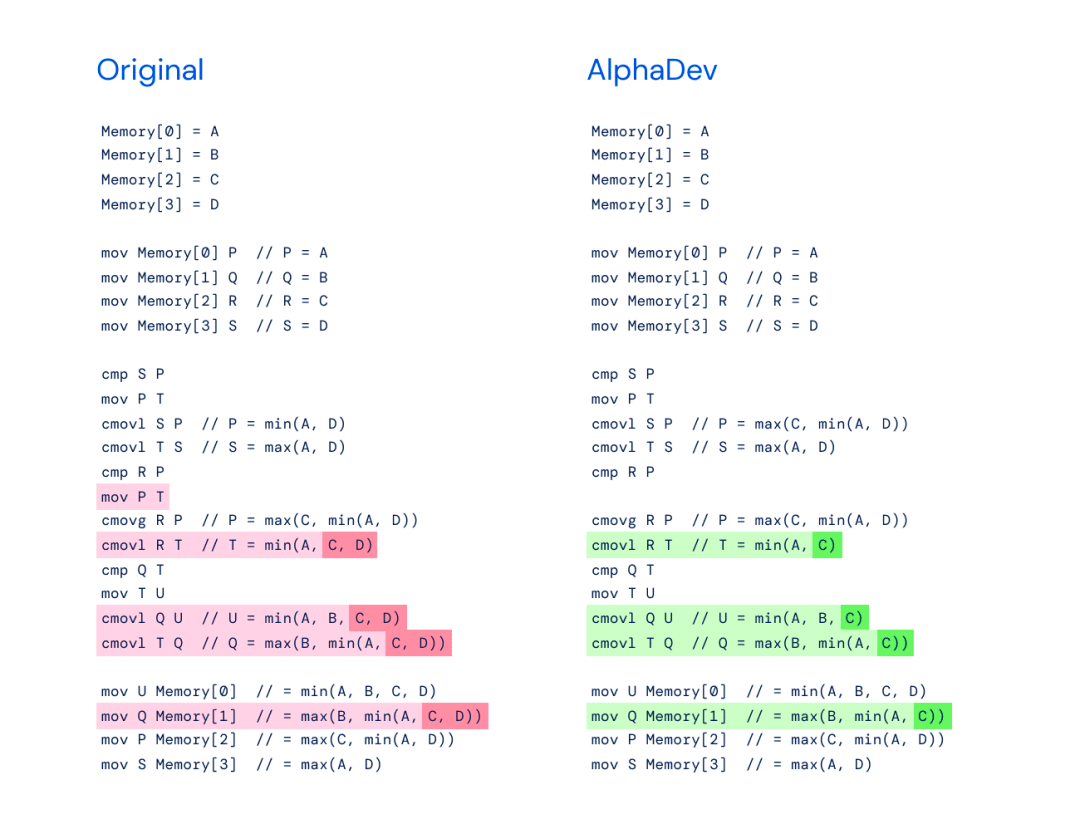
Links: Ursprüngliche Implementierung von max (B, min (A, C)) für einen größeren Sortieralgorithmus, der acht Elemente sortiert.
Richtig: AlphaDev hat festgestellt, dass nur max (B, min (A, C)) benötigt wird, wenn die Kopierbewegung verwendet wird.
Der Hauptvorteil dieses Systems besteht darin, dass für den Trainingsprozess keine Codebeispiele erforderlich sind. Stattdessen generiert das System selbstständig Codebeispiele und wertet diese anschließend aus. Dabei erwirbt es nach und nach Informationen über die effektive Abfolge von Befehlskombinationen.
Vom Sortieren bis zum Hashing
Nachdem DeepMind einen schnelleren Sortieralgorithmus entdeckt hatte, testete es, ob AlphaDev einen anderen Informatikalgorithmus verallgemeinern und verbessern könnte: Hashing.
Hashing ist ein grundlegender Algorithmus, der in der Informatik zum Abrufen, Speichern und Komprimieren von Daten verwendet wird. Genau wie ein Bibliothekar, der ein Klassifizierungssystem verwendet, um ein bestimmtes Buch zu finden, helfen Hashing-Algorithmen den Benutzern dabei, zu wissen, wonach sie suchen und wo sie es finden können. Diese Algorithmen nehmen Daten für einen bestimmten Schlüssel (z. B. Benutzername „Jane Doe“) und hashen sie – ein Prozess, der die Rohdaten in eine eindeutige Zeichenfolge (z. B. 1234ghfty) umwandelt. Dieser Hashing-Algorithmus wird verwendet, um schnell Daten zu einem Schlüssel abzurufen, sodass nicht die gesamten Daten durchsucht werden müssen.
DeepMind wendet AlphaDev auf einen der am häufigsten verwendeten Hashing-Algorithmen in Datenstrukturen an, um schnellere Algorithmen zu entdecken. AlphaDev stellte fest, dass der Algorithmus 30 % schneller war, wenn die Hash-Funktion Daten im Bereich von 9 bis 16 Byte verwendete.
In diesem Jahr wurde der neue Hashing-Algorithmus von AlphaDev in der Open-Source-Bibliothek Abseil veröffentlicht, die Millionen von Entwicklern auf der ganzen Welt zur Verfügung steht, und die Bibliothek wird mittlerweile jeden Tag Billionen Mal verwendet.
Tatsächlicher Arbeitscode
Sortiermechanismen in komplexen Programmen können große Sammlungen beliebiger Elemente verarbeiten. Auf der Ebene der Standardbibliothek beruht diese Fähigkeit jedoch auf einer Reihe stark eingeschränkter spezifischer Funktionen. Jede dieser Funktionen kann nur eine oder wenige Situationen bewältigen. Einige einzelne Algorithmen können beispielsweise nur 3, 4 oder 5 Elemente sortieren. Wir können eine beliebige Anzahl von Einträgen mithilfe einer Reihe von Funktionen sortieren, aber wir können nur bis zu 4 Einträge pro Funktionsaufruf sortieren.
AlphaDev wurde von DeepMind für jede Funktion implementiert, die tatsächlichen Betriebsmethoden unterscheiden sich jedoch erheblich. Es ist möglich, Code ohne Verzweigungsanweisungen zu schreiben, um eine Funktion zu verarbeiten, die eine bestimmte Anzahl von Einträgen verarbeitet, d. h. abhängig vom Status der Variablen unterschiedlichen Code ausführt. Daher ist die Codeleistung tendenziell umgekehrt proportional zur Anzahl der beteiligten Anweisungen.
AlphaDev hat die Anzahl der Anweisungen in sort-3, sort-5 und sort-8 erfolgreich um jeweils eine und in sort-6 und sort-7 sogar noch mehr reduziert. Nur bei sort-4 konnte keine Möglichkeit gefunden werden, den vorhandenen Code zu verbessern. Wiederholte Tests an realen Systemen zeigen, dass weniger Anweisungen die Leistung verbessern.
Um eine variable Anzahl von Einträgen zu sortieren, müssen Sie Verzweigungsanweisungen in Ihren Code einschließen, und verschiedene Prozessoren verfügen über eine unterschiedliche Anzahl von Komponenten, die für die Verarbeitung dieser Verzweigungen zuständig sind.
Bei der Bewertung dieser Situation verwendeten die Forscher 100 verschiedene Computergeräte. AlphaDev hat auch Möglichkeiten gefunden, die Leistung in solchen Szenarien weiter zu senken. Nehmen wir als Beispiel eine Funktion, die bis zu 4 Elemente gleichzeitig sortiert, um zu sehen, wie sie funktioniert.
In der aktuellen Implementierung der C++-Bibliothek muss der Code eine Reihe von Tests durchführen, um zu bestätigen, wie viele Elemente sortiert werden müssen, und dann die entsprechende Sortierfunktion basierend auf der Anzahl der Elemente aufrufen.
Der modifizierte Code von AlphaDev übernimmt eine „magischere“ Idee: Er testet zunächst, ob zwei Einträge vorhanden sind, und ruft in diesem Fall sofort die entsprechende Funktion zum Sortieren auf. Wenn die Zahl größer als 2 ist, sortiert der Code zuerst die ersten 3 Einträge. Auf diese Weise werden die sortierten Ergebnisse zurückgegeben, wenn tatsächlich nur 3 Einträge vorhanden sind. Da tatsächlich 4 Elemente sortiert werden müssen, führt AlphaDev speziellen Code aus, um das 4. Element an der entsprechenden Position unter den ersten 3 Elementen einzufügen, die auf sehr effiziente Weise sortiert wurden.
Dieser Ansatz klingt etwas seltsam, aber es stellt sich heraus, dass seine Leistung immer besser ist als die des vorhandenen Codes.
Da AlphaDev effizienteren Code generiert, plant das Forschungsteam, diese Ergebnisse wieder in die LLVM-Standard-C++-Bibliothek zusammenzuführen. Das Problem besteht jedoch darin, dass der Code im Assemblerformat und nicht in C++ vorliegt. Daher müssen sie rückwärts arbeiten, um den C++-Code zu finden, der dieselbe Assembly generiert.
Eine umgeschriebene Version dieses Satzes: Dieser Teil des Codes wurde nun in die LLVM-Toolchain integriert und zum ersten Mal seit fast einem Jahrzehnt aktualisiert. Forscher schätzen, dass von AlphaDev generierter neuer Code jeden Tag Billionen Mal ausgeführt wird.
Fazit
Das ist so gut! Wir Programmierer haben diese grundlegende Sortieraufgabe schon vor langer Zeit gelernt, aber jetzt sind wir 70 % schneller. Die KI in Algorithmen und Bibliotheken, auf die wir uns alle verlassen, sorgt für erhebliche Beschleunigungen, die sehr aufregend sind. „Einige Entwickler sind von den Ergebnissen von Google DeepMind begeistert.
Aber einige Entwickler haben es nicht gekauft: „Ziemlich enttäuschend … 1,7 % Verbesserung? 70 % der Folge von 5 Elementen? Wahrscheinlich die unbeliebteste und unrealistischste angewandte Forschung …“ Einige Entwickler sagten: „Nicht wahr? Ist es etwas irreführend zu sagen, dass ein neuer Algorithmus entdeckt wurde? Scheint trotzdem eher eine Algorithmusoptimierung zu sein
Referenzlink:
https://arstechnica.com/science/2023/06/googles-deepmind-develops-a-system-that-writes-efficient-algorithms/https://www.deepmind.com/blog/alphadev-discovers-faster-sorting-algorithms
Tiefe: Warum ist im chinesischen Datenbankbereich kein Gigant wie Snowflake aufgetaucht?
Der bizarrste Zusammenbruch seit siebzehn Jahren! Um zu verhindern, dass OpenAI und Google umsonst an Daten kommen, hat Reddit enorme API-Gebühren erhoben und Entwickler diffamiert, was zu großen Protesten in der Community geführt hat
Code „stehlen“, um ein Unternehmen aufzubauen, akademische Qualifikationen zu fälschen und in 6 Tagen 100 Millionen US-Dollar zu verdienen, aber keinen Lohnrückstand zu erhalten, nachdem er wiederholt befragt wurde
Das obige ist der detaillierte Inhalt vonGoogle nutzt KI, um das Zehn-Jahres-Ranking-Algorithmus-Siegel zu brechen. Es wird jeden Tag Billionen Mal ausgeführt, aber Internetnutzer sagen, es sei die unrealistischste Forschung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Die Zookeper -Leistungsstimmung auf CentOS kann von mehreren Aspekten beginnen, einschließlich Hardwarekonfiguration, Betriebssystemoptimierung, Konfigurationsparameteranpassung, Überwachung und Wartung usw. Hier finden Sie einige spezifische Tuning -Methoden: SSD wird für die Hardwarekonfiguration: Da die Daten von Zookeeper an Disk geschrieben werden, wird empfohlen, SSD zu verbessern, um die I/O -Leistung zu verbessern. Genug Memory: Zookeeper genügend Speicherressourcen zuweisen, um häufige Lesen und Schreiben von häufigen Festplatten zu vermeiden. Multi-Core-CPU: Verwenden Sie Multi-Core-CPU, um sicherzustellen, dass Zookeeper es parallel verarbeiten kann.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
