

Neue Forschung des Teams von Tian Yuandong: Feinabstimmung von

Da jeder seine eigenen großen Modelle weiter aktualisiert und iteriert, ist auch die Fähigkeit von LLM (Large Language Model) zur Verarbeitung von Kontextfenstern zu einem wichtigen Bewertungsindikator geworden.
Zum Beispiel bietet der gpt-3.5-turbo von OpenAI eine Kontextfensteroption mit 16.000 Token, und AnthropicAI hat Claudes Token-Verarbeitungskapazität auf 100.000 erhöht. Was ist das Konzept eines großen Modellverarbeitungskontextfensters? GPT-4 unterstützt beispielsweise 32.000 Token, was 50 Seiten Text entspricht, was bedeutet, dass GPT-4 beim Sprechen oder Generieren bis zu 50 Seiten Inhalt speichern kann Text.
Im Allgemeinen ist die Fähigkeit großer Sprachmodelle, mit der Größe des Kontextfensters umzugehen, vorbestimmt. Für das von Meta AI veröffentlichte LLaMA-Modell muss die Größe des Eingabetokens beispielsweise kleiner als 2048 sein.
Allerdings wird bei Anwendungen wie dem Führen langer Gespräche, dem Zusammenfassen langer Dokumente oder dem Ausführen langfristiger Pläne das voreingestellte Kontextfensterlimit häufig überschritten, weshalb LLMs, die längere Kontextfenster verarbeiten können, beliebter sind.
Aber dies steht vor einem neuen Problem. Die Ausbildung eines LLM mit einem langen Kontextfenster von Grund auf erfordert eine Menge Investitionen. Dies führt natürlich zu der Frage: Können wir das Kontextfenster bestehender vorab trainierter LLMs erweitern?
Ein einfacher Ansatz besteht darin, den vorhandenen vorab trainierten Transformer zu optimieren, um ein längeres Kontextfenster zu erhalten. Empirische Ergebnisse zeigen jedoch, dass sich auf diese Weise trainierte Modelle nur sehr langsam an lange Kontextfenster anpassen. Nach 10.000 Trainingschargen ist der Anstieg des effektiven Kontextfensters immer noch sehr gering, nur von 2048 auf 2560 (wie in Tabelle 4 im experimentellen Teil zu sehen ist). Dies deutet darauf hin, dass dieser Ansatz bei der Skalierung auf längere Kontextfenster ineffizient ist.
In diesem Artikel führten Forscher von Meta Position Interpolation (PI) ein, um das Kontextfenster einiger bestehender vorab trainierter LLMs (einschließlich LLaMA) zu erweitern. Die Ergebnisse zeigen, dass das LLaMA-Kontextfenster mit weniger als 1000 Feinabstimmungsschritten von 2k auf 32k skaliert werden kann.
 Bilder
Bilder
Papieradresse: https://arxiv.org/pdf/2306.15595.pdf
Die Schlüsselidee dieser Forschung besteht nicht darin, eine Extrapolation durchzuführen, sondern die Position direkt zu reduzieren index: Stellen Sie sicher, dass der maximale Positionsindex mit dem Kontextfensterlimit der Vortrainingsphase übereinstimmt. Mit anderen Worten: Um mehr Eingabetoken zu berücksichtigen, interpoliert diese Studie Positionskodierungen an benachbarten ganzzahligen Positionen und nutzt dabei die Tatsache aus, dass Positionskodierungen auf nicht ganzzahlige Positionen angewendet werden können, anstatt über die trainierten Positionen hinaus zu extrapolieren. Letzteres kann zu katastrophalen Werten führen.
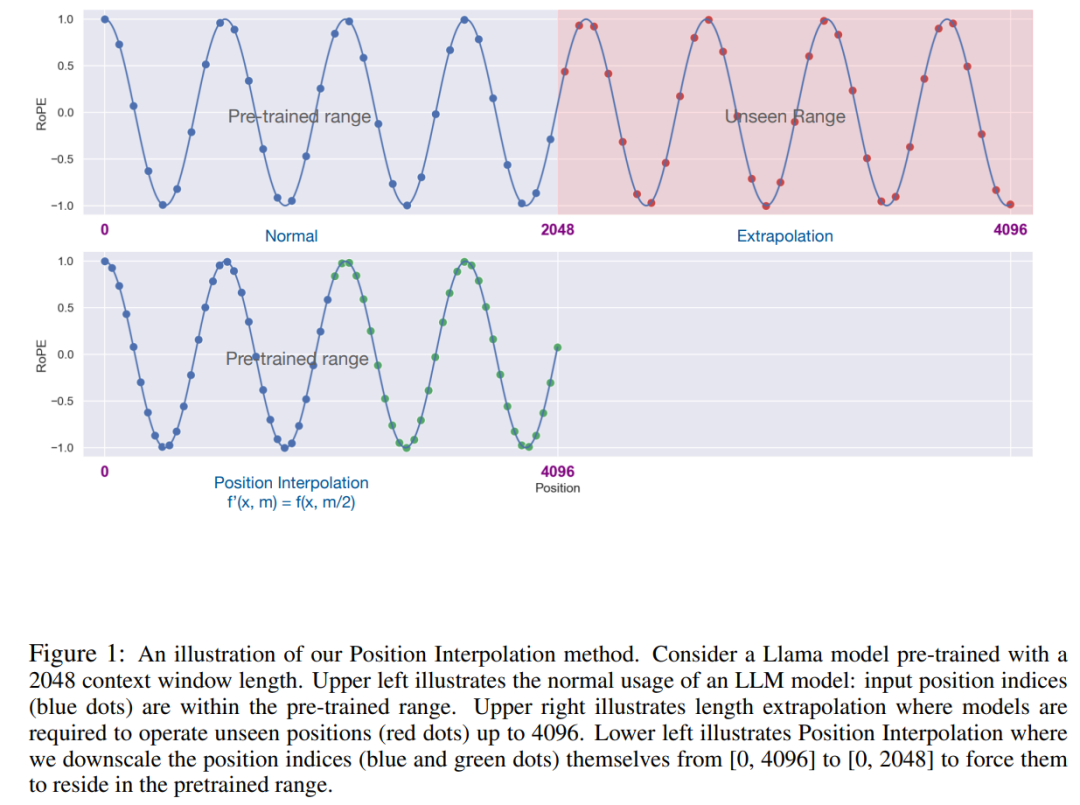
Die PI-Methode erweitert die Kontextfenstergröße von auf RoPE (Rotation Positional Encoding) basierenden vorab trainierten LLM wie LLaMA auf bis zu 32768 mit minimaler Feinabstimmung (innerhalb von 1000 Schritten). Diese Forschung liefert gute Ergebnisse zu einer Vielzahl von Aufgaben, die einen langen Kontext erfordern, einschließlich Retrieval, Sprachmodellierung und Zusammenfassung langer Dokumente von LLaMA 7B bis 65B. Gleichzeitig behält das von PI erweiterte Modell innerhalb seines ursprünglichen Kontextfensters eine relativ gute Qualität bei.
Methode
RoPE ist in großen Sprachmodellen wie LLaMA, ChatGLM-6B und PaLM vorhanden, mit denen wir vertraut sind. Diese Methode wurde von Su Jianlin und anderen von Zhuiyi Technology vorgeschlagen und durch absolute implementiert Kodierung. Relative Positionskodierung.
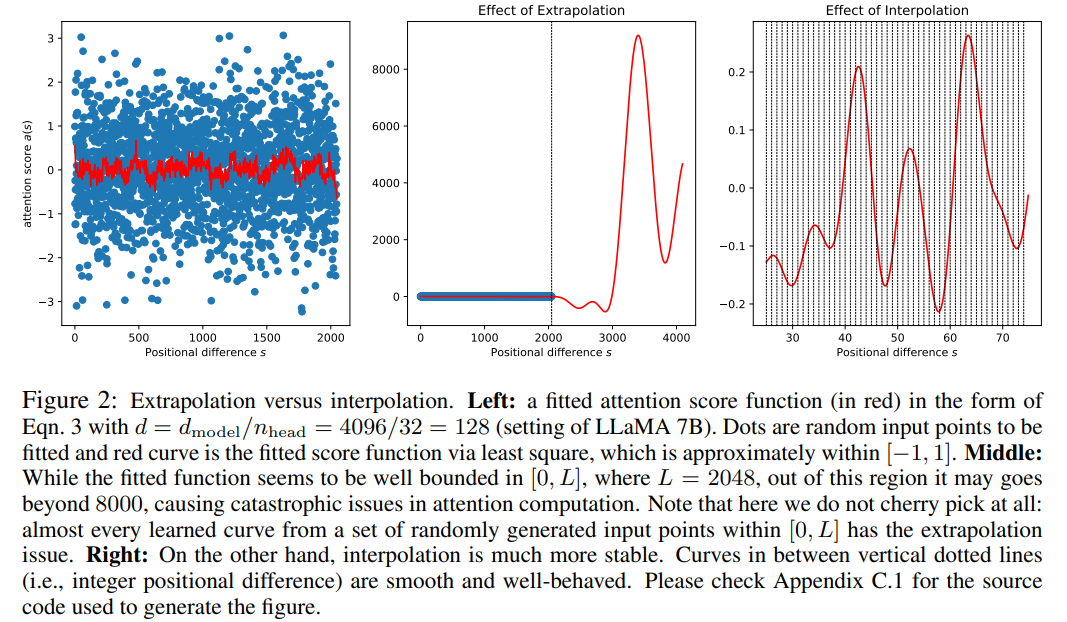
Obwohl der Aufmerksamkeitswert in RoPE nur von der relativen Position abhängt, ist seine Extrapolationsleistung nicht gut. Insbesondere bei der direkten Skalierung auf größere Kontextfenster kann die Verwirrung auf sehr hohe Zahlen (z. B. > 10^3) ansteigen.
Dieser Artikel verwendet die Positionsinterpolationsmethode und der Vergleich mit der Extrapolationsmethode ist wie folgt. Aufgrund der Glattheit der Basisfunktionen ϕ_j ist die Interpolation stabiler und führt nicht zu Ausreißern.
 Bild
Bild
Diese Studie ersetzte RoPE f durch f′ und erhielt die folgende Formel:
 Bild
Bild
Diese Studie nennt die Konvertierung der Positionskodierung Positionsinterpolation. Dieser Schritt reduziert den Positionsindex von [0, L′ ) auf [0, L), um mit dem ursprünglichen Indexbereich übereinzustimmen, bevor RoPE berechnet wird. Daher wurde als Eingabe für RoPE der maximale relative Abstand zwischen zwei beliebigen Token von L ′ auf L reduziert. Durch die Angleichung des Bereichs der Positionsindizes und relativen Abstände vor und nach der Erweiterung werden die Auswirkungen der Kontextfenstererweiterung auf die Aufmerksamkeitsbewertungsberechnungen abgemildert, was die Anpassung des Modells erleichtert.
Es ist erwähnenswert, dass die Methode zur Neuskalierung des Positionsindex weder zusätzliche Gewichte einführt noch die Modellarchitektur in irgendeiner Weise verändert.
Experimente
Diese Studie zeigt, dass die Positionsinterpolation das Kontextfenster effektiv auf das 32-fache der ursprünglichen Größe erweitern kann und dass diese Erweiterung in nur wenigen hundert Trainingsschritten abgeschlossen werden kann.
Tabelle 1 und Tabelle 2 zeigen die Verwirrung des PI-Modells und des Basismodells für die PG-19- und Arxiv Math Proof-Pile-Datensätze. Die Ergebnisse zeigen, dass das mit der PI-Methode erweiterte Modell die Ratlosigkeit bei längeren Kontextfenstergrößen deutlich verbessert.
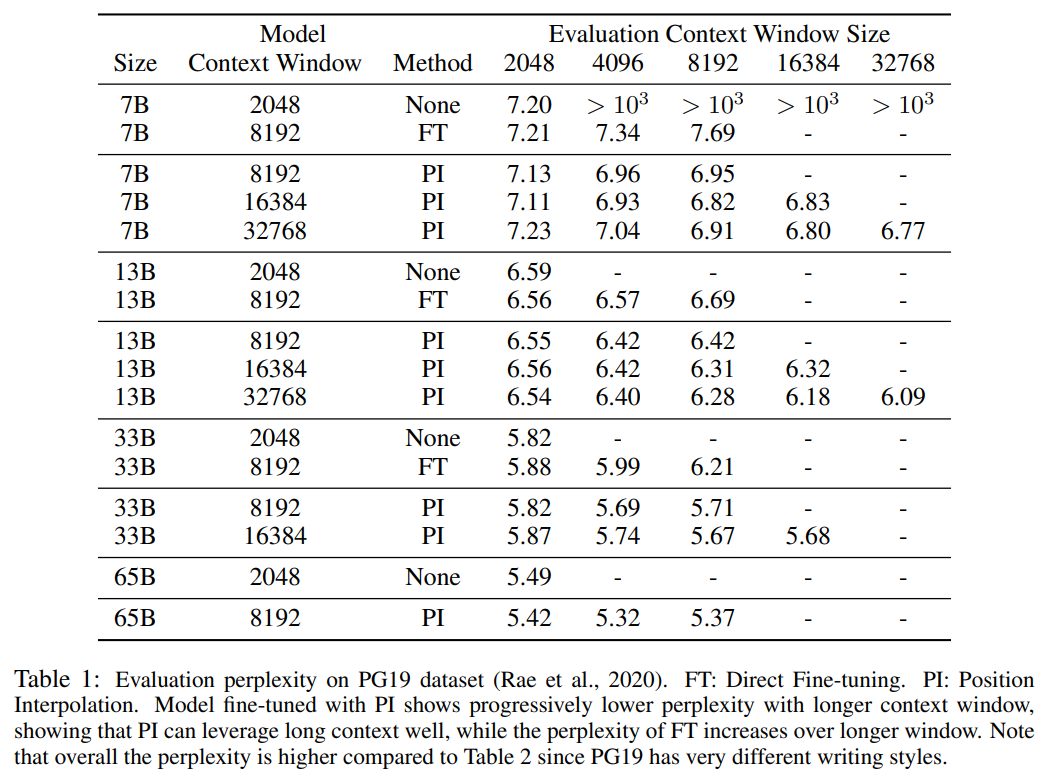
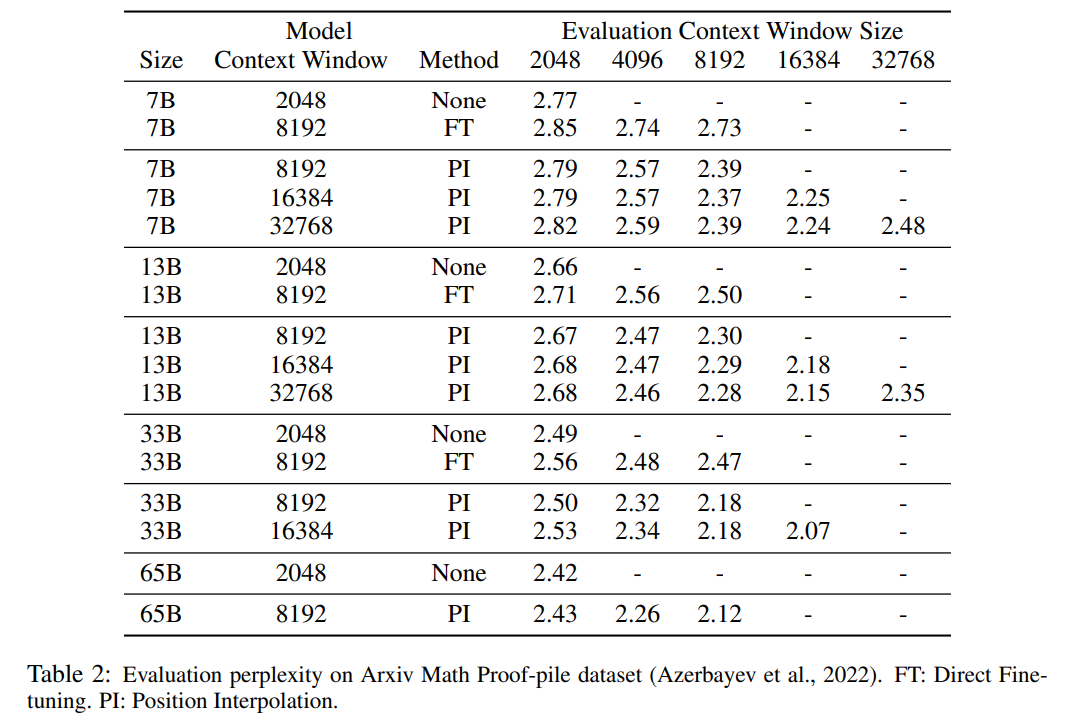
Tabelle 3 zeigt die Beziehung zwischen Ratlosigkeit und der Anzahl der Feinabstimmungsschritte bei der Erweiterung des LLaMA 7B-Modells auf 8192- und 16384-Kontextfenstergrößen unter Verwendung der PI-Methode für den PG19-Datensatz.
Aus den Ergebnissen geht hervor, dass das Modell ohne Feinabstimmung (die Anzahl der Schritte beträgt 0) bestimmte Sprachmodellierungsfunktionen demonstrieren kann. Wenn beispielsweise das Kontextfenster auf 8192 erweitert wird, ist die Verwirrung geringer als 20 (im Vergleich zu Unten ist die Verwirrung der direkten Extrapolationsmethode größer als 10^3). Bei 200 Schritten übersteigt die Ratlosigkeit des Modells die des Originalmodells bei einer Kontextfenstergröße von 2048, was darauf hindeutet, dass das Modell in der Lage ist, längere Sequenzen effektiv für die Sprachmodellierung zu nutzen als die vorab trainierte Einstellung. Bei 1000 Schritten ist eine stetige Verbesserung des Modells zu beobachten und es wird eine bessere Ratlosigkeit erreicht.
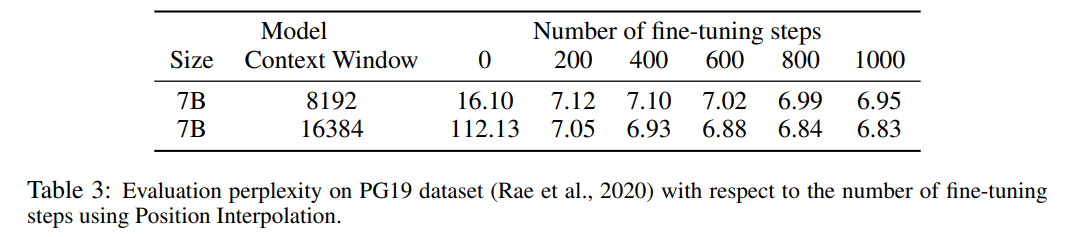 Bilder
Bilder
Die folgende Tabelle zeigt, dass das von PI erweiterte Modell das Skalierungsziel hinsichtlich der effektiven Kontextfenstergröße erfolgreich erreicht, d. h. nach nur 200 Schritten der Feinabstimmung die effektive Kontextfenstergröße erreicht den Maximalwert, konsistent über die Modellgrößen 7B und 33B und bis zu 32768 Kontextfenster. Im Gegensatz dazu stieg die effektive Kontextfenstergröße des LLaMA-Modells, das nur durch direkte Feinabstimmung erweitert wurde, nur von 2048 auf 2560, ohne Anzeichen einer signifikanten beschleunigten Fenstergrößenzunahme, selbst nach mehr als 10.000 Feinabstimmungsschritten.
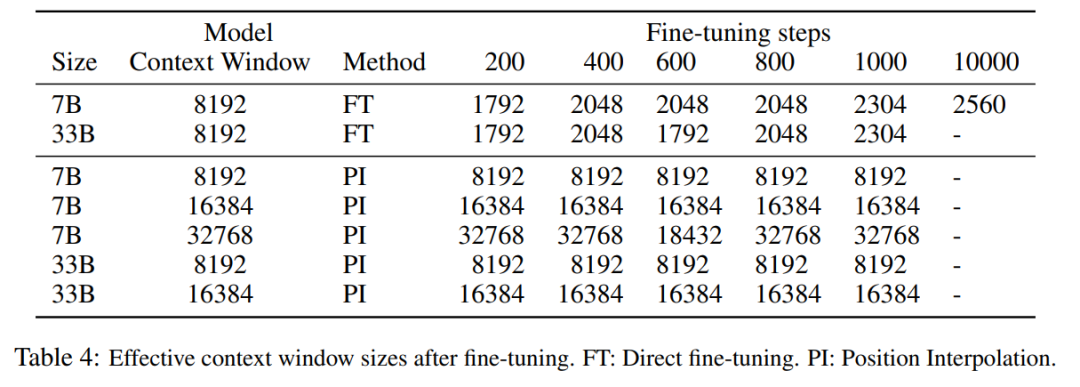 Bilder
Bilder
Tabelle 5 zeigt, dass das auf 8192 erweiterte Modell vergleichbare Ergebnisse bei der ursprünglichen Basisaufgabe liefert, die für kleinere Kontextfenster konzipiert wurde, und zwar für die Modellgrößen 7B und 33B, die Verschlechterung in der Benchmark-Aufgabe erreicht bis zu 2 %.
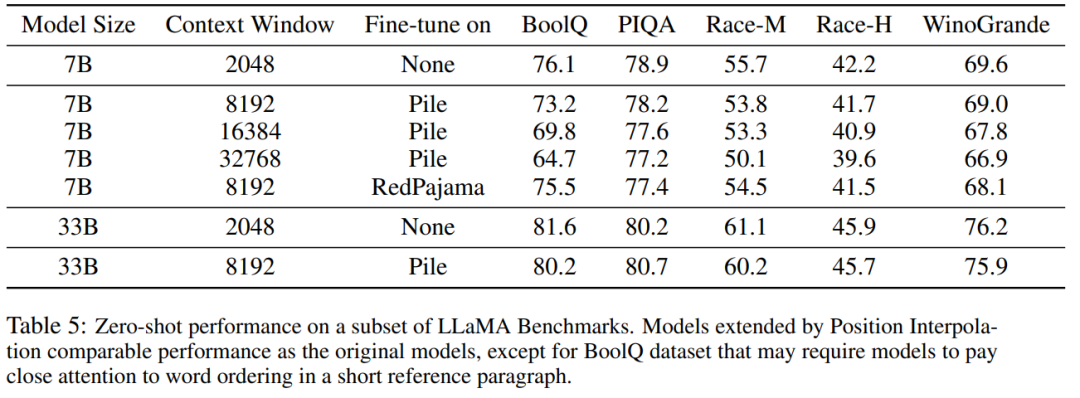 Bilder
Bilder
Tabelle 6 zeigt, dass das PI-Modell mit 16384 Kontextfenstern Langtextzusammenfassungsaufgaben effektiv bewältigen kann.
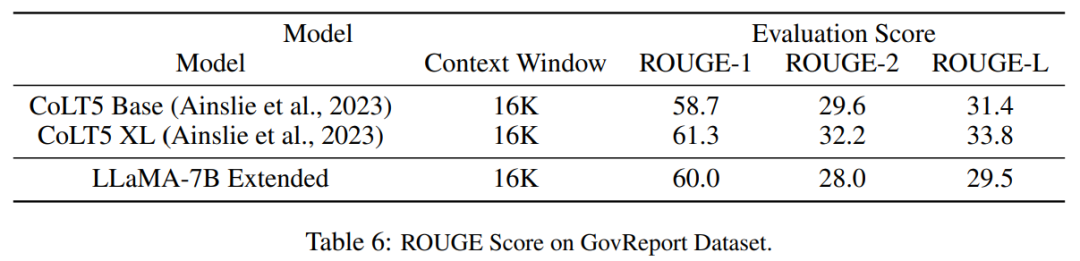 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonNeue Forschung des Teams von Tian Yuandong: Feinabstimmung von . Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Das neue erschwingliche Meta Quest 3S VR-Headset erscheint bei FCC, was auf eine baldige Markteinführung hindeutet
Sep 04, 2024 am 06:51 AM
Das neue erschwingliche Meta Quest 3S VR-Headset erscheint bei FCC, was auf eine baldige Markteinführung hindeutet
Sep 04, 2024 am 06:51 AM
Die Meta Connect 2024-Veranstaltung findet vom 25. bis 26. September statt. Bei dieser Veranstaltung wird das Unternehmen voraussichtlich ein neues erschwingliches Virtual-Reality-Headset vorstellen. Gerüchten zufolge handelt es sich bei dem VR-Headset um das Meta Quest 3S, das offenbar auf der FCC-Liste aufgetaucht ist. Dieser Vorschlag
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
