
 Technologie-Peripheriegeräte
KI
Das intelligente Open-Source-Multimodal-Großmodell VisCPM der Tsinghua-Universität in China unterstützt die bidirektionale Generierung von Dialogtexten und -bildern und verfügt über erstaunliche Poesie- und Malfunktionen
Technologie-Peripheriegeräte
KI
Das intelligente Open-Source-Multimodal-Großmodell VisCPM der Tsinghua-Universität in China unterstützt die bidirektionale Generierung von Dialogtexten und -bildern und verfügt über erstaunliche Poesie- und Malfunktionen
Das intelligente Open-Source-Multimodal-Großmodell VisCPM der Tsinghua-Universität in China unterstützt die bidirektionale Generierung von Dialogtexten und -bildern und verfügt über erstaunliche Poesie- und Malfunktionen

Der im Dezember 2020 veröffentlichte CPM-1 ist das erste chinesische Großmodell in China; der im September 2022 veröffentlichte CPM-Ant kann den vollen Parameter-Feinabstimmungseffekt durch eine Feinabstimmung von nur 0,06 % der veröffentlichten Parameter erreichen im Mai 2023 ist Chinesisch Das erste Open-Source-Modell für suchbasierte Fragenbeantwortung. Das CPM-Bee 10-Milliarden-Großmodell ist das neueste vom Team veröffentlichte Basismodell. Seine Chinesischkenntnisse stehen an der Spitze der maßgeblichen Liste ZeroCLUE, und seine Englischkenntnisse sind gleichauf mit LLaMA.
Die CPM-Serie großer Modelle hat wiederholt bahnbrechende Erfolge erzielt und inländische große Modelle an die Spitze geführt, und das kürzlich veröffentlichte VisCPM ist ein weiterer Beweis! VisCPM ist eine multimodale große Modellreihe, die gemeinsam von Wallface Intelligence, dem Tsinghua University NLP Laboratory und Zhihu in OpenBMB bereitgestellt wird. Das VisCPM-Chat-Modell unterstützt zweisprachige multimodale Dialogfunktionen in Chinesisch und Englisch, und das VisCPM-Paint-Modell unterstützt Die Auswertung zeigt, dass VisCPM das beste Niveau unter den chinesischen multimodalen Open-Source-Modellen erreicht.
VisCPM wird auf der Grundlage des zig Milliarden Parameter-Basismodells CPM-Bee trainiert und integriert den visuellen Encoder (Q-Former) und den visuellen Decoder (Diffusion-UNet), um die Eingabe und Ausgabe visueller Signale zu unterstützen. Dank CPM-Bee Mit den hervorragenden zweisprachigen Funktionen der Basis kann VisCPM mit englischen multimodalen Daten vorab trainiert und verallgemeinert werden, um hervorragende chinesische multimodale Funktionen zu erzielen Schauen Sie sich VisCPM-Chat im Detail an. Wo ist die Kuh mit VisCPM-Paint? VisCPM-Chat unterstützt die bildorientierte zweisprachige Verarbeitung in Chinesisch und Englisch
Das Modell verwendet Q-Former als visuellen Encoder, verwendet CPM-Bee (10B) als Basismodell für die Sprachinteraktion und verbindet visuelle Elemente und Sprachmodelle durch Sprachmodellierungs-Trainingsziele. Das Team verwendete etwa  hochwertige englische Bild- und Textdaten, einschließlich CC3M , CC12M, COCO, Visual Genome, Laion usw. im Vortraining. In dieser Phase bleiben die Parameter des Sprachmodells festgelegt und nur einige Parameter von Q-Former werden aktualisiert, um eine effiziente Ausrichtung umfangreicher visueller Sprachdarstellungen zu unterstützen .
hochwertige englische Bild- und Textdaten, einschließlich CC3M , CC12M, COCO, Visual Genome, Laion usw. im Vortraining. In dieser Phase bleiben die Parameter des Sprachmodells festgelegt und nur einige Parameter von Q-Former werden aktualisiert, um eine effiziente Ausrichtung umfangreicher visueller Sprachdarstellungen zu unterstützen .
Das Team hat dann die Anweisungen von VisCPM-Chat unter Verwendung der LLaVA-150K-Befehls-Feinabstimmungsdaten verfeinert und die entsprechenden übersetzten chinesischen Daten gemischt, um das Modell zu verfeinern - Modale Grundfunktionen und Benutzernutzungsabsichten. In der Befehlsfeinabstimmungsphase wurden alle Modellparameter aktualisiert, um die Befehlsnutzungseffizienz der Feinabstimmungsdaten zu verbessern Die Daten wurden zur Feinabstimmung der Anweisungen verwendet. Das Modell konnte chinesische Fragen verstehen, konnte jedoch nur auf Englisch antworten. Dies zeigt, dass die modalen Fähigkeiten durch das weitere Hinzufügen einer kleinen Menge chinesischer Übersetzungsdaten gut verallgemeinert wurden In der Feinabstimmungsphase der Anweisungen kann die Antwortsprache des Modells an die Fragesprache des Benutzers angepasst werden
 Das Team testete den LLaVA-Testsatz für Englisch und die Übersetzung auf Chinesisch. Das Modell wurde anhand dieses Bewertungsbenchmarks bewertet Untersucht die Leistung des Modells im offenen Domänendialog, in der Bilddetailbeschreibung und im komplexen Denken und verwendet GPT-4 zur Bewertung. Es kann beobachtet werden, dass VisCPM-Chat über hervorragende chinesische multimodale Fähigkeiten verfügt
Das Team testete den LLaVA-Testsatz für Englisch und die Übersetzung auf Chinesisch. Das Modell wurde anhand dieses Bewertungsbenchmarks bewertet Untersucht die Leistung des Modells im offenen Domänendialog, in der Bilddetailbeschreibung und im komplexen Denken und verwendet GPT-4 zur Bewertung. Es kann beobachtet werden, dass VisCPM-Chat über hervorragende chinesische multimodale Fähigkeiten verfügt
VisCPM-Chat bietet zwei Modellversionen, VisCPM-Chat-balance und VisCPM-Chat-zhplus ausgeglichenere Fähigkeiten in Englisch und Chinesisch, während Letzteres bei den Chinesischkenntnissen stärker ausgeprägt ist. Die beiden Modelle verwenden in der Feinabstimmungsphase der Anweisungen die gleichen Daten. VisCPM-Chat-zhplus fügt in der Vortrainingsphase zusätzlich 20 Millionen bereinigte native chinesische Bild-Text-Paardaten und 120 Millionen übersetzte chinesische Bild-Text-Paardaten hinzu.
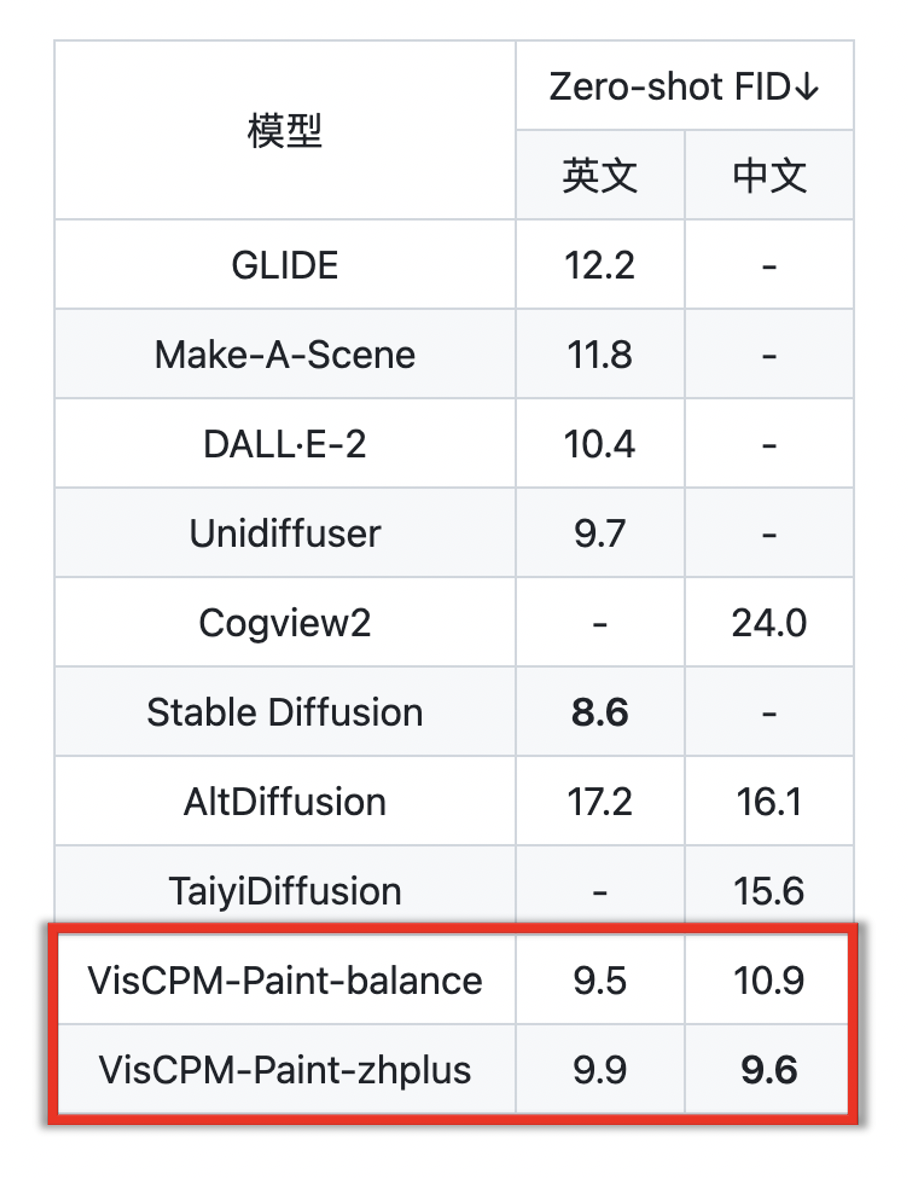
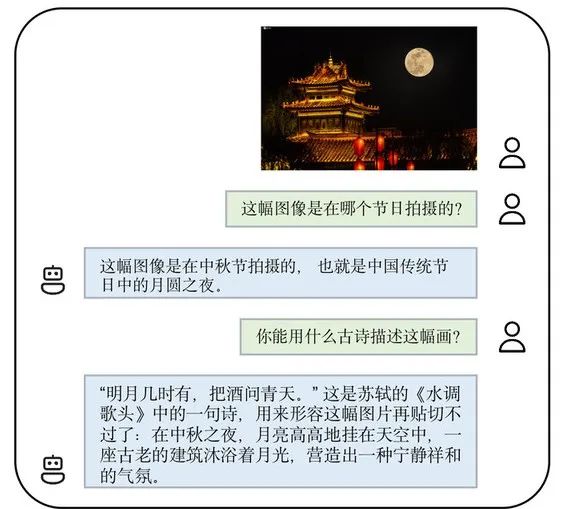
Bilder Das Folgende ist eine Demonstration der multimodalen Dialogfunktionen von VisCPM-Chat. Es kann nicht nur Karten bestimmter Bereiche erkennen, sondern auch Graffiti und Filmplakate verstehen und sogar das Starbucks-Logo erkennen. Außerdem bin ich sehr zweisprachig in Chinesisch und Englisch! Schauen wir uns VisCPM-Paint an, das die zweisprachige Text-zu-Bild-Generierung in Chinesisch und Englisch unterstützt. Das Modell verwendet CPM-Bee (10B) als Textkodierer, UNet als Bilddekodierer und zielt durch Diffusionsmodelltraining auf verschmolzene Sprach- und visuelle Modelle ab. Während des Trainingsprozesses bleiben die Parameter des Sprachmodells immer fest. Initialisieren Sie den visuellen Decoder mit den UNet-Parametern von Stable Diffusion 2.1 und verschmelzen Sie ihn mit dem Sprachmodell, indem Sie seine wichtigsten Überbrückungsparameter schrittweise freigeben: Trainieren Sie zunächst die lineare Schicht der Textdarstellungszuordnung zum visuellen Modell und geben Sie dann die Queraufmerksamkeit weiter frei Schicht von UNet. Das Modell wurde auf englischen Bild-Text-Daten von Laion 2B trainiert. Ähnlich wie VisCPM-Paint kann VisCPM-Paint dank der zweisprachigen Fähigkeit des Basismodells CPM-Bee nur durch englische Bild- und Textpaare trainiert und verallgemeinert werden, um gute chinesische Text-zu-Bild-Generierungsfähigkeiten zu erreichen und erreicht damit chinesische Open-Source-Modelle von ihrer besten Seite. Durch das weitere Hinzufügen von 20 Mio. bereinigten nativen chinesischen Bild-Text-Paardaten und 120 Mio. ins Chinesische übersetzten Bild-Text-Paardaten wurde die Fähigkeit des Modells zur chinesischen Text-zu-Bild-Generierung weiter verbessert. Ebenso gibt es von VisCPM-Paint zwei verschiedene Versionen: Balance und zhplus. Sie haben 30.000 Bilder mit dem Standard-Bilderzeugungstestsatz MSCOCO abgetastet und die häufig verwendete Bewertungsbilderzeugungsmetrik FID (Fréchet Inception Distance) berechnet, um die Qualität der erzeugten Bilder zu bewerten. Geben Sie zwei Eingabeaufforderungen in das VisCPM-Paint-Modell ein: „Der helle Mond geht auf dem Meer auf, die Welt ist zu dieser Zeit, ästhetischer Stil, abstrakter Stil“ und „Die Leute sind untätig, Osmanthusblüten fallen, die „Mond ist ruhig am Frühlingshimmel“, und die folgenden beiden werden generiert. Bild: (Die Stabilität des Erzeugungseffekts hat noch Raum für Verbesserungen) ist ziemlich erstaunlich. Man kann es sagen dass es die künstlerische Konzeption antiker Poesie genau erfasst. Wenn Sie das Gedicht in Zukunft nicht verstehen können, erstellen Sie einfach ein Bild, um es zu verstehen! Wenn es im Design angewendet wird, kann es viel Personal einsparen. Mit VisCPM-Chat können Sie nicht nur „zeichnen“, sondern auch „Gedichte aufsagen“: Rückwärtssuche nach Gedichten anhand von Bildern. Ich kann zum Beispiel die Gedichte von Li Bai verwenden, um die Szene am Gelben Fluss zu beschreiben und zu interpretieren, und ich kann auch Su Shis „Shui Tiao Ge Tou“ verwenden, um meine Gefühle auszudrücken, wenn ich der Mittherbstmondnacht gegenüberstehe. VisCPM liefert nicht nur gute Generierungsergebnisse, die Download-Version ist auch durchdacht gestaltet und auch sehr einfach zu installieren und zu verwenden. VisCPM bietet Modellversionen mit unterschiedlichen chinesischen und englischen Funktionen zum Herunterladen und Auswählen. Die Installationsschritte sind einfach und für mehrere Modelle geeignet kann mit wenigen Codezeilen während der Verwendung implementiert werden, und Sicherheitsprüfungen für Eingabetext und Ausgabebilder sind standardmäßig im Code aktiviert. (Spezifische Tutorials finden Sie in der README-Datei.) In Zukunft wird das Team VisCPM auch in das Huggingface-Code-Framework integrieren und das Sicherheitsmodell schrittweise verbessern, die schnelle Bereitstellung von Webseiten unterstützen, Modellquantifizierungsfunktionen unterstützen, die Feinabstimmung des Modells unterstützen und vieles mehr Funktionen. Bleiben Sie dran für Updates! Erwähnenswert ist, dass Modelle der VisCPM-Serie für den persönlichen Gebrauch und Forschungszwecke sehr willkommen sind. Wenn Sie das Modell für kommerzielle Zwecke nutzen möchten, können Sie sich auch an cpm@modelbest.cn wenden, um kommerzielle Lizenzfragen zu besprechen. Traditionelle Modelle konzentrieren sich auf die Verarbeitung monomodaler Daten in der realen Welt. Multimodale große Modelle verbessern die Wahrnehmungsinteraktionsfähigkeiten künstlicher Intelligenzsysteme und lösen komplexe Wahrnehmungs- und Interaktionsprobleme in der realen Welt für KI. Aufgaben zu verstehen bringt neue Möglichkeiten. Es muss gesagt werden, dass die in Tsinghua ansässigen großen Modellunternehmen über starke Forschungs- und Entwicklungskapazitäten für wandorientierte Intelligenz verfügen. Das gemeinsam veröffentlichte multimodale Großmodell VisCPM ist leistungsstark und weist eine erstaunliche Leistung auf. 


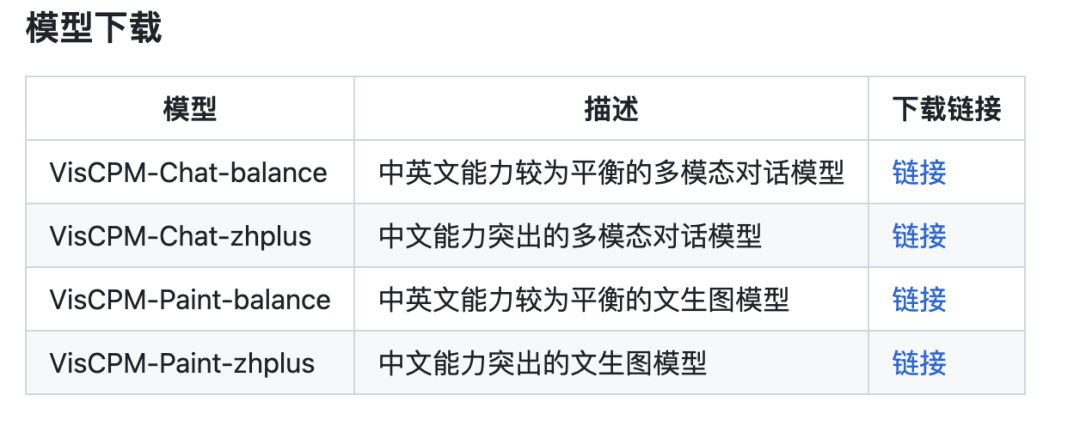 VisCPM bietet Modellversionen mit unterschiedlichen chinesischen und englischen Funktionen.
VisCPM bietet Modellversionen mit unterschiedlichen chinesischen und englischen Funktionen. 
Das obige ist der detaillierte Inhalt vonDas intelligente Open-Source-Multimodal-Großmodell VisCPM der Tsinghua-Universität in China unterstützt die bidirektionale Generierung von Dialogtexten und -bildern und verfügt über erstaunliche Poesie- und Malfunktionen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Web3 Trading Platform Ranking_Web3 Globale Top Ten Summary Top Ten Summary
Apr 21, 2025 am 10:45 AM
Web3 Trading Platform Ranking_Web3 Globale Top Ten Summary Top Ten Summary
Apr 21, 2025 am 10:45 AM
Binance ist der Overlord des Global Digital Asset Trading -Ökosystems, und seine Merkmale umfassen: 1. Das durchschnittliche tägliche Handelsvolumen übersteigt 150 Milliarden US -Dollar, unterstützt 500 Handelspaare, die 98% der Mainstream -Währungen abdecken. 2. Die Innovationsmatrix deckt den Markt für Derivate, das Web3 -Layout und den Bildungssystem ab; 3. Die technischen Vorteile sind Millisekunden -Matching -Engines mit Spitzenvolumina von 1,4 Millionen Transaktionen pro Sekunde. 4. Compliance Progress hält 15 Länderlizenzen und legt konforme Einheiten in Europa und den Vereinigten Staaten ein.
 Worldcoin (WLD) Preisprognose 2025-2031: Wird WLD bis 2031 $ erreichen?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) Preisprognose 2025-2031: Wird WLD bis 2031 $ erreichen?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) fällt auf dem Kryptowährungsmarkt mit seinen einzigartigen biometrischen Überprüfungs- und Datenschutzschutzmechanismen auf, die die Aufmerksamkeit vieler Investoren auf sich ziehen. WLD hat mit seinen innovativen Technologien, insbesondere in Kombination mit OpenAI -Technologie für künstliche Intelligenz, außerdem unter Altcoins gespielt. Aber wie werden sich die digitalen Vermögenswerte in den nächsten Jahren verhalten? Lassen Sie uns den zukünftigen Preis von WLD zusammen vorhersagen. Die Preisprognose von 2025 WLD wird voraussichtlich im Jahr 2025 ein signifikantes Wachstum in WLD erzielen. Die Marktanalyse zeigt, dass der durchschnittliche WLD -Preis 1,31 USD mit maximal 1,36 USD erreichen kann. In einem Bärenmarkt kann der Preis jedoch auf rund 0,55 US -Dollar fallen. Diese Wachstumserwartung ist hauptsächlich auf Worldcoin2 zurückzuführen.
 Rangliste der Hebelbörsen im Währungskreis Die neuesten Empfehlungen der zehn meistgezogenen Börsen im Währungskreis
Apr 21, 2025 pm 11:24 PM
Rangliste der Hebelbörsen im Währungskreis Die neuesten Empfehlungen der zehn meistgezogenen Börsen im Währungskreis
Apr 21, 2025 pm 11:24 PM
Die Plattformen, die im Jahr 2025 im Leveraged Trading, Security und Benutzererfahrung hervorragende Leistung haben, sind: 1. OKX, geeignet für Hochfrequenzhändler und bieten bis zu 100-fache Hebelwirkung; 2. Binance, geeignet für Mehrwährungshändler auf der ganzen Welt und bietet 125-mal hohe Hebelwirkung; 3. Gate.io, geeignet für professionelle Derivate Spieler, die 100 -fache Hebelwirkung bietet; 4. Bitget, geeignet für Anfänger und Sozialhändler, die bis zu 100 -fache Hebelwirkung bieten; 5. Kraken, geeignet für stetige Anleger, die fünfmal Hebelwirkung liefert; 6. Bybit, geeignet für Altcoin -Entdecker, die 20 -fache Hebelwirkung bietet; 7. Kucoin, geeignet für kostengünstige Händler, die 10-fache Hebelwirkung bietet; 8. Bitfinex, geeignet für das Seniorenspiel
 Was bedeutet Cross-Chain-Transaktion? Was sind die Cross-Chain-Transaktionen?
Apr 21, 2025 pm 11:39 PM
Was bedeutet Cross-Chain-Transaktion? Was sind die Cross-Chain-Transaktionen?
Apr 21, 2025 pm 11:39 PM
Börsen, die Cross-Chain-Transaktionen unterstützen: 1. Binance, 2. Uniswap, 3. Sushiswap, 4. Kurvenfinanzierung, 5. Thorchain, 6. 1inch Exchange, 7. DLN-Handel, diese Plattformen unterstützen Multi-Chain-Asset-Transaktionen durch verschiedene Technologien.
 'Black Monday Sell' ist ein schwieriger Tag für die Kryptowährungsbranche
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' ist ein schwieriger Tag für die Kryptowährungsbranche
Apr 21, 2025 pm 02:48 PM
Der Sprung in den Kryptowährungsmarkt hat bei den Anlegern Panik verursacht, und Dogecoin (DOGE) ist zu einem der am stärksten getroffenen Bereiche geworden. Der Preis fiel stark, und die Gesamtwertsperrung der dezentralen Finanzierung (DEFI) (TVL) verzeichnete ebenfalls einen signifikanten Rückgang. Die Verkaufswelle von "Black Monday" fegte den Kryptowährungsmarkt, und Dogecoin war der erste, der getroffen wurde. Die Defitvl fiel auf 2023 und der Währungspreis fiel im vergangenen Monat um 23,78%. Die Defitvl von Dotecoin fiel auf ein Tiefpunkt von 2,72 Millionen US -Dollar, hauptsächlich aufgrund eines Rückgangs des SOSO -Wertindex um 26,37%. Andere große Defi -Plattformen wie die langweilige DAO und Thorchain, TVL, fielen ebenfalls um 24,04% bzw. 20.
 Warum ist der Anstieg oder Abfall der virtuellen Währungspreise? Warum ist der Anstieg oder Abfall der virtuellen Währungspreise?
Apr 21, 2025 am 08:57 AM
Warum ist der Anstieg oder Abfall der virtuellen Währungspreise? Warum ist der Anstieg oder Abfall der virtuellen Währungspreise?
Apr 21, 2025 am 08:57 AM
Faktoren der steigenden Preise für virtuelle Währung sind: 1. Erhöhte Marktnachfrage, 2. Verringertes Angebot, 3.. Rückgangsfaktoren umfassen: 1. Verringerte Marktnachfrage, 2. Erhöhtes Angebot, 3. Streik der negativen Nachrichten, 4. Pessimistische Marktstimmung, 5. makroökonomisches Umfeld.
 So gewinnen Sie Kernel Airdrop -Belohnungen für Binance vollständige Prozessstrategie
Apr 21, 2025 pm 01:03 PM
So gewinnen Sie Kernel Airdrop -Belohnungen für Binance vollständige Prozessstrategie
Apr 21, 2025 pm 01:03 PM
In der geschäftigen Welt der Kryptowährungen entstehen immer neue Möglichkeiten. Gegenwärtig zieht Kerneldao (Kernel) Airdrop -Aktivität viel Aufmerksamkeit auf sich und zieht die Aufmerksamkeit vieler Investoren auf sich. Also, was ist der Ursprung dieses Projekts? Welche Vorteile können BNB -Inhaber davon bekommen? Machen Sie sich keine Sorgen, das Folgende wird es einzeln für Sie enthüllen.
 Aavenomics ist eine Empfehlung, das Aave -Protokoll -Token zu ändern und Token -Rückkauf einzuführen, die die Quorum -Anzahl von Personen erreicht hat.
Apr 21, 2025 pm 06:24 PM
Aavenomics ist eine Empfehlung, das Aave -Protokoll -Token zu ändern und Token -Rückkauf einzuführen, die die Quorum -Anzahl von Personen erreicht hat.
Apr 21, 2025 pm 06:24 PM
Aavenomics ist ein Vorschlag zur Änderung des Aave -Protokoll -Tokens und zur Einführung von Token -Repos, die ein Quorum für Aavedao implementiert hat. Marc Zeller, Gründer der AAVE -Projektkette (ACI), kündigte dies auf X an und stellte fest, dass sie eine neue Ära für die Vereinbarung markiert. Marc Zeller, Gründer der Aave Chain Initiative (ACI), kündigte auf X an, dass der Aavenomics -Vorschlag das Modifizieren des Aave -Protokoll -Tokens und die Einführung von Token -Repos umfasst, hat ein Quorum für Aavedao erreicht. Laut Zeller ist dies eine neue Ära für die Vereinbarung. AVEDAO -Mitglieder stimmten überwiegend für die Unterstützung des Vorschlags, der am Mittwoch 100 pro Woche betrug
