


Nachrichten vom 11. Juli: Microsoft hat kürzlich eine Pressemitteilung herausgegeben und das Composable Diffusion Model (CoDi) eingeführt, ein einzigartiges Modell der künstlichen Intelligenz, das auf kombinierbarer Diffusion basiert. Sein Designziel besteht darin, multimodale Inhalte zu interagieren und zu generieren.
Microsoft hat CoDi entwickelt, um die Einschränkungen traditioneller Single-Modal-KI-Modelle zu beseitigen. Am Beispiel synchronisierter Video- und Audiodaten kann es zu Inkonsistenzen und Ausrichtungsproblemen kommen, wenn unabhängig generierte Informationsströme zusammengefügt werden.
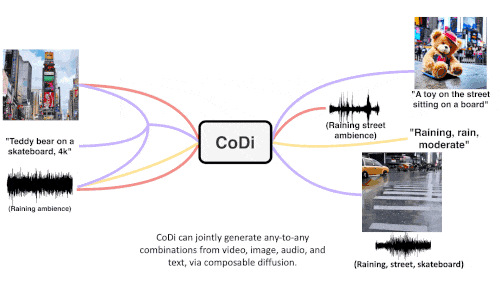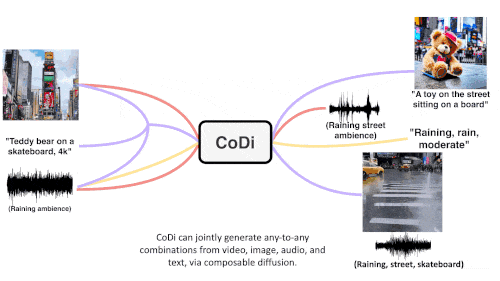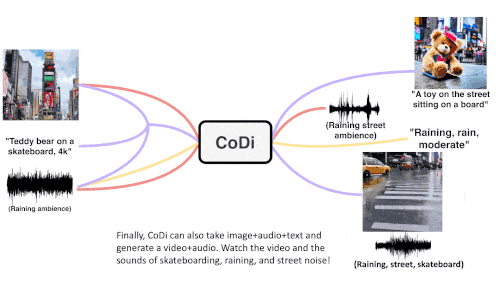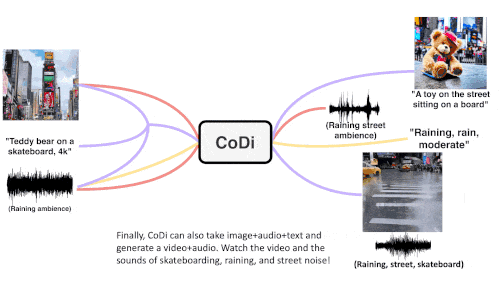
CoDi verwendet eine einzigartige kombinierbare Generierungsstrategie, um mehrere Modalitäten während des Diffusionsprozesses auszurichten, um miteinander verflochtene Muster zu erzeugen. Noch wichtiger ist, dass CoDi in der Lage ist, beliebige Eingabemodi zu verarbeiten und Inhalte beliebiger Modalität zu generieren.
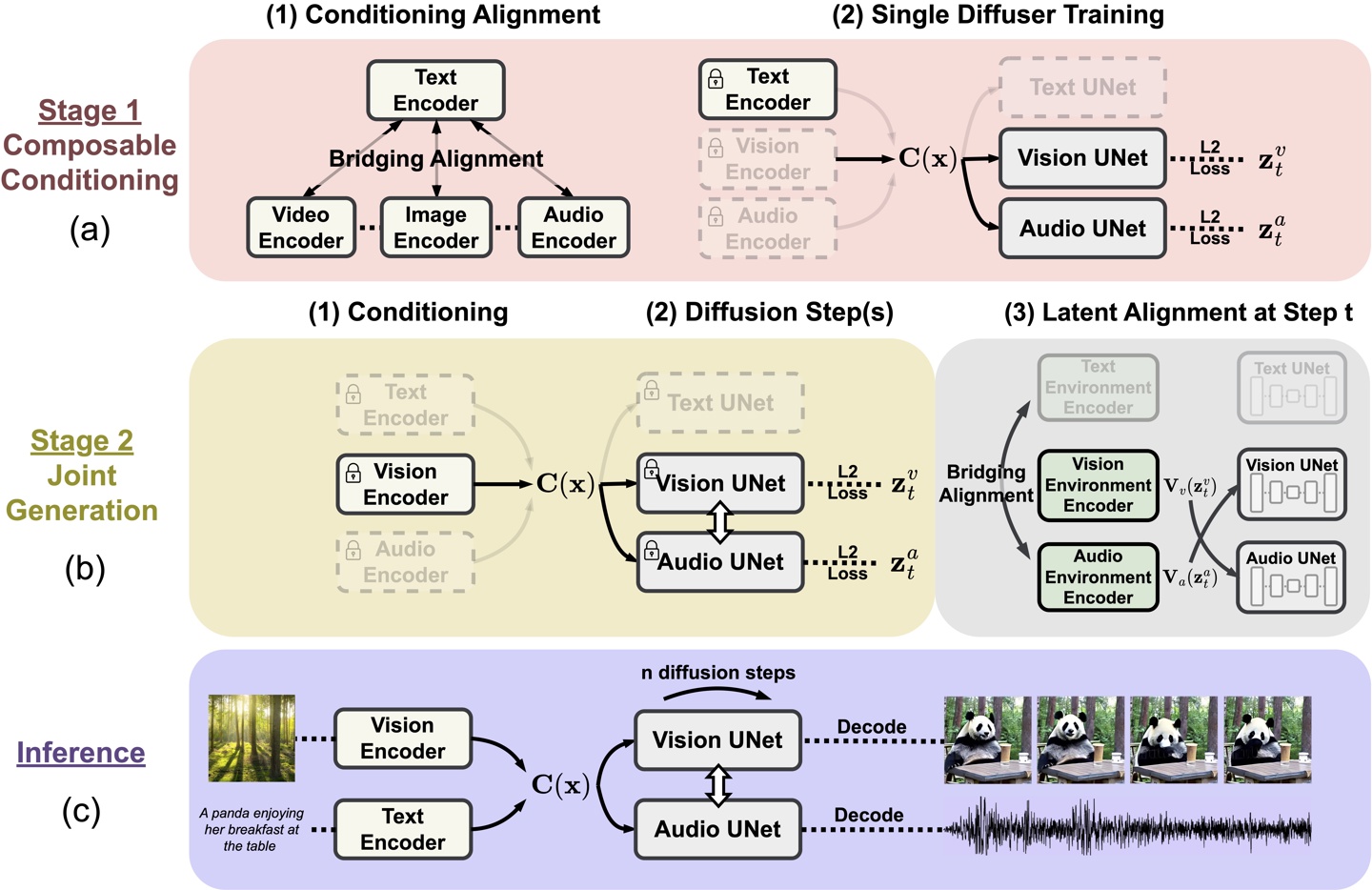
CoDi wurde vom Microsoft Azure Cognitive Services-Forschungsteam in Zusammenarbeit mit der University of North Carolina in Chapel Hill entwickelt und ist Teil von Microsofts Project i-Code, das künstliche Intelligenz nutzt, um die Mensch-Computer-Interaktion zu verbessern.
IT Home fügt hier den offiziellen Einführungslink des CoDi-Projekts hinzu Interessierte Benutzer können ausführlich lesen.
Das obige ist der detaillierte Inhalt vonMicrosoft führt das künstliche Intelligenzmodell CoDi ein, um multimodale Inhalte zu interagieren und zu generieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Plattform ist Kuai Tuan Tuan?
Welche Plattform ist Kuai Tuan Tuan?
 Selbststudium für Anfänger in C-Sprache ohne Grundkenntnisse
Selbststudium für Anfänger in C-Sprache ohne Grundkenntnisse
 So verwenden Sie die Imfinfo-Funktion
So verwenden Sie die Imfinfo-Funktion
 regulärer Perl-Ausdruck
regulärer Perl-Ausdruck
 So konvertieren Sie PDF-Dateien in PDF
So konvertieren Sie PDF-Dateien in PDF
 Lösungen für verstümmelte chinesische Schriftzeichen
Lösungen für verstümmelte chinesische Schriftzeichen
 Der Unterschied zwischen PHP und JS
Der Unterschied zwischen PHP und JS
 Wie man Douyin Xiaohuoren verkleidet
Wie man Douyin Xiaohuoren verkleidet








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



