
 Technologie-Peripheriegeräte
KI
BLIP-2 und InstructBLIP sind fest unter den ersten drei! Zwölf Hauptmodelle, sechzehn Listen, umfassende Bewertung des „multimodalen großen Sprachmodells'
Technologie-Peripheriegeräte
KI
BLIP-2 und InstructBLIP sind fest unter den ersten drei! Zwölf Hauptmodelle, sechzehn Listen, umfassende Bewertung des „multimodalen großen Sprachmodells'
BLIP-2 und InstructBLIP sind fest unter den ersten drei! Zwölf Hauptmodelle, sechzehn Listen, umfassende Bewertung des „multimodalen großen Sprachmodells'

Das Multimodal Large Language Model (MLLM) stützt sich auf den umfangreichen Wissensvorrat und die leistungsstarken Argumentations- und Generalisierungsfähigkeiten von LLM, um multimodale Probleme zu lösen, wie z. B. das Betrachten von Bildern und das Betrachten von Bildern und das Schreiben von Code.
Aber es ist schwierig, die Leistung von MLLM allein anhand dieser Beispiele vollständig darzustellen, und es mangelt immer noch an einer umfassenden Bewertung von MLLM.
Zu diesem Zweck führten Tencent Youtu Lab und die Universität Xiamen erstmals eine umfassende quantitative Bewertung von 12 bestehenden Open-Source-MLLM-Modellen auf dem neu erstellten Bewertungsbenchmark MM durch und veröffentlichten 16 Rankings, darunter sowohl die Wahrnehmungs- als auch die Kognitions-Gesamtliste und 14 Unterlisten:

Papierlink: https://arxiv.org/pdf/2306.13394.pdf
Projektlink: https://github.com/BradyFU/Awesome -Multimodal- Large-Language-Models/tree/Evaluation
Die bestehenden quantitativen Bewertungsmethoden von MLLM sind hauptsächlich in drei Kategorien unterteilt, aber alle weisen gewisse Einschränkungen auf, die es schwierig machen, ihre Leistung vollständig abzubilden.
Die erste Kategorie von Methoden wird anhand traditioneller öffentlicher Datensätze evaluiert, z. B. Bildunterschriften und VQA-Datensätzen (Visual Question Answering).
Aber einerseits sind diese traditionellen Datensätze möglicherweise nicht in der Lage, die neuen Fähigkeiten widerzuspiegeln, die sich aus MLLM ergeben. Andererseits ist dies schwierig, da die Trainingssätze im Zeitalter der großen Modelle nicht mehr einheitlich sind garantieren, dass diese Bewertungsdatensätze nicht von anderen MLLMs trainiert wurden.
Die zweite Möglichkeit besteht darin, neue Daten zur offenen Auswertung zu sammeln, diese Daten sind jedoch entweder nicht öffentlich [1] oder die Anzahl ist zu gering (nur 50 Bilder) [2].
Die dritte Methode konzentriert sich auf einen bestimmten Aspekt von MLLM, wie z. B. Objekthalluzination [3] oder gegnerische Robustheit [4], und kann nicht vollständig bewertet werden.
Es besteht dringender Bedarf an einem umfassenden Bewertungsmaßstab, der der rasanten Entwicklung von MLLM gerecht wird. Forscher glauben, dass ein universeller umfassender Bewertungsmaßstab die folgenden Merkmale aufweisen sollte:
(1) Er sollte einen möglichst großen Bereich abdecken, einschließlich Wahrnehmung und kognitiven Fähigkeiten. Ersteres bezieht sich auf die Identifizierung von Objekten, einschließlich ihrer Existenz, Menge, Position und Farbe. Letzteres bezieht sich auf die Integration sensorischer Informationen und Wissen im LLM, um komplexere Überlegungen anzustellen. Ersteres ist die Grundlage für Letzteres.
(2) Daten oder Anmerkungen sollten die Verwendung vorhandener öffentlicher Datensätze so weit wie möglich vermeiden, um das Risiko von Datenlecks zu verringern.
(3) Anweisungen sollten so prägnant wie möglich sein und mit den kognitiven Gewohnheiten des Menschen übereinstimmen. Unterschiedliche Befehlsdesigns können die Ausgabe des Modells stark beeinflussen, alle Modelle werden jedoch anhand einheitlicher und prägnanter Anweisungen bewertet, um Fairness zu gewährleisten. Ein gutes MLLM-Modell sollte in der Lage sein, solche präzisen Anweisungen zu verallgemeinern, um nicht in die Prompt-Engineering-Ära zu verfallen.
(4) Die Ausgabe von MLLM im Rahmen dieser prägnanten Anleitung sollte für quantitative Statistiken intuitiv und praktisch sein. Die offenen Antworten des MLLM stellen die quantitative Statistik vor große Herausforderungen. Bestehende Methoden verwenden in der Regel GPT oder manuelles Scoring, können jedoch mit Problemen der Ungenauigkeit und Subjektivität konfrontiert sein.
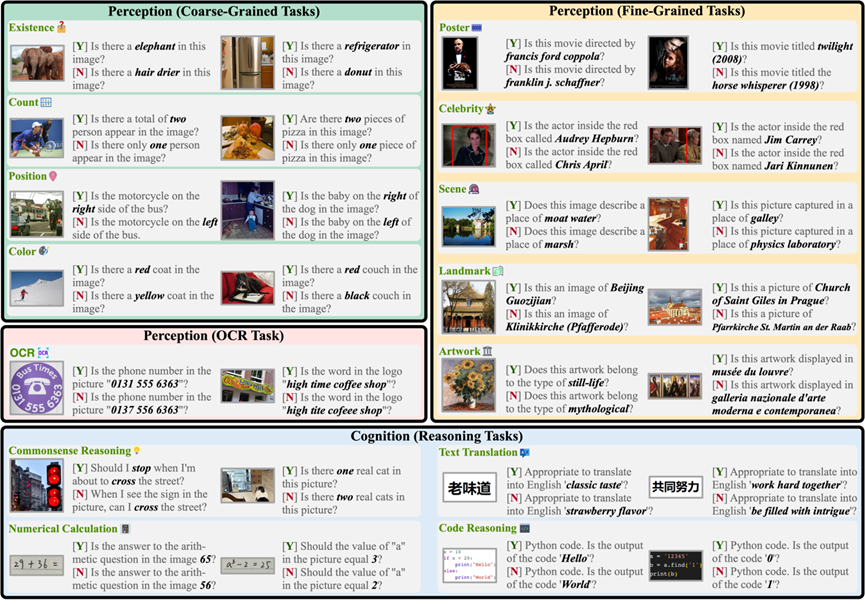
Abbildung 1. Beispiel für einen MME-Bewertungsbenchmark. Jedes Bild entspricht zwei Fragen und die Antworten lauten Ja[J] bzw. Nein[N]. Die Frage und „Bitte antworten Sie mit Ja oder Nein“ bilden zusammen den Befehl.
Basierend auf den oben genannten Gründen wurde ein neuer MLLM-Bewertungsbenchmark MME erstellt, der gleichzeitig die oben genannten vier Merkmale aufweist:
1. MME bewertet gleichzeitig Wahrnehmung und kognitive Fähigkeiten. Zusätzlich zur OCR umfassen die Erfassungsfunktionen eine grobkörnige und feinkörnige Zielerkennung. Ersteres identifiziert das Vorhandensein, die Menge, den Ort und die Farbe von Objekten. Letzteres identifiziert Filmplakate, Prominente, Szenen, Sehenswürdigkeiten und Kunstwerke. Zu den kognitiven Fähigkeiten gehören gesundes Denken, numerische Berechnungen, Textübersetzung und Codeschlussfolgerung. Die Gesamtzahl der Unteraufgaben beträgt 14, wie in Abbildung 1 dargestellt.
2. Alle Befehl-Antwort-Paare in MME werden manuell erstellt. Für die wenigen verwendeten öffentlich zugänglichen Datensätze wurden nur deren Bilder verwendet, ohne sich auf ihre Originalanmerkungen zu verlassen. Gleichzeitig versuchen Forscher ihr Bestes, Daten durch manuelle Fotografie und Bilderzeugung zu sammeln.
3. MME-Anweisungen sind so prägnant wie möglich gestaltet, um die Auswirkungen von Prompt Engineering auf die Modellausgabe zu vermeiden. Die Forscher bekräftigen, dass ein gutes MLLM auf solch prägnante und häufig verwendete Anweisungen verallgemeinern sollte, was allen Modellen gerecht wird. Die Anweisungen für jede Unteraufgabe sind in Abbildung 1 dargestellt.
4. Dank des Befehlsdesigns „Bitte antworten Sie mit Ja oder Nein“ können quantitative Statistiken basierend auf der „Ja“- oder „Nein“-Ausgabe des Modells einfach durchgeführt werden. Diese Methode kann sowohl Genauigkeit als auch Objektivität gewährleisten. Es ist erwähnenswert, dass Forscher auch versucht haben, Anweisungen für Multiple-Choice-Fragen zu entwerfen, aber festgestellt haben, dass es im aktuellen MLLM immer noch schwierig ist, solch komplexere Anweisungen zu befolgen.
Forscher bewerteten insgesamt 12 fortgeschrittene MLLM-Modelle, darunter BLIP-2 [5], LLaVA [6], MiniGPT-4 [7], mPLUG-Owl [2], LLaMA-Adapter-v2 [8], Otter [9], Multimodal-GPT [10], InstructBLIP [11], VisualGLM-6B [12], PandaGPT [13], ImageBind-LLM [14] und LaVIN [15].
Unter ihnen gibt es drei statistische Indikatoren, darunter Genauigkeit, Genauigkeit+ und Punktzahl. Für jede Aufgabe basiert Accuracy auf Fragenstatistiken, Accuracy+ auf Bildstatistiken (beide Fragen zu den Bildern müssen richtig beantwortet werden) und Score ist die Summe von Accuracy und Accuracy+.
Die Gesamtbewertung der Wahrnehmung ist die Summe der Bewertungen von 10 Wahrnehmungsunteraufgaben, und die Gesamtbewertung der Wahrnehmung ist die Summe der Bewertungen von 4 kognitiven Aufgaben. Weitere Informationen finden Sie unter dem Projektlink.
Der Testvergleich von 12 Modellen zu 14 Teilaufgaben ist in Abbildung 2 dargestellt:
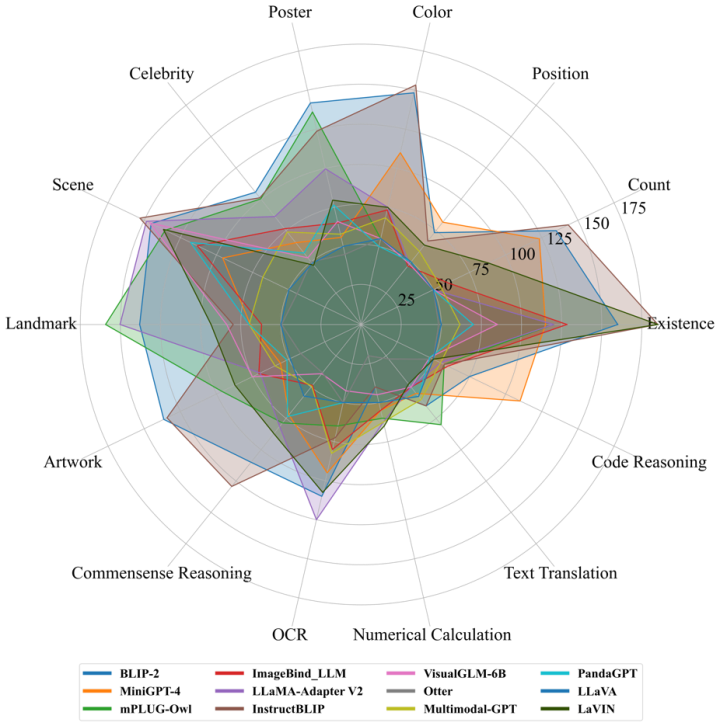
Abbildung 2. Vergleich von 12 Modellen zu 14 Teilaufgaben. Die Gesamtpunktzahl für jede Teilaufgabe beträgt 200 Punkte.
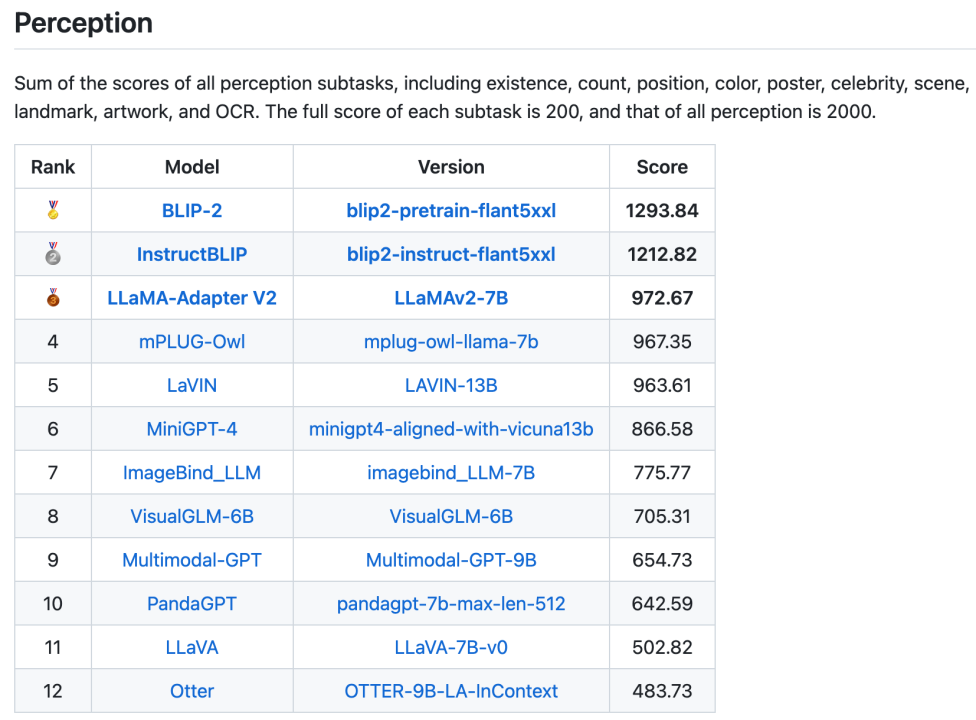
Außerdem wurden insgesamt 16 Listen veröffentlicht, darunter die Gesamtliste der Wahrnehmungs- und Kognitionskategorien und die Listen mit 14 Unteraufgaben. Die beiden Gesamtlisten sind in den Abbildungen 3 und 4 dargestellt. Es ist erwähnenswert, dass BLIP-2 und InstructBLIP in beiden Listen weiterhin unter den ersten drei stehen.
 Bilder
Bilder
Abbildung 3. Gesamtliste der Wahrnehmungsaufgaben
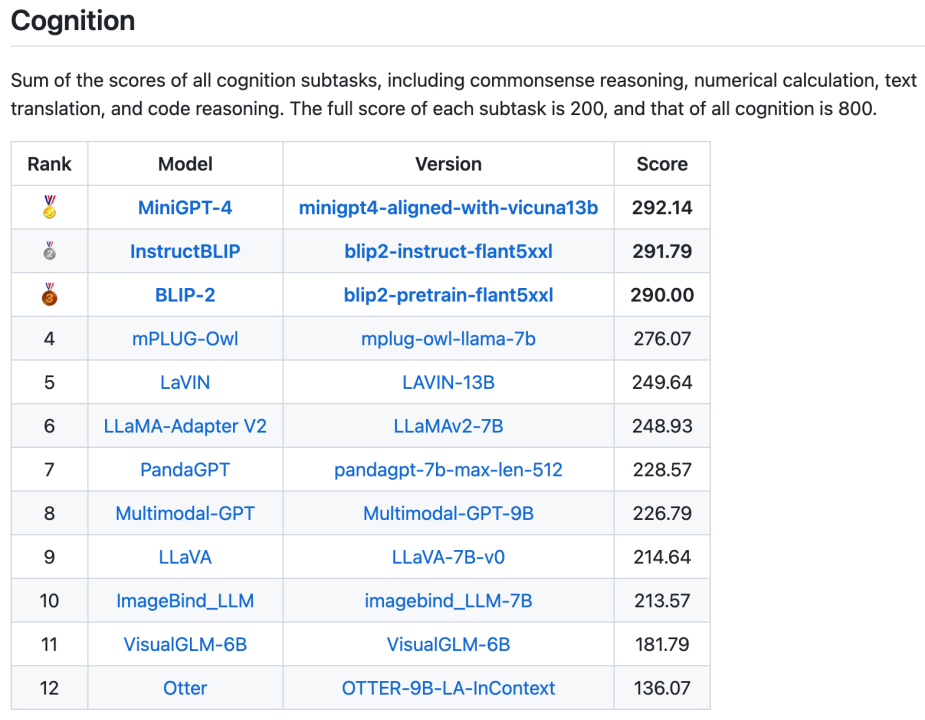
Abbildung 4. Gesamtliste der kognitiven Aufgaben
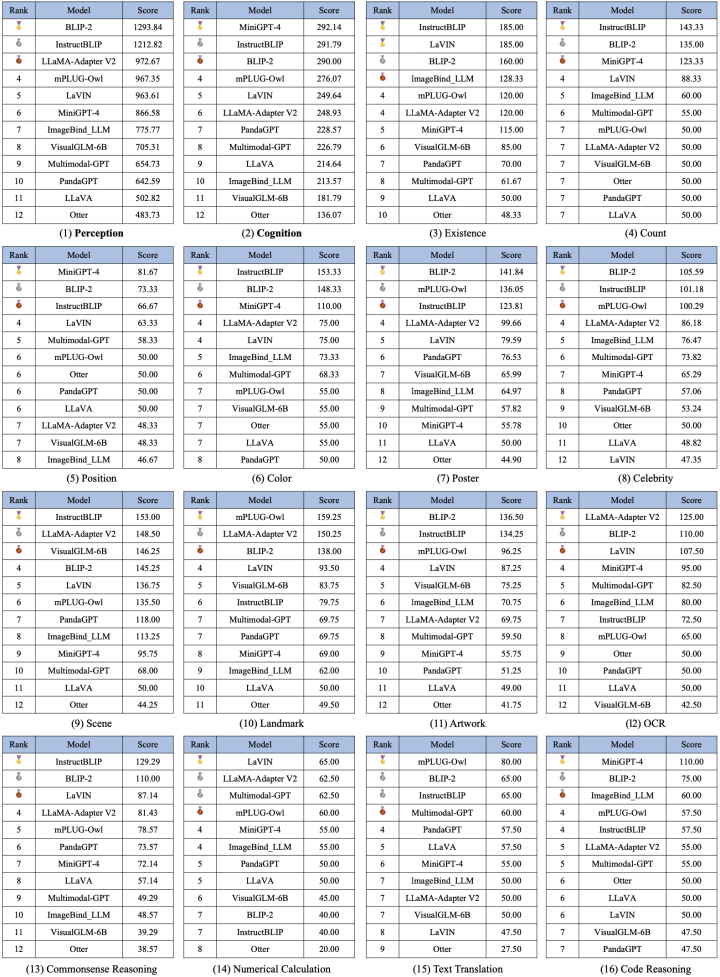
Abbildung 5. Alle Listen
In Darüber hinaus fassten die Forscher auch einige häufige Probleme zusammen, die das MLLM-Modell in Experimenten aufdeckt (siehe Abbildung 6), in der Hoffnung, Hinweise für die nachfolgende Modelloptimierung zu geben.
 Bilder
Bilder
Abbildung 6. Häufige Probleme, die durch MLLM aufgedeckt werden. [Y]/[N] bedeutet, dass die tatsächliche Antwort Ja/Nein ist. [R] ist die von MLLM generierte Antwort.
Das erste Problem besteht darin, den Anweisungen nicht zu folgen.
Obwohl ein sehr prägnantes Anleitungsdesign übernommen wurde, gibt es immer noch MLLMs, denen es freisteht, Fragen zu beantworten, anstatt Anweisungen zu befolgen.
Wie in der ersten Zeile von Abbildung 6 gezeigt, lautete die Anweisung „Bitte antworten Sie mit Ja oder Nein“, aber MLLM gab nur eine deklarative Antwort. Steht am Anfang der Antwort nicht „Ja“ oder „Nein“, wird die Antwort als falsch gewertet. Ein gutes MLLM sollte, insbesondere nach der Feinabstimmung der Anweisungen, in der Lage sein, auf solch einfache Anweisungen zu verallgemeinern.
Das zweite Problem ist die mangelnde Wahrnehmung.
Wie in der zweiten Zeile in Abbildung 6 dargestellt, hat MLLM die Anzahl der Bananen im ersten Bild und die Anzahl im zweiten Bild falsch identifiziert, was zu falschen Antworten führte. Die Forscher stellten außerdem fest, dass die Wahrnehmungsleistung durch Änderungen in den Anweisungen leicht beeinträchtigt wurde, da zwei Anweisungen für dasselbe Bild, die sich nur um ein Wort unterschieden, zu völlig unterschiedlichen Wahrnehmungsergebnissen führten.
Das dritte Problem ist mangelnde Denkfähigkeit.
Wie in der dritten Zeile von Abbildung 6 dargestellt, ist anhand des roten Textes zu erkennen, dass MLLM bereits weiß, dass es sich auf dem ersten Bild nicht um eine Bürofläche handelt, aber trotzdem eine falsche Antwort „Ja“ gegeben hat.
Ebenso hat MLLM im zweiten Bild das richtige Rechenergebnis berechnet, letztlich aber auch die falsche Antwort gegeben. Das Hinzufügen einer Denkanregung wie „Lass uns Schritt für Schritt denken“ kann zu besseren Ergebnissen führen. Ich freue mich auf eine eingehendere Forschung in diesem Bereich.
Die vierte Frage ist die Objektsicht, die dem Befehl folgt. Wie in der vierten Zeile von Abbildung 6 dargestellt, geht MLLM davon aus, dass das Objekt existiert, wenn die Anweisung ein Objekt enthält, das im Bild nicht vorhanden ist, und gibt schließlich eine „Ja“-Antwort.
Dieser Ansatz, immer mit „Ja“ zu antworten, führt zu einer Genauigkeit von nahezu 50 % und einer Genauigkeit+ von nahezu 0. Dies zeigt, wie wichtig es ist, Zielhalluzinationen zu unterdrücken, und erfordert auch weitere Überlegungen zur Zuverlässigkeit der von MLLM generierten Antworten.
Das obige ist der detaillierte Inhalt vonBLIP-2 und InstructBLIP sind fest unter den ersten drei! Zwölf Hauptmodelle, sechzehn Listen, umfassende Bewertung des „multimodalen großen Sprachmodells'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
