
 Technologie-Peripheriegeräte
KI
NTU und Shanghai AI Lab haben über 300 Artikel zusammengestellt: Die neueste Überprüfung der visuellen Segmentierung auf Basis von Transformer wird veröffentlicht
Technologie-Peripheriegeräte
KI
NTU und Shanghai AI Lab haben über 300 Artikel zusammengestellt: Die neueste Überprüfung der visuellen Segmentierung auf Basis von Transformer wird veröffentlicht
NTU und Shanghai AI Lab haben über 300 Artikel zusammengestellt: Die neueste Überprüfung der visuellen Segmentierung auf Basis von Transformer wird veröffentlicht

SAM (Segment Anything) hat als grundlegendes visuelles Segmentierungsmodell in nur drei Monaten die Aufmerksamkeit und Nachverfolgung vieler Forscher auf sich gezogen. Wenn Sie die Technologie hinter SAM systematisch verstehen, mit der Geschwindigkeit der Involution Schritt halten und Ihr eigenes SAM-Modell erstellen möchten, sollten Sie sich diese transformatorbasierte Segmentierungsumfrage nicht entgehen lassen! Kürzlich haben mehrere Forscher der Nanyang Technological University und des Shanghai Artificial Intelligence Laboratory einen Bericht über Transformer-basierte Segmentierung geschrieben und dabei die auf Transformer basierenden Segmentierungs- und Erkennungsmodelle der letzten Jahre systematisch überprüft. Das neueste untersuchte Modell ist Stand: Bis Juni dieses Jahres! Gleichzeitig umfasst die Rezension auch die neuesten Arbeiten in verwandten Bereichen sowie eine Vielzahl experimenteller Analysen und Vergleiche und zeigt eine Reihe zukünftiger Forschungsrichtungen mit breiten Perspektiven auf!
Die visuelle Segmentierung dient dazu, Bilder, Videobilder oder Punktwolken in mehrere Segmente oder Gruppen aufzuteilen. Diese Technologie hat viele reale Anwendungen, wie zum Beispiel autonomes Fahren, Bildbearbeitung, Roboterwahrnehmung und medizinische Analyse. Im letzten Jahrzehnt haben Deep-Learning-basierte Methoden in diesem Bereich erhebliche Fortschritte gemacht. In letzter Zeit hat sich Transformer zu einem neuronalen Netzwerk entwickelt, das auf einem Selbstaufmerksamkeitsmechanismus basiert und ursprünglich für die Verarbeitung natürlicher Sprache entwickelt wurde. Es übertrifft frühere Faltungs- oder wiederkehrende Methoden bei verschiedenen visuellen Verarbeitungsaufgaben erheblich. Konkret bietet der Vision Transformer leistungsstarke, einheitliche und noch einfachere Lösungen für verschiedene Segmentierungsaufgaben. Diese Rezension bietet einen umfassenden Überblick über die Transformer-basierte visuelle Segmentierung und fasst die jüngsten Fortschritte zusammen. In diesem Artikel wird zunächst der Hintergrund besprochen, einschließlich Problemdefinition, Datensätze und frühere Faltungsmethoden. Als nächstes fasst dieses Papier eine „Meta-Architektur“ zusammen, die alle neueren Transformer-basierten Methoden vereint. Basierend auf dieser Metaarchitektur untersucht dieser Artikel verschiedene Methodendesigns, einschließlich Modifikationen dieser Metaarchitektur und verwandter Anwendungen.Darüber hinaus werden in diesem Artikel auch verschiedene verwandte Einstellungen vorgestellt, darunter 3D-Punktwolkensegmentierung, grundlegende Modelloptimierung, domänenadaptive Segmentierung, effiziente Segmentierung und medizinische Segmentierung. Darüber hinaus werden in diesem Artikel diese Methoden anhand mehrerer allgemein anerkannter Datensätze zusammengestellt und neu bewertet. Abschließend identifiziert das Papier offene Herausforderungen in diesem Bereich und schlägt Richtungen für zukünftige Forschung vor. Dieser Artikel wird fortgesetzt und die neuesten Transformer-basierten Segmentierungs- und Erkennungsmethoden verfolgen. Bilder
Projektadresse: https://github.com/lxtGH/Awesome-Segmentation-With-Transformer Papieradresse: https://arxiv.org/pdf/2304.09854.pdf
Papieradresse: https://arxiv.org/pdf/2304.09854.pdf
Forschungsmotivation
Das Aufkommen von ViT und DETR hat im Bereich der Segmentierung und Erkennung große Fortschritte gemacht. Derzeit basieren die Top-Ranking-Methoden für fast alle Datensatz-Benchmarks auf Transformer. Aus diesem Grund ist es notwendig, die Methoden und technischen Merkmale dieser Richtung systematisch zusammenzufassen und zu vergleichen.
Neueste große Modellarchitekturen basieren alle auf der Transformer-Struktur, einschließlich multimodaler Modelle und Segmentierungsgrundmodelle (SAM), und verschiedene visuelle Aufgaben rücken näher an die einheitliche Modellmodellierung heran.
- Segmentierung und Erkennung haben viele verwandte nachgelagerte Aufgaben abgeleitet, und viele dieser Aufgaben werden auch mithilfe der Transformer-Struktur gelöst.
- Bewertungsfunktionen
Systematisch und lesbar. In diesem Artikel werden systematisch jede Aufgabendefinition der Segmentierung sowie zugehörige Aufgabendefinitionen und Bewertungsindikatoren überprüft. Und dieser Artikel beginnt mit der Faltungsmethode und fasst eine Metaarchitektur basierend auf ViT und DETR zusammen. Basierend auf dieser Metaarchitektur werden in dieser Übersicht verwandte Methoden zusammengefasst und zusammengefasst und neuere Methoden systematisch überprüft. Der spezifische Weg der technischen Überprüfung ist in Abbildung 1 dargestellt.
- Detaillierte Klassifizierung aus technischer Sicht. Im Vergleich zu früheren Transformer-Rezensionen wird die Klassifizierung der Methoden in diesem Artikel detaillierter sein. In diesem Artikel werden Arbeiten mit ähnlichen Ideen zusammengestellt und deren Gemeinsamkeiten und Unterschiede verglichen. In diesem Artikel werden beispielsweise Methoden klassifiziert, die gleichzeitig die Decoderseite der Metaarchitektur in bildbasierte Cross-Attention- und videobasierte räumlich-zeitliche Cross-Attention-Modellierung modifizieren.
- Vollständigkeit der Forschungsfrage. In diesem Artikel werden alle Segmentierungsrichtungen systematisch überprüft, einschließlich Bild-, Video- und Punktwolken-Segmentierungsaufgaben. Gleichzeitig werden in diesem Artikel auch verwandte Richtungen wie Open-Set-Segmentierungs- und Erkennungsmodelle, unbeaufsichtigte Segmentierung und schwach überwachte Segmentierung besprochen.
- Bilder
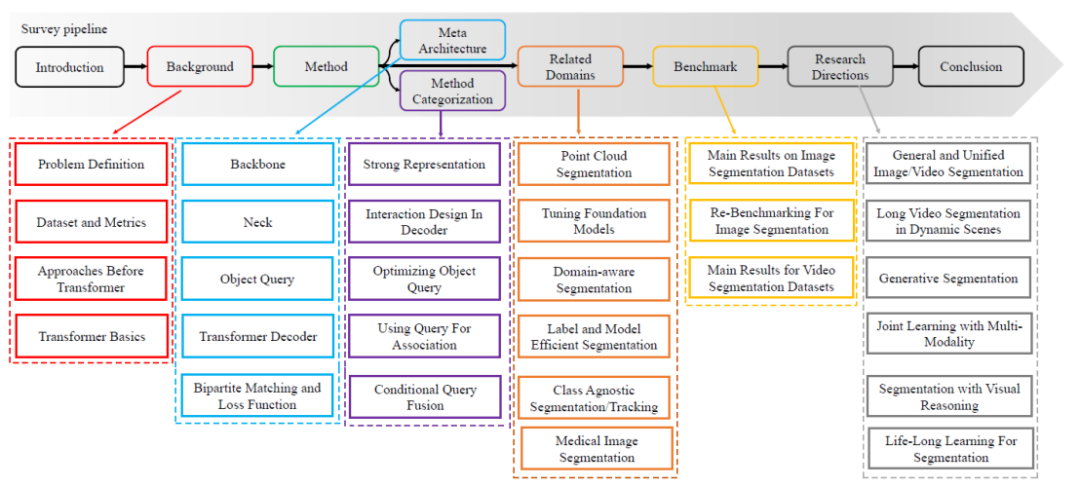
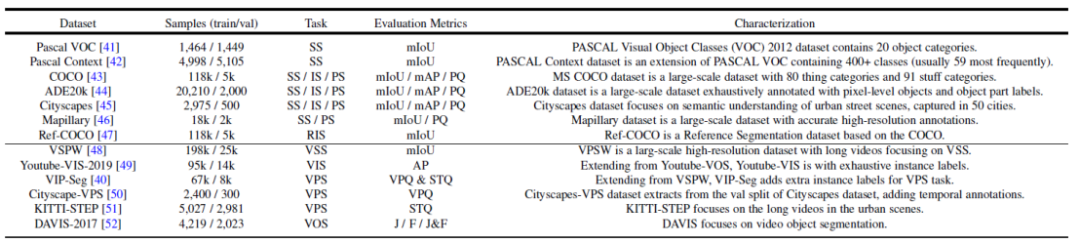
Abbildung 2. Zusammenfassung häufig verwendeter Datensätze und Segmentierungsaufgaben - Architektur)
Dieser Artikel fasst zunächst eine Metaarchitektur basierend auf den DETR- und MaskFormer-Frameworks zusammen. Dieses Modell umfasst die folgenden verschiedenen Module:
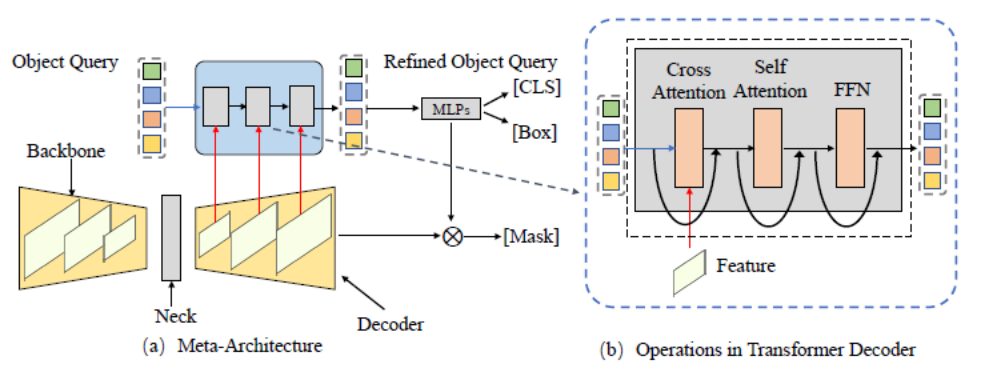 Backbone:
Backbone:
Feature-Extraktor, der zum Extrahieren von Bildmerkmalen verwendet wird.
Hals:
- Erstellen Sie Funktionen mit mehreren Maßstäben, um Objekte mit mehreren Maßstäben zu verarbeiten. Objektabfrage:
- Abfrageobjekt, das zur Darstellung jeder Entität in der Szene verwendet wird, einschließlich Vordergrundobjekten und Hintergrundobjekten. Decoder:
- Decoder, der zur schrittweisen Optimierung der Objektabfrage und der entsprechenden Funktionen verwendet wird. End-to-End-Schulung:
- Das auf Object Query basierende Design kann eine End-to-End-Optimierung erreichen. Basierend auf dieser Metaarchitektur können bestehende Methoden zur Optimierung und Anpassung je nach Aufgabenstellung in die folgenden fünf verschiedenen Richtungen unterteilt werden. Wie in Abbildung 4 dargestellt, enthält jede Richtung mehrere verschiedene Unterrichtungen.
-
Abbildung 4. Zusammenfassung und Vergleich transformatorbasierter Segmentierungsmethoden
- Besseres Lernen von Merkmalsausdrücken und Repräsentationslernen. Eine leistungsstarke visuelle Merkmalsdarstellung führt immer zu besseren Segmentierungsergebnissen. Dieser Artikel unterteilt verwandte Arbeiten in drei Aspekte: besseres visuelles Transformer-Design, hybrides CNN/Transformer/MLP und selbstüberwachtes Lernen.
- Methodendesign auf der Decoderseite, Interaktionsdesign im Decoder. In diesem Kapitel wird das neue Transformer-Decoder-Design vorgestellt. In diesem Artikel wird das Decoder-Design in zwei Gruppen unterteilt: Eine wird zur Verbesserung des Cross-Attention-Designs bei der Bildsegmentierung und die andere zur Verbesserung des räumlich-zeitlichen Cross-Attention-Designs bei der Videosegmentierung verwendet. Ersteres konzentriert sich auf die Entwicklung eines besseren Decoders, der den im ursprünglichen DETR verbessert. Letzteres erweitert abfrageobjektbasierte Objektdetektoren und -segmentierer auf die Videodomäne zur Videoobjekterkennung (VOD), Videoinstanzsegmentierung (VIS) und Videopixelsegmentierung (VPS) und konzentriert sich dabei auf die Modellierung von zeitlicher Konsistenz und Korrelation des Geschlechts.
- Versuchen Sie, die Objektabfrage aus der Perspektive der Abfrageobjektoptimierung zu optimieren. Im Vergleich zu Faster-RCNN hat DETR einen längeren Konvergenzzeitplan. Aufgrund der Schlüsselrolle von Abfrageobjekten wurden einige vorhandene Methoden untersucht, um das Training zu beschleunigen und die Leistung zu verbessern. Gemäß der Methode der Objektabfrage unterteilt dieser Artikel die folgende Literatur in zwei Aspekte: Hinzufügen von Standortinformationen und Verwenden zusätzlicher Überwachung. Standortinformationen liefern Hinweise für eine schnelle Trainingsstichprobe von Abfragemerkmalen. Die zusätzliche Aufsicht konzentriert sich auf die Gestaltung spezifischer Verlustfunktionen zusätzlich zur DETR-Standardverlustfunktion.
- Verwenden Sie Abfrageobjekte, um Features und Instanzen zuzuordnen, indem Sie Abfragen für die Zuordnung verwenden. Mehrere neuere Studien nutzen die Einfachheit von Abfrageobjekten und nutzen sie als Korrelationstools zur Lösung nachgelagerter Aufgaben. Es gibt zwei Hauptverwendungen: Die eine ist die Zuordnung auf Instanzebene und die andere die Zuordnung auf Aufgabenebene. Ersteres nutzt die Idee der Instanzunterscheidung, um Matching-Probleme auf Instanzebene in Videos zu lösen, wie z. B. Videosegmentierung und -verfolgung. Letzteres nutzt Abfrageobjekte, um verschiedene Teilaufgaben zu überbrücken und so ein effizientes Multitasking-Lernen zu erreichen.
- Multimodale bedingte Abfrageobjektgenerierung, bedingte Abfragegenerierung. Dieses Kapitel konzentriert sich hauptsächlich auf multimodale Segmentierungsaufgaben. Bedingte Abfrageabfrageobjekte werden hauptsächlich zur Bearbeitung modal- und bildübergreifender Feature-Matching-Aufgaben verwendet. Abhängig von den Aufgabeneingabebedingungen verwendet der Decoderkopf unterschiedliche Abfragen, um die entsprechenden Segmentierungsmasken zu erhalten. Basierend auf den Quellen verschiedener Eingaben unterteilt dieser Artikel diese Arbeiten in zwei Aspekte: Sprachmerkmale und Bildmerkmale. Diese Methoden basieren auf der Strategie der Fusion von Abfrageobjekten mit unterschiedlichen Modellmerkmalen und haben bei mehreren multimodalen Segmentierungsaufgaben und der Segmentierung mit wenigen Schüssen gute Ergebnisse erzielt.
Abbildung 5 zeigt einige repräsentative Arbeitsvergleiche in diesen 5 verschiedenen Richtungen. Genauere Methodendetails und Vergleiche finden Sie im Inhalt des Dokuments.
 Bilder: 1. Transformatorbasierte Punktwolken-Segmentierungsmethode. 2. Vision und multimodales Tuning großer Modelle. 3. Forschung zu domänenbezogenen Segmentierungsmodellen, einschließlich Domänentransferlernen und Domänengeneralisierungslernen. 4. Effiziente semantische Segmentierung: unbeaufsichtigte und schwach überwachte Segmentierungsmodelle. 5. Klassenunabhängige Segmentierung und Verfolgung. 6. Medizinische Bildsegmentierung.
Bilder: 1. Transformatorbasierte Punktwolken-Segmentierungsmethode. 2. Vision und multimodales Tuning großer Modelle. 3. Forschung zu domänenbezogenen Segmentierungsmodellen, einschließlich Domänentransferlernen und Domänengeneralisierungslernen. 4. Effiziente semantische Segmentierung: unbeaufsichtigte und schwach überwachte Segmentierungsmodelle. 5. Klassenunabhängige Segmentierung und Verfolgung. 6. Medizinische Bildsegmentierung. Bilder
Abbildung 6. Zusammenfassung und Vergleich transformatorbasierter Methoden in verwandten Forschungsfeldern
Vergleich experimenteller Ergebnisse verschiedener Methoden
Abbildung 7. Benchmark-Experiment zur Semantik Segmentierungsdatensatz
Abbildung 8. Benchmark-Experiment des Panorama-SegmentierungsdatensatzesDieser Artikel verwendet außerdem einheitlich dieselben experimentellen Designbedingungen, um die Ergebnisse mehrerer repräsentativer Arbeiten an mehreren Datensätzen zur Panoramasegmentierung und semantischen Segmentierung zu vergleichen. Es wurde festgestellt, dass bei Verwendung derselben Trainingsstrategie und desselben Encoders die Lücke zwischen der Methodenleistung kleiner wird.
Darüber hinaus vergleicht dieser Artikel auch die Ergebnisse aktueller Transformer-basierter Segmentierungsmethoden für mehrere verschiedene Datensätze und Aufgaben. (Semantische Segmentierung, Instanzsegmentierung, Panoramasegmentierung und entsprechende Videosegmentierungsaufgaben)
Zukünftige Richtungen
Darüber hinaus bietet dieser Artikel auch eine Analyse einiger möglicher zukünftiger Forschungsrichtungen. Beispielhaft seien hier drei unterschiedliche Richtungen angegeben.
- UpdateFügen Sie ein universelles und einheitliches Segmentierungsmodell hinzu. Die Verwendung der Transformer-Struktur zur Vereinheitlichung verschiedener Segmentierungsaufgaben liegt im Trend. Neuere Forschungen verwenden auf Abfrageobjekten basierende Transformer, um verschiedene Segmentierungsaufgaben unter einer Architektur auszuführen. Eine mögliche Forschungsrichtung besteht darin, Bild- und Videosegmentierungsaufgaben für verschiedene Segmentierungsdatensätze durch ein Modell zu vereinheitlichen. Diese allgemeinen Modelle können eine vielseitige und robuste Segmentierung in verschiedenen Szenarien erreichen. Beispielsweise hilft die Erkennung und Segmentierung seltener Kategorien in verschiedenen Szenarien, bessere Entscheidungen zu treffen.
- Segmentierungsmodell kombiniert mit visuellem Denken. Visuelles Denken erfordert, dass der Roboter die Verbindungen zwischen Objekten in der Szene versteht, und dieses Verständnis spielt eine Schlüsselrolle bei der Bewegungsplanung. Frühere Forschungen haben Segmentierungsergebnisse als Eingabe für visuelle Argumentationsmodelle für verschiedene Anwendungen wie Objektverfolgung und Szenenverständnis untersucht. Gemeinsame Segmentierung und visuelles Denken können eine vielversprechende Richtung sein, mit für beide Seiten vorteilhaftem Potenzial sowohl für die Segmentierung als auch für die relationale Klassifizierung. Durch die Einbeziehung des visuellen Denkens in den Segmentierungsprozess können Forscher die Kraft des Denkens nutzen, um die Segmentierungsgenauigkeit zu verbessern, während die Segmentierungsergebnisse auch einen besseren Input für das visuelle Denken liefern können.
- Forschung zum Segmentierungsmodell des kontinuierlichen Lernens. Vorhandene Segmentierungsmethoden werden in der Regel anhand von Closed-World-Datensätzen mit einem vordefinierten Satz von Kategorien verglichen, d. h. unter der Annahme, dass Trainings- und Testproben dieselbe Kategorie und denselben Merkmalsraum haben, der im Voraus bekannt ist. Allerdings sind reale Szenarien oft offen und instabil, und es können ständig neue Datenkategorien entstehen. Beispielsweise können bei autonomen Fahrzeugen und in der medizinischen Diagnostik plötzlich unvorhergesehene Situationen auftreten. Es besteht eine klare Lücke zwischen der Leistung und den Fähigkeiten bestehender Methoden in realen und geschlossenen Szenarien. Daher besteht die Hoffnung, dass neue Konzepte schrittweise und kontinuierlich in die vorhandene Wissensbasis des Segmentierungsmodells integriert werden können, damit das Modell lebenslanges Lernen ermöglichen kann.
Weitere Forschungsanweisungen finden Sie im Originalpapier.
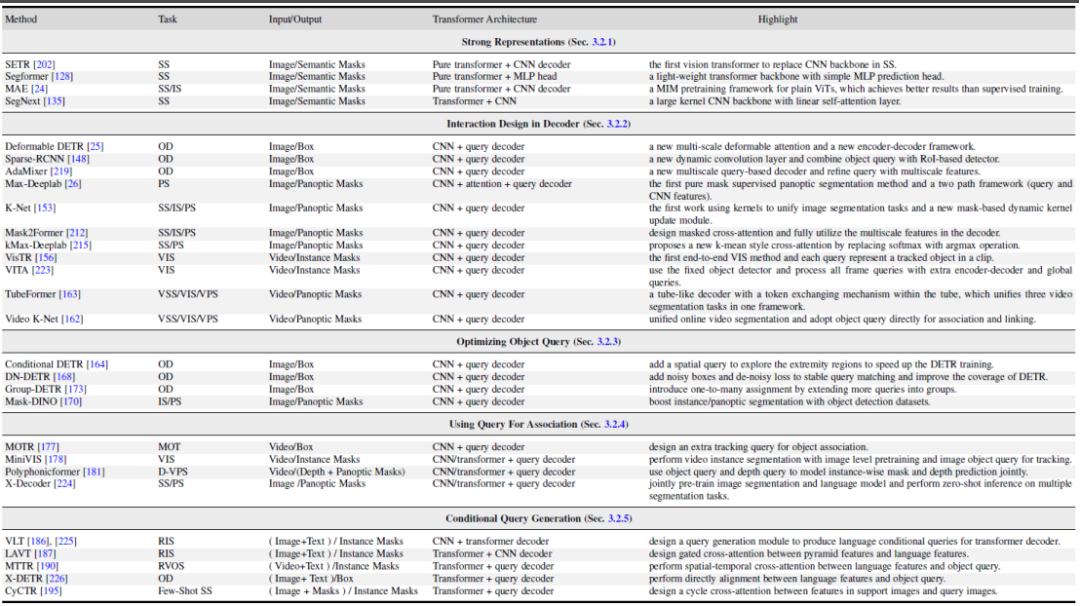
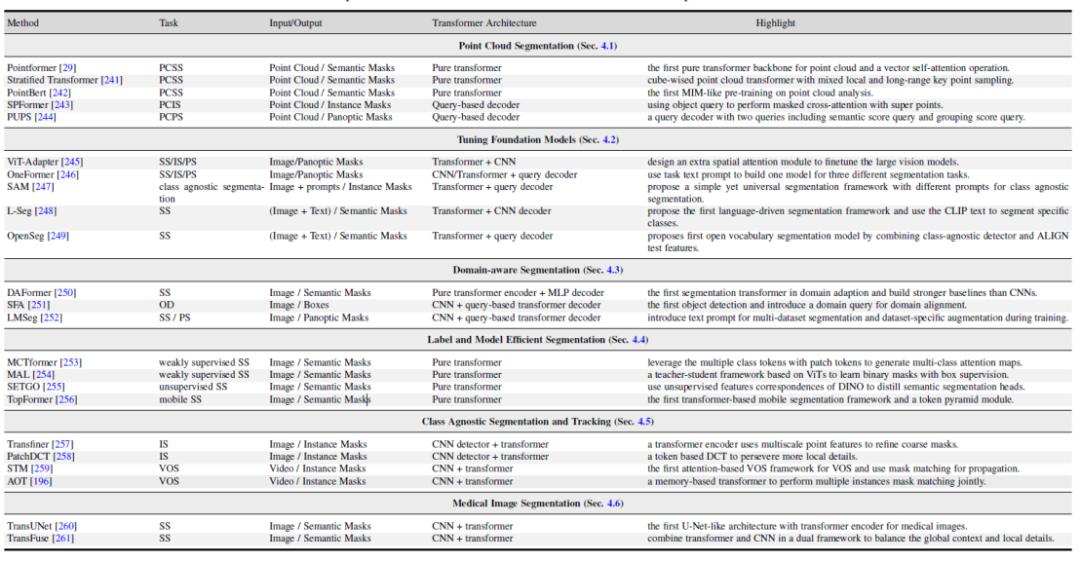
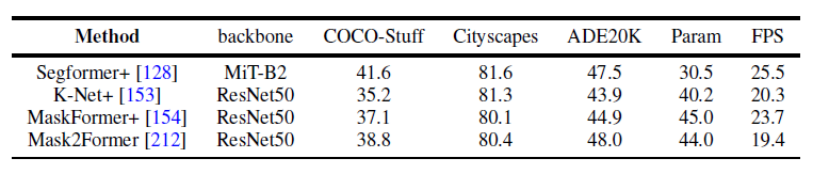 Abbildung 8. Benchmark-Experiment des Panorama-Segmentierungsdatensatzes
Abbildung 8. Benchmark-Experiment des Panorama-SegmentierungsdatensatzesDas obige ist der detaillierte Inhalt vonNTU und Shanghai AI Lab haben über 300 Artikel zusammengestellt: Die neueste Überprüfung der visuellen Segmentierung auf Basis von Transformer wird veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 ICCV'23-Papierpreis „Fighting of Gods'! Meta Divide Everything und ControlNet wurden gemeinsam ausgewählt, und es gab einen weiteren Artikel, der die Jury überraschte
Oct 04, 2023 pm 08:37 PM
ICCV'23-Papierpreis „Fighting of Gods'! Meta Divide Everything und ControlNet wurden gemeinsam ausgewählt, und es gab einen weiteren Artikel, der die Jury überraschte
Oct 04, 2023 pm 08:37 PM
ICCV2023, die Top-Computer-Vision-Konferenz in Paris, Frankreich, ist gerade zu Ende gegangen! Der diesjährige Preis für das beste Papier ist einfach ein „Kampf zwischen Göttern“. Zu den beiden Arbeiten, die den Best Paper Award gewannen, gehörte beispielsweise ControlNet, eine Arbeit, die das Gebiet der vinzentinischen Graphen-KI untergrub. Seitdem ControlNet als Open-Source-Lösung verfügbar ist, hat es auf GitHub 24.000 Sterne erhalten. Ob es sich um Diffusionsmodelle oder den gesamten Bereich der Computer Vision handelt, die Auszeichnung für dieses Papier ist wohlverdient. Die lobende Erwähnung für die beste Arbeit ging an eine andere ebenso berühmte Arbeit, Metas „Separate Everything“ „Model SAM“. Seit seiner Einführung ist „Segment Everything“ zum „Benchmark“ für verschiedene Bildsegmentierungs-KI-Modelle geworden, auch für solche, die von hinten kamen.
 NeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!
Nov 14, 2023 pm 03:09 PM
NeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!
Nov 14, 2023 pm 03:09 PM
Seit Neural Radiance Fields im Jahr 2020 vorgeschlagen wurde, hat die Zahl verwandter Arbeiten exponentiell zugenommen. Es hat sich nicht nur zu einem wichtigen Zweig der dreidimensionalen Rekonstruktion entwickelt, sondern ist auch allmählich an der Forschungsgrenze als wichtiges Werkzeug für autonomes Fahren aktiv geworden . NeRF ist in den letzten zwei Jahren plötzlich aufgetaucht, hauptsächlich weil es die Merkmalspunktextraktion und -anpassung, die epipolare Geometrie und Triangulation, PnP plus Bündelanpassung und andere Schritte der traditionellen CV-Rekonstruktionspipeline und sogar die Netzrekonstruktion, Kartierung und Lichtverfolgung überspringt , direkt aus 2D Das Eingabebild wird verwendet, um ein Strahlungsfeld zu lernen, und dann wird aus dem Strahlungsfeld ein gerendertes Bild ausgegeben, das einem echten Foto nahekommt. Mit anderen Worten: Lassen Sie ein implizites dreidimensionales Modell, das auf einem neuronalen Netzwerk basiert, zur angegebenen Perspektive passen
 Auch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.
Jun 27, 2023 pm 05:46 PM
Auch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.
Jun 27, 2023 pm 05:46 PM
Generative KI hat die Community der künstlichen Intelligenz im Sturm erobert. Sowohl Einzelpersonen als auch Unternehmen sind daran interessiert, entsprechende modale Konvertierungsanwendungen wie Vincent-Bilder, Vincent-Videos, Vincent-Musik usw. zu erstellen. In jüngster Zeit haben mehrere Forscher von wissenschaftlichen Forschungseinrichtungen wie ServiceNow Research und LIVIA versucht, Diagramme in Aufsätzen basierend auf Textbeschreibungen zu erstellen. Zu diesem Zweck schlugen sie eine neue Methode von FigGen vor, und das entsprechende Papier wurde auch als TinyPaper in ICLR2023 aufgenommen. Adresse des Bildpapiers: https://arxiv.org/pdf/2306.00800.pdf Manche Leute fragen sich vielleicht: Was ist so schwierig daran, die Diagramme im Papier zu erstellen? Wie hilft dies der wissenschaftlichen Forschung?
 Chat-Screenshots enthüllen versteckte Regeln für KI-Rezensenten! AAAI 3000 Yuan ist stark zu akzeptieren?
Apr 12, 2023 am 08:34 AM
Chat-Screenshots enthüllen versteckte Regeln für KI-Rezensenten! AAAI 3000 Yuan ist stark zu akzeptieren?
Apr 12, 2023 am 08:34 AM
Gerade als die Einreichungsfrist für AAAI 2023-Papiere näher rückte, erschien plötzlich ein Screenshot eines anonymen Chats in der AI-Einreichungsgruppe auf Zhihu. Einer von ihnen behauptete, er könne „3.000 Yuan pro starkem Akzept“ anbieten. Sobald die Nachricht bekannt wurde, erregte sie sofort öffentliche Empörung unter den Internetnutzern. Aber beeilen Sie sich noch nicht. Zhihu-Chef „Fine Tuning“ sagte, dass dies höchstwahrscheinlich nur ein „verbales Vergnügen“ sei. Laut „Fine Tuning“ sind Begrüßungen und Bandenkriminalität in jedem Bereich unvermeidbare Probleme. Mit dem Aufkommen von OpenReview werden die verschiedenen Nachteile von cmt immer deutlicher. Der Spielraum für kleine Kreise wird in Zukunft kleiner, aber es wird immer Platz geben. Denn es handelt sich um ein persönliches Problem und nicht um ein Problem mit dem Einreichungssystem und -mechanismus. Wir stellen Open R vor
 CVPR-Rangliste 2023 veröffentlicht, die Akzeptanzrate beträgt 25,78 %! 2.360 Beiträge wurden angenommen und die Zahl der Einreichungen stieg auf 9.155
Apr 13, 2023 am 09:37 AM
CVPR-Rangliste 2023 veröffentlicht, die Akzeptanzrate beträgt 25,78 %! 2.360 Beiträge wurden angenommen und die Zahl der Einreichungen stieg auf 9.155
Apr 13, 2023 am 09:37 AM
Gerade hat CVPR 2023 eine Erklärung herausgegeben, in der es heißt: In diesem Jahr haben wir eine Rekordzahl von 9.155 Beiträgen erhalten (ein Anstieg von 12 % gegenüber CVPR 2022) und 2.360 Beiträge angenommen, was einer Annahmequote von 25,78 % entspricht. Laut Statistik stieg die Zahl der Einreichungen beim CVPR in den sieben Jahren von 2010 bis 2016 lediglich von 1.724 auf 2.145. Nach 2017 stieg sie rasant an und trat in eine Phase rasanten Wachstums ein. Im Jahr 2019 überstieg sie erstmals die 5.000-Marke, und bis 2022 lag die Zahl der Einreichungen bei 8.161. Wie Sie sehen, wurden in diesem Jahr insgesamt 9.155 Beiträge eingereicht, was einen Rekord darstellt. Nachdem sich die Epidemie abgeschwächt hat, wird der diesjährige CVPR-Gipfel in Kanada stattfinden. In diesem Jahr wird das Format einer eingleisigen Konferenz übernommen und die traditionelle mündliche Auswahl entfällt. Google-Recherche
 Das chinesische Team gewann die Auszeichnungen „Best Paper' und „Best System Paper' und die CoRL-Forschungsergebnisse wurden bekannt gegeben.
Nov 10, 2023 pm 02:21 PM
Das chinesische Team gewann die Auszeichnungen „Best Paper' und „Best System Paper' und die CoRL-Forschungsergebnisse wurden bekannt gegeben.
Nov 10, 2023 pm 02:21 PM
Seit ihrer ersten Veranstaltung im Jahr 2017 hat sich die CoRL zu einer der weltweit führenden akademischen Konferenzen an der Schnittstelle von Robotik und maschinellem Lernen entwickelt. CoRL ist eine themenspezifische Konferenz für Roboterlernforschung, die mehrere Themen wie Robotik, maschinelles Lernen und Steuerung, einschließlich Theorie und Anwendung, abdeckt. Die CoRL-Konferenz 2023 findet vom 6. bis 9. November in Atlanta, USA, statt. Nach offiziellen Angaben wurden in diesem Jahr 199 Arbeiten aus 25 Ländern für CoRL ausgewählt. Beliebte Themen sind Operationen, Reinforcement Learning und mehr. Obwohl CoRL von kleinerem Umfang ist als große akademische KI-Konferenzen wie AAAI und CVPR, wird die Beliebtheit von Konzepten wie großen Modellen, verkörperter Intelligenz und humanoiden Robotern in diesem Jahr zunehmen, aber auch relevante Forschung verdient Aufmerksamkeit
 Microsofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token
Jul 22, 2023 pm 03:34 PM
Microsofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token
Jul 22, 2023 pm 03:34 PM
Da jeder seine eigenen großen Modelle weiter aktualisiert und iteriert, ist auch die Fähigkeit von LLM (großes Sprachmodell), Kontextfenster zu verarbeiten, zu einem wichtigen Bewertungsindikator geworden. Beispielsweise unterstützt das Star-Modell GPT-4 32.000 Token, was 50 Textseiten entspricht. Anthropic wurde von einem ehemaligen Mitglied von OpenAI gegründet und hat die Token-Verarbeitungsfähigkeiten von Claude auf 100.000 erhöht, was ungefähr 75.000 Wörtern entspricht entspricht der Zusammenfassung von „Harry Potter“ mit einem Klick 》Teil Eins. In der neuesten Studie von Microsoft wurde Transformer dieses Mal direkt auf 1 Milliarde Token erweitert. Dies eröffnet neue Möglichkeiten zur Modellierung sehr langer Sequenzen, beispielsweise die Behandlung eines gesamten Korpus oder sogar des gesamten Internets als eine Sequenz. Zum Vergleich: üblich
