
 Java
javaLernprogramm
So lösen Sie das Problem der hohen Speichernutzung beim XML-Parsing in der Java-Entwicklung
Java
javaLernprogramm
So lösen Sie das Problem der hohen Speichernutzung beim XML-Parsing in der Java-Entwicklung
So lösen Sie das Problem der hohen Speichernutzung beim XML-Parsing in der Java-Entwicklung

XML ist ein häufig verwendetes Datenaustauschformat. In der Java-Entwicklung müssen häufig große XML-Dateien analysiert werden. Da XML-Dateien jedoch oft eine große Anzahl an Knoten und Elementen enthalten, können herkömmliche XML-Parsing-Methoden leicht zu einer hohen Speichernutzung führen. In diesem Artikel werden einige Methoden vorgestellt, um das Problem der hohen Speichernutzung beim XML-Parsen zu lösen.
- SAX-Parser verwenden
SAX (Simple API for XML) ist eine ereignisgesteuerte XML-Parsing-Methode. Im Vergleich zur DOM-Analysemethode (Document Object Model) lädt der SAX-Parser beim Parsen von XML nicht das gesamte XML-Dokument in den Speicher, sondern liest beim Parsen den XML-Inhalt. Dadurch kann die Speichernutzung erheblich reduziert werden.
Der Prozess zum Parsen von XML mit SAX ist wie folgt:
- Erstellen Sie ein SAX-Parser-Objekt.
- Ereignisbehandlungsmethoden neu schreiben, einschließlich Startdokument, Elementstart, Elementende und anderen Ereignissen.
- Parsen Sie die XML-Datei über das Parser-Objekt. Wenn der Parser das entsprechende Ereignis liest, wird die entsprechende Ereignisverarbeitungsmethode ausgelöst.
- StAX-Parser verwenden
StAX (Streaming API for XML) ist ebenfalls eine ereignisgesteuerte XML-Parsing-Methode, ähnlich wie SAX, jedoch mit einer einfacheren API. Der StAX-Parser kann beim Parsen auch XML-Inhalte lesen, um den Speicherverbrauch zu reduzieren.
Der Prozess zum Parsen von XML mit StAX ist wie folgt:
- Erstellen Sie ein StAX-Parser-Objekt.
- Schleife zum Lesen von Ereignissen in XML-Dateien, einschließlich Startelement, Endelement, Elementtext und anderen Ereignissen.
- Führen Sie entsprechende Vorgänge entsprechend verschiedenen Ereignistypen aus.
- Inkrementelles Parsen verwenden
Inkrementelles Parsen ist eine Möglichkeit, eine XML-Datei zum Parsen in kleine Teile aufzuteilen. Inkrementelles Parsen reduziert den Speicherverbrauch im Vergleich zum Laden der gesamten XML-Datei auf einmal.
Der Prozess der inkrementellen Analyse ist wie folgt:
- Erstellen Sie ein inkrementelles Parser-Objekt.
- Legen Sie die Eingabequelle des Parsers fest, bei der es sich um eine Datei, einen Eingabestream usw. handeln kann.
- Schleife, um die Analyseergebnisse des Parsers zu erhalten, dh jeden analysierten Block und den Typ des Blocks.
- Führen Sie je nach Blocktyp den entsprechenden Vorgang aus.
- Verwenden Sie Komprimierungstechnologie
Bei besonders großen XML-Dateien können Sie den Einsatz von Komprimierungstechnologie in Betracht ziehen, um den von ihnen belegten Speicherplatz zu reduzieren. Java bietet eine Vielzahl von Komprimierungs- und Dekomprimierungsalgorithmen wie gzip, zip usw.
Der Prozess der Verwendung der Komprimierungstechnologie ist wie folgt:
- Komprimieren Sie die XML-Datei und generieren Sie die entsprechende komprimierte Datei.
- Entpacken Sie beim Parsen von XML zunächst die komprimierte Datei und führen Sie dann den Parsing-Vorgang durch.
Zusammenfassung:
Um in der Java-Entwicklung das Problem der übermäßigen Speichernutzung beim XML-Parsen zu lösen, können ereignisgesteuerte Methoden wie SAX und StAX zum Parsen verwendet werden, um die Speichernutzung zu reduzieren. Gleichzeitig kann der Einsatz der inkrementellen Analyse- und Komprimierungstechnologie auch den Speicherverbrauch effektiv reduzieren. In der tatsächlichen Entwicklung kann die Auswahl der geeigneten Analysemethode entsprechend den spezifischen Anforderungen und Szenarien das Problem der übermäßigen Speichernutzung bei der XML-Analyse besser lösen.
Das obige ist der detaillierte Inhalt vonSo lösen Sie das Problem der hohen Speichernutzung beim XML-Parsing in der Java-Entwicklung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
1. Öffnen Sie Xiaohongshu, klicken Sie unten rechts auf „Ich“. 2. Klicken Sie auf das Einstellungssymbol und dann auf „Allgemein“. 3. Klicken Sie auf „Cache leeren“.
 Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Unzureichender Speicher auf Huawei-Mobiltelefonen ist mit der Zunahme mobiler Anwendungen und Mediendateien zu einem häufigen Problem geworden, mit dem viele Benutzer konfrontiert sind. Um Benutzern zu helfen, den Speicherplatz ihres Mobiltelefons voll auszunutzen, werden in diesem Artikel einige praktische Methoden vorgestellt, um das Problem des unzureichenden Speichers auf Huawei-Mobiltelefonen zu lösen. 1. Cache bereinigen: Verlaufsdatensätze und ungültige Daten, um Speicherplatz freizugeben und von Anwendungen generierte temporäre Dateien zu löschen. Suchen Sie in den Huawei-Telefoneinstellungen nach „Speicher“, klicken Sie auf die Schaltfläche „Cache löschen“ und löschen Sie dann die Cache-Dateien der Anwendung. 2. Deinstallieren Sie selten verwendete Anwendungen: Um Speicherplatz freizugeben, löschen Sie einige selten verwendete Anwendungen. Ziehen Sie es an den oberen Rand des Telefonbildschirms, drücken Sie lange auf das Symbol „Deinstallieren“ der Anwendung, die Sie löschen möchten, und klicken Sie dann auf die Bestätigungsschaltfläche, um die Deinstallation abzuschließen. 3.Mobile Anwendung auf
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zunächst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. Wählen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schließen oder deinstallieren Sie als Nächstes die Plug-Ins, die Sie nicht benötigen.
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
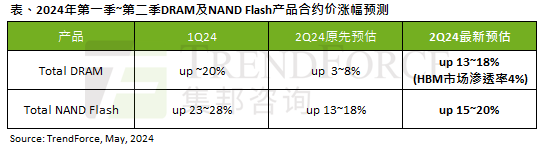 Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Die Auswirkungen der KI-Welle sind offensichtlich. TrendForce hat seine Prognose für Preiserhöhungen bei DRAM-Speicher und NAND-Flash-Speicher in diesem Quartal nach oben korrigiert.
May 07, 2024 pm 09:58 PM
Laut einem TrendForce-Umfragebericht hat die KI-Welle erhebliche Auswirkungen auf die Märkte für DRAM-Speicher und NAND-Flash-Speicher. In den Nachrichten dieser Website vom 7. Mai sagte TrendForce heute in seinem neuesten Forschungsbericht, dass die Agentur die Vertragspreiserhöhungen für zwei Arten von Speicherprodukten in diesem Quartal erhöht habe. Konkret schätzte TrendForce ursprünglich, dass der DRAM-Speichervertragspreis im zweiten Quartal 2024 um 3 bis 8 % steigen wird, und schätzt ihn nun auf 13 bis 18 %, bezogen auf NAND-Flash-Speicher, die ursprüngliche Schätzung wird um 13 bis 18 % steigen 18 %, und die neue Schätzung liegt bei 15 %, nur eMMC/UFS weist einen geringeren Anstieg von 10 % auf. ▲Bildquelle TrendForce TrendForce gab an, dass die Agentur ursprünglich damit gerechnet hatte, dies auch weiterhin zu tun
 C++-Programmoptimierung: Techniken zur Reduzierung der Zeitkomplexität
Jun 01, 2024 am 11:19 AM
C++-Programmoptimierung: Techniken zur Reduzierung der Zeitkomplexität
Jun 01, 2024 am 11:19 AM
Die Zeitkomplexität misst die Ausführungszeit eines Algorithmus im Verhältnis zur Größe der Eingabe. Zu den Tipps zur Reduzierung der Zeitkomplexität von C++-Programmen gehören: Auswahl geeigneter Container (z. B. Vektor, Liste) zur Optimierung der Datenspeicherung und -verwaltung. Nutzen Sie effiziente Algorithmen wie die schnelle Sortierung, um die Rechenzeit zu verkürzen. Eliminieren Sie mehrere Vorgänge, um Doppelzählungen zu reduzieren. Verwenden Sie bedingte Verzweigungen, um unnötige Berechnungen zu vermeiden. Optimieren Sie die lineare Suche, indem Sie schnellere Algorithmen wie die binäre Suche verwenden.
 Auf welche Fallstricke sollten wir beim Entwurf verteilter Systeme mit Golang-Technologie achten?
May 07, 2024 pm 12:39 PM
Auf welche Fallstricke sollten wir beim Entwurf verteilter Systeme mit Golang-Technologie achten?
May 07, 2024 pm 12:39 PM
Fallstricke in der Go-Sprache beim Entwurf verteilter Systeme Go ist eine beliebte Sprache für die Entwicklung verteilter Systeme. Allerdings gibt es bei der Verwendung von Go einige Fallstricke zu beachten, die die Robustheit, Leistung und Korrektheit Ihres Systems beeinträchtigen können. In diesem Artikel werden einige häufige Fallstricke untersucht und praktische Beispiele für deren Vermeidung gegeben. 1. Übermäßiger Gebrauch von Parallelität Go ist eine Parallelitätssprache, die Entwickler dazu ermutigt, Goroutinen zu verwenden, um die Parallelität zu erhöhen. Eine übermäßige Nutzung von Parallelität kann jedoch zu Systeminstabilität führen, da zu viele Goroutinen um Ressourcen konkurrieren und einen Mehraufwand beim Kontextwechsel verursachen. Praktischer Fall: Übermäßiger Einsatz von Parallelität führt zu Verzögerungen bei der Dienstantwort und Ressourcenkonkurrenz, was sich in einer hohen CPU-Auslastung und einem hohen Aufwand für die Speicherbereinigung äußert.
