

Dieser Artikel erläutert hauptsächlich das Prinzip des konsistenten Hash-Algorithmus und das bestehende Datenversatzproblem, stellt dann Methoden zur Lösung des Datenversatzproblems vor und analysiert schließlich die Verwendung des konsistenten Hash-Algorithmus in Dubbo. In diesem Artikel wird die Funktionsweise des konsistenten Hashing-Algorithmus sowie die Probleme und Lösungen vorgestellt, mit denen der Algorithmus konfrontiert ist.
Hier ist ein Zitat von der offiziellen Website von Dubbo:
LoadBalance bedeutet auf Chinesisch, dass es darum geht, Netzwerkanforderungen oder andere Formen der Last „gleichmäßig“ auf verschiedene Maschinen zu verteilen. Vermeiden Sie die Situation, dass einige Server im Cluster übermäßigem Druck ausgesetzt sind, während andere Server relativ inaktiv sind. Durch Lastausgleich kann jeder Server eine Last erhalten, die für seine eigenen Verarbeitungskapazitäten geeignet ist. Durch die Entlastung hoch ausgelasteter Server können Sie auch die Verschwendung von Ressourcen vermeiden und so zwei Fliegen mit einer Klappe schlagen. Der Lastausgleich kann in Software-Lastausgleich und Hardware-Lastausgleich unterteilt werden. In unserer täglichen Entwicklung ist es im Allgemeinen schwierig, auf den Hardware-Lastausgleich zuzugreifen. Es ist jedoch weiterhin Software-Lastausgleich verfügbar, beispielsweise Nginx. In Dubbo gibt es auch das Konzept des Lastausgleichs und die entsprechende Implementierung.
Um eine übermäßige Belastung bestimmter Dienstanbieter zu vermeiden, muss Dubbo Anrufanfragen von Dienstkonsumenten zuordnen. Die Auslastung des Dienstanbieters ist zu groß, was dazu führen kann, dass bei einigen Anfragen eine Zeitüberschreitung auftritt. Daher ist es sehr wichtig, die Last auf jeden Dienstanbieter auszugleichen. Dubbo bietet vier Lastausgleichsimplementierungen, nämlich RandomLoadBalance basierend auf einem gewichteten Zufallsalgorithmus, LeastActiveLoadBalance basierend auf dem Algorithmus der geringsten aktiven Anrufanzahl, ConsistentHashLoadBalance basierend auf der Hash-Konsistenz und RoundRobinLoadBalance basierend auf einem gewichteten Polling-Algorithmus. Obwohl die Codes dieser Lastausgleichsalgorithmen nicht sehr langwierig sind, erfordert das Verständnis ihrer Prinzipien gewisse Fachkenntnisse und Verständnis.
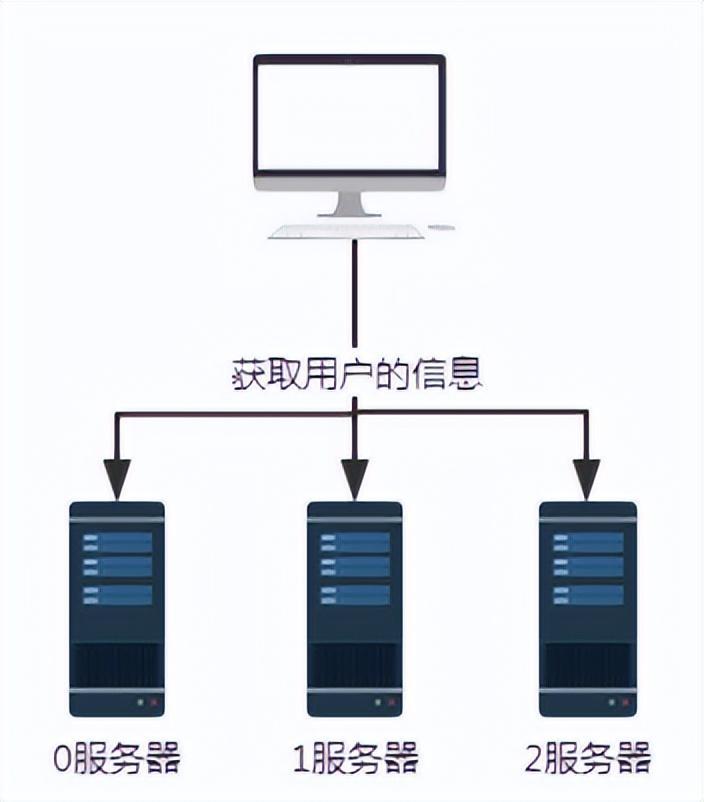
Abbildung 1 Anfrage ohne Hash-Algorithmus
Angenommen, die Server 0, 1 und 2 speichern alle Benutzerinformationen, dann müssen wir bestimmte Benutzerinformationen abrufen, weil wir Wenn wir nicht wissen, auf welchem Server die Benutzerinformationen gespeichert sind, müssen wir die Server 0, 1 und 2 abfragen. Die Effizienz der Datenbeschaffung auf diese Weise ist äußerst gering.
Für ein solches Szenario können wir einen Hash-Algorithmus einführen.
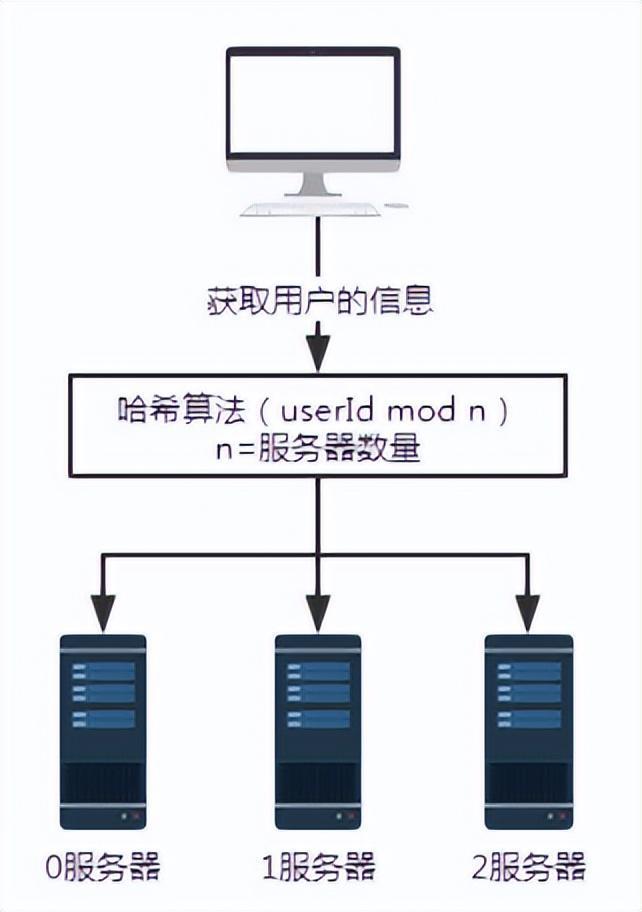
Abbildung 2 Anfrage nach Einführung des Hash-Algorithmus
Im obigen Szenario wird davon ausgegangen, dass jeder Server denselben Hash-Algorithmus zum Speichern von Benutzerinformationen verwendet. Befolgen Sie daher beim Abrufen von Benutzerinformationen einfach denselben Hashing-Algorithmus.
Angenommen, wir möchten die Benutzerinformationen mit der Benutzernummer 100 abfragen. Nach einem bestimmten Hash-Algorithmus, wie hier Benutzer-ID mod n, also 100 mod 3, ist das Ergebnis 1. Die Anfrage von Benutzer Nummer 100 wird also letztendlich von Server Nummer 1 empfangen und verarbeitet.
Dies löst das Problem ungültiger Abfragen.
Aber welche Probleme wird eine solche Lösung mit sich bringen?
Beim Erweitern oder Verkleinern werden große Datenmengen migriert. Mindestens 50 % der Daten werden betroffen sein.
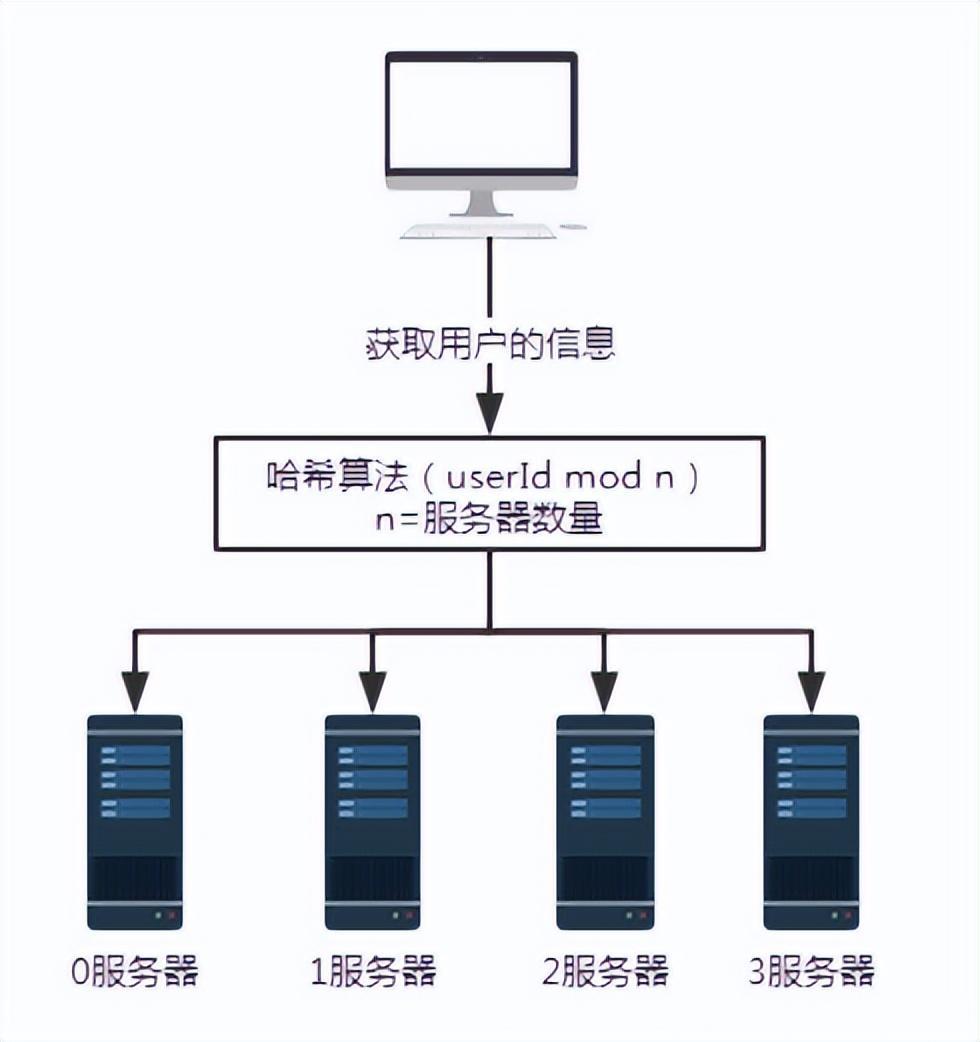
Abbildung 3 Hinzufügen eines Servers
Um das Problem zu veranschaulichen, fügen Sie einen Server 3 hinzu. Die Anzahl der Server n ändert sich von 3 auf 4. Bei der Abfrage der Benutzerinformationen mit der Benutzernummer 100 ist der Rest nach der Division von 100 durch 4 0. Zu diesem Zeitpunkt wird die Anfrage von Server 0 empfangen.
Wenn also die Anzahl der Server zunimmt oder abnimmt, ist mit Sicherheit eine große Datenmigration verbunden.
Der Vorteil dieses Hash-Algorithmus ist seine Einfachheit und Benutzerfreundlichkeit, weshalb er von den meisten Sharding-Regeln übernommen wird. Im Allgemeinen wird die Anzahl der Partitionen im Voraus basierend auf der Datenmenge geschätzt.
Der Nachteil dieser Technologie besteht darin, dass, sobald die Anzahl der Knoten im Netzwerk zunimmt oder schrumpft, die Zuordnungsbeziehung der Knoten neu berechnet werden muss, was eine Datenmigration erforderlich macht. Daher wird bei der Kapazitätserweiterung normalerweise eine Verdoppelung der Kapazität verwendet, um zu vermeiden, dass die gesamte Datenzuordnung unterbrochen wird und eine vollständige Migration auftritt. In diesem Fall werden nur 50 % der Daten migriert.
** Der konsistente Hash-Algorithmus wurde 1997 von Karger und seinen Mitarbeitern am MIT vorgeschlagen. Der Algorithmus wurde ursprünglich für den Lastausgleich großer Cache-Systeme vorgeschlagen. ** Der Arbeitsprozess ist wie folgt. Zuerst wird ein Hash für den Cache-Knoten basierend auf der IP oder anderen Informationen generiert und der Hash auf den Ring von [0, 232 – 1] projiziert. Bei jeder Abfrage oder Schreibanforderung wird ein Hashwert für den Schlüssel des Cache-Elements generiert. Als Nächstes müssen Sie den ersten Knoten im Cache-Knoten mit einem Hash-Wert finden, der größer oder gleich dem angegebenen Wert ist, und eine Cache-Abfrage oder einen Schreibvorgang für diesen Knoten durchführen. Wenn der aktuelle Knoten abläuft, kann bei der nächsten Cache-Abfrage oder dem nächsten Cache-Schreibvorgang nach einem anderen Cache-Knoten mit einem Hash gesucht werden, der größer als der aktuelle Cache-Eintrag ist. Der allgemeine Effekt ist in der folgenden Abbildung dargestellt. Jeder Cache-Knoten nimmt eine Position im Ring ein. Wenn der Hash-Wert des Schlüssels des Cache-Elements kleiner ist als der Hash-Wert des Cache-Knotens, wird das Cache-Element gespeichert oder vom Cache-Knoten gelesen. Das Cache-Element, das der grünen Markierung unten entspricht, wird im Knoten-Cache-2 gespeichert. Die Cache-Elemente sollten ursprünglich im Cache-3-Knoten gespeichert werden, aber aufgrund der Ausfallzeit dieses Knotens wurden sie schließlich im Cache-4-Knoten gespeichert.
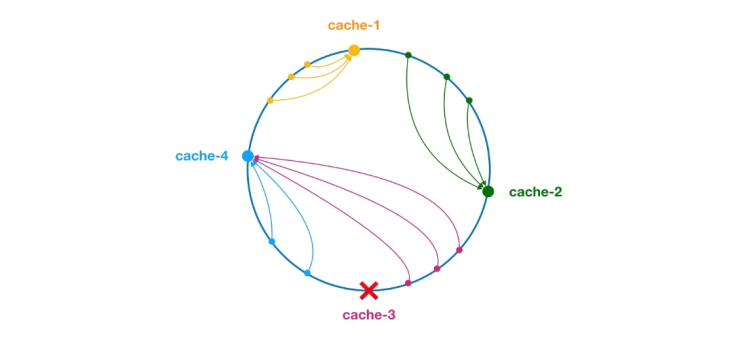
Abbildung 4 Konsistenter Hash-Algorithmus
Unabhängig davon, ob Knoten hinzugefügt oder ausgefallen sind, ist der betroffene Bereich nur die Zunahme oder Ausfallzeit des Servers im Hash-Ring-Bereich Im Gegenuhrzeigersinn werden andere Intervalle nicht beeinflusst.
Aber es gibt auch Probleme mit konsistentem Hashing:
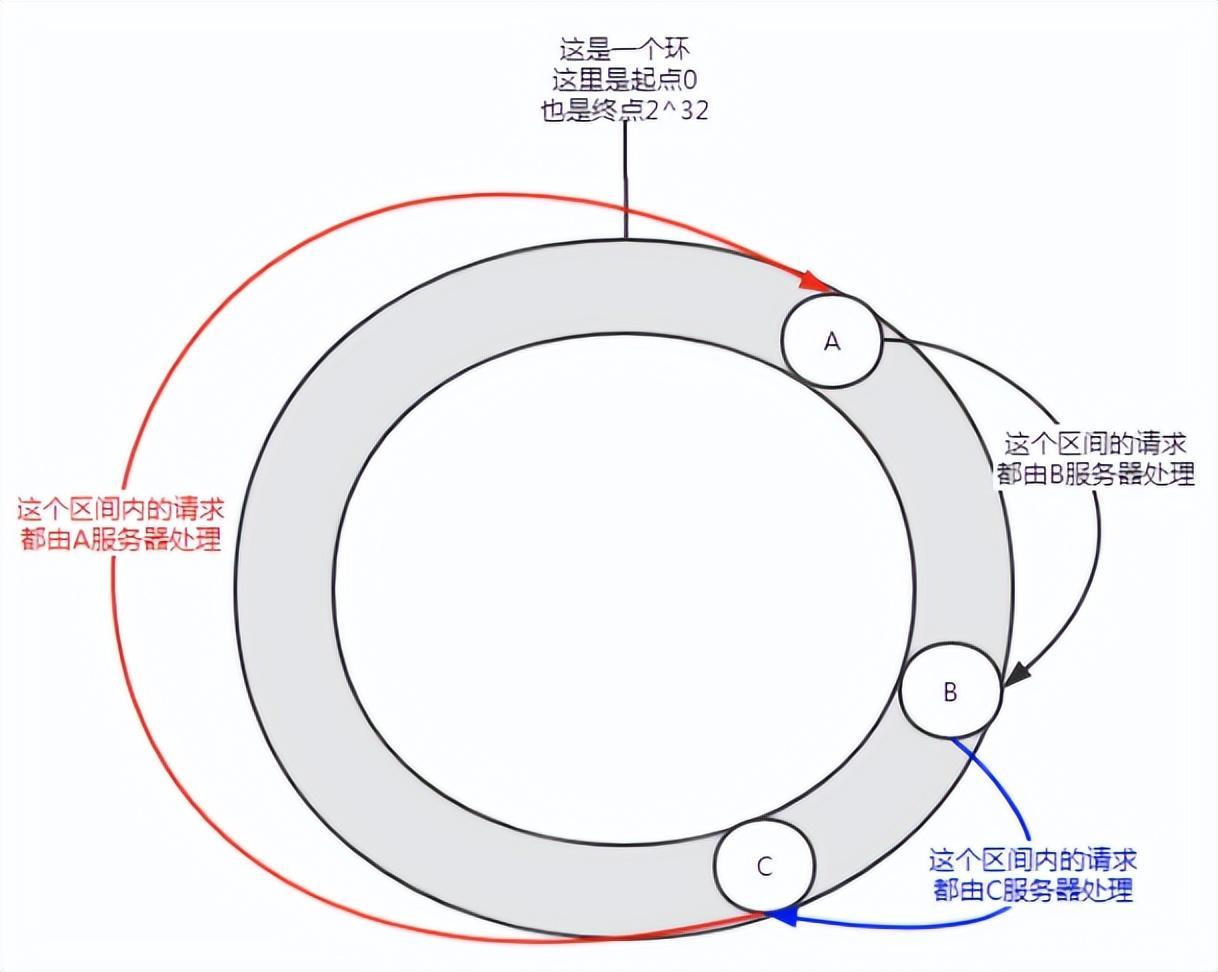
Abbildung 5 Datenversatz
Wenn nur wenige Knoten vorhanden sind, kann eine solche Verteilung auftreten, und Dienst A wird die meisten Anforderungen bewältigen. Diese Situation wird als Datenversatz bezeichnet.
Wie lässt sich also das Problem der Datenverzerrung lösen?
Treten Sie virtuellen Knoten bei.
Erstens kann ein Server je nach Bedarf mehrere virtuelle Knoten haben. Angenommen, ein Server verfügt über n virtuelle Knoten. Bei einer Hash-Berechnung kann eine Kombination aus IP-Adresse, Portnummer und Nummer zur Berechnung des Hash-Werts verwendet werden. Die Zahl ist eine Zahl von 0 bis n. Diese n Knoten verweisen alle auf denselben Computer, da sie dieselbe IP-Adresse und Portnummer haben.
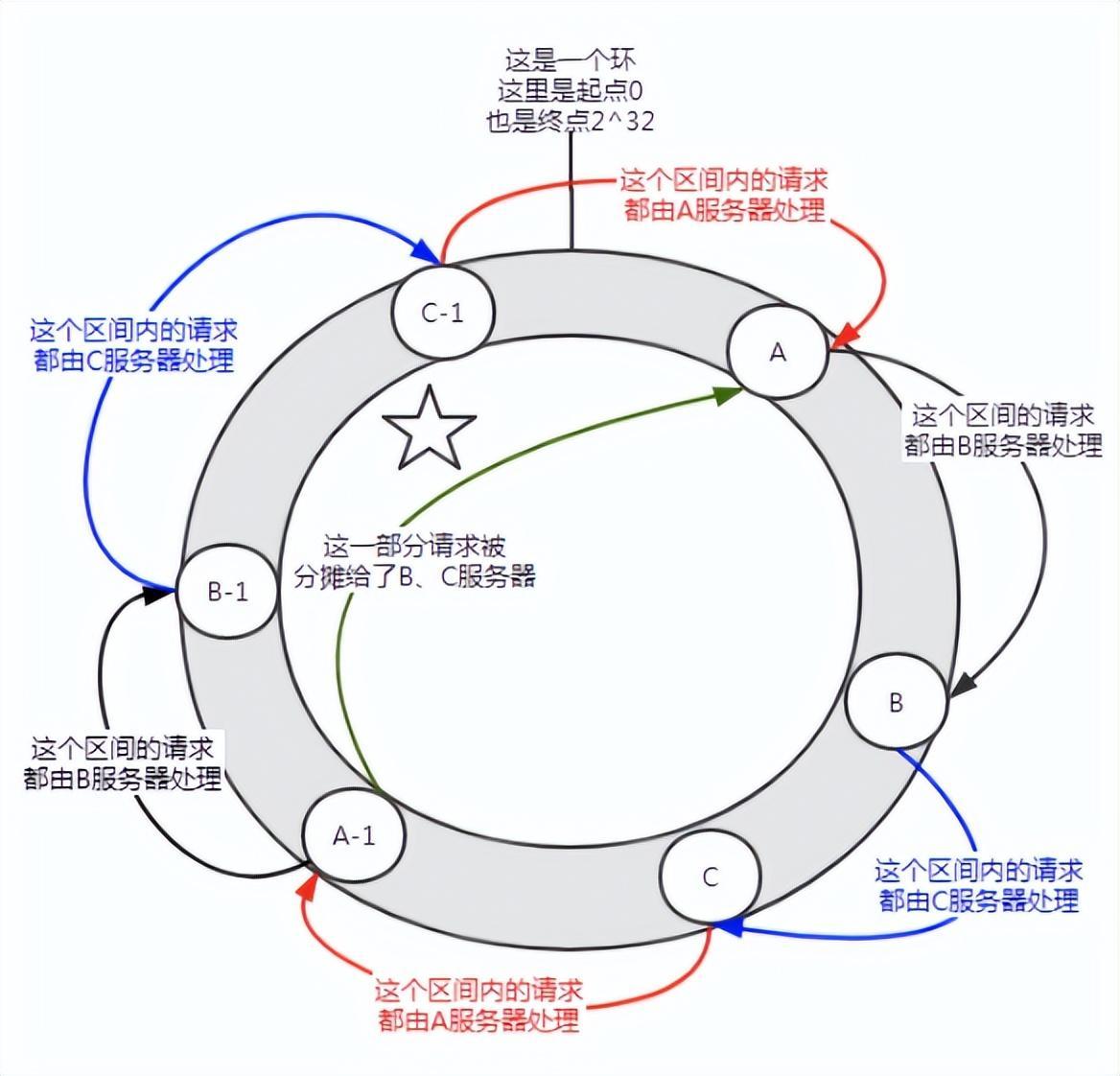
Abbildung 6 Einführung virtueller Knoten
Vor dem Hinzufügen virtueller Knoten verarbeitete Server A die überwiegende Mehrheit der Anfragen. Wenn jeder Server einen virtuellen Knoten (A-1, B-1, C-1) hat und durch Hash-Berechnung dem in der Abbildung oben gezeigten Standort zugewiesen wird. Dann werden die von Server A durchgeführten Anforderungen bis zu einem gewissen Grad den virtuellen Knoten B-1 und C-1 zugewiesen (der Teil, der in der Abbildung mit einem fünfzackigen Stern markiert ist), der tatsächlich den Servern B und C zugewiesen ist.
Im konsistenten Hash-Algorithmus kann das Hinzufügen virtueller Knoten das Problem der Datenverzerrung lösen.
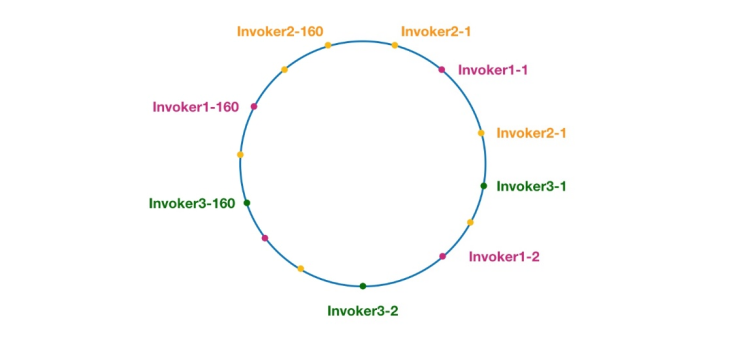
Abbildung 7 Konsistenter Hashing-Ring in Dubbo
Knoten mit derselben Farbe gehören hier alle zum selben Dienstanbieter, wie Invoker1-1, Invoker1-2,…, Aufrufer1-160. Durch das Hinzufügen virtueller Knoten können wir den Invoker über den Hash-Ring verteilen und so das Problem der Datenverzerrung vermeiden. Der sogenannte Datenversatz bezieht sich auf die Situation, in der eine große Anzahl von Anfragen auf denselben Knoten fällt, weil die Knoten nicht weit genug verteilt sind, während andere Knoten nur eine kleine Anzahl von Anfragen erhalten. Zum Beispiel:
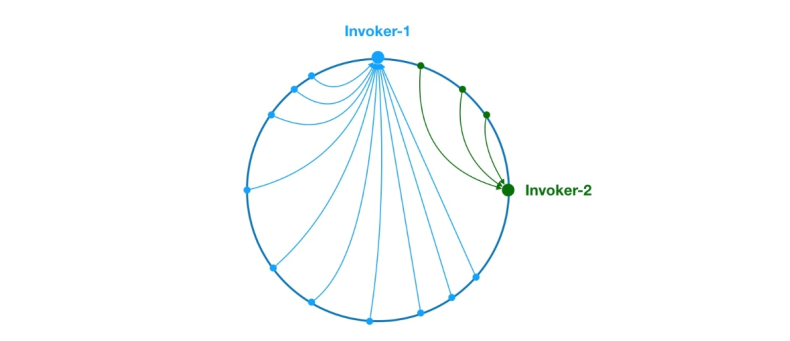
Abbildung 8 Datenversatzproblem
Wie oben fallen aufgrund der ungleichmäßigen Verteilung von Invoker-1 und Invoker-2 im Ring 75 % der Anforderungen im System an Invoker-1. und nur 25 % Die Anfrage wird auf Invoker-2 fallen. Um dieses Problem zu lösen, können virtuelle Knoten eingeführt werden, um das Anforderungsvolumen jedes Knotens auszugleichen.
Da nun das Hintergrundwissen verbreitet ist, beginnen wir mit der Analyse des Quellcodes. Beginnen wir mit der doSelect-Methode von ConsistentHashLoadBalance wie folgt:
public class ConsistentHashLoadBalance extends AbstractLoadBalance {private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;// 获取 invokers 原始的 hashcodeint identityHashCode = System.identityHashCode(invokers);ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if (selector == null || selector.identityHashCode != identityHashCode) {// 创建新的 ConsistentHashSelectorselectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));selector = (ConsistentHashSelector<T>) selectors.get(key);}// 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturn selector.select(invocation);}private static final class ConsistentHashSelector<T> {...}}Wie oben führt die doSelect-Methode hauptsächlich einige vorbereitende Arbeiten durch, z. B. das Erkennen, ob sich die Aufruferliste geändert hat, und das Erstellen eines ConsistentHashSelector. Nachdem diese Aufgaben abgeschlossen sind, wird die Auswahlmethode von ConsistentHashSelector aufgerufen, um die Lastausgleichslogik auszuführen. Bevor wir die Auswahlmethode analysieren, werfen wir zunächst einen Blick auf den Initialisierungsprozess des konsistenten Hash-Selektors ConsistentHashSelector wie folgt:
private static final class ConsistentHashSelector<T> {// 使用 TreeMap 存储 Invoker 虚拟节点private final TreeMap<Long, Invoker<T>> virtualInvokers;private final int replicaNumber;private final int identityHashCode;private final int[] argumentIndex;ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {this.virtualInvokers = new TreeMap<Long, Invoker<T>>();this.identityHashCode = identityHashCode;URL url = invokers.get(0).getUrl();// 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);// 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));argumentIndex = new int[index.length];for (int i = 0; i < index.length; i++) {argumentIndex[i] = Integer.parseInt(index[i]);}for (Invoker<T> invoker : invokers) {String address = invoker.getUrl().getAddress();for (int i = 0; i < replicaNumber / 4; i++) {// 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i);// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for (int h = 0; h < 4; h++) {// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上long m = hash(digest, h);// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}}ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。注意到 ConsistentHashLoadBalance 无需考虑权重的影响。
在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点 hash 值,并将虚拟节点存储到 TreeMap 中。ConsistentHashSelector的初始化工作在此完成。接下来,我们来看看 select 方法的逻辑。
public Invoker<T> select(Invocation invocation) {// 将参数转为 keyString key = toKey(invocation.getArguments());// 对参数 key 进行 md5 运算byte[] digest = md5(key);// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,// 寻找合适的 Invokerreturn selectForKey(hash(digest, 0));}private Invoker<T> selectForKey(long hash) {// 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头节点赋值给 entryif (entry == null) {entry = virtualInvokers.firstEntry();}// 返回 Invokerreturn entry.getValue();}如上,选择的过程相对比较简单了。首先,需要对参数进行 md5 和 hash 运算,以生成一个哈希值。接着使用这个值去 TreeMap 中查找需要的 Invoker。
到此关于 ConsistentHashLoadBalance 就分析完了。
在阅读 ConsistentHashLoadBalance 源码之前,建议读者先补充背景知识,不然看懂代码逻辑会有很大难度。
作者:京东物流 乔杰
来源:京东云开发者社区
Das obige ist der detaillierte Inhalt vonKonsistentes Hashing der Dubbo-Lastausgleichsstrategie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist der Unterschied zwischen Dubbo und Zookeeper?
Was ist der Unterschied zwischen Dubbo und Zookeeper?
 Was sind die Unterschiede zwischen Springcloud und Dubbo?
Was sind die Unterschiede zwischen Springcloud und Dubbo?
 Was ist das Prinzip und der Mechanismus von Dubbo?
Was ist das Prinzip und der Mechanismus von Dubbo?
 Die Rolle von Cortana in Windows 10
Die Rolle von Cortana in Windows 10
 Linux finden
Linux finden
 So stellen Sie mit vb eine Verbindung zur Datenbank her
So stellen Sie mit vb eine Verbindung zur Datenbank her
 Fotoanzeigezeit
Fotoanzeigezeit
 Verwendung mit linearem Gradienten
Verwendung mit linearem Gradienten








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



