
 Backend-Entwicklung
PHP-Tutorial
Anwendungsfälle von PhpFastCache bei API-Aufrufen mit hoher Parallelität
Backend-Entwicklung
PHP-Tutorial
Anwendungsfälle von PhpFastCache bei API-Aufrufen mit hoher Parallelität
Anwendungsfälle von PhpFastCache bei API-Aufrufen mit hoher Parallelität

Anwendungsfälle von PhpFastCache bei API-Aufrufen mit hoher Parallelität
Übersicht:
In der modernen Webentwicklung sind API-Aufrufe mit hoher Parallelität eine häufige Anforderung. Um eine große Anzahl von Anfragen effektiv zu bearbeiten und die Belastung der Datenbank zu reduzieren, ist Caching eine sehr wichtige Lösung. PhpFastCache ist als Caching-Bibliothek in der PHP-Sprache einfach zu verwenden, weist eine hohe Leistung auf und wird häufig in API-Aufrufen mit hoher Parallelität verwendet. In diesem Artikel wird die Verwendung von PhpFastCache anhand eines praktischen Falls vorgestellt.
Fallbeschreibung:
Angenommen, wir möchten eine API für eine E-Commerce-Website entwickeln und diese API muss Produktdetails zurückgeben. Da Produktdetails komplex sind und eine Vielzahl von Datenbankabfragen und Berechnungen beinhalten, verbraucht jede Anfrage viele Ressourcen. Um die Leistung zu verbessern, haben wir uns entschieden, PhpFastCache zum Zwischenspeichern von Produktdetails zu verwenden.
Codebeispiel:
Zuerst müssen wir die PhpFastCache-Bibliothek installieren. Es kann über Composer installiert werden. Führen Sie den folgenden Befehl aus:
composer require phpfastcache/phpfastcache
Führen Sie dann die PhpFastCache-Bibliothek in unseren API-Code ein:
require_once 'vendor/autoload.php';
use PhpfastcacheHelperPsr16Adapter;
// 创建一个名为"product_cache"的缓存对象
$cache = new Psr16Adapter('product_cache');Als nächstes können wir die folgenden Schritte ausführen, um den Cache zu verwenden:
Überprüfen Sie, ob der Cache vorhanden ist existiert:
$product_id = $_GET['product_id']; if ($cache->has($product_id)) { // 缓存存在,直接从缓存中获取商品详情 $product = $cache->get($product_id); echo json_encode($product); return; }Nach dem Login kopierenWenn der Cache nicht existiert, holen Sie sich die Produktdetails aus der Datenbank und speichern Sie sie im Cache:
// 数据库查询逻辑 $product = queryProductDetails($product_id); // 将商品详情存入缓存,缓存时间设置为1小时 $cache->set($product_id, $product, 3600); // 返回商品详情 echo json_encode($product);
Nach dem Login kopierenAnhand des obigen Codebeispiels können wir sehen, dass wir bei jedem API-Aufruf zuerst Überprüfen Sie, ob das Produkt im Cache vorhanden ist. Detaillierte Informationen. Wenn sie vorhanden sind, werden die zwischengespeicherten Daten direkt zurückgegeben. Wenn sie nicht vorhanden sind, werden die Produktdetails aus der Datenbank abgerufen und für die nächste Verwendung im Cache gespeichert. Dies kann die Belastung der Datenbank erheblich reduzieren und die Antwortgeschwindigkeit der API verbessern.
Zusammenfassung:
Dieser Artikel stellt die Anwendungsmethode von PhpFastCache in API-Aufrufen mit hoher Parallelität anhand eines praktischen Falls vor. Durch die Verwendung von PhpFastCache können wir auf einfache Weise leistungsstarke Caching-Funktionen implementieren, die Belastung der Datenbank reduzieren und die Reaktionsgeschwindigkeit der API verbessern. Ich hoffe, dass dieser Artikel jedem hilft, die Anwendung von PhpFastCache zu verstehen.Das obige ist der detaillierte Inhalt vonAnwendungsfälle von PhpFastCache bei API-Aufrufen mit hoher Parallelität. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

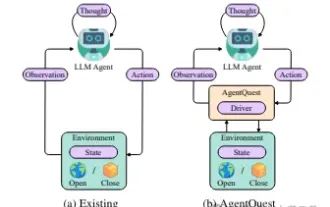 Erkundung der Grenzen von Agenten: AgentQuest, ein modulares Benchmark-Framework zur umfassenden Messung und Verbesserung der Leistung großer Sprachmodellagenten
Apr 11, 2024 pm 08:52 PM
Erkundung der Grenzen von Agenten: AgentQuest, ein modulares Benchmark-Framework zur umfassenden Messung und Verbesserung der Leistung großer Sprachmodellagenten
Apr 11, 2024 pm 08:52 PM
Basierend auf der kontinuierlichen Optimierung großer Modelle haben LLM-Agenten – diese leistungsstarken algorithmischen Einheiten – das Potenzial gezeigt, komplexe mehrstufige Argumentationsaufgaben zu lösen. Von der Verarbeitung natürlicher Sprache bis hin zum Deep Learning rücken LLM-Agenten nach und nach in den Fokus von Forschung und Industrie. Sie können nicht nur menschliche Sprache verstehen und generieren, sondern auch Strategien formulieren, Aufgaben in verschiedenen Umgebungen ausführen und sogar API-Aufrufe und Codierung zum Erstellen verwenden Lösungen. In diesem Zusammenhang ist die Einführung des AgentQuest-Frameworks ein Meilenstein. Es bietet nicht nur eine modulare Benchmarking-Plattform für die Bewertung und Weiterentwicklung von LLM-Agenten, sondern bietet Forschern auch leistungsstarke Tools, um die Leistung dieser Agenten gleichzeitig zu verfolgen und zu verbessern granularerer Ebene
 Die Architektur des Golang-Frameworks in Systemen mit hoher Parallelität
Jun 03, 2024 pm 05:14 PM
Die Architektur des Golang-Frameworks in Systemen mit hoher Parallelität
Jun 03, 2024 pm 05:14 PM
Für Systeme mit hoher Parallelität bietet das Go-Framework Architekturmodi wie den Pipeline-Modus, den Goroutine-Pool-Modus und den Nachrichtenwarteschlangenmodus. In der Praxis verwenden Websites mit hoher Parallelität Nginx-Proxy, Golang-Gateway, Goroutine-Pool und Datenbank, um eine große Anzahl gleichzeitiger Anforderungen zu verarbeiten. Das Codebeispiel zeigt die Implementierung eines Goroutine-Pools zur Bearbeitung eingehender Anfragen. Durch die Auswahl geeigneter Architekturmuster und Implementierungen kann das Go-Framework skalierbare und hochgradig gleichzeitige Systeme mit hoher Parallelität erstellen.
 Kann von Mingw kompilierte Software in einer Linux-Umgebung verwendet werden?
Mar 20, 2024 pm 05:06 PM
Kann von Mingw kompilierte Software in einer Linux-Umgebung verwendet werden?
Mar 20, 2024 pm 05:06 PM
Kann von Mingw kompilierte Software in einer Linux-Umgebung verwendet werden? Mingw ist eine Toolkette, die auf der Windows-Plattform zum Kompilieren und Generieren von Programmen verwendet wird, die unter Windows ausgeführt werden können. Kann die von Mingw kompilierte Software also in der Linux-Umgebung verwendet werden? Die Antwort ist ja, aber es erfordert einige zusätzliche Arbeiten und Schritte. Die gebräuchlichste Möglichkeit, unter Windows kompilierte Programme unter Linux auszuführen, ist die Verwendung von Wine. Wine ist ein Tool, das in Linux und anderen ähnlichen Un verwendet wird
 Leistung des PHP-Frameworks in Szenarien mit hoher Parallelität
Jun 06, 2024 am 10:25 AM
Leistung des PHP-Frameworks in Szenarien mit hoher Parallelität
Jun 06, 2024 am 10:25 AM
In Szenarien mit hoher Parallelität beträgt die Leistung des PHP-Frameworks laut Benchmark-Tests: Phalcon (RPS2200), Laravel (RPS1800), CodeIgniter (RPS2000) und Symfony (RPS1500). Tatsächliche Fälle zeigen, dass das Phalcon-Framework während des Double Eleven-Events auf der E-Commerce-Website 3.000 Bestellungen pro Sekunde erreichte.
 Sehen Sie sich Ihre Litecoin-Wallet-Adresse an
Apr 07, 2024 pm 05:12 PM
Sehen Sie sich Ihre Litecoin-Wallet-Adresse an
Apr 07, 2024 pm 05:12 PM
Um die Litecoin-Wallet-Adresse anzuzeigen, besuchen Sie die Litecoin-Wallet und suchen Sie auf der Registerkarte „Empfangen“ nach der Adresse. Sie können auch einen Blockchain-Browser oder einen API-Aufruf verwenden.
 Anwendung von Golang-Funktionen in Szenarien mit hoher Parallelität in der objektorientierten Programmierung
Apr 30, 2024 pm 01:33 PM
Anwendung von Golang-Funktionen in Szenarien mit hoher Parallelität in der objektorientierten Programmierung
Apr 30, 2024 pm 01:33 PM
In Szenarien mit hoher Parallelität der objektorientierten Programmierung werden Funktionen häufig in der Go-Sprache verwendet: Funktionen als Methoden: Funktionen können an Strukturen angehängt werden, um objektorientierte Programmierung zu implementieren, Strukturdaten bequem zu bedienen und spezifische Funktionen bereitzustellen. Funktionen als gleichzeitige Ausführungskörper: Funktionen können als Goroutine-Ausführungskörper verwendet werden, um die gleichzeitige Aufgabenausführung zu implementieren und die Programmeffizienz zu verbessern. Funktion als Rückruf: Funktionen können als Parameter an andere Funktionen übergeben und aufgerufen werden, wenn bestimmte Ereignisse oder Vorgänge auftreten, wodurch ein flexibler Rückrufmechanismus bereitgestellt wird.
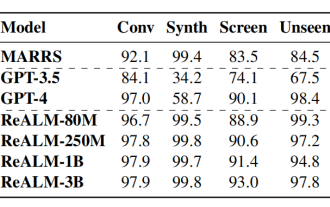 Lass Siri nicht länger geistig zurückgeblieben sein! Apple definiert ein neues geräteseitiges Modell, das „viel besser als GPT-4' ist. Es verzichtet auf Text und simuliert Bildschirminformationen immer noch 5 % besser als das Basissystem.
Apr 02, 2024 pm 09:20 PM
Lass Siri nicht länger geistig zurückgeblieben sein! Apple definiert ein neues geräteseitiges Modell, das „viel besser als GPT-4' ist. Es verzichtet auf Text und simuliert Bildschirminformationen immer noch 5 % besser als das Basissystem.
Apr 02, 2024 pm 09:20 PM
Geschrieben von Noah |. 51CTO Technology Stack (WeChat ID: blog51cto) Siri, die von Nutzern immer als „etwas geistig zurückgeblieben“ kritisiert wird, kann gerettet werden! Siri gehört seit seiner Geburt zu den Vertretern auf dem Gebiet der intelligenten Sprachassistenten, doch seine Leistung ist seit langem unbefriedigend. Allerdings wird erwartet, dass die neuesten Forschungsergebnisse des Apple-Teams für künstliche Intelligenz den Status quo deutlich verändern werden. Diese Ergebnisse sind aufregend und wecken große Erwartungen für die Zukunft dieses Bereichs. In entsprechenden Forschungsarbeiten beschreiben die KI-Experten von Apple ein System, mit dem Siri mehr kann, als nur Inhalte in Bildern zu identifizieren, und dadurch intelligenter und nützlicher wird. Dieses Funktionsmodell heißt ReALM, basiert auf dem GPT4.0-Standard und verfügt über eine
 Zusammenfassung der FAQs für die Verwendung von Deepseek
Feb 19, 2025 pm 03:45 PM
Zusammenfassung der FAQs für die Verwendung von Deepseek
Feb 19, 2025 pm 03:45 PM
Deepseekai Tool User Guide und FAQ Deepseek ist ein leistungsstarkes KI -Intelligent -Tool. FAQ: Der Unterschied zwischen verschiedenen Zugriffsmethoden: Es gibt keinen Unterschied in der Funktion zwischen Webversion, App -Version und API -Aufrufen, und App ist nur ein Wrapper für die Webversion. Die lokale Bereitstellung verwendet ein Destillationsmodell, das der Vollversion von Deepseek-R1 geringfügig unteren ist, das 32-Bit-Modell theoretisch 90% Vollversionsfunktion. Was ist eine Taverne? SillyTervern ist eine Front-End-Oberfläche, die das KI-Modell über API oder Ollama anruft. Was ist Breaking Limit
