
 Technologie-Peripheriegeräte
KI
Basierend auf der Kalibrierungstechnologie der Informationstheorie macht CML multimodales maschinelles Lernen zuverlässiger
Technologie-Peripheriegeräte
KI
Basierend auf der Kalibrierungstechnologie der Informationstheorie macht CML multimodales maschinelles Lernen zuverlässiger
Basierend auf der Kalibrierungstechnologie der Informationstheorie macht CML multimodales maschinelles Lernen zuverlässiger

Multimodales maschinelles Lernen hat in verschiedenen Szenarien beeindruckende Fortschritte gemacht. Zur Zuverlässigkeit multimodaler Lernmodelle mangelt es jedoch an eingehender Forschung. „Information ist die Beseitigung von Unsicherheit.“ Die ursprüngliche Absicht des multimodalen maschinellen Lernens steht im Einklang damit – zusätzliche Modalitäten können Vorhersagen genauer und zuverlässiger machen. Das kürzlich in ICML2023 veröffentlichte Papier „Calibrating Multimodal Learning“ stellte jedoch fest, dass aktuelle multimodale Lernmethoden diese Zuverlässigkeitsannahme verletzen, und führte detaillierte Analysen und Korrekturen durch.
 Bilder
Bilder
- Papier Arxiv: https://arxiv.org/abs/2306.01265
- Code GitHub: https://github.com /Q ingyangZhang/CML
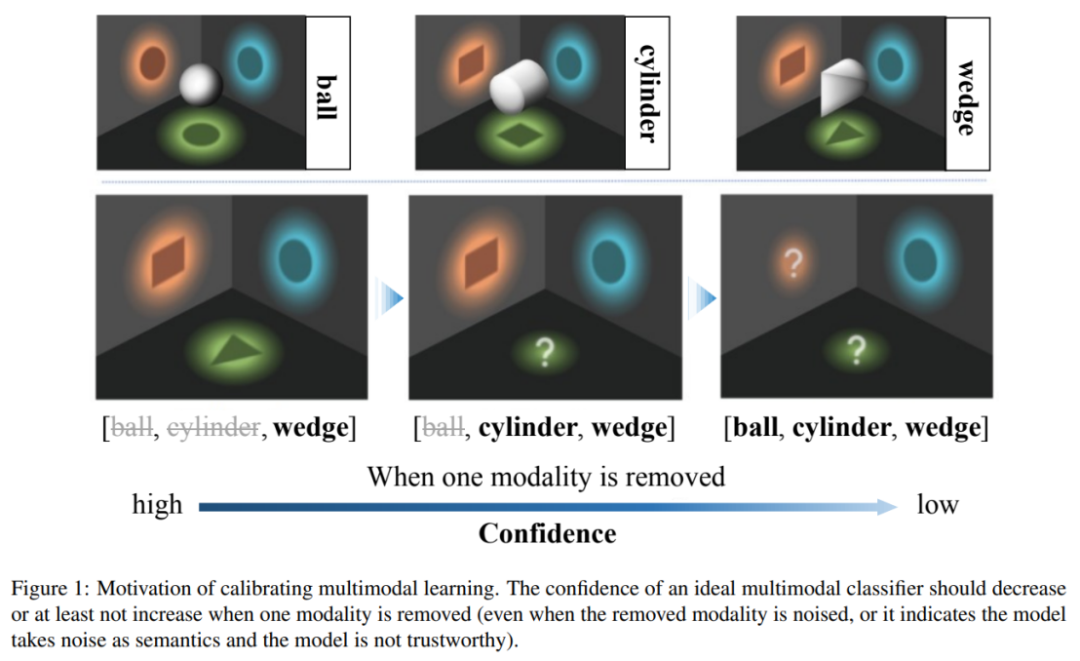
Die aktuelle multimodale Klassifizierungsmethode weist ein unzuverlässiges Vertrauen auf, das heißt, wenn einige Modi entfernt werden, kann das Modell ein höheres Vertrauen erzeugen, was gegen die Informationstheorie „Informationen wird eliminiert“ verstößt das Grundprinzip. Um dieses Problem anzugehen, schlägt dieser Artikel die Methode „Kalibrierendes multimodales Lernen“ vor. Diese Methode kann in verschiedenen multimodalen Lernparadigmen eingesetzt werden, um die Rationalität und Glaubwürdigkeit multimodaler Lernmodelle zu verbessern.
 Bilder
Bilder
Diese Arbeit weist darauf hin, dass aktuelle multimodale Lernmethoden unzuverlässige Probleme mit der Vorhersagesicherheit haben und bestehende multimodale Modelle für maschinelles Lernen dazu neigen, sich auf Teilmodalitäten zu verlassen, um die Zuverlässigkeit abzuschätzen. Die Studie ergab insbesondere, dass die Zuverlässigkeit aktueller Modellschätzungen zunimmt, wenn bestimmte Modi beschädigt werden. Um dieses unvernünftige Problem zu lösen, schlagen die Autoren ein intuitives multimodales Lernprinzip vor: Wenn die Modalität entfernt wird, sollte die Zuverlässigkeit der Modellvorhersage nicht zunehmen. Aktuelle Modelle tendieren jedoch dazu, eine Teilmenge von Modalitäten zu glauben und von dieser beeinflusst zu werden, anstatt alle Modalitäten fair zu berücksichtigen. Dies wirkt sich weiter auf die Robustheit des Modells aus, d. h. das Modell wird leicht beeinträchtigt, wenn bestimmte Modi beschädigt werden.
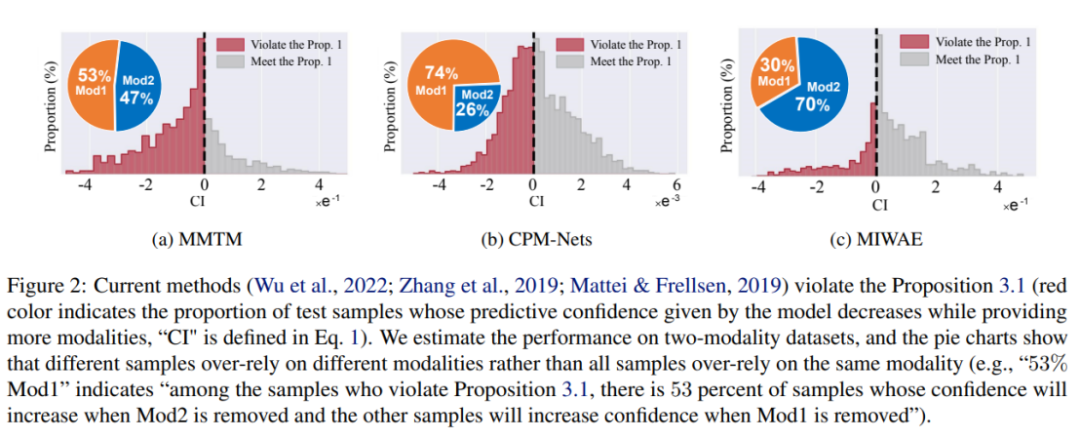
Um die oben genannten Probleme zu lösen, übernehmen einige Methoden derzeit bestehende Methoden zur Unsicherheitskalibrierung, wie z. B. Temperaturskalierung oder Bayes'sche Lernmethoden. Diese Methoden können genauere Konfidenzschätzungen erstellen als herkömmliche Trainings-/Inferenzmethoden. Diese Methoden gleichen jedoch nur die Konfidenzschätzung des endgültigen Fusionsergebnisses mit der Genauigkeit ab und berücksichtigen nicht explizit die Beziehung zwischen der modalen Informationsmenge und der Konfidenz. Daher können sie die Glaubwürdigkeit des multimodalen Lernmodells nicht wesentlich verbessern.
Der Autor schlägt eine neue Regularisierungstechnik namens „Calibrating Multimodal Learning (CML)“ vor. Diese Technik erzwingt die Übereinstimmungsbeziehung zwischen der Zuverlässigkeit der Modellvorhersage und dem Informationsgehalt, indem ein Strafterm hinzugefügt wird, um Konsistenz zwischen der Zuverlässigkeit der Vorhersage und dem Informationsgehalt zu erreichen. Diese Technik basiert auf der natürlichen Intuition, dass die Vorhersagesicherheit abnehmen sollte (zumindest nicht zunehmen), wenn eine Modalität entfernt wird, was von Natur aus die Vertrauenskalibrierung verbessern kann. Insbesondere wird ein einfacher Regularisierungsterm vorgeschlagen, um das Modell zum Erlernen einer intuitiven Ordnungsbeziehung zu zwingen, indem den Stichproben, deren Vorhersagesicherheit zunimmt, wenn eine Modalität entfernt wird, eine Strafe hinzugefügt wird:

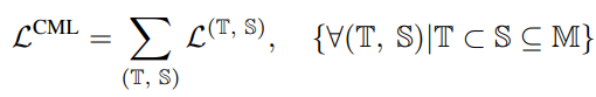
Die obige Einschränkung ist a Regelmäßiger Verlust, der als Nachteil erscheint, wenn Modalinformationen entfernt werden und das Vertrauen steigt.
Experimentelle Ergebnisse zeigen, dass die CML-Regularisierung die Zuverlässigkeit der Vorhersagesicherheit bestehender multimodaler Lernmethoden erheblich verbessern kann. Darüber hinaus kann CML die Klassifizierungsgenauigkeit und die Robustheit des Modells verbessern.
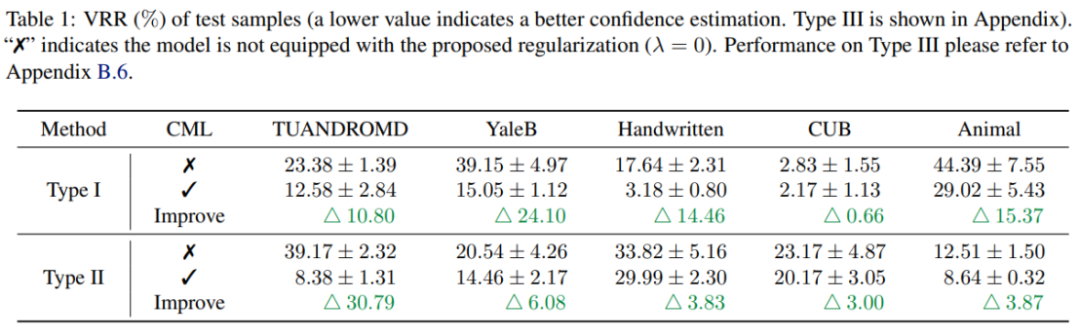
Multimodales maschinelles Lernen hat in verschiedenen Szenarien erhebliche Fortschritte gemacht, aber die Zuverlässigkeit multimodaler maschineller Lernmodelle ist immer noch ein Problem, das gelöst werden muss. Durch umfangreiche empirische Forschung kommt dieser Artikel zu dem Schluss, dass aktuelle multimodale Klassifizierungsmethoden das Problem einer unzuverlässigen Vorhersagesicherheit haben und gegen die Prinzipien der Informationstheorie verstoßen. Um dieses Problem anzugehen, schlugen die Forscher die CML-Regularisierungstechnik vor, die flexibel auf bestehende Modelle angewendet werden kann und die Leistung in Bezug auf Vertrauenskalibrierung, Klassifizierungsgenauigkeit und Modellrobustheit verbessert. Man geht davon aus, dass diese neue Technologie eine wichtige Rolle beim künftigen multimodalen Lernen spielen und die Zuverlässigkeit und Praktikabilität des maschinellen Lernens verbessern wird.
Das obige ist der detaillierte Inhalt vonBasierend auf der Kalibrierungstechnologie der Informationstheorie macht CML multimodales maschinelles Lernen zuverlässiger. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
