
 Technologie-Peripheriegeräte
KI
Industrielle Praxis des Meta-Learnings und der domänenübergreifenden Empfehlung von Tencent TRS
Technologie-Peripheriegeräte
KI
Industrielle Praxis des Meta-Learnings und der domänenübergreifenden Empfehlung von Tencent TRS
Industrielle Praxis des Meta-Learnings und der domänenübergreifenden Empfehlung von Tencent TRS

1. Meta-Learning die Samples, was zu einem Problem führt: Ein einzelnes Modell eignet sich besser für die Schätzung großer Szenen. Die Berücksichtigung verschiedener Szenarien und die Verbesserung der Modellpersonalisierungsfähigkeiten ist ein Problem bei der personalisierten Modellierung.

PPNet/Poso: Dieses Modell erreicht die Personalisierung durch Offset-Gate usw. und weist eine bessere Leistung und Kosten auf. Allerdings teilen sich mehrere Szenarien einen Satz von Modellparametern und die personalisierte Darstellung ist begrenzt.
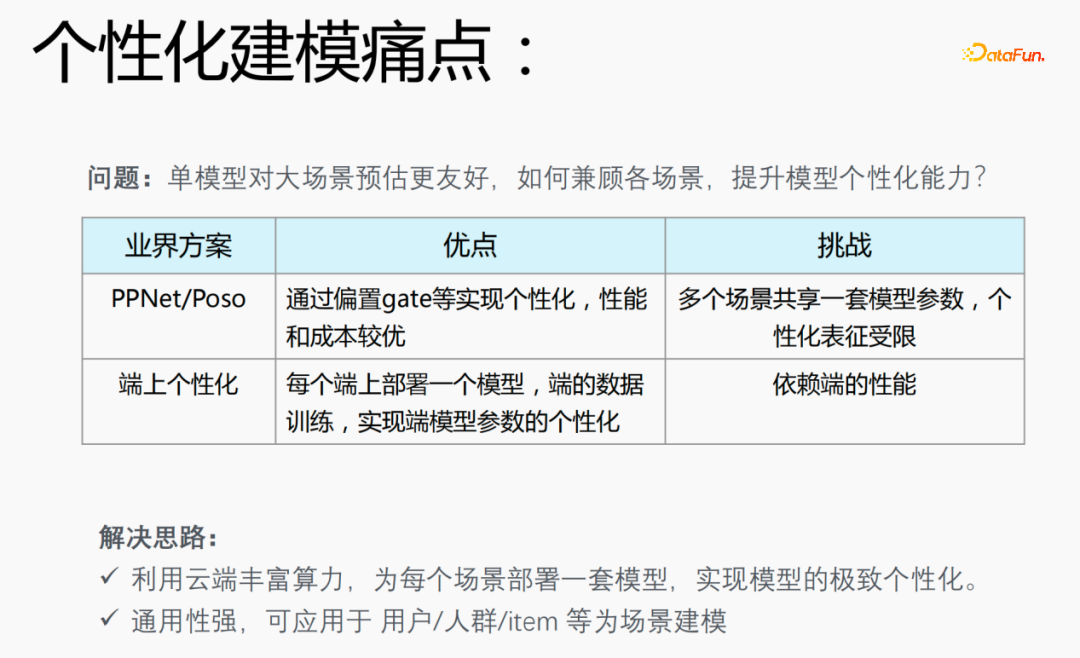
Als Reaktion auf die Probleme, die bei Modellen in der Branche bestehen, haben wir die folgenden Lösungen vorgeschlagen:
- Nutzen Sie die umfangreiche Rechenleistung der Cloud, um eine Reihe von Modellen für jedes zu erreichende Szenario bereitzustellen die ultimative Personalisierung des Modells;
- Das Modell ist äußerst vielseitig und kann auf personalisierte Modellierungsszenarien wie Benutzer/Menschen/Gegenstände angewendet werden. 2. Meta-Learning löst das Problem der Modellpersonalisierung und Leistung.
Lösungsauswahl: Wenn für jeden Benutzer eine Reihe von Modellen bereitgestellt wird, sind die Modellstruktur und die Modellparameter unterschiedlich, was dazu führt, dass die Kosten für Modellschulung und -service relativ hoch sind. Wir erwägen die Bereitstellung personalisierter Modellparameter für jedes Szenario unter derselben Modellstruktur, um das Problem der Modellpersonalisierung zu lösen.
- Bereitstellungsort: Stellen Sie das Modell in der Cloud bereit und nutzen Sie die reichlich vorhandene Rechenleistung in der Cloud. Gleichzeitig möchten Sie das Modell in der Cloud flexibel steuern.
- Algorithmusidee: Traditionelles Meta-Lernen löst das Problem der wenigen Stichproben und des Kaltstarts. Durch ein umfassendes Verständnis des Algorithmus wird die Innovation des Meta-Lernens zur Lösung des Problems genutzt extreme Personalisierung des Modells.
Die Gesamtidee besteht darin, mithilfe von Meta-Learning einen Satz personalisierter Modellparameter für jeden Benutzer in der Cloud bereitzustellen, um letztendlich den Effekt zu erzielen, dass keine Kosten- und Leistungsverluste entstehen.

- 3. Einführung in Meta-Learning
- Meta-Learning bezieht sich auf einen Algorithmus, der allgemeines Wissen lernt, um neue Aufgaben zu steuern, und dem Netzwerk schnelle Lernfähigkeiten verleiht. Beispiel: Die Klassifizierungsaufgabe im Bild oben: Katzen und Vögel, Blumen und Fahrräder. Wir definieren diese Klassifizierungsaufgabe als K-kurze N-Klasse-Klassifizierungsaufgabe und hoffen, durch Meta-Lernen Klassifizierungswissen zu erlernen. Im Feinabstimmungsschätzungsprozess hoffen wir, dass bei Klassifizierungsaufgaben wie Hunden und Ottern durch die Feinabstimmung mit sehr wenigen Stichproben der ultimative Schätzeffekt erzielt werden kann. Ein weiteres Beispiel: Wenn wir die vier gemischten Operationen lernen, lernen wir zuerst Addition und Subtraktion und dann Multiplikation und Division. Wenn wir diese beiden Kenntnisse beherrschen, können wir lernen, die beiden Kenntnisse zu integrieren, um sie zu berechnen , Subtraktion, Multiplikation und Division, wir berechnen sie nicht separat, aber auf der Grundlage von Addition, Subtraktion, Multiplikation und Division lernen wir zuerst die Operationsregeln der Multiplikation und Division und dann der Addition und Subtraktion und verwenden dann einige Beispiele zum Trainieren Diese Regel dient dazu, diese Regel schnell zu verstehen, sodass in der neuen Schätzung bessere Ergebnisse für die Daten erzielt werden. Die Idee des Meta-Lernens ähnelt dieser.
- Metrikbasiert: Verwenden Sie metrische Lernmethoden wie KNN und K-Means, um neue und bestehende Szenarien zu lernen. Die Entfernung der Szene und Zu welcher Kategorie es voraussichtlich gehört, sind Convolutional Siamese, Neural Network, Matching Networks und Prototypical Networks. Modellbasiert: Modellparameter schnell über Speicher oder RNN usw. lernen. Die repräsentativen Algorithmen sind: Memeory-Augmented, Neural Networks
- Optimierungsbasierte Methode (optimierungsbasiert): Dies ist eine in den letzten Jahren beliebte Methode. Sie verwendet die Gradientenabstiegsmethode, um den Verlust für jede Szene zu berechnen, um das Optimum zu erhalten Der Parameter stellt den Algorithmus MAML dar, der derzeit für die personalisierte Modellierung verwendet wird.
- 4. Meta-Learning-Algorithmus
- Lösung 1: Führen Sie eine Beispielauswahl innerhalb des Meta-Train-Batches durch. Gleichzeitig modifizieren wir für zig Millionen Modellschulungen das unendliche Framework, um die Meta-Learning-Beispielorganisation und zig Millionen Modellschulungen zu unterstützen. Die herkömmliche Modellbereitstellungsmethode besteht darin, in jedem Szenario eine Reihe von Modellen bereitzustellen, was zu sehr großen Modellgrößen im zweistelligen Millionenbereich führt und die Schulungs- und Bereitstellungskosten erhöht. Wir verwenden eine Tune-and-Use-and-Release-Methode, um nur einen Satz von Modellparametern zu speichern, wodurch eine Vergrößerung der Modellgröße vermieden werden kann. Gleichzeitig untersuchen wir nur den Kernnetzwerkteil, um Leistung zu sparen.
- Lösung 2: Führen Sie während des Bereitstellungsprozesses eine Feinabstimmung durch. Die herkömmliche Probenspeicherverbindung erhöht die Wartungskosten für Proben. Daher geben wir die traditionelle Methode auf und speichern nur die Daten der mittleren Ebene als Eingabe von Metadaten -Lernen.
Das Ziel traditioneller Lernmethoden besteht darin, das optimale θ für alle Daten, also das global optimale θ, zu lernen. Beim Meta-Lernen wird die Aufgabe als Dimension verwendet, um das Allgemeine 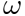 in der Szene zu lernen, und der Verlust kann in allen Szenen das optimale Niveau erreichen. Das durch traditionelle Lernmethoden gelernte θ liegt in großen Szenen näher an der Masse, hat bessere Vorhersagen für große Szenen und hat einen durchschnittlichen Effekt auf Long-Tail-Vorhersagen Jeder Szenendaten oder neue Szenendaten werden an diesem Punkt feinabgestimmt, um den optimalen Punkt für jede Szene zu erreichen. Daher ist es möglich, in jedem Szenario personalisierte Modellparameter zu erstellen, um das Ziel der ultimativen Personalisierung zu erreichen. Im obigen Beispiel wird die Menge als Aufgabe für das Meta-Lernen verwendet, es ist jedoch auch geeignet, Benutzer oder Elemente als Aufgaben für die Modellierung zu verwenden.
in der Szene zu lernen, und der Verlust kann in allen Szenen das optimale Niveau erreichen. Das durch traditionelle Lernmethoden gelernte θ liegt in großen Szenen näher an der Masse, hat bessere Vorhersagen für große Szenen und hat einen durchschnittlichen Effekt auf Long-Tail-Vorhersagen Jeder Szenendaten oder neue Szenendaten werden an diesem Punkt feinabgestimmt, um den optimalen Punkt für jede Szene zu erreichen. Daher ist es möglich, in jedem Szenario personalisierte Modellparameter zu erstellen, um das Ziel der ultimativen Personalisierung zu erreichen. Im obigen Beispiel wird die Menge als Aufgabe für das Meta-Lernen verwendet, es ist jedoch auch geeignet, Benutzer oder Elemente als Aufgaben für die Modellierung zu verwenden.
Es gibt drei Kategorien des Meta-Lernens:
Model-Agnostic Meta-Learning (MAML) ist ein Algorithmus, der nichts mit der Modellstruktur zu tun hat und zur Verallgemeinerung geeignet ist zwei Teile: Meta-Train und Finetune.

Unter diesen kann Support Set als Trainingssatz und Query Set als Validierungssatz verstanden werden.
Der Finetune-Prozess ist dem Meta-Train-Prozess sehr ähnlich. θ wird in einer bestimmten Szene platziert, der Unterstützungssatz der Szene wird abgerufen und die Gradientenabstiegsmethode (SGD) wird verwendet, um die zu erhalten optimale Parameter der Szene
 ; Verwendung
; Verwendung
Generieren Sie geschätzte Ergebnisse für die im Aufgabenszenario zu bewertenden Proben (Abfragesatz).  5. Herausforderungen der Meta-Learning-Industrialisierung
5. Herausforderungen der Meta-Learning-Industrialisierung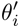
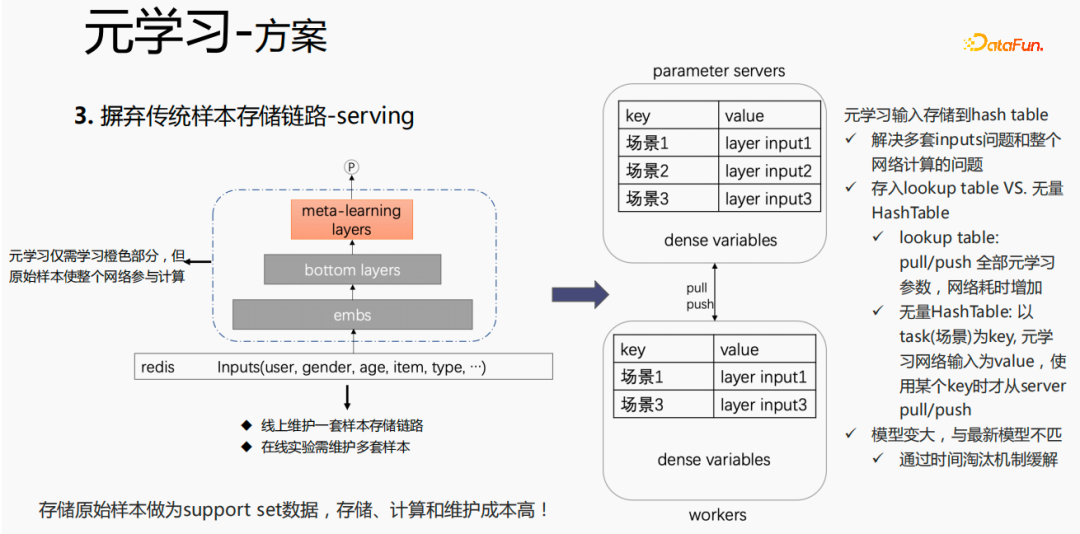
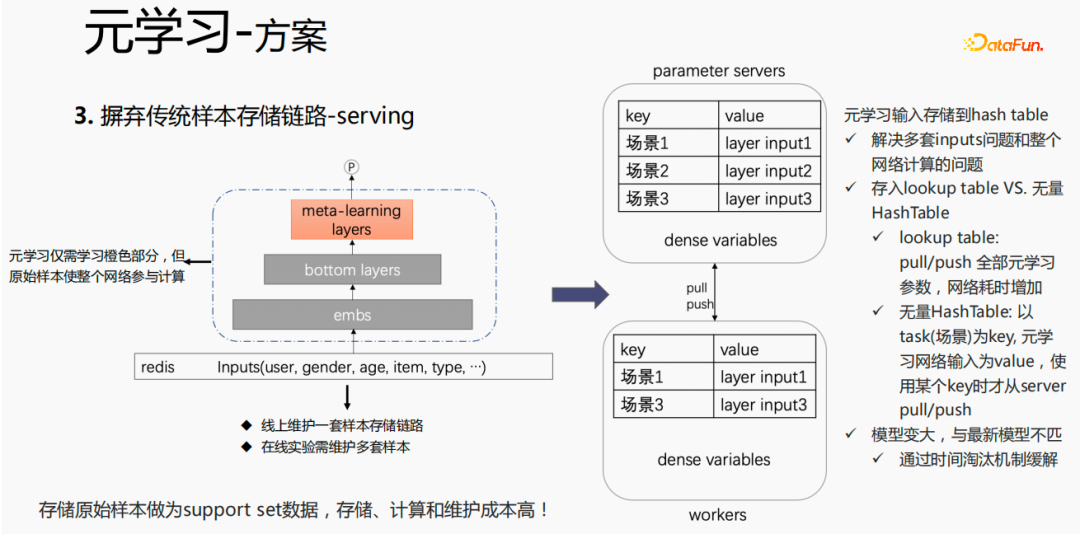
Die Anwendung von Meta-Learning-Algorithmen in industriellen Szenarien stellt relativ große Herausforderungen dar: Der Meta-Train-Prozess von Meta-Learning-Algorithmen umfasst zwei Stichproben, Szenenstichproben und Stichproben Probenahme. Für Samples ist es notwendig, die Samples gut zu organisieren und in der Reihenfolge der Szenen zu speichern und zu verarbeiten. Gleichzeitig ist eine Wörterbuchtabelle erforderlich, um die entsprechende Beziehung zwischen den Samples und den Szenen zu speichern Gleichzeitig müssen die Proben für den Verbrauch an Arbeitskräfte weitergegeben werden, was für Industrieszenarien eine sehr große Herausforderung darstellt.
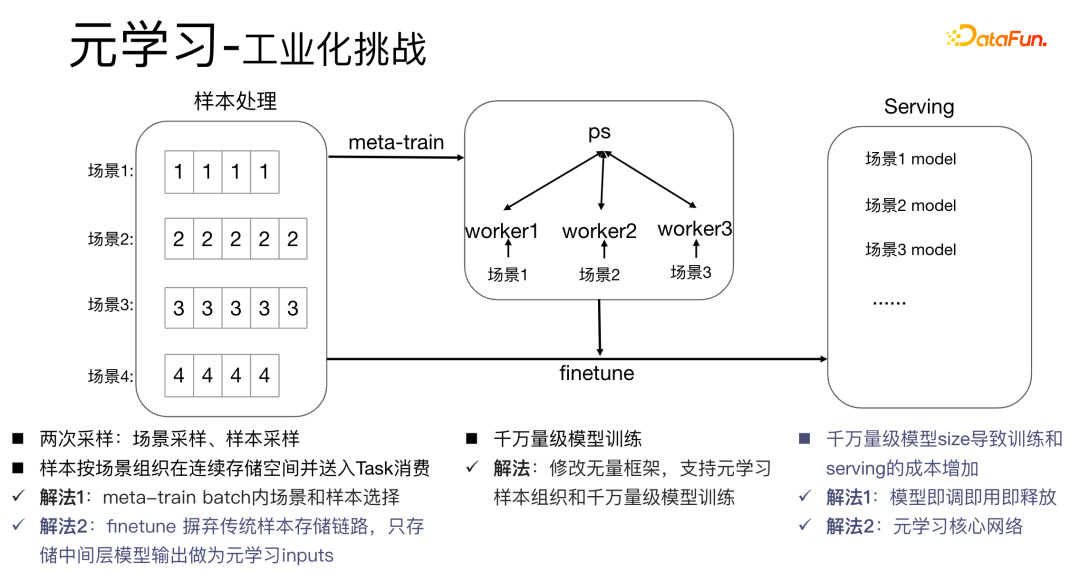
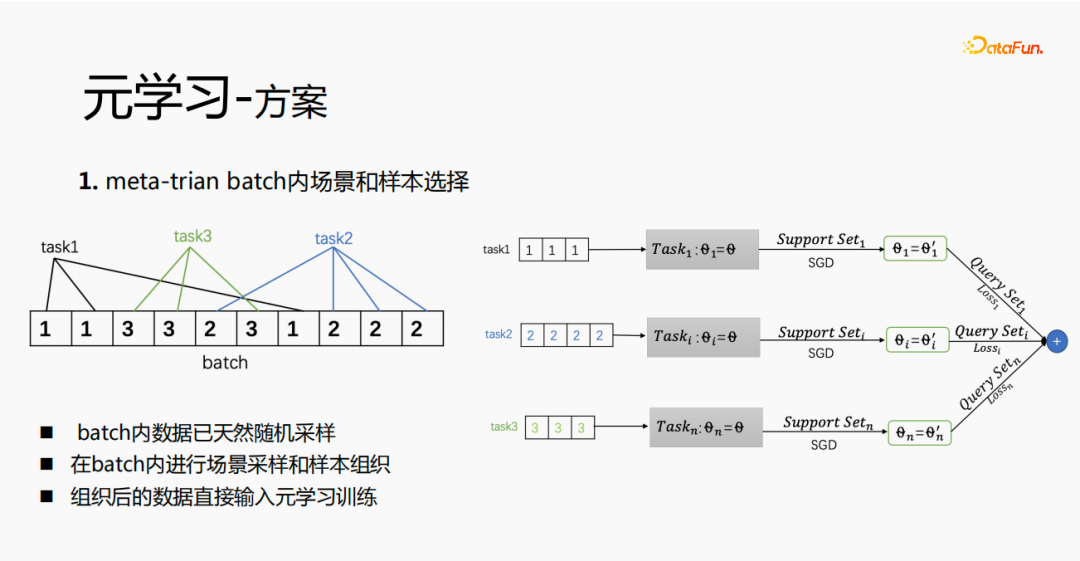
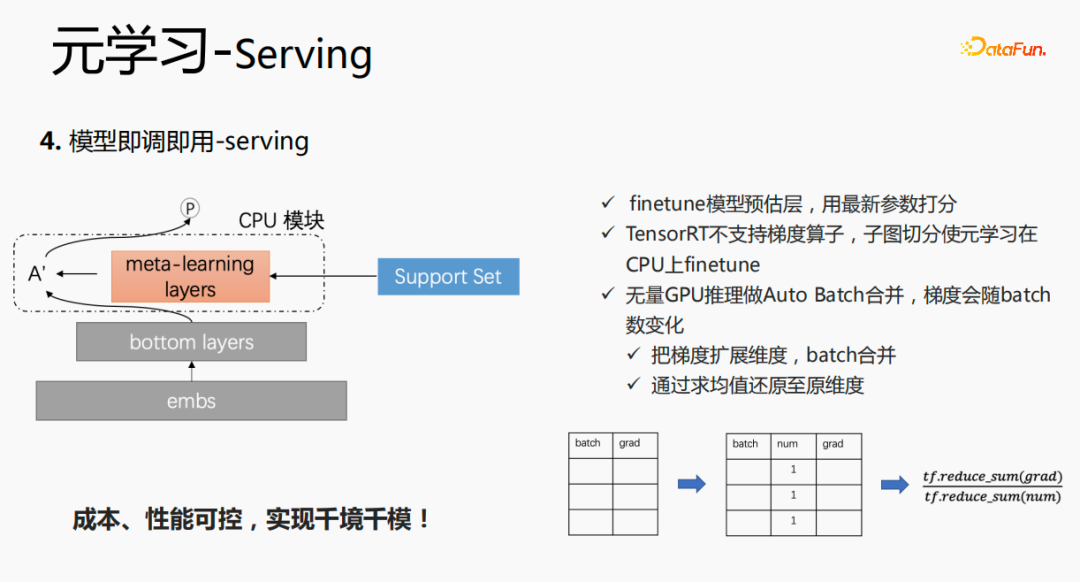
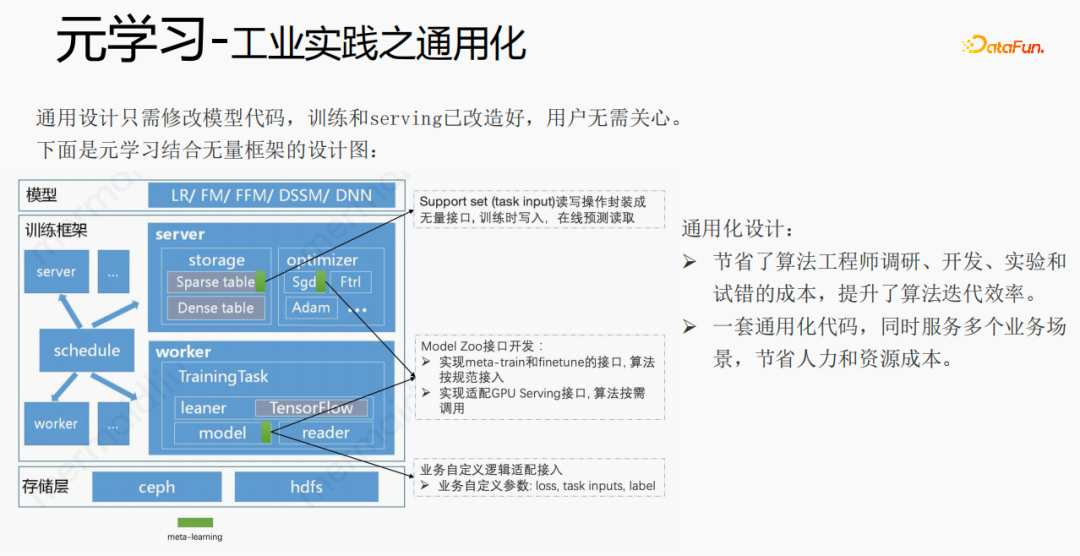
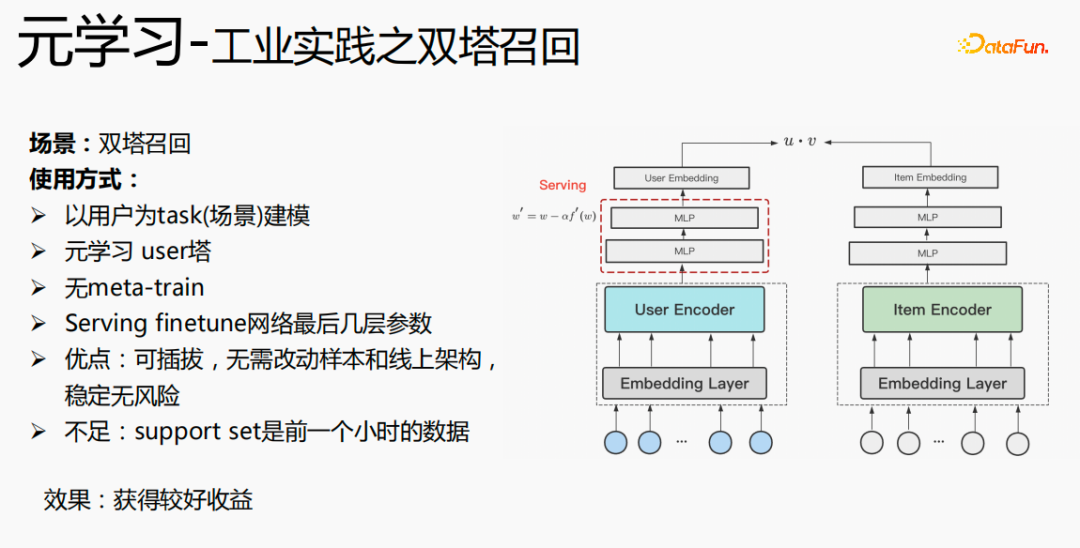
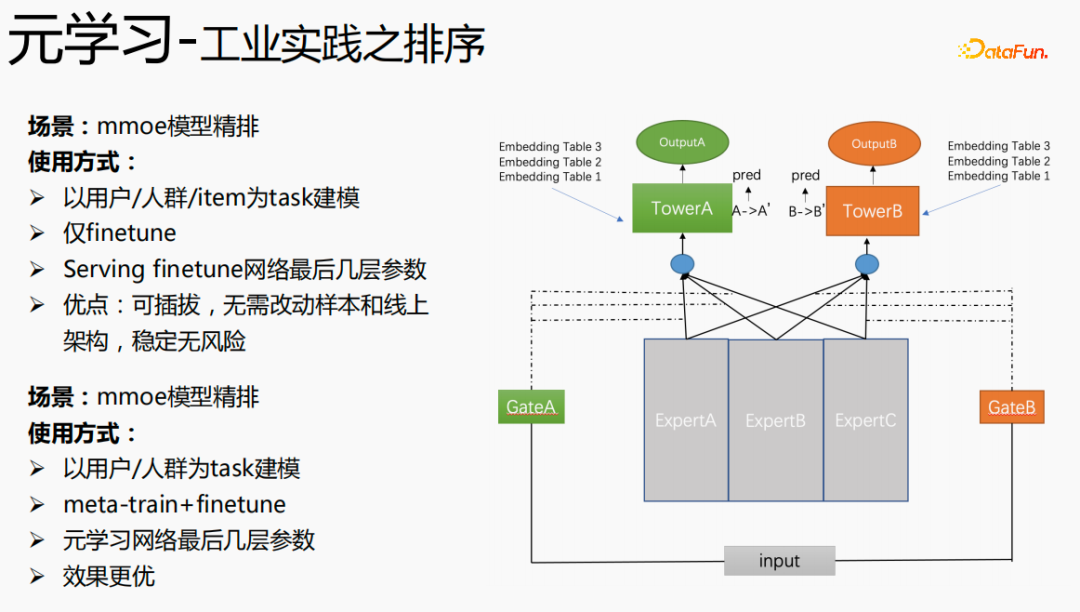
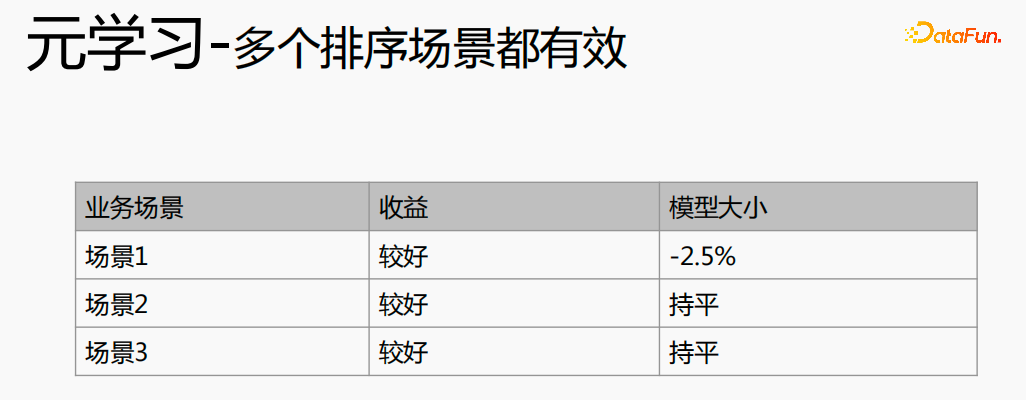
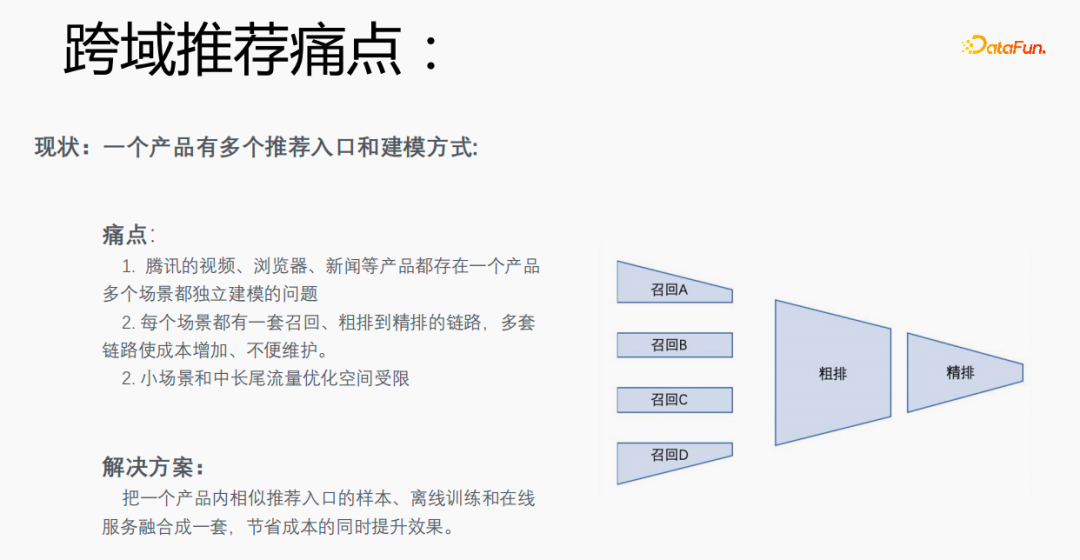
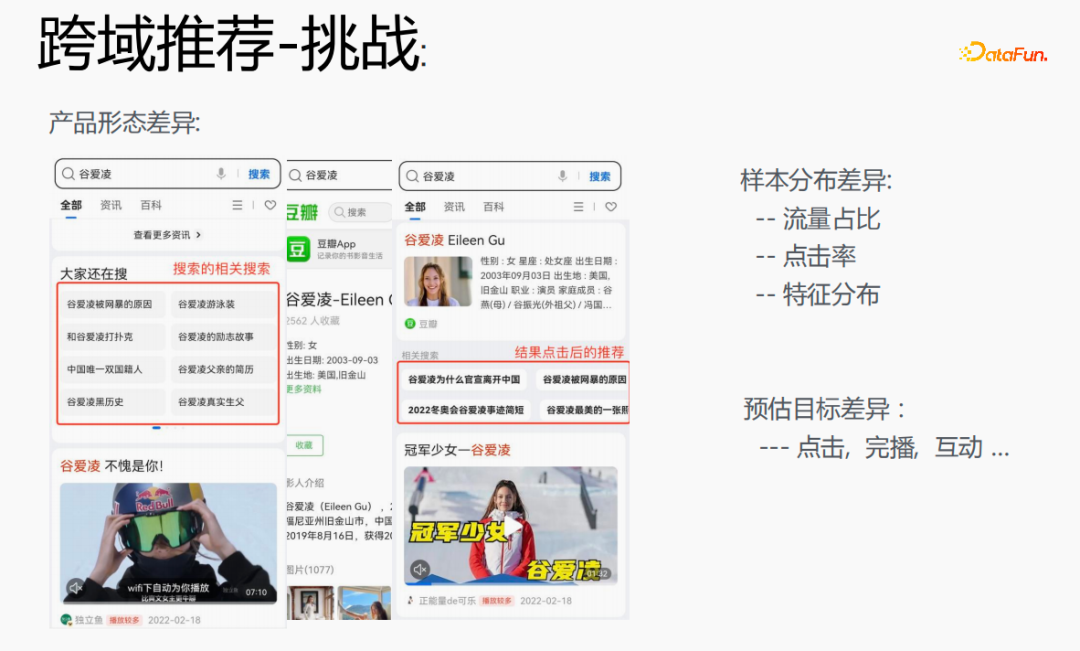
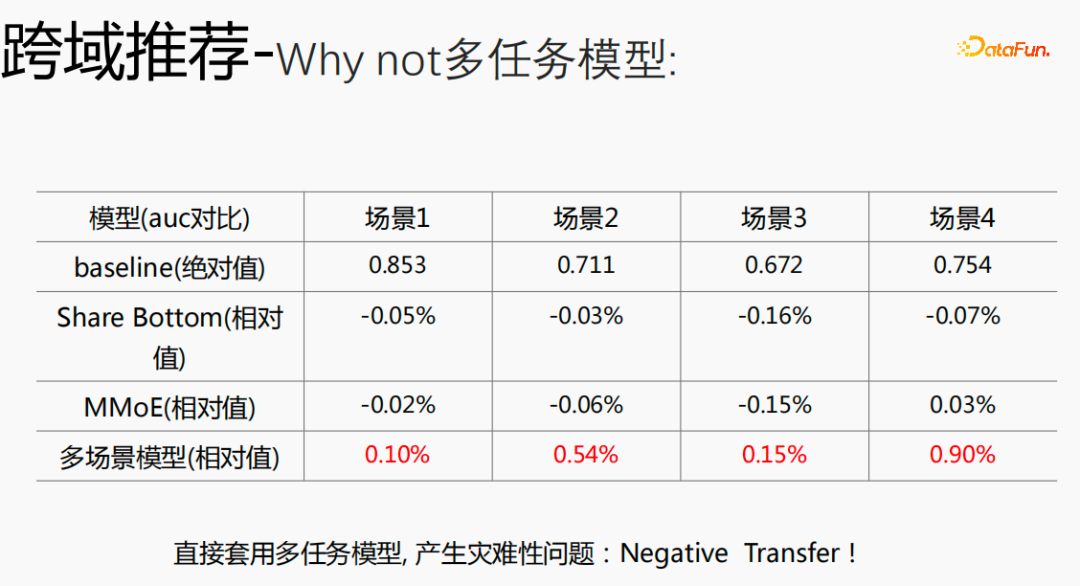
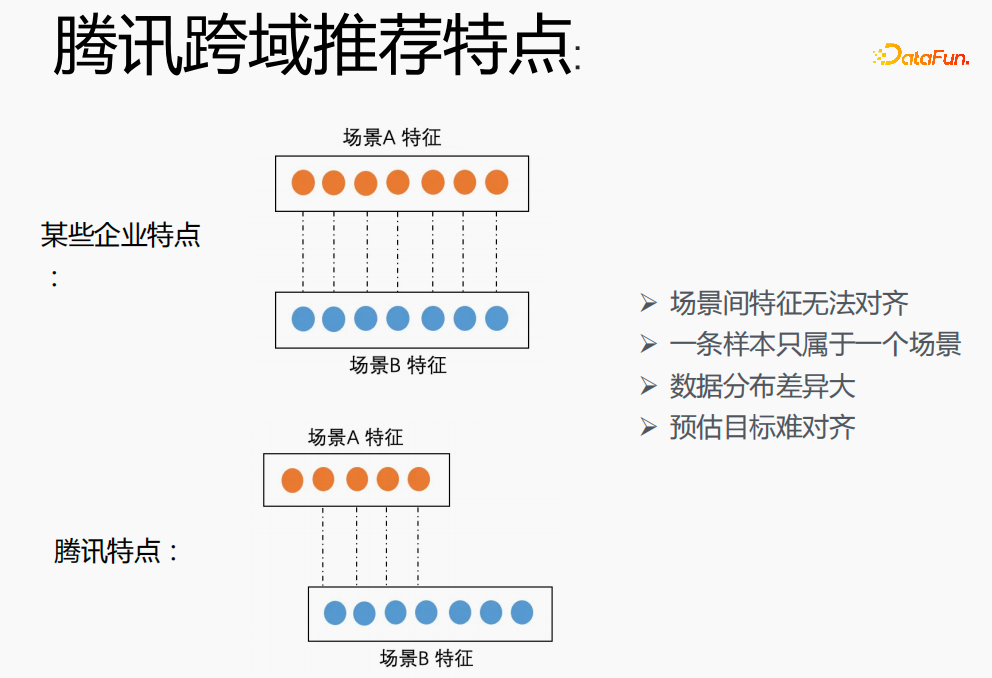
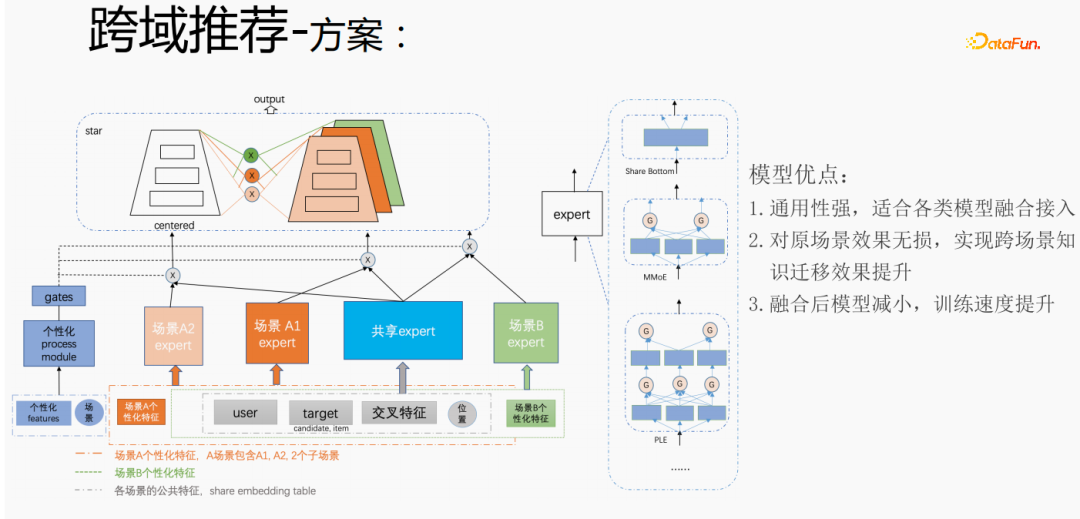
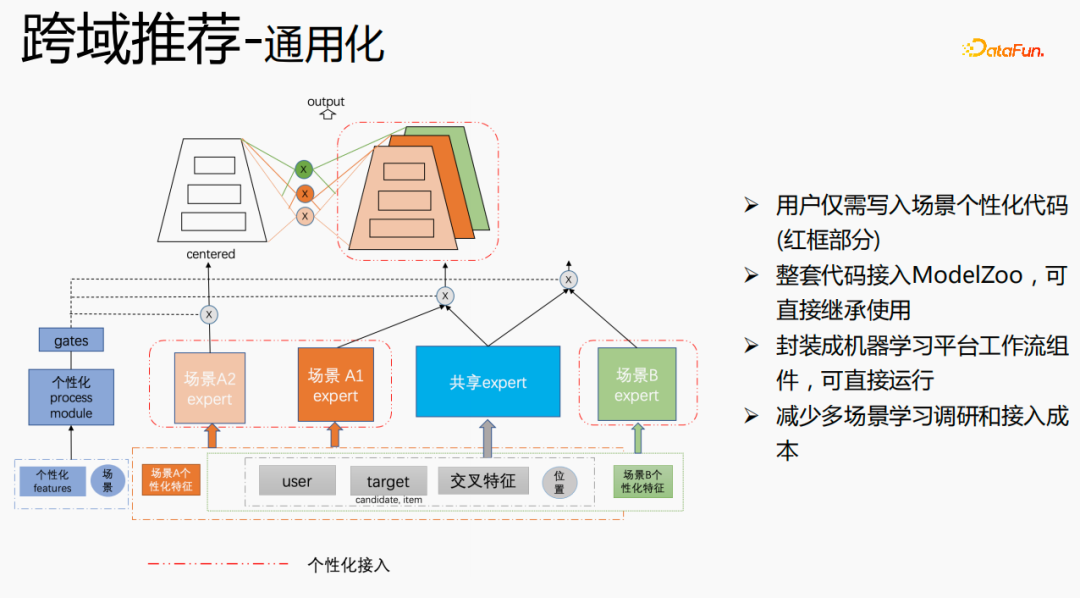
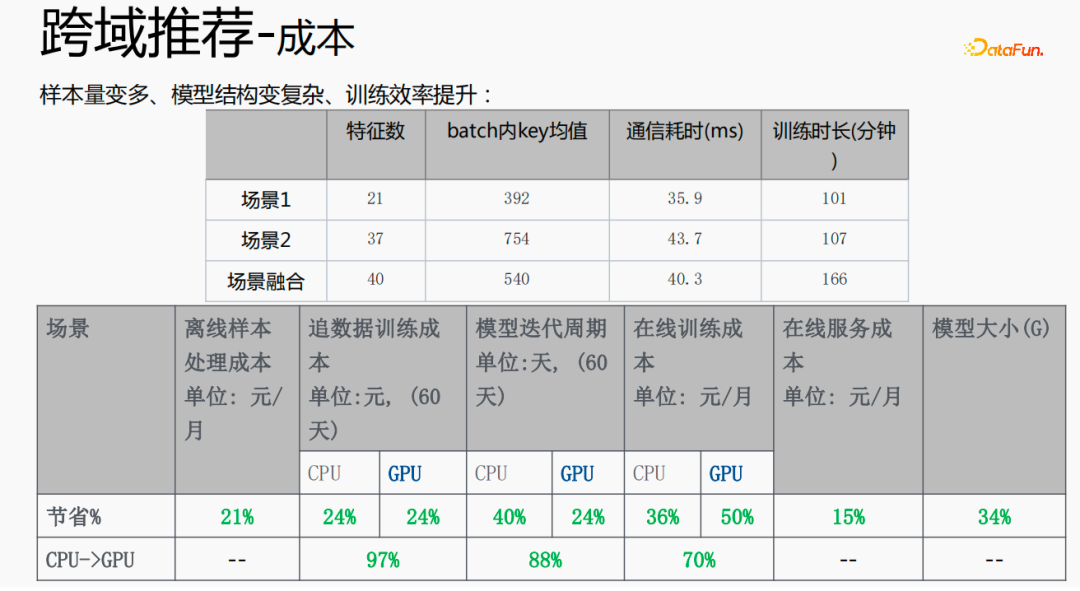
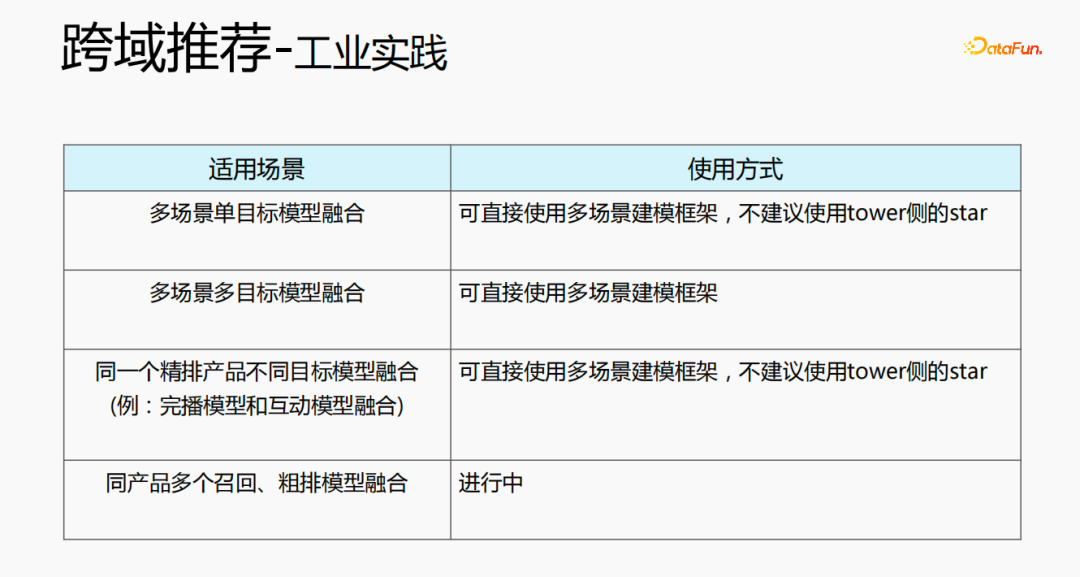
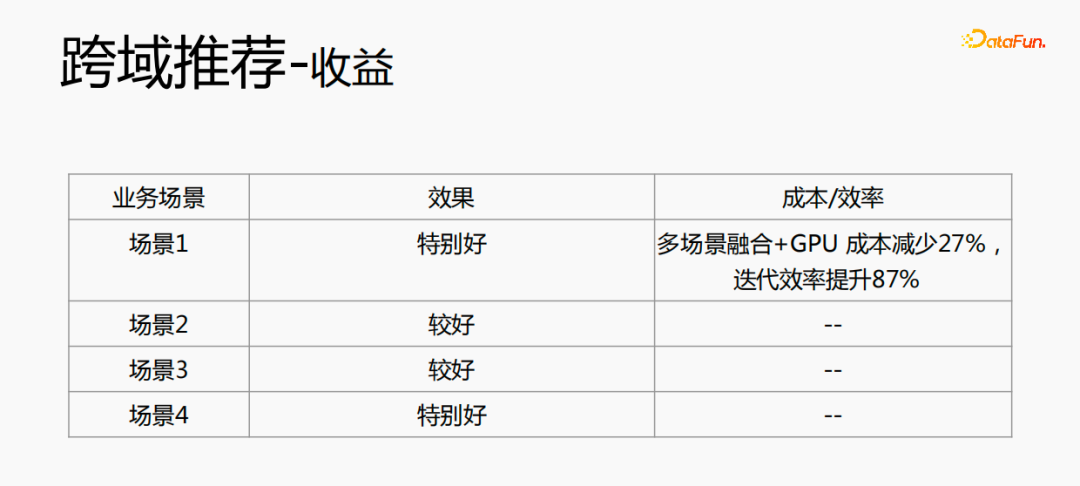
Zunächst wird die Auswahl von Szenen und Beispielen innerhalb des Stapels in jedem Stapel implementiert Daten gehören zu einer Aufgabe. Innerhalb eines Stapels werden diese Daten entsprechend den Aufgaben extrahiert und die extrahierten Proben werden in den Meta-Train-Trainingsprozess eingefügt. Dadurch wird das Problem gelöst, dass eine Reihe von Verarbeitungsverknüpfungen für die Szenenauswahl und die Probenauswahl unabhängig verwaltet werden müssen. Durch experimentelle Forschung und das Lesen von Artikeln haben wir festgestellt, dass bei der Feinabstimmung und im Meta-Lernprozess der Einfluss auf den Vorhersageeffekt des Modells umso größer ist Gleichzeitig hat die Emb-Schicht einen größeren Einfluss auf den Vorhersageeffekt des Modells, und die mittlere Ebene hat keinen großen Einfluss auf den Vorhersageeffekt. Unsere Idee ist also, dass Meta-Learning nur Parameter auswählt, die näher an der Vorhersageschicht liegen. Aus Kostengründen erhöht die Emb-Schicht die Lernkosten und die Emb-Schicht wird nicht für Meta-Lernen trainiert. Im gesamten Trainingsprozess, wie dem MMOE-Trainingsnetzwerk im Bild oben, lernen wir die Parameter der Turmschicht und die Parameter anderer Szenen werden weiterhin gemäß der ursprünglichen Trainingsmethode gelernt. Die Beispiele sind mit dem Benutzer als Dimension organisiert. Die Trainingsdaten sind in zwei Teile unterteilt, ein Teil ist der Unterstützungssatz und der andere Teil ist der Abfragesatz. Im Unterstützungssatz wird nur der Inhalt auf der lokalen Seite für die Turmaktualisierung und das Parametertraining gelernt. Anschließend werden die Daten des Abfragesatzes verwendet, um den Verlust des gesamten Netzwerks zu berechnen, und dann wird der Gradient zurückgegeben, um die Parameter des gesamten Netzwerks zu aktualisieren . Daher ist der gesamte Trainingsprozess: Die ursprüngliche Trainingsmethode des gesamten Netzwerks bleibt unverändert; unter Berücksichtigung der Kosten nimmt die Einbettung nicht am Meta-Lernen teil; Meta-Verlust; wenn Fintune durchgeführt wird, wird Emb gespeichert. Im Bereitstellungsprozess wird Emb zur Feinabstimmung des Kernnetzwerks verwendet, und der Switch kann zum Ein- und Ausschalten des Meta-Lernens verwendet werden. Wenn bei der herkömmlichen Probenspeichermethode die Feinabstimmung direkt während des Serviervorgangs durchgeführt wird, treten schwerwiegende Probleme auf: Ein Satz von Probenspeicherlinks muss online für mehrere Sätze von Online-Experimenten verwaltet werden müssen gepflegt werden. Mehrere Probensätze. Gleichzeitig werden im Feinabstimmungsprozess die Originalbeispiele für die Feinabstimmung verwendet. Die Muster durchlaufen jedoch die Emb-Schicht, die unterste Schicht und die Meta-Lernschicht Prozess und kümmert sich nicht um andere Teile. Wir erwägen, während des Bereitstellungsprozesses nur die Meta-Lerneingabe in das Modell zu speichern, wodurch die Wartung des Beispiellinks eingespart und ein bestimmter Effekt erzielt werden kann. Wenn nur der Emb-Teil gespeichert wird, können die Berechnungskosten und Wartungskosten dieses Teils gesenkt werden gerettet werden. Wir verwenden folgende Methoden: Fügen Sie den Speicher in die Nachschlagetabelle des Modells ein. Die Nachschlagetabelle wird als dichte Variable betrachtet und in ps gespeichert. Beim Aktualisieren werden auch alle Variablen übertragen Netzwerkzeit. Eine andere Möglichkeit besteht darin, eine unendliche HashTable zu verwenden. Der Schlüssel ist die Szene und der Wert ist die Eingabe der Metaebene Durch Drücken oder Ziehen wird insgesamt Netzwerkzeit gespart. Daher probieren wir diese Methode aus, um die Eingabe der Metaebene zu speichern. Wenn gleichzeitig Meta-Lernebenen im Modell gespeichert werden, wird das Modell größer und es treten Ablaufprobleme auf, was zu einer Nichtübereinstimmung mit dem aktuellen Modell führt. Wir verwenden die Zeiteliminierung, um dieses Problem zu lösen, das heißt, es zu beseitigen Abgelaufene Einbettungen verkleinern nicht nur das Modell, sondern lösen auch das Echtzeitproblem. In der Bereitstellungsphase verwendet dieses Modell die Einbettung in die untere Ebene. Bei der Bewertung handelt es sich nicht um die gleiche Methode wie bei der ursprünglichen Methode. Stattdessen werden die Daten im Unterstützungssatz abgerufen Durch Meta-Learning-Ebenen und die Die Parameter dieser Ebene werden aktualisiert und die aktualisierten Parameter werden für die Bewertung verwendet. Dieser Prozess kann nicht auf der GPU berechnet werden, daher führen wir den Prozess auf der CPU aus. Gleichzeitig führt die Wuliang-GPU-Inferenz eine automatische Batch-Zusammenführung durch, um mehrere Anforderungen auf der GPU zusammenzuführen. Auf diese Weise ändert sich der Gradient, wenn der Batch zunimmt Fügen Sie bei der Berechnung des Gradienten eine Num-Dimension hinzu, addieren Sie den Grad und verarbeiten Sie ihn entsprechend der Num-Dimension, um die Stabilität des Gradienten aufrechtzuerhalten. Letztendlich sind Kosten und Leistung kontrollierbar und es werden verschiedene Szenarien und Modelle erreicht. Durch die Verwendung von Frameworks und Komponenten zur Verallgemeinerung des Meta-Lernens müssen Benutzer beim Zugriff nur den Modellcode ändern, und Benutzer müssen sich nicht darum kümmern Sie müssen nur das aufrufen, was wir bereits haben. Implementieren Sie gute Schnittstellen, z. B. Support-Set-Lese- und Schreibschnittstellen, Meta-Train- und Finetune-Implementierungsschnittstellen und GPU-Serving-Anpassungsschnittstellen. Benutzer müssen lediglich geschäftsbezogene Parameter wie Verlust, Aufgabeneingaben, Bezeichnung usw. übergeben. Dieses Design erspart Algorithmusingenieuren die Kosten für Forschung, Entwicklung, Experimente und Versuch und Irrtum und verbessert die Iterationseffizienz des Algorithmus. Gleichzeitig kann der verallgemeinerte Code mehrere Geschäftsszenarien bedienen, wodurch Personal- und Ressourcenkosten gespart werden. Der Einsatz von Meta-Learning im Zwei-Türme-Rückrufszenario wird mit dem Benutzer als Dimension modelliert, einschließlich des Benutzerturms und des Artikelturms. Die Vorteile des Modells sind: steckbar, keine Änderung von Beispielen und Online-Architektur erforderlich, stabil und risikofrei; der Nachteil besteht darin, dass der Supportsatz die Daten der vorherigen Stunde ist, was zu Echtzeitproblemen führt. Ein weiteres Anwendungsszenario des Meta-Lernens ist das Sequenzrückrufszenario. Dieses Szenario wird mit dem Benutzer als Szenario und der Verhaltenssequenz des Benutzers als Unterstützungssatz modelliert , die wir verwalten werden Eine negative Probenwarteschlange, die Proben in der Probenwarteschlange werden als negative Proben verwendet und die positiven Proben werden in den Unterstützungssatz gespleißt. Die Vorteile hiervon sind: stärkere Echtzeitleistung und geringere Kosten. Abschließend wird Meta-Learning auch in Sortierszenarien angewendet, wie zum Beispiel dem mmoe-Feinsortiermodell im Bild oben. Es gibt zwei Implementierungsmethoden: nur die Verwendung von Finetune und die Verwendung von Meta-Train und Finetune. Die zweite Implementierungsmethode ist effektiver. Meta-Learning hat in verschiedenen Szenarien gute Ergebnisse erzielt. Jede Szene verfügt über mehrere empfohlene Eingänge. Es ist notwendig, für jede Szene eine Reihe von Verknüpfungen vom Rückruf über die grobe Rangfolge bis hin zur feinen Rangfolge festzulegen. Besonders kleine Szenen sowie mittlere und lange Verkehrsdaten sind spärlich und der Optimierungsraum ist begrenzt. Können wir Beispiele ähnlicher Empfehlungsportale, Offline-Schulungen und Online-Dienste in einem Produkt in ein Set integrieren, um Kosten zu sparen und die Ergebnisse zu verbessern? Allerdings gibt es dabei gewisse Herausforderungen. Suchen Sie im Browser nach Gu Ailing, und nach dem Klicken auf den spezifischen Inhalt werden relevante Suchbegriffe angezeigt. Nach dem Klicken auf die Ergebnisse werden Empfehlungen angezeigt. Die Verkehrsanteile, Klickraten und Funktionsverteilungen der beiden sind recht Gleichzeitig gibt es auch Unterschiede in den geschätzten Zielen. Wenn Sie ein Multitask-Modell für ein domänenübergreifendes Modell verwenden, treten schwerwiegende Probleme auf und Sie können keine besseren Vorteile erzielen. Die Implementierung einer szenarioübergreifenden Modellierung in Tencent ist eine große Herausforderung. Erstens können in anderen Unternehmen die Merkmale der beiden Szenarien eins zu eins übereinstimmen, aber im domänenübergreifenden Empfehlungsfeld von Tencent können die Merkmale der beiden Szenarien nicht abgeglichen werden. Eine Stichprobe kann nur zu einem Szenario gehören. Die Datenverteilung ist sehr unterschiedlich und es ist schwierig, die geschätzten Ziele aufeinander abzustimmen. Entsprechend den personalisierten Anforderungen der domänenübergreifenden Empfehlungsszenarien von Tencent wird die obige Methode zur Handhabung verwendet. Für die gemeinsame Einbettung allgemeiner Funktionen verfügen die personalisierten Szenenfunktionen über einen eigenen unabhängigen Einbettungsraum. Im Modellteil gibt es gemeinsame Experten und personalisierte Experten. Alle Daten fließen in die gemeinsamen Experten ein, und die Beispiele jeder Szene haben ihre eigenen Personalisieren Sie den Experten, integrieren Sie den gemeinsamen Experten und den personalisierten Experten über das personalisierte Tor, geben Sie sie in den Turm ein und verwenden Sie die Sternmethode, um das Problem der Zielspärlichkeit in verschiedenen Szenarien zu lösen. Für den Expertenteil kann eine beliebige Modellstruktur verwendet werden, z. B. Share Bottom, MMoE, PLE oder eine vollständige Modellstruktur für das Geschäftsszenario. Die Vorteile dieser Methode sind: Das Modell ist äußerst vielseitig und eignet sich für den Fusionszugriff verschiedener Modelle, da der Szenenexperte direkt migriert werden kann, der ursprüngliche Szeneneffekt nicht beschädigt wird und der Effekt des szenarioübergreifenden Wissenstransfers verbessert wird. Nach der Fusion wird das Modell reduziert und die Trainingsgeschwindigkeit verbessert. Verbessern und gleichzeitig Kosten sparen. Wir haben eine universelle Konstruktion durchgeführt. Der rote Teil ist der Inhalt, der personalisierten Zugriff erfordert, z. B. personalisierte Funktionen, personalisierte Modellstruktur usw. Benutzer müssen nur personalisierten Code schreiben. Für andere Teile haben wir den gesamten Codesatz mit ModelZoo verbunden, der direkt vererbt und verwendet werden kann, und in Workflow-Komponenten der Plattform für maschinelles Lernen gekapselt, die direkt ausgeführt werden können. Diese Methode reduziert die Kosten für die Erforschung mehrerer Szenarien Zugang. Diese Methode erhöht die Stichprobengröße und verkompliziert die Modellstruktur, aber die Effizienz wird verbessert. Die Gründe dafür sind wie folgt: Da einige Features gemeinsam genutzt werden, ist die Anzahl der zusammengeführten Features aufgrund der gemeinsamen Einbettungsfunktion geringer als die Summe der Feature-Nummern, und der mittlere Schlüsselwert innerhalb des Stapels ist kleiner als der Die Summe der beiden Szenen verringert die Zeit des Ziehens oder Drückens von der Serverseite, wodurch die Kommunikationszeit gespart und die gesamte Schulungszeit verkürzt wird. Die Fusion mehrerer Szenarien kann die Gesamtkosten senken: Durch die Offline-Probenverarbeitung können die Kosten um 21 % gesenkt werden; durch die Verwendung der CPU zur Datenverfolgung werden 24 % der Kosten eingespart, während die Iterationszeit des Modells ebenfalls um 40 % reduziert wird %, und Online-Schulung Die Kosten, die Online-Servicekosten und die Modellgröße werden alle reduziert, sodass die Kosten für die gesamte Verbindung reduziert werden. Gleichzeitig eignet sich die Zusammenführung der Daten mehrerer Szenen besser für die GPU-Berechnung. Durch die Zusammenführung der CPU zweier einzelner Szenen mit der GPU wird ein höherer Anteil eingespart. Domainübergreifende Empfehlungen können vielfältig eingesetzt werden. Die erste ist eine Mehrszenen-Einzelobjektiv-Modellstruktur, die das Mehrszenen-Modellierungsframework direkt verwenden kann. Es wird nicht empfohlen, den Stern auf der Turmseite zu verwenden -objektiv und kann das Multi-Szenario-Modellierungs-Framework direkt verwenden Der Star auf der Turmseite; das letzte ist die Fusion mehrerer Rückruf- und Grobplanungsmodelle für dasselbe Produkt. Cross-Domain-Empfehlung verbessert nicht nur die Wirkung, sondern spart auch jede Menge Kosten.
6. Meta-Lernlösung

7. Industrialisierungspraxis des Meta-Lernens

2. Domainübergreifende Empfehlung
1. Schwachstellen der domänenübergreifenden Empfehlung
Das obige ist der detaillierte Inhalt vonIndustrielle Praxis des Meta-Learnings und der domänenübergreifenden Empfehlung von Tencent TRS. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Die unterste Ebene der C++-Sortierfunktion verwendet die Zusammenführungssortierung, ihre Komplexität beträgt O(nlogn) und bietet verschiedene Auswahlmöglichkeiten für Sortieralgorithmen, einschließlich schneller Sortierung, Heap-Sortierung und stabiler Sortierung.
 Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Die Konvergenz von künstlicher Intelligenz (KI) und Strafverfolgung eröffnet neue Möglichkeiten zur Kriminalprävention und -aufdeckung. Die Vorhersagefähigkeiten künstlicher Intelligenz werden häufig in Systemen wie CrimeGPT (Crime Prediction Technology) genutzt, um kriminelle Aktivitäten vorherzusagen. Dieser Artikel untersucht das Potenzial künstlicher Intelligenz bei der Kriminalitätsvorhersage, ihre aktuellen Anwendungen, die Herausforderungen, denen sie gegenübersteht, und die möglichen ethischen Auswirkungen der Technologie. Künstliche Intelligenz und Kriminalitätsvorhersage: Die Grundlagen CrimeGPT verwendet Algorithmen des maschinellen Lernens, um große Datensätze zu analysieren und Muster zu identifizieren, die vorhersagen können, wo und wann Straftaten wahrscheinlich passieren. Zu diesen Datensätzen gehören historische Kriminalstatistiken, demografische Informationen, Wirtschaftsindikatoren, Wettermuster und mehr. Durch die Identifizierung von Trends, die menschliche Analysten möglicherweise übersehen, kann künstliche Intelligenz Strafverfolgungsbehörden stärken
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 Üben und denken Sie an die multimodale große Modellplattform DataCanvas von Jiuzhang Yunji
Oct 20, 2023 am 08:45 AM
Üben und denken Sie an die multimodale große Modellplattform DataCanvas von Jiuzhang Yunji
Oct 20, 2023 am 08:45 AM
1. Die historische Entwicklung multimodaler Großmodelle zeigt den ersten Workshop zur künstlichen Intelligenz, der 1956 am Dartmouth College in den Vereinigten Staaten stattfand Pioniere der symbolischen Logik (außer dem Neurobiologen Peter Milner in der Mitte der ersten Reihe). Diese symbolische Logiktheorie konnte jedoch lange Zeit nicht verwirklicht werden und leitete in den 1980er und 1990er Jahren sogar den ersten KI-Winter ein. Erst mit der kürzlich erfolgten Implementierung großer Sprachmodelle haben wir entdeckt, dass neuronale Netze dieses logische Denken tatsächlich tragen. Die Arbeit des Neurobiologen Peter Milner inspirierte die spätere Entwicklung künstlicher neuronaler Netze, und aus diesem Grund wurde er zur Teilnahme eingeladen in diesem Projekt.
 Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
1. Hintergrund des Baus der 58-Portrait-Plattform Zunächst möchte ich Ihnen den Hintergrund des Baus der 58-Portrait-Plattform mitteilen. 1. Das traditionelle Denken der traditionellen Profiling-Plattform reicht nicht mehr aus. Der Aufbau einer Benutzer-Profiling-Plattform basiert auf Data-Warehouse-Modellierungsfunktionen, um Daten aus mehreren Geschäftsbereichen zu integrieren, um genaue Benutzerporträts zu erstellen Und schließlich muss es über Datenplattformfunktionen verfügen, um Benutzerprofildaten effizient zu speichern, abzufragen und zu teilen sowie Profildienste bereitzustellen. Der Hauptunterschied zwischen einer selbst erstellten Business-Profiling-Plattform und einer Middle-Office-Profiling-Plattform besteht darin, dass die selbst erstellte Profiling-Plattform einen einzelnen Geschäftsbereich bedient und bei Bedarf angepasst werden kann. Die Mid-Office-Plattform bedient mehrere Geschäftsbereiche und ist komplex Modellierung und bietet allgemeinere Funktionen. 2.58 Benutzerporträts vom Hintergrund der Porträtkonstruktion im Mittelbahnsteig 58
 Fügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!
Mar 14, 2024 pm 11:50 PM
Fügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!
Mar 14, 2024 pm 11:50 PM
Oben geschrieben & Das persönliche Verständnis des Autors ist, dass im autonomen Fahrsystem die Wahrnehmungsaufgabe eine entscheidende Komponente des gesamten autonomen Fahrsystems ist. Das Hauptziel der Wahrnehmungsaufgabe besteht darin, autonome Fahrzeuge in die Lage zu versetzen, Umgebungselemente wie auf der Straße fahrende Fahrzeuge, Fußgänger am Straßenrand, während der Fahrt angetroffene Hindernisse, Verkehrszeichen auf der Straße usw. zu verstehen und wahrzunehmen und so flussabwärts zu helfen Module Treffen Sie richtige und vernünftige Entscheidungen und Handlungen. Ein Fahrzeug mit autonomen Fahrfähigkeiten ist in der Regel mit verschiedenen Arten von Informationserfassungssensoren ausgestattet, wie z. B. Rundumsichtkamerasensoren, Lidar-Sensoren, Millimeterwellenradarsensoren usw., um sicherzustellen, dass das autonome Fahrzeug die Umgebung genau wahrnehmen und verstehen kann Elemente, die es autonomen Fahrzeugen ermöglichen, beim autonomen Fahren die richtigen Entscheidungen zu treffen. Kopf
