
 Technologie-Peripheriegeräte
KI
Intel Zhang Yu: Edge Computing spielt eine wichtige Rolle im gesamten KI-Ökosystem
Technologie-Peripheriegeräte
KI
Intel Zhang Yu: Edge Computing spielt eine wichtige Rolle im gesamten KI-Ökosystem
Intel Zhang Yu: Edge Computing spielt eine wichtige Rolle im gesamten KI-Ökosystem

[Global Network Science and Technology Reporter Lin Mengxue] Derzeit werden generative KI und große Modelle auf der ganzen Welt immer beliebter. Während der gerade vergangenen Weltkonferenz für künstliche Intelligenz 2023 (WAIC 2023) haben verschiedene Hersteller sogar einen „Hundertfachen Erfolg“ erzielt „„Model War“, nach unvollständigen Statistiken des Organisationskomitees, wurden insgesamt mehr als 30 große Modellplattformen veröffentlicht und vorgestellt, 60 % der Offline-Stände demonstrierten die relevante Einführung und Anwendung generativer KI-Technologie, und 80 % der Teilnehmer diskutierten die Inhalte rund um Großmodelle.
Während der WAIC 2023 glaubte Zhang Yu, leitender Chef-KI-Ingenieur der Intel Corporation und Chief Technology Officer der Network and Edge Division China, dass der Kernfaktor, der die Entwicklung dieser Runde künstlicher Intelligenz vorantreibt, tatsächlich die kontinuierliche Verbesserung von Computer, Kommunikation und ist Speichertechnologien. Im gesamten KI-Ökosystem, egal ob es sich um groß angelegte Modelle oder KI-Fusion handelt, spielt der Edge eine entscheidende Rolle.
Zhang Yu sagte: „Mit der digitalen Transformation der Branche haben die Anforderungen der Menschen an agile Verbindungen, Echtzeit-Geschäfts- und Anwendungsintelligenz die Entwicklung von künstlicher Edge-Intelligenz gefördert Mit anderen Worten: Wir müssen eine große Datenmenge und enorme Rechenleistung verwenden, um ein Modell im Rechenzentrum zu trainieren, und wir übertragen die Trainingsergebnisse an das Frontend aktuelles Nutzungsmodell zur Implementierung künstlicher Intelligenz am Rande“
„Dieses Modell wird zwangsläufig die Häufigkeit von Modellaktualisierungen begrenzen, aber wir haben auch gesehen, dass viele intelligente Branchen tatsächlich Anforderungen an Modellaktualisierungen haben, die sich an verschiedene Straßenbedingungen anpassen und für die Fahrgewohnheiten verschiedener Personen geeignet sein müssen.“ Wenn wir jedoch ein Vorbild in einer Autofabrik trainieren, gibt es oft bestimmte Unterschiede zwischen den verwendeten Trainingsdaten und den beim dynamischen Fahren generierten Daten. Dieser Unterschied wirkt sich auf die Generalisierungsfähigkeit des Modells aus die Fähigkeit, sich an neue Fahrverhaltensweisen anzupassen, müssen wir das Modell kontinuierlich trainieren und optimieren, um diesen Prozess voranzutreiben“, sagte er.
Daher schlug Zhang Yu vor, dass die zweite Stufe der Entwicklung künstlicher Intelligenz die Edge-Trainingsstufe sein sollte. „Wenn wir Edge-Training implementieren wollen, benötigen wir mehr automatisierte Mittel und Tools, um einen vollständigen Entwicklungsprozess von der Datenanmerkung über das Modelltraining bis hin zur Modellbereitstellung abzuschließen. Er sagte, dass die nächste Entwicklungsrichtung der künstlichen Edge-Intelligenz darin bestehen sollte.“ ist selbstständiges Lernen.
Im eigentlichen Entwicklungsprozess steht Edge Artificial Intelligence auch vor vielen Herausforderungen. Nach Ansicht von Zhang Yu gibt es neben den Herausforderungen des Edge-Trainings auch Herausforderungen der Edge-Ausrüstung. „Da der Stromverbrauch, den die bereitgestellte Rechenleistung tragen kann, oft begrenzt ist, stellt die Implementierung von Edge Reasoning und Training mit begrenzten Ressourcen höhere Anforderungen an die Leistung und das Stromverbrauchsverhältnis des Chips.“ Die Fragmentierung von Edge-Geräten ist sehr offensichtlich, und auch die Art und Weise, wie Software zur Migration zwischen verschiedenen Plattformen eingesetzt werden kann, stellt weitere Anforderungen.
Darüber hinaus ist die Entwicklung künstlicher Intelligenz eng mit der Rechenleistung verbunden, und hinter der Rechenleistung steht eine riesige Datenbasis. Angesichts der riesigen Datenbestände ist der Schutz von Daten zu einem heißen Thema bei der Entwicklung künstlicher Kanten geworden Intelligenz. Sobald KI am Rande eingesetzt wird, liegen diese Modelle außerhalb der Kontrolle des Dienstanbieters. Wie schützen wir das Modell zu diesem Zeitpunkt? Und es ist notwendig, gute Schutzwirkungen bei Lagerung und Betrieb zu erzielen. Dies sind die Herausforderungen, denen sich Edge Artificial Intelligence gegenübersieht.
„Intel ist ein Datenunternehmen und unsere Produkte decken alle Aspekte der Datenverarbeitung, Kommunikation und Speicherung ab. Im Bereich Datenverarbeitung bietet Intel eine Vielzahl von Produkten an, darunter CPUs, GPUs, FPGAs und verschiedene Beschleunigungschips für künstliche Intelligenz. , um den Anforderungen der Benutzer gerecht zu werden In Bezug auf große Modelle für künstliche Intelligenz ist beispielsweise das von Intel eingeführte Produkt Gaudi2 das einzige Produkt in der Branche, das eine hervorragende Leistung beim Training großer Modelle zeigt Intel kann die von Entwicklern auf dem offenen Framework für künstliche Intelligenz entworfenen und trainierten Modelle schnell auf verschiedenen Hardwareplattformen bereitstellen, um Inferenzoperationen durchzuführen.“
Das obige ist der detaillierte Inhalt vonIntel Zhang Yu: Edge Computing spielt eine wichtige Rolle im gesamten KI-Ökosystem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Intel Core Ultra 9 285K-Prozessor enthüllt: Der CineBench R23 Multi-Core-Lauf-Score ist 18 % höher als der i9-14900K
Jul 25, 2024 pm 12:25 PM
Intel Core Ultra 9 285K-Prozessor enthüllt: Der CineBench R23 Multi-Core-Lauf-Score ist 18 % höher als der i9-14900K
Jul 25, 2024 pm 12:25 PM
Laut Nachrichten dieser Website vom 25. Juli hat die Quelle Jaykihn gestern (24. Juli) einen Tweet auf der X-Plattform gepostet, in dem sie die laufenden Score-Daten des Intel Core Ultra9285K „ArrowLake-S“-Desktop-Prozessors teilt. Die Ergebnisse zeigen, dass dies der Fall ist besser als der Core 14900K 18 % schneller. Diese Seite zitierte den Inhalt des Tweets. Die Quelle teilte die Laufergebnisse der ES2- und QS-Versionen des Intel Core Ultra9285K-Prozessors mit und verglich sie mit dem Core i9-14900K-Prozessor. Berichten zufolge ist der TD von ArrowLake-SQS beim Ausführen von Workloads wie CinebenchR23, Geekbench5, SpeedoMeter, WebXPRT4 und CrossMark
 Intel kündigt Wi-Fi 7 BE201-Netzwerkkarte an, die die CNVio3-Schnittstelle unterstützt
Jun 07, 2024 pm 03:34 PM
Intel kündigt Wi-Fi 7 BE201-Netzwerkkarte an, die die CNVio3-Schnittstelle unterstützt
Jun 07, 2024 pm 03:34 PM
Laut Nachrichten dieser Website vom 1. Juni hat Intel am 27. Mai das Supportdokument aktualisiert und die Produktdetails der Wi-Fi7 (802.11be) BE201-Netzwerkkarte mit dem Codenamen „Fillmore Peak2“ bekannt gegeben. Quelle des obigen Bildes: benchlife-Website Hinweis: Im Gegensatz zu den bestehenden BE200 und BE202, die eine PCIe/USB-Schnittstelle verwenden, unterstützt BE201 die neueste CNVio3-Schnittstelle. Die Hauptspezifikationen der BE201-Netzwerkkarte ähneln denen der BE200. Sie unterstützt 2x2TX/RX-Streaming, unterstützt 2,4 GHz, 5 GHz und 6 GHz. Die maximale Netzwerkgeschwindigkeit kann 5 Gbit/s erreichen, was weit unter der maximalen Standardrate von 40 Gbit liegt /S. BE201 unterstützt auch Bluetooth 5.4 und Bluetooth LE.
 Intel N250 Low-Power-Prozessor freigelegt: 4 Kerne, 4 Threads, 1,2 GHz Frequenz
Jun 03, 2024 am 10:26 AM
Intel N250 Low-Power-Prozessor freigelegt: 4 Kerne, 4 Threads, 1,2 GHz Frequenz
Jun 03, 2024 am 10:26 AM
Laut Nachrichten dieser Website vom 16. Mai hat die Quelle @InstLatX64 kürzlich getwittert, dass Intel die Einführung einer neuen N250-Serie „TwinLake“ mit stromsparenden Prozessoren vorbereitet, um die N200-Serie „AlderLake-N“ zu ersetzen. Quelle: videocardz Die Prozessoren der N200-Serie sind beliebt in kostengünstigen Laptops, Thin Clients, eingebetteten Systemen, Selbstbedienungs- und Point-of-Sale-Terminals, NAS und Unterhaltungselektronik. „TwinLake“ ist der Codename der neuen Prozessorserie, die in gewisser Weise den Single-Chip-Prozessoren ähnelt. Dies nutzt ein Ringbus-Layout (RingBus), verfügt jedoch über einen E-Core-Cluster zur Vervollständigung der Rechenleistung. Die dieser Site beigefügten Screenshots lauten wie folgt: AlderLake-N-Mining
 MSI bringt neue Minikonsole MS-C918 mit Intel Alder Lake-N N100 Prozessor auf den Markt
Jul 03, 2024 am 11:33 AM
MSI bringt neue Minikonsole MS-C918 mit Intel Alder Lake-N N100 Prozessor auf den Markt
Jul 03, 2024 am 11:33 AM
Diese Website berichtete am 3. Juli, dass MSIIPC, eine Tochtergesellschaft von MSI, kürzlich den industriellen Mini-Host MS-C918 auf den Markt gebracht hat, um den vielfältigen Anforderungen moderner Unternehmen gerecht zu werden. Es wurde noch kein öffentlicher Preis gefunden. MS-C918 richtet sich an Unternehmen, die Wert auf Kosteneffizienz, Benutzerfreundlichkeit und Portabilität legen. Es wurde speziell für unkritische Umgebungen entwickelt und bietet eine 3-jährige Lebensdauergarantie. MS-C918 ist ein tragbarer Industriecomputer mit Intel AlderLake-NN100-Prozessor, der speziell auf Lösungen mit extrem geringem Stromverbrauch zugeschnitten ist. Die Hauptfunktionen und Merkmale des auf dieser Website enthaltenen MS-C918 sind wie folgt: Kompakte Größe: 80 mm x 80 mm x 36 mm, handflächengroß, einfach zu bedienen und hinter dem Display versteckt. Anzeigefunktion: über 2 HDMI2.
 ASUS veröffentlicht BIOS-Update für Z790-Motherboards, um Instabilitätsprobleme mit Intels Core-Prozessoren der 13./14. Generation zu beheben
Aug 09, 2024 am 12:47 AM
ASUS veröffentlicht BIOS-Update für Z790-Motherboards, um Instabilitätsprobleme mit Intels Core-Prozessoren der 13./14. Generation zu beheben
Aug 09, 2024 am 12:47 AM
Laut Nachrichten dieser Website vom 8. August haben MSI und ASUS heute eine Beta-Version des BIOS veröffentlicht, die das 0x129-Mikrocode-Update für einige Z790-Motherboards enthält, als Reaktion auf die Instabilitätsprobleme bei Intel Core Desktop-Prozessoren der 13. und 14. Generation. Zu den ersten Motherboards von ASUS, die BIOS-Updates bereitstellen, gehören: ROGMAXIMUSZ790HEROBetaBios2503ROGMAXIMUSZ790DARKHEROBetaBios1503ROGMAXIMUSZ790HEROBTFBetaBios1503ROGMAXIMUSZ790HEROEVA-02, gemeinsame Version BetaBios2503ROGMAXIMUSZ790A
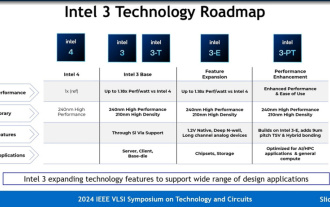 Intel erklärt ausführlich den Intel 3-Prozess: Anwendung von mehr EUV-Lithographie, wodurch die Häufigkeit des gleichen Stromverbrauchs um bis zu 18 % erhöht wird
Jun 19, 2024 pm 10:53 PM
Intel erklärt ausführlich den Intel 3-Prozess: Anwendung von mehr EUV-Lithographie, wodurch die Häufigkeit des gleichen Stromverbrauchs um bis zu 18 % erhöht wird
Jun 19, 2024 pm 10:53 PM
Laut Nachrichten dieser Website vom 19. Juni hat Intel im Rahmen der IEEEVLSI-Seminaraktivitäten 2024 kürzlich die technischen Details des Intel3-Prozessknotens auf seiner offiziellen Website vorgestellt. Intels neueste Generation der FinFET-Transistortechnologie ist im Vergleich zu Intel4 zusätzliche Schritte zur Verwendung von EUV. Es wird auch eine Knotenfamilie sein, die lange Zeit Foundry-Dienste bereitstellt, einschließlich grundlegender Intel3- und drei Varianten Knoten. Unter anderem unterstützt Intel3-E nativ eine Hochspannung von 1,2 V, was für die Herstellung analoger Module geeignet ist, während der zukünftige Intel3-PT die Gesamtleistung weiter verbessern und feineres 9μm-Pitch-TSV und Hybrid-Bonding unterstützen wird. Intel behauptet, dass es so ist
 Spezifikationen des mobilen Intel Panther Lake-Prozessors offengelegt: bis zu „4+8+4' 16-Kern-CPU, 12 Xe3-Kern-Display
Jul 18, 2024 pm 04:43 PM
Spezifikationen des mobilen Intel Panther Lake-Prozessors offengelegt: bis zu „4+8+4' 16-Kern-CPU, 12 Xe3-Kern-Display
Jul 18, 2024 pm 04:43 PM
Laut Nachrichten dieser Website vom 16. Juli veröffentlichte der Blogger @jaykihn0 nach der Enthüllung der Spezifikationen des ArrowLake-Desktop-Prozessors und des BartlettLake-Desktop-Prozessors am frühen Morgen die Spezifikationen der mobilen U- und H-Versionen des Intel PantherLake-Prozessors. Der mobile Panther Lake-Prozessor wird voraussichtlich den Namen Core Ultra300-Serie tragen und in den folgenden Versionen erhältlich sein: PTL-U: 4P+0E+4LPE+4Xe, 15WPL1PTL-H: 4P+8E+4LPE+12Xe, 25WPL1PTL-H : 4P+8E+4LPE+ 4Xe, 25WPL1 Der Blogger hat auch die 12Xe-Core-Display-Version des PantherLake-Prozessors veröffentlicht.
 6700E debütiert am 6. Juni in China, Intel stellt offiziell Prozessoren der Xeon 6-Serie vor
Jun 06, 2024 am 10:51 AM
6700E debütiert am 6. Juni in China, Intel stellt offiziell Prozessoren der Xeon 6-Serie vor
Jun 06, 2024 am 10:51 AM
Diese Website berichtete am 4. Juni, dass Intel plant, ab sofort bis zum ersten Quartal nächsten Jahres eine neue Generation von Xeon-Prozessoren in Chargen auf den Markt zu bringen, von denen der Xeon 6700E am 6. Juni in China auf den Markt kommen wird. Intel plant, den Xeon 6900P „Granite Rapids“ im dritten Quartal 2024 mit bis zu 128 Kernen und den Xeon 6900E „Sierra Forest“ im ersten Quartal 2025 mit bis zu 288 Kernen auf den internationalen Markt zu bringen. Die „Xeon 6“-Serie ist in E- und P-Serie unterteilt: P-Serie Die P-Serie richtet sich hauptsächlich an rechenintensive und KI-Workloads wie High Performance Computing, Datenbank und Analyse, künstliche Intelligenz, Netzwerk, Edge und Infrastruktur/Speicher , mit bis zu 128 Personal Performance-Kernen, einschließlich 6900P/
