
 Technologie-Peripheriegeräte
KI
Das Bild in Ihrem Gehirn kann jetzt in hoher Auflösung wiederhergestellt werden
Technologie-Peripheriegeräte
KI
Das Bild in Ihrem Gehirn kann jetzt in hoher Auflösung wiederhergestellt werden
Das Bild in Ihrem Gehirn kann jetzt in hoher Auflösung wiederhergestellt werden

In den letzten Jahren wurden große Fortschritte auf dem Gebiet der Bildgenerierung erzielt, insbesondere bei der Text-zu-Bild-Generierung: Solange wir Text verwenden, um unsere Gedanken zu beschreiben, kann KI neuartige und realistische Bilder erzeugen.
Aber tatsächlich können wir noch einen Schritt weiter gehen – der Schritt der Umwandlung von Ideen im Kopf in Text kann entfallen und die Entstehung von Bildern kann direkt durch Gehirnaktivität (wie z. B. EEG-Aufzeichnung (Elektroenzephalogramm)) gesteuert werden.
Diese „Thinking to Image“-Generierungsmethode hat breite Anwendungsaussichten. Beispielsweise kann es die Effizienz des künstlerischen Schaffens erheblich verbessern und Menschen dabei helfen, flüchtige Inspirationen einzufangen. Es kann auch möglich sein, die Träume von Menschen nachts zu visualisieren. Es kann sogar in der Psychotherapie eingesetzt werden, um autistischen Kindern und Patienten mit Sprachstörungen zu helfen.
Kürzlich haben Forscher der Tsinghua University Shenzhen International Graduate School, des Tencent AI Lab und des Pengcheng Laboratory gemeinsam eine Forschungsarbeit zum Thema „Thinking to Image“ veröffentlicht, bei der vorab trainierte Text-zu-Bild-Modelle (wie Stable Diffusion) verwendet wurden. Die leistungsstarken Generierungsfunktionen erzeugen hochwertige Bilder direkt aus EEG-Signalen.
 Bilder
Bilder
Papieradresse: https://arxiv.org/pdf/2306.16934.pdf
Projektadresse: https://github.com/bbaaii/DreamDiffusion
Ich thod-Übersicht
Einige neuere verwandte Forschungen (wie MinD-Vis) versuchen, visuelle Informationen auf der Grundlage von fMRT (Signalen der funktionellen Magnetresonanztomographie) zu rekonstruieren. Sie haben gezeigt, dass es möglich ist, die Gehirnaktivität zur Rekonstruktion hochwertiger Ergebnisse zu nutzen. Diese Methoden sind jedoch noch weit von der idealen Nutzung von Gehirnsignalen für eine schnelle und effiziente Erstellung entfernt. Dies hat hauptsächlich zwei Gründe:
Erstens sind fMRT-Geräte nicht tragbar und erfordern die Bedienung durch Fachpersonal, daher ist die Erfassung von fMRT-Signalen sehr schwierig schwierig;
Zweitens sind die Kosten für die fMRT-Datenerfassung hoch, was den Einsatz dieser Methode in der tatsächlichen Kunstschaffung stark behindern wird.
Im Gegensatz dazu ist EEG eine nicht-invasive, kostengünstige Methode zur Aufzeichnung der elektrischen Aktivität des Gehirns, und es gibt mittlerweile tragbare kommerzielle Produkte auf dem Markt, die EEG-Signale empfangen können.
Aber es gibt immer noch zwei große Herausforderungen bei der Erzeugung von „Gedanken-zu-Bildern“:
1) EEG-Signale werden mit nicht-invasiven Methoden erfasst und sind daher von Natur aus verrauscht. Darüber hinaus sind die EEG-Daten begrenzt und individuelle Unterschiede können nicht ignoriert werden. Wie kann man also unter so vielen Einschränkungen effektive und robuste semantische Darstellungen aus EEG-Signalen erhalten?
2) Text- und Bildräume in Stable Diffusion sind aufgrund der Verwendung von CLIP und des Trainings an einer großen Anzahl von Text-Bild-Paaren gut aufeinander abgestimmt. Allerdings haben EEG-Signale ihre eigenen Eigenschaften und ihr Raum unterscheidet sich deutlich von Text und Bildern. Wie lassen sich EEG-, Text- und Bildräume auf begrenzte und verrauschte EEG-Bildpaare ausrichten?
Um die erste Herausforderung anzugehen, schlägt diese Studie vor, große Mengen an EEG-Daten zum Trainieren von EEG-Darstellungen zu verwenden, anstatt nur seltene EEG-Bildpaare. Diese Studie verwendet eine maskierte Signalmodellierungsmethode, um fehlende Token basierend auf kontextuellen Hinweisen vorherzusagen.
Im Gegensatz zu MAE und MinD-Vis, die die Eingabe als zweidimensionales Bild behandeln und räumliche Informationen maskieren, berücksichtigt diese Studie die zeitlichen Eigenschaften des EEG-Signals und befasst sich eingehend mit der Semantik hinter den zeitlichen Veränderungen im menschlichen Gehirn . Diese Studie blockierte zufällig einen Teil der Token und rekonstruierte diese blockierten Token dann im Zeitbereich. Auf diese Weise ist der vorab trainierte Encoder in der Lage, ein tiefes Verständnis der EEG-Daten verschiedener Personen und unterschiedlicher Gehirnaktivitäten zu entwickeln.
Für die zweite Herausforderung optimieren frühere Lösungen das Modell der stabilen Diffusion normalerweise direkt, indem sie eine kleine Anzahl verrauschter Datenpaare für das Training verwenden. Es ist jedoch schwierig, eine genaue Ausrichtung zwischen Gehirnsignalen (z. B. EEG und fMRT) und Textraum zu erlernen, indem SD nur durchgängig durch den endgültigen Bildrekonstruktionsverlust feinabgestimmt wird. Daher schlug das Forschungsteam den Einsatz zusätzlicher CLIP-Überwachung vor, um die Ausrichtung von EEG-, Text- und Bildräumen zu erreichen.
Konkret verwendet SD selbst den Text-Encoder von CLIP, um Texteinbettungen zu generieren, was sich stark von den maskierten vorab trainierten EEG-Einbettungen der vorherigen Stufe unterscheidet. Nutzen Sie den Bild-Encoder von CLIP, um umfangreiche Bildeinbettungen zu extrahieren, die gut auf die Texteinbettungen von CLIP abgestimmt sind. Diese CLIP-Bildeinbettungen wurden dann verwendet, um die EEG-Einbettungsdarstellung weiter zu verfeinern. Daher können die verbesserten EEG-Funktionseinbettungen gut mit den Bild- und Texteinbettungen von CLIP abgestimmt werden und eignen sich besser für die SD-Bilderzeugung, wodurch die Qualität der generierten Bilder verbessert wird.
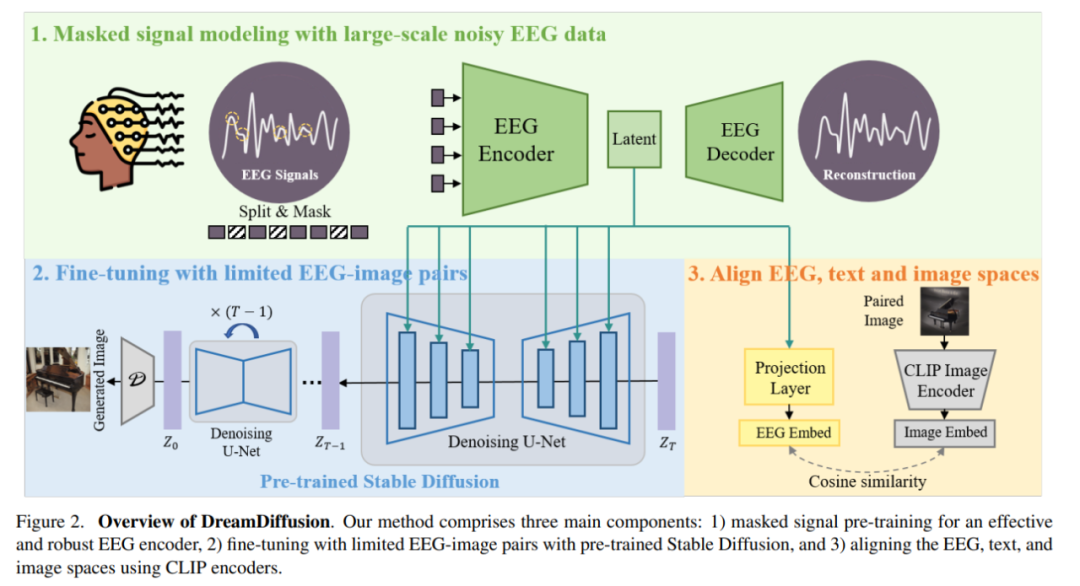
Basierend auf den beiden oben genannten sorgfältig entwickelten Lösungen schlägt diese Forschung eine neue Methode DreamDiffusion vor. DreamDiffusion generiert hochwertige und realistische Bilder aus Elektroenzephalogramm-Signalen (EEG).
 Bilder
Bilder
Im Einzelnen besteht DreamDiffusion hauptsächlich aus drei Teilen:
1) Maskieren Sie das Signal-Vortraining, um einen effektiven und robusten EEG-Encoder zu erreichen;
2) Verwenden Sie vorab trainierte Stable Diffusion und begrenzte EEG-Bildpaare zur Feinabstimmung;
3) Verwenden Sie den CLIP-Encoder, um EEG-, Text- und Bildräume auszurichten.
Zuerst nutzten die Forscher EEG-Daten mit viel Rauschen und nutzten Maskensignalmodellierung, um den EEG-Encoder zu trainieren und Kontextwissen zu extrahieren. Der resultierende EEG-Encoder wird dann verwendet, um über einen Kreuzaufmerksamkeitsmechanismus bedingte Merkmale für eine stabile Diffusion bereitzustellen.
 Bilder
Bilder
Um die Kompatibilität der EEG-Funktionen mit Stable Diffusion zu verbessern, richteten die Forscher das EEG, den Text und das Bild weiter aus, indem sie während der Feinabstimmung den Abstand zwischen der EEG-Einbettung und der CLIP-Bildeinbettung verringerten Prozess. Eingebetteter Raum.
Experimente und Analyse
Vergleich mit Brain2Image
Die Forscher verglichen die Methode in diesem Artikel mit Brain2Image. Brain2Image verwendet traditionelle generative Modelle, nämlich Variational Autoencoder (VAEs) und generative Adversarial Networks (GANs), für die Konvertierung von EEG in Bilder. Allerdings liefert Brain2Image nur Ergebnisse für wenige Kategorien und keine Referenzimplementierung.
Vor diesem Hintergrund führte diese Studie einen qualitativen Vergleich mehrerer im Brain2Image-Papier vorgestellter Kategorien durch (d. h. Flugzeuge, Kürbislaternen und Pandas). Um einen fairen Vergleich zu gewährleisten, verwendeten die Forscher dieselbe Bewertungsstrategie wie im Brain2Image-Artikel beschrieben und zeigen die mit den verschiedenen Methoden generierten Ergebnisse in Abbildung 5 unten.
Die erste Zeile der folgenden Abbildung zeigt die von Brain2Image generierten Ergebnisse, und die letzte Zeile wird von DreamDiffusion generiert, der von den Forschern vorgeschlagenen Methode. Es ist ersichtlich, dass die von DreamDiffusion erzeugte Bildqualität deutlich höher ist als die von Brain2Image, was auch die Wirksamkeit dieser Methode bestätigt.
 Bilder
Bilder
Ablationsexperiment
Die Rolle des Vortrainings: Um die Wirksamkeit eines groß angelegten EEG-Daten-Vortrainings zu demonstrieren, wurden in dieser Studie ungeschulte Encoder zum Trainieren verwendet Validieren Sie mehrere Modelle. Eines der Modelle war identisch mit dem vollständigen Modell, während das andere Modell nur zwei EEG-Kodierungsschichten hatte, um eine Überanpassung an die Daten zu vermeiden. Während des Trainingsprozesses wurden die beiden Modelle mit bzw. ohne CLIP-Überwachung trainiert. Die Ergebnisse sind in den Spalten 1 bis 4 des Modells in Tabelle 1 aufgeführt. Es ist ersichtlich, dass die Genauigkeit des Modells ohne Vortraining abnimmt.
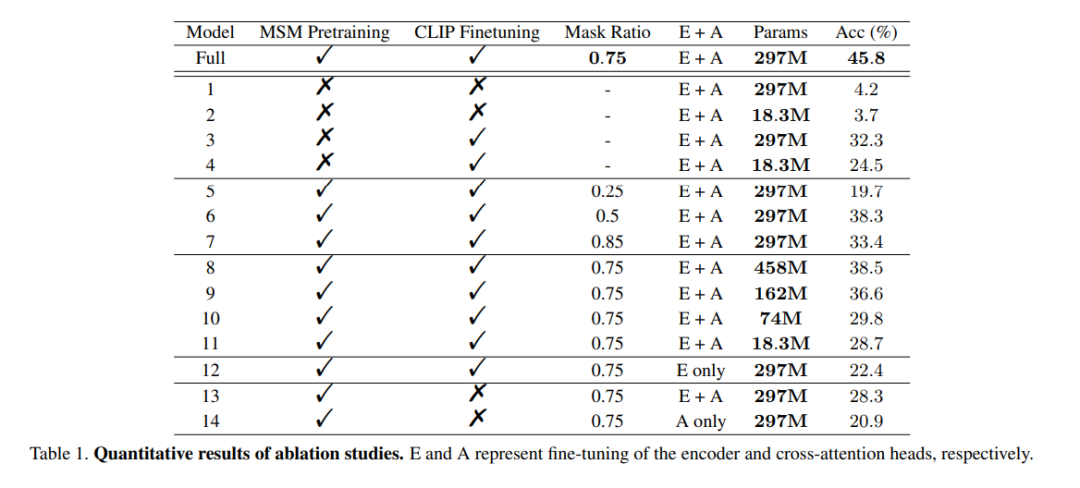
Maskenverhältnis: In diesem Artikel wird auch die Verwendung von EEG-Daten untersucht, um das optimale Maskenverhältnis für das MSM-Vortraining zu bestimmen. Wie in den Spalten 5 bis 7 des Modells in Tabelle 1 dargestellt, kann ein zu hohes oder zu niedriges Maskenverhältnis die Modellleistung beeinträchtigen. Die höchste Gesamtgenauigkeit wird erreicht, wenn das Maskenverhältnis 0,75 beträgt. Dieses Ergebnis ist von entscheidender Bedeutung, da es darauf hindeutet, dass im Gegensatz zur Verarbeitung natürlicher Sprache, bei der normalerweise niedrige Maskenverhältnisse verwendet werden, hohe Maskenverhältnisse die bessere Wahl sind, wenn MSM im EEG durchgeführt wird.
CLIP-Ausrichtung: Einer der Schlüssel zu dieser Methode besteht darin, die EEG-Darstellung über einen CLIP-Encoder am Bild auszurichten. In dieser Studie wurden Experimente durchgeführt, um die Wirksamkeit dieser Methode zu überprüfen. Die Ergebnisse sind in Tabelle 1 aufgeführt. Es ist zu beobachten, dass die Leistung des Modells erheblich abnimmt, wenn die CLIP-Überwachung nicht verwendet wird. Tatsächlich kann die Verwendung von CLIP zum Ausrichten von EEG-Merkmalen, wie in der unteren rechten Ecke von Abbildung 6 dargestellt, auch ohne vorheriges Training noch zu vernünftigen Ergebnissen führen, was die Bedeutung der CLIP-Überwachung bei dieser Methode unterstreicht.
 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonDas Bild in Ihrem Gehirn kann jetzt in hoher Auflösung wiederhergestellt werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So wählen Sie eine Gitlab -Datenbank in CentOS aus
Apr 14, 2025 pm 05:39 PM
So wählen Sie eine Gitlab -Datenbank in CentOS aus
Apr 14, 2025 pm 05:39 PM
Bei der Installation und Konfiguration von GitLab in einem CentOS -System ist die Auswahl der Datenbank von entscheidender Bedeutung. GitLab ist mit mehreren Datenbanken kompatibel, aber PostgreSQL und MySQL (oder MariADB) werden am häufigsten verwendet. Dieser Artikel analysiert Datenbankauswahlfaktoren und enthält detaillierte Installations- und Konfigurationsschritte. Datenbankauswahlhandbuch Bei der Auswahl einer Datenbank müssen Sie die folgenden Faktoren berücksichtigen: PostgreSQL: Die Standarddatenbank von GitLab ist leistungsstark, hat eine hohe Skalierbarkeit, unterstützt komplexe Abfragen und Transaktionsverarbeitung und ist für große Anwendungsszenarien geeignet. MySQL/Mariadb: Eine beliebte relationale Datenbank, die in Webanwendungen häufig verwendet wird, mit einer stabilen und zuverlässigen Leistung. MongoDB: NoSQL -Datenbank, spezialisiert auf
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
