
 Technologie-Peripheriegeräte
KI
Das große Modell der Alpaka-Familie entwickelt sich gemeinsam weiter! 32k-Kontext entspricht GPT-4, erstellt vom Team von Tian Yuandong
Technologie-Peripheriegeräte
KI
Das große Modell der Alpaka-Familie entwickelt sich gemeinsam weiter! 32k-Kontext entspricht GPT-4, erstellt vom Team von Tian Yuandong
Das große Modell der Alpaka-Familie entwickelt sich gemeinsam weiter! 32k-Kontext entspricht GPT-4, erstellt vom Team von Tian Yuandong

Der Open-Source-Alpaka-Großmodell-LLaMA-Kontext entspricht GPT-4, mit nur einer einfachen Änderung!
Dieses gerade von Meta AI eingereichte Papier zeigt, dass weniger als 1000 Feinabstimmungsschritte erforderlich sind, nachdem das LLaMA-Kontextfenster von 2k auf 32k erweitert wurde.
Die Kosten sind im Vergleich zum Vortraining vernachlässigbar.

Das Erweitern des Kontextfensters bedeutet, dass die „Arbeitsgedächtnis“-Kapazität der KI erhöht wird. Konkret kann sie:
- Mehr Dialogrunden unterstützen und das Vergessen reduzieren, z. B. ein stabileres Rollenspiel.
- Mehr eingeben Daten können komplexere Aufgaben erledigen, wie zum Beispiel die Verarbeitung längerer Dokumente oder mehrerer Dokumente gleichzeitig
Die wichtigere Bedeutung ist, dass alle großen Alpaka-Modellfamilien, die auf LLaMA basieren, diese Methode zu geringen Kosten übernehmen und sich gemeinsam weiterentwickeln können?
Alpaca ist derzeit das umfassendste Open-Source-Basismodell und hat viele vollständig kommerziell verfügbare Open-Source-Großmodelle und vertikale Industriemodelle abgeleitet.
Auch Tian Yuandong, der korrespondierende Autor des Papiers, teilte diese neue Entwicklung begeistert in seinem Freundeskreis.
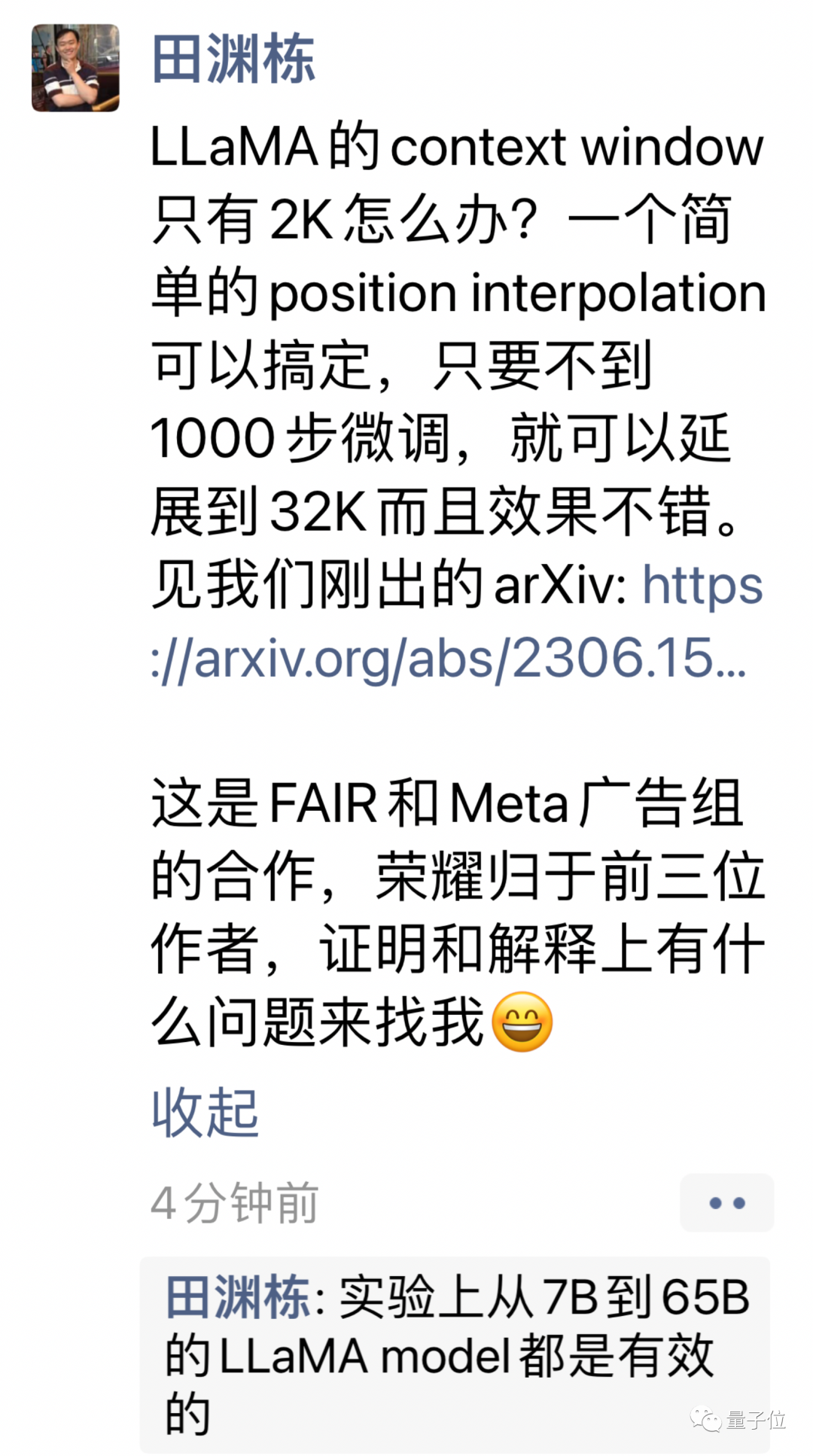
Alle großen Modelle, die auf RoPE basieren, können verwendet werden.
Die neue Methode heißt Positionsinterpolation und eignet sich für große Modelle, die RoPE (Rotationspositionskodierung) verwenden.
RoPE wurde bereits 2021 vom Team von Zhuiyi Technology vorgeschlagen und hat sich mittlerweile zu einer der gebräuchlichsten Methoden zur Positionskodierung für große Modelle entwickelt.

Aber die direkte Verwendung der Extrapolation zur Erweiterung des Kontextfensters unter dieser Architektur wird den Selbstaufmerksamkeitsmechanismus vollständig zerstören.
Insbesondere der Teil, der über die Länge des vorab trainierten Kontexts hinausgeht, führt dazu, dass die Ratlosigkeit des Modells auf das gleiche Niveau ansteigt wie bei einem untrainierten Modell.
Die neue Methode wurde geändert, um den Positionsindex linear zu verkleinern, die Bereichsausrichtung des vorderen und hinteren Positionsindex und den relativen Abstand zu erweitern.

Es ist intuitiver, Bilder zu verwenden, um den Unterschied zwischen den beiden auszudrücken.
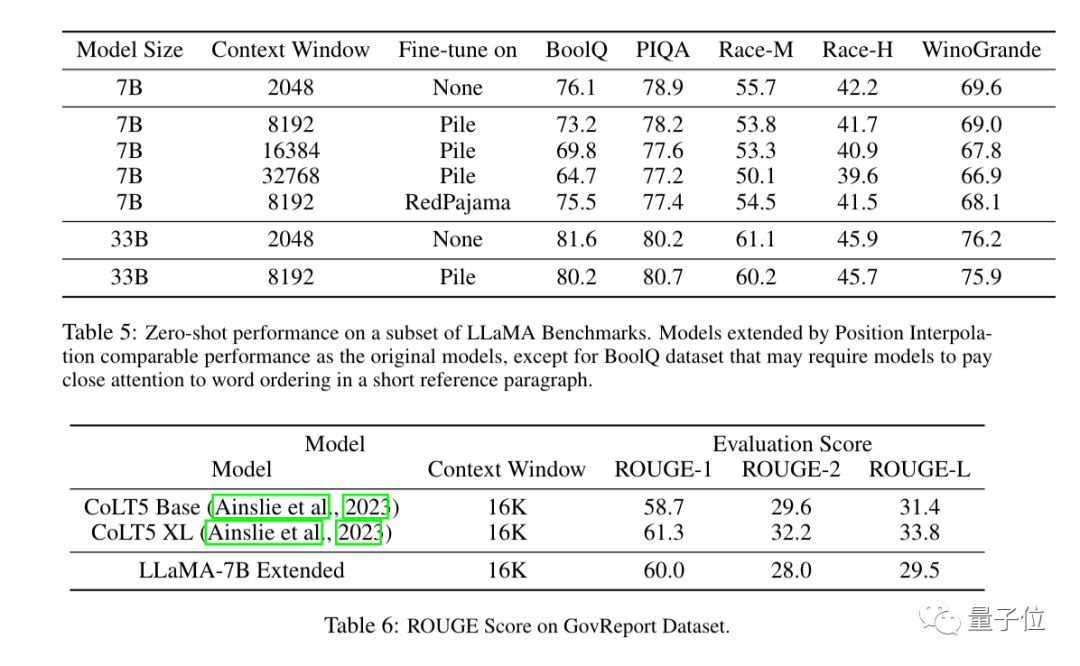
Experimentelle Ergebnisse zeigen, dass die neue Methode für LLaMA-Großmodelle von 7B bis 65B wirksam ist.
Bei der Langsequenz-Sprachmodellierung, dem Passkey-Abruf und der Zusammenfassung langer Dokumente gibt es keine nennenswerten Leistungseinbußen.
Neben Experimenten findet sich im Anhang der Arbeit auch ein ausführlicher Nachweis der neuen Methode.
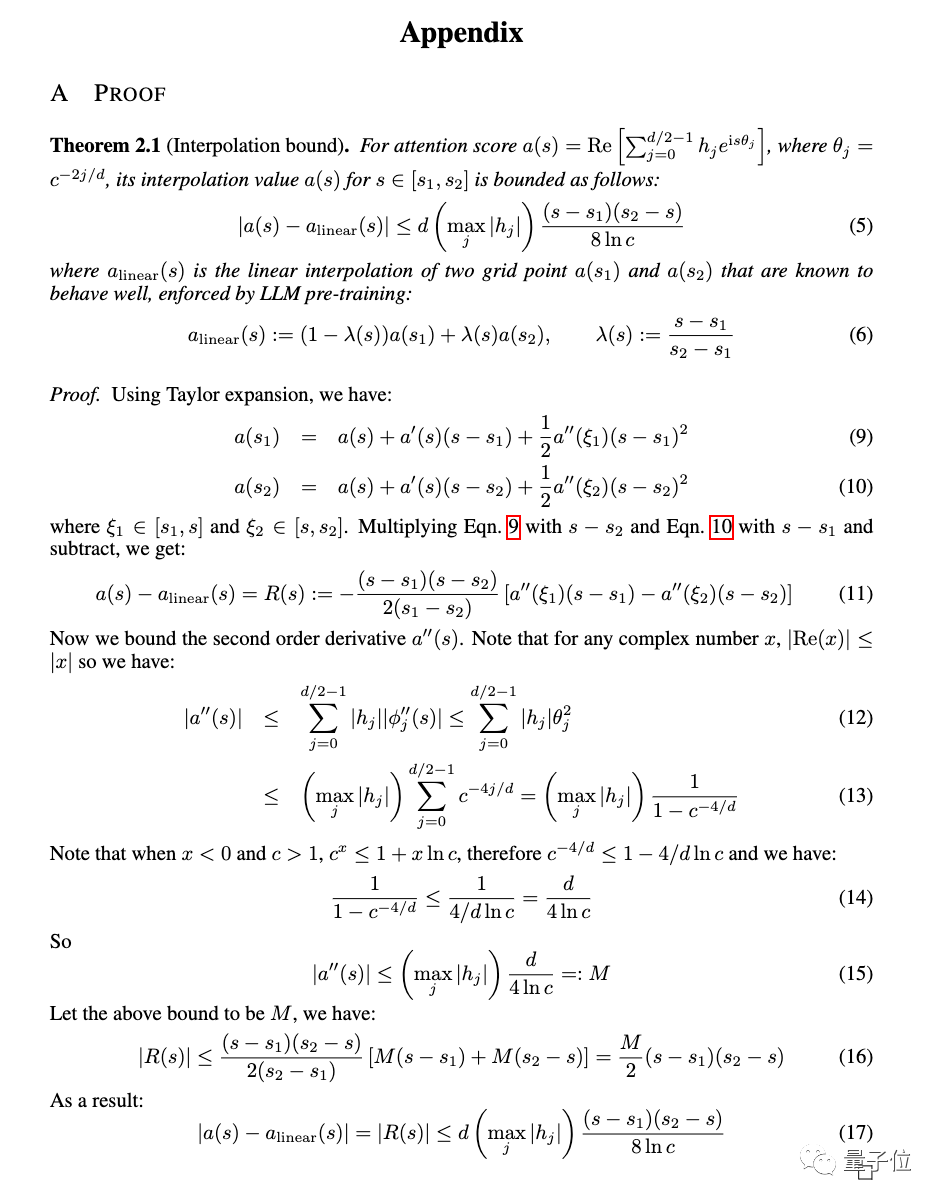
Three More Thing
Das Kontextfenster war früher eine wichtige Lücke zwischen Open-Source-Großmodellen und kommerziellen Großmodellen.
Zum Beispiel unterstützt GPT-3.5 von OpenAI bis zu 16.000, GPT-4 unterstützt 32.000 und Claude von AnthropicAI unterstützt bis zu 100.000.
Gleichzeitig stecken viele Open-Source-Großmodelle wie LLaMA und Falcon immer noch bei 2k fest.
Jetzt haben die neuen Ergebnisse von Meta AI diese Lücke direkt geschlossen.
Die Erweiterung des Kontextfensters ist auch einer der Schwerpunkte der jüngsten Großmodellforschung. Neben Positionsinterpolationsmethoden gibt es viele Versuche, die Aufmerksamkeit der Industrie auf sich zu ziehen.
1. Entwickler Kaiokendev hat in einem technischen Blog eine Methode zur Erweiterung des LLaMa-Kontextfensters auf 8k untersucht.
2. Galina Alperovich, Leiterin für maschinelles Lernen beim Datensicherheitsunternehmen Soveren, hat in einem Artikel 6 Tipps zum Erweitern des Kontextfensters zusammengefasst.

3. Teams von Mila, IBM und anderen Institutionen haben in einem Artikel auch versucht, die Positionskodierung in Transformer vollständig zu entfernen.伴 Wenn Sie es benötigen, können Sie auf den Link unten klicken, um ~ anzuzeigen TPS:/ /www.php.cn/link/9659078925b57e621eb3f9ef19773ac3
 Das Geheimnis hinter dem 100K-Kontextfenster in
Das Geheimnis hinter dem 100K-Kontextfenster in
https:/ /www.php.cn/link/fb6c84779f12283a81d739d8f088fc12
Das obige ist der detaillierte Inhalt vonDas große Modell der Alpaka-Familie entwickelt sich gemeinsam weiter! 32k-Kontext entspricht GPT-4, erstellt vom Team von Tian Yuandong. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 Mithilfe der Shengteng-KI-Technologie hilft das Qinling·Qinchuan-Transportmodell Xi'an beim Aufbau eines intelligenten Transportinnovationszentrums
Oct 15, 2023 am 08:17 AM
Mithilfe der Shengteng-KI-Technologie hilft das Qinling·Qinchuan-Transportmodell Xi'an beim Aufbau eines intelligenten Transportinnovationszentrums
Oct 15, 2023 am 08:17 AM
„Hohe Komplexität, hohe Fragmentierung und Cross-Domain“ waren schon immer die Hauptprobleme auf dem Weg zur digitalen und intelligenten Modernisierung der Transportbranche. Kürzlich ist das „Qinling·Qinchuan Traffic Model“ mit einer Parameterskala von 100 Milliarden, das gemeinsam von China Science Vision, der Bezirksregierung Xi'an Yanta und dem Xi'an Future Artificial Intelligence Computing Center entwickelt wurde, auf den Bereich des intelligenten Transports ausgerichtet und bietet Dienstleistungen für Xi'an und die umliegenden Gebiete. Die Region wird ein Dreh- und Angelpunkt für intelligente Transportinnovationen sein. Das „Qinling·Qinchuan Traffic Model“ kombiniert Xi'ans umfangreiche lokale verkehrsökologische Daten in offenen Szenarien, den ursprünglich von China Science Vision unabhängig entwickelten fortschrittlichen Algorithmus und die leistungsstarke Rechenleistung der Shengteng AI des Xi'an Future Artificial Intelligence Computing Center Überwachung des Straßennetzes, intelligente Transportszenarien wie Notfallkommando, Wartungsmanagement und öffentlicher Verkehr führen zu digitalen und intelligenten Veränderungen. Das Verkehrsmanagement weist in verschiedenen Städten und auf verschiedenen Straßen unterschiedliche Merkmale auf
 Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Produktpositionierung von TensorRT-LLM TensorRT-LLM ist eine von NVIDIA entwickelte skalierbare Inferenzlösung für große Sprachmodelle (LLM). Es erstellt, kompiliert und führt Berechnungsdiagramme auf der Grundlage des TensorRT-Deep-Learning-Kompilierungsframeworks aus und stützt sich auf die effiziente Kernels-Implementierung in FastTransformer. Darüber hinaus nutzt es NCCL für die Kommunikation zwischen Geräten. Entwickler können Betreiber entsprechend der Technologieentwicklung und Nachfrageunterschieden an spezifische Anforderungen anpassen, beispielsweise durch die Entwicklung maßgeschneiderter GEMM auf Basis von Entermessern. TensorRT-LLM ist die offizielle Inferenzlösung von NVIDIA, die sich der Bereitstellung hoher Leistung und der kontinuierlichen Verbesserung ihrer Praktikabilität verschrieben hat. TensorRT-LL
 Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Laut Nachrichten vom 4. April hat die Cyberspace Administration of China kürzlich eine Liste registrierter großer Modelle veröffentlicht, in der das „Jiutian Natural Language Interaction Large Model“ von China Mobile enthalten ist, was darauf hinweist, dass das große Jiutian AI-Modell von China Mobile offiziell generative künstliche Intelligenz bereitstellen kann Geheimdienste nach außen. China Mobile gab an, dass dies das erste groß angelegte Modell sei, das von einem zentralen Unternehmen entwickelt wurde und sowohl die nationale Doppelregistrierung „Generative Artificial Intelligence Service Registration“ als auch die „Domestic Deep Synthetic Service Algorithm Registration“ bestanden habe. Berichten zufolge zeichnet sich Jiutians großes Modell für die Interaktion mit natürlicher Sprache durch verbesserte Branchenfähigkeiten, Sicherheit und Glaubwürdigkeit aus und unterstützt die vollständige Lokalisierung. Es hat mehrere Parameterversionen wie 9 Milliarden, 13,9 Milliarden, 57 Milliarden und 100 Milliarden gebildet. und kann flexibel in der Cloud eingesetzt werden, Edge und End sind unterschiedliche Situationen
 Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Wenn die Testfragen zu einfach sind, können sowohl Spitzenschüler als auch schlechte Schüler 90 Punkte erreichen, und der Abstand kann nicht vergrößert werden ... Mit der Veröffentlichung stärkerer Modelle wie Claude3, Llama3 und später sogar GPT-5 ist die Branche in Bewegung Dringender Bedarf an einem schwierigeren und differenzierteren Benchmark-Modell. LMSYS, die Organisation hinter der großen Modellarena, brachte den Benchmark der nächsten Generation, Arena-Hard, auf den Markt, der große Aufmerksamkeit erregte. Es gibt auch die neueste Referenz zur Stärke der beiden fein abgestimmten Versionen der Llama3-Anweisungen. Im Vergleich zu MTBench, das zuvor ähnliche Ergebnisse erzielte, stieg die Arena-Hard-Diskriminierung von 22,6 % auf 87,4 %, was auf den ersten Blick stärker und schwächer ist. Arena-Hard basiert auf menschlichen Echtzeitdaten aus der Arena und seine Übereinstimmungsrate mit menschlichen Vorlieben liegt bei bis zu 89,1 %.
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Laut Nachrichten vom 13. Juni hat Xiaomis Assistent für künstliche Intelligenz „Xiao Ai“ laut Bytes öffentlichem Bericht „Volcano Engine“ eine Zusammenarbeit mit Volcano Engine erzielt. Die beiden Parteien werden ein intelligenteres interaktives KI-Erlebnis auf der Grundlage des großen Beanbao-Modells erzielen . Berichten zufolge kann das von ByteDance erstellte groß angelegte Beanbao-Modell bis zu 120 Milliarden Text-Tokens effizient verarbeiten und täglich 30 Millionen Inhalte generieren. Xiaomi nutzte das große Doubao-Modell, um die Lern- und Denkfähigkeiten seines eigenen Modells zu verbessern und einen neuen „Xiao Ai Classmate“ zu schaffen, der nicht nur die Benutzerbedürfnisse genauer erfasst, sondern auch eine schnellere Reaktionsgeschwindigkeit und umfassendere Inhaltsdienste bietet. Wenn ein Benutzer beispielsweise nach einem komplexen wissenschaftlichen Konzept fragt, &ldq
