
 Technologie-Peripheriegeräte
KI
Ein neues Ventil für KI? Das erste hochwertige „Vinson Video'-Modell Zeroskop löst einen Open-Source-Krieg aus: Es kann mit mindestens 8G Videospeicher laufen
Technologie-Peripheriegeräte
KI
Ein neues Ventil für KI? Das erste hochwertige „Vinson Video'-Modell Zeroskop löst einen Open-Source-Krieg aus: Es kann mit mindestens 8G Videospeicher laufen
Ein neues Ventil für KI? Das erste hochwertige „Vinson Video'-Modell Zeroskop löst einen Open-Source-Krieg aus: Es kann mit mindestens 8G Videospeicher laufen

Nachdem das Vincent-Grafikmodell Stable Diffusion als Open Source verfügbar ist, wurde die „KI-Kunst“ vollständig demokratisiert. Nur mit einer Consumer-Grafikkarte können sehr schöne Bilder erstellt werden.
Im Bereich der Text-zu-Video-Konvertierung ist Runway derzeit das einzige hochwertige kommerzielle Gen-2-Modell, das vor nicht allzu langer Zeit auf den Markt gebracht wurde, und es gibt kein Modell, das in der Open-Source-Branche mithalten kann.
Kürzlich hat ein Autor auf Huggingface ein Text-zu-Video-Synthesemodell Zeroskop_v2 veröffentlicht, das auf der Grundlage des ModelScope-Text-zu-Video-Synthesemodells mit 1,7 Milliarden Parametern entwickelt wurde.
 Bilder
Bilder
Modelllink: https://huggingface.co/cerspense/zerscope_v2_576w
Im Vergleich zur Originalversion weist das von Zeroskop generierte Video kein Wasserzeichen auf und die Glätte und Auflösung sind verbessert Verbessert zur Anpassung an das Seitenverhältnis 16:9.
Entwickler Cerspense sagte, sein Ziel sei es, mit Gen-2 als Open Source zu konkurrieren, das heißt, während die Qualität des Modells verbessert wird, kann es auch von der Öffentlichkeit frei genutzt werden.
Zeroskop_v2 umfasst zwei Versionen. Unter anderem kann Zeroskop_v2 567w schnell ein Video mit einer Auflösung von 576 x 320 Pixeln und einer Bildrate von 30 Bildern/Sekunde erstellen. Es kann zur schnellen Überprüfung von Videokonzepten verwendet werden und erfordert nur etwa 7,9 GB Videospeicher zur Ausführung.
Verwenden Sie Zeroskop_v2 XL, um hochauflösende Videos mit einer Auflösung von 1024 x 576 zu generieren und etwa 15,3 GB Videospeicher zu belegen.
Zeroskop kann auch mit dem Musikgenerierungstool MusicGen verwendet werden, um schnell ein rein originelles Kurzvideo zu erstellen.
Das Training des Zeroskop-Modells verwendet 9923 Videoclips (Clips) und 29769 kommentierte Frames, wobei jeder Clip 24 Frames umfasst. Offset-Rauschen umfassen zufällige Verschiebungen von Objekten innerhalb von Videobildern, leichte Änderungen im Bild-Timing oder kleine Verzerrungen.
Die Einführung von Rauschen während des Trainings kann das Verständnis des Modells für die Datenverteilung verbessern, sodass es vielfältigere und realistischere Videos erstellen und Änderungen in Textbeschreibungen effektiver erklären kann.
So verwenden Sie
Verwenden Sie Stable Diffusion WebUI
Laden Sie die Gewichtsdatei im zs2_XL-Verzeichnis auf Huggingface herunter und legen Sie sie dann im Stable-Diffusion-WebuimodelsModelScopet2v-Verzeichnis ab.
Beim Erstellen von Videos beträgt der empfohlene Intensitätswert für die Rauschunterdrückung 0,66 bis 0,85. drive/1TsZmatSu1-1lNBeOqz3_9Zq5P2c0xTTq?usp=sharing
Klicken Sie zunächst unter Schritt 1 auf die Schaltfläche „Ausführen“ und warten Sie auf die Installation, die etwa 3 Minuten dauert;Bild
Bilder
Klicken Sie auf die Schaltfläche „Ausführen“ neben dem Modell, das Sie installieren möchten. Um schnell ein 3-Sekunden-bearbeitetes Video in Colab zu erhalten, wird empfohlen, ein ZeroScope-Modell mit niedriger Auflösung (576 oder) zu verwenden 448). 
Bilder
erfordern einen Kompromiss aus längeren Ausführungszeiten, wenn Modelle mit höherer Auflösung wie Potat 1 oder ZeroScope XL ausgeführt werden. 
Wählen Sie das in Schritt 2 installierte Modell aus und möchten Sie es verwenden. Für Modelle mit höherer Auflösung werden die folgenden Konfigurationsparameter empfohlen, die keine zu lange Generierungszeit erfordern.

Als nächstes können Sie die Aufforderungswörter des Zielvideos eingeben, um den Effekt zu ändern. Sie können auch negative Aufforderungen (negative Aufforderungen) eingeben und dann auf die Schaltfläche „Ausführen“ klicken.
Nachdem Sie eine Weile gewartet haben, wird das generierte Video im Ausgabeverzeichnis abgelegt.
Bilder Derzeit steckt der Bereich Vincent Video noch in den Kinderschuhen und selbst die besten Tools können nur wenige Sekunden lange Videos erzeugen und weisen oft große visuelle Mängel auf. Aber tatsächlich hatte das vinzentinische Modell zunächst mit ähnlichen Problemen zu kämpfen, doch schon wenige Monate später erreichte es den Fotorealismus. Im Gegensatz zum vinzentinischen Graphenmodell erfordert der Videobereich jedoch beim Training und der Generierung mehr Ressourcen als Bilder. Obwohl Google Phenaki- und Imagen-Video-Modelle entwickelt hat, die hochauflösende, längere und logisch zusammenhängende Videoclips generieren können, sind diese beiden Modelle nicht für die Öffentlichkeit verfügbar; Metas Make-a-Video-Modell ist ebenfalls nicht veröffentlicht . Die derzeit verfügbaren Tools sind immer noch nur das kommerzielle Modell Gen-2 von Runway. Die Veröffentlichung von Zeroskop markiert auch die Entstehung des ersten hochwertigen Open-Source-Modells im Vincent-Videobereich. 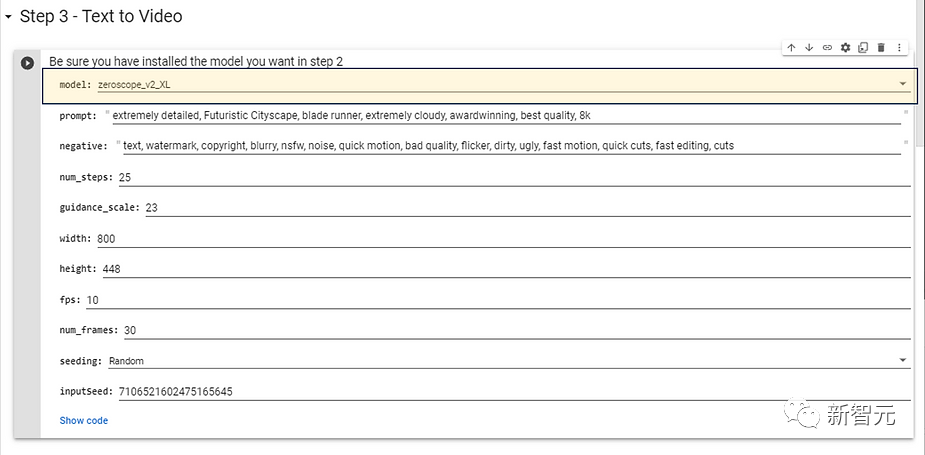
Open-Source-Wettbewerb „Vincent Video“
Das obige ist der detaillierte Inhalt vonEin neues Ventil für KI? Das erste hochwertige „Vinson Video'-Modell Zeroskop löst einen Open-Source-Krieg aus: Es kann mit mindestens 8G Videospeicher laufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
