
 Technologie-Peripheriegeräte
KI
Auch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.
Technologie-Peripheriegeräte
KI
Auch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.
Auch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.

Generative KI hat die Community der künstlichen Intelligenz im Sturm erobert. Sowohl Einzelpersonen als auch Unternehmen sind daran interessiert, entsprechende modale Konvertierungsanwendungen wie Vincent-Bilder, Vincent-Videos, Vincent-Musik usw. zu erstellen.
Vor kurzem haben mehrere Forscher von wissenschaftlichen Forschungseinrichtungen wie ServiceNow Research und LIVIA versucht, Diagramme in Aufsätzen basierend auf Textbeschreibungen zu erstellen. Zu diesem Zweck schlugen sie eine neue Methode von FigGen vor, und das zugehörige Papier wurde auch als Tiny Paper in ICLR 2023 aufgenommen.
 Bilder
Bilder
Papieradresse: https://arxiv.org/pdf/2306.00800.pdf
Manche Leute fragen sich vielleicht: Was ist so schwierig daran, die Diagramme in dem Papier zu erstellen? Wie hilft dies der wissenschaftlichen Forschung?
Die Generierung wissenschaftlicher Forschungsdiagramme trägt dazu bei, Forschungsergebnisse prägnant und leicht verständlich zu verbreiten, und die automatische Generierung von Diagrammen kann Forschern viele Vorteile bringen, wie z . Darüber hinaus kann die Gestaltung optisch ansprechender und leicht verständlicher Abbildungen das Papier für mehr Menschen zugänglich machen.
Die Erstellung von Diagrammen ist jedoch auch mit einigen Herausforderungen verbunden. Sie müssen komplexe Beziehungen zwischen einzelnen Komponenten wie Kästchen, Pfeilen, Text usw. darstellen. Im Gegensatz zur Generierung natürlicher Bilder können Konzepte in Papierdiagrammen unterschiedliche Darstellungen haben und ein detailliertes Verständnis erfordern. Beispielsweise ist die Generierung eines neuronalen Netzwerkdiagramms mit einem schlecht gestellten Problem mit hoher Varianz verbunden.
Daher trainierten die Forscher in diesem Artikel ein generatives Modell anhand eines Datensatzes von Papierdiagrammpaaren, um die Beziehung zwischen Diagrammkomponenten und dem entsprechenden Text im Artikel zu erfassen. Dies erfordert den Umgang mit unterschiedlichen Längen und hochtechnischen Textbeschreibungen, unterschiedlichen Diagrammstilen, Bildseitenverhältnissen sowie Schriftarten, -größen und Ausrichtungsproblemen bei der Textwiedergabe.
Während des spezifischen Implementierungsprozesses ließen sich die Forscher von aktuellen Text-zu-Bild-Ergebnissen inspirieren und verwendeten das Diffusionsmodell zur Generierung von Diagrammen. Sie schlugen ein potenzielles Diffusionsmodell zur Generierung wissenschaftlicher Forschungsdiagramme aus Textbeschreibungen vor – FigGen.
Was sind die einzigartigen Merkmale dieses Diffusionsmodells? Kommen wir zu den Details.
Modelle und Methoden
Die Forscher trainierten ein latentes Diffusionsmodell von Grund auf.
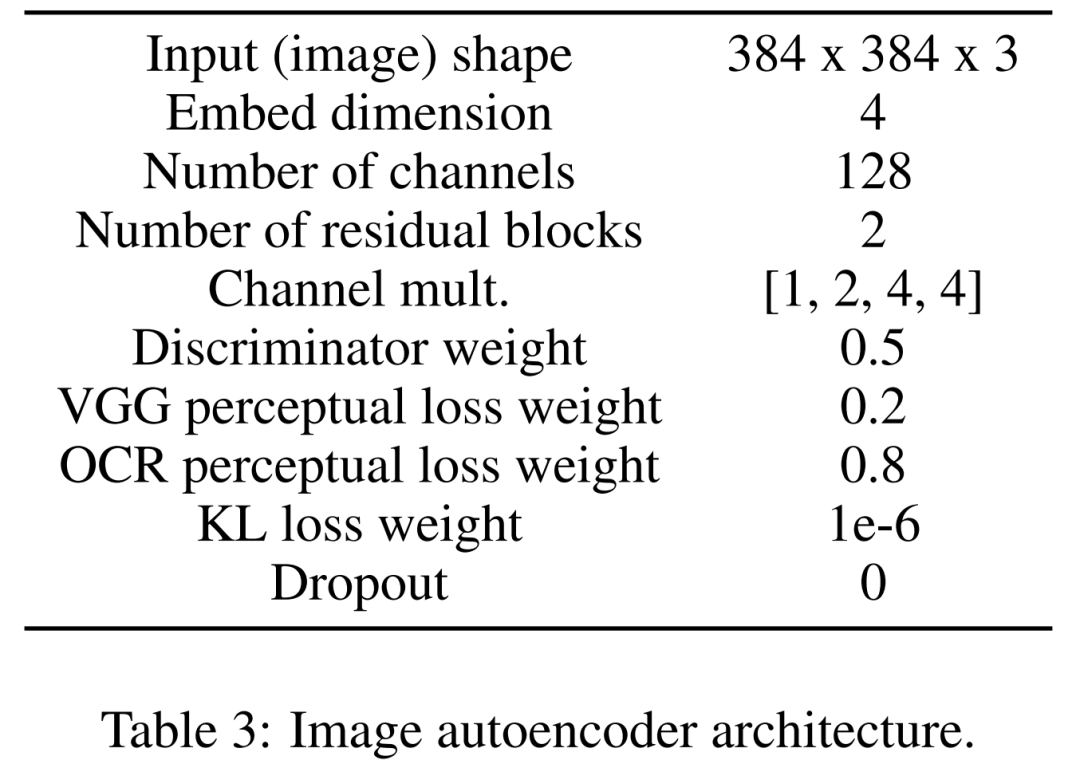
Erlernen Sie zunächst einen Bild-Autoencoder, um Bilder in komprimierte latente Darstellungen abzubilden. Der Bildencoder nutzt KL-Verlust und OCR-Wahrnehmungsverlust. Der zur Konditionierung verwendete Textkodierer wird im Training dieses Diffusionsmodells durchgängig erlernt. Tabelle 3 unten zeigt die detaillierten Parameter der Bild-Autoencoder-Architektur.
Das Diffusionsmodell interagiert dann direkt im latenten Raum und führt eine datenbeschädigte Vorwärtsplanung durch, während es lernt, die zeitliche und textliche bedingte Entrauschung von U-Net zu nutzen, um den Prozess wiederherzustellen.
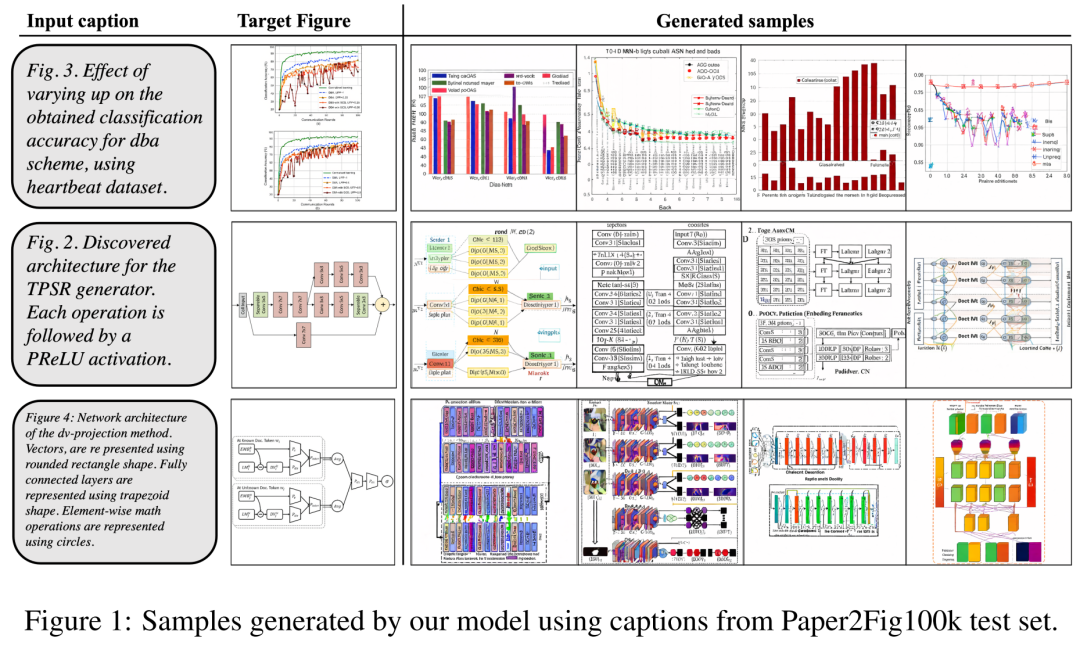
Als Datensatz verwendeten die Forscher Paper2Fig100k, das aus Diagramm-Text-Paaren im Papier besteht und 81.194 Trainingsbeispiele und 21.259 Validierungsbeispiele enthält. Abbildung 1 unten ist ein Beispiel für ein Diagramm, das mithilfe von Textbeschreibungen im Testsatz Paper2Fig100k erstellt wurde.
Modelldetails
Zuerst ist der Bildencoder. In der ersten Stufe lernt der Bild-Autoencoder eine Zuordnung vom Pixelraum zur komprimierten latenten Darstellung, wodurch das Training des Diffusionsmodells beschleunigt wird. Der Bildencoder muss auch lernen, das zugrunde liegende Bild wieder dem Pixelraum zuzuordnen, ohne wichtige Details des Diagramms (z. B. die Qualität der Textwiedergabe) zu verlieren.
Zu diesem Zweck haben die Forscher einen Faltungscodec mit einem Engpass definiert, der das Bild mit dem Faktor f=8 heruntersampelt. Der Encoder ist darauf trainiert, KL-Verluste, VGG-bewusste Verluste und OCR-bewusste Verluste mit Gauß-Verteilung zu minimieren.
Zweitens ist der Text-Encoder. Forscher haben herausgefunden, dass Allzweck-Textencoder für Aufgaben zur Diagrammerstellung nicht geeignet sind. Daher definieren sie einen von Grund auf im Diffusionsprozess trainierten Bert-Transformator, der einen Einbettungskanal der Größe 512 verwendet, der auch die Einbettungsgröße ist, die die Queraufmerksamkeitsschicht von U-Net reguliert. Die Forscher untersuchten auch Veränderungen in der Anzahl der Transformatorschichten unter verschiedenen Einstellungen (8, 32 und 128).
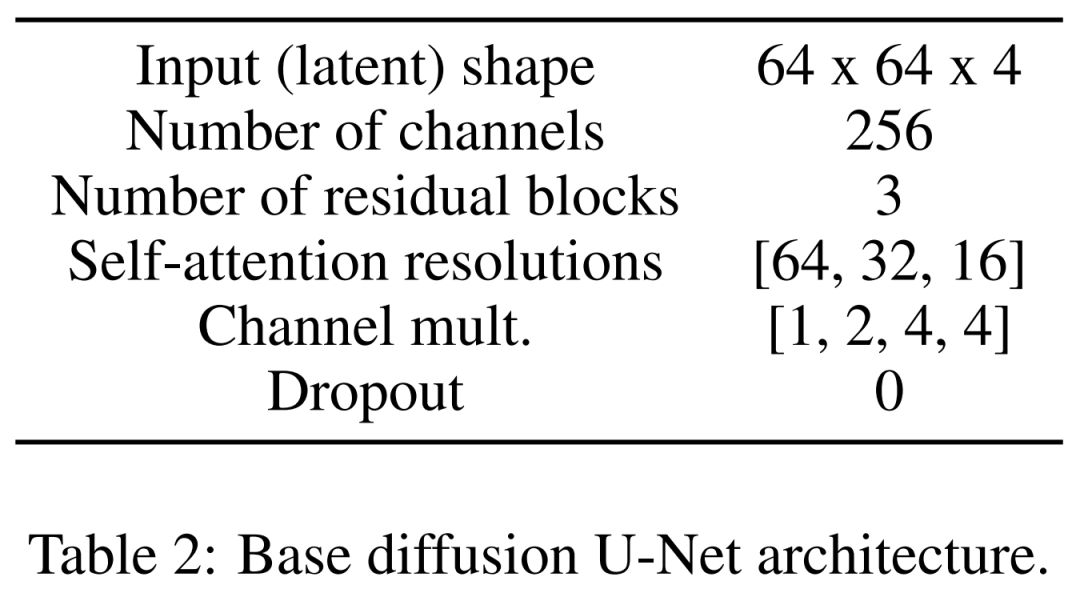
Das letzte ist das latente Diffusionsmodell. Tabelle 2 unten zeigt die Netzwerkarchitektur von U-Net. Wir führen den Diffusionsprozess an einer wahrnehmungsmäßig äquivalenten latenten Darstellung des Bildes durch, wobei die Eingabegröße des Bildes auf 64 x 64 x 4 komprimiert wird, wodurch das Diffusionsmodell schneller wird. Sie definierten 1.000 Diffusionsschritte und eine lineare Geräuschplanung.
Trainingsdetails
Um den Bild-Autoencoder zu trainieren, verwendeten die Forscher einen Adam-Optimierer mit einer effektiven Stapelgröße von 4 Proben und einer Lernrate von 4,5e −6 wobei vier 12GB NVIDIA V100 Grafikkarten zum Einsatz kamen. Um Trainingsstabilität zu erreichen, wärmen sie das Modell in 50.000 Iterationen auf, ohne den Diskriminator zu verwenden.
Zum Training des latenten Diffusionsmodells verwendeten die Forscher auch den Adam-Optimierer, der eine effektive Stapelgröße von 32 und eine Lernrate von 1e−4 hat. Beim Training des Modells mit dem Paper2Fig100k-Datensatz verwendeten sie acht 80-GB-NVIDIA-A100-Grafikkarten.
Experimentelle Ergebnisse
Während des Generierungsprozesses verwendeten die Forscher einen DDIM-Sampler mit 200 Schritten und generierten 12.000 Proben für jedes Modell, um FID, IS, KID und OCR-SIM1 zu berechnen. Robuster Einsatz von Classifier-Free Guidance (CFG) zum Testen von Hyperkonditionierung.
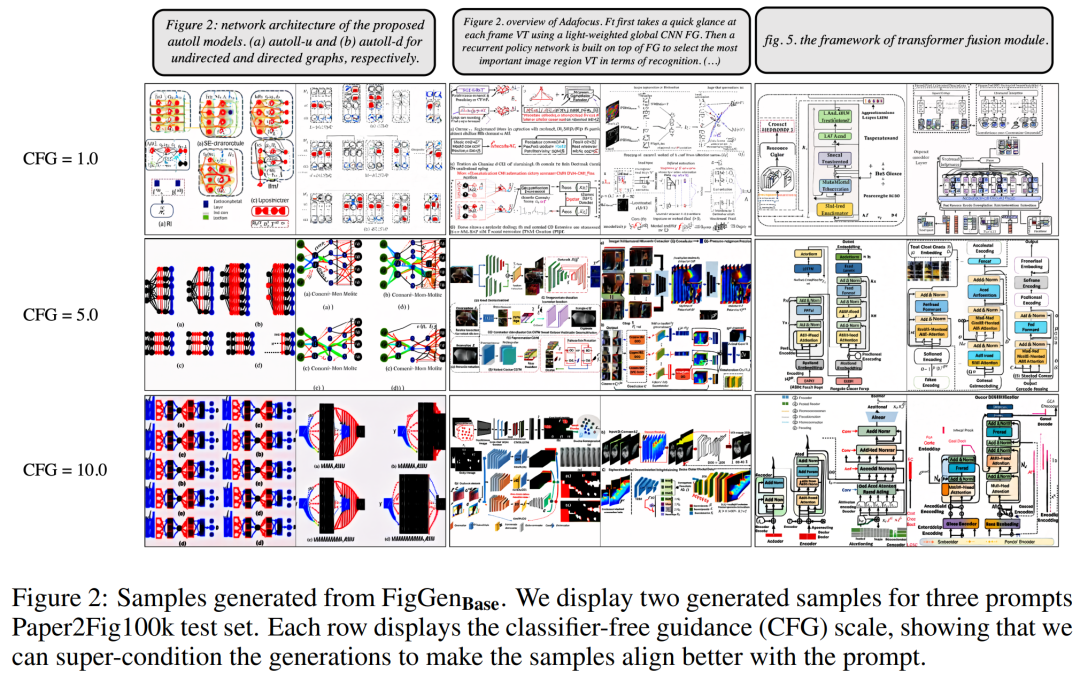
Tabelle 1 unten zeigt die Ergebnisse verschiedener Text-Encoder. Es ist ersichtlich, dass Encoder für große Texte die besten qualitativen Ergebnisse liefern und die Bedingungsgenerierung durch Erhöhen der Größe des CFG verbessert werden kann. Obwohl qualitative Proben nicht von ausreichender Qualität sind, um das Problem zu lösen, hat FigGen die Beziehung zwischen Text und Bildern erfasst.
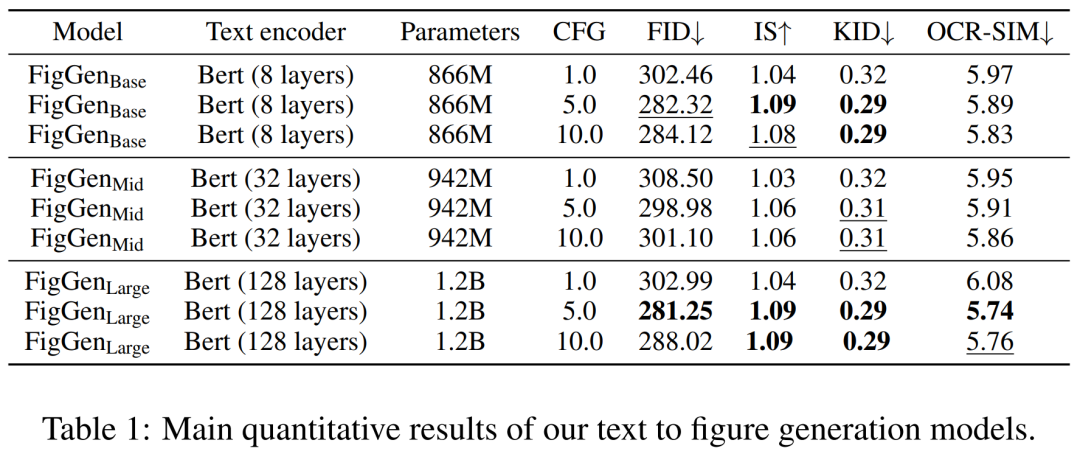
Abbildung 2 unten zeigt die zusätzlichen FigGen-Beispiele, die beim Anpassen der Classifier Free Guidance (CFG)-Parameter generiert werden. Die Forscher beobachteten, dass eine Vergrößerung des CFG, die auch quantitativ nachgewiesen werden konnte, zu einer Verbesserung der Bildqualität führte.
 Bilder
Bilder
Abbildung 3 unten zeigt weitere Generationsbeispiele von FigGen. Achten Sie auf die Längenunterschiede zwischen den Beispielen sowie auf das technische Niveau der Textbeschreibung, da dies einen großen Einfluss auf die Schwierigkeit des Modells hat, verständliche Bilder korrekt zu erzeugen.
 Bilder
Bilder
Die Forscher gaben jedoch auch zu, dass diese generierten Diagramme den Autoren des Papiers zwar keine praktische Hilfe bieten können, sie aber dennoch eine vielversprechende Richtung darstellen, die es zu erkunden gilt.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonAuch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
 Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Die Syntax zum Hinzufügen von Spalten in SQL ist Alter table table_name add column_name data_type [nicht null] [Standard default_value]; Wenn table_name der Tabellenname ist, ist Column_Name der neue Spaltenname, Data_Type ist der Datentyp, nicht null Gibt an, ob Nullwerte zulässig sind, und Standard Standard_Value gibt den Standardwert an.
 SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
Tipps zur Verbesserung der SQL -Tabellenlösungsleistung: Verwenden Sie die Truncate -Tabelle anstelle des Löschens, löschen Sie den Speicherplatz und setzen Sie die Identitätsspalte zurück. Deaktivieren Sie fremde Schlüsselbeschränkungen, um die Kaskadierung der Löschung zu verhindern. Verwenden Sie Transaktionskapselungsvorgänge, um die Datenkonsistenz sicherzustellen. Batch löschen Big Data und begrenzen Sie die Anzahl der Zeilen durch die Grenze. Bauen Sie den Index nach dem Löschen neu auf, um die Effizienz der Abfrage zu verbessern.
 So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
Legen Sie den Standardwert für neu hinzugefügte Spalten fest, verwenden Sie die Anweisung für die Änderung der Tabelle: Hinzufügen von Spalten angeben und den Standardwert: Alter Table table_name hinzufügen column_name data_type Standard default_value; Verwenden Sie die Einschränkungsklausel, um den Standardwert anzugeben: Alter Table Table_Name add Column_Name Data_type Einschränkung default_constraint default default_value;
 Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Ja, mit der Anweisung Löschen kann eine SQL -Tabelle gelöscht werden. TABLE_NAME ERSETZEN AUS DER NAME DER TABELLE, DIE DELDET.
 Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Redis -Gedächtnisfragmentierung bezieht sich auf die Existenz kleiner freier Bereiche in dem zugewiesenen Gedächtnis, die nicht neu zugewiesen werden können. Zu den Bewältigungsstrategien gehören: Neustart von Redis: Der Gedächtnis vollständig löschen, aber den Service unterbrechen. Datenstrukturen optimieren: Verwenden Sie eine Struktur, die für Redis besser geeignet ist, um die Anzahl der Speicherzuweisungen und -freisetzungen zu verringern. Konfigurationsparameter anpassen: Verwenden Sie die Richtlinie, um die kürzlich verwendeten Schlüsselwertpaare zu beseitigen. Verwenden Sie den Persistenzmechanismus: Daten regelmäßig sichern und Redis neu starten, um Fragmente zu beseitigen. Überwachen Sie die Speicherverwendung: Entdecken Sie die Probleme rechtzeitig und ergreifen Sie Maßnahmen.
 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
 Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Eine effektive Überwachung von Redis -Datenbanken ist entscheidend für die Aufrechterhaltung einer optimalen Leistung, die Identifizierung potenzieller Engpässe und die Gewährleistung der Zuverlässigkeit des Gesamtsystems. Redis Exporteur Service ist ein leistungsstarkes Dienstprogramm zur Überwachung von Redis -Datenbanken mithilfe von Prometheus. In diesem Tutorial führt Sie die vollständige Setup und Konfiguration des Redis -Exporteur -Dienstes, um sicherzustellen, dass Sie nahtlos Überwachungslösungen erstellen. Durch das Studium dieses Tutorials erhalten Sie voll funktionsfähige Überwachungseinstellungen
