
 Betrieb und Instandhaltung
Sicherheit
Ein SRE, der kein Datenbeständesystem aufbauen kann, ist kein guter Wartungsmann.
Betrieb und Instandhaltung
Sicherheit
Ein SRE, der kein Datenbeständesystem aufbauen kann, ist kein guter Wartungsmann.
Ein SRE, der kein Datenbeständesystem aufbauen kann, ist kein guter Wartungsmann.

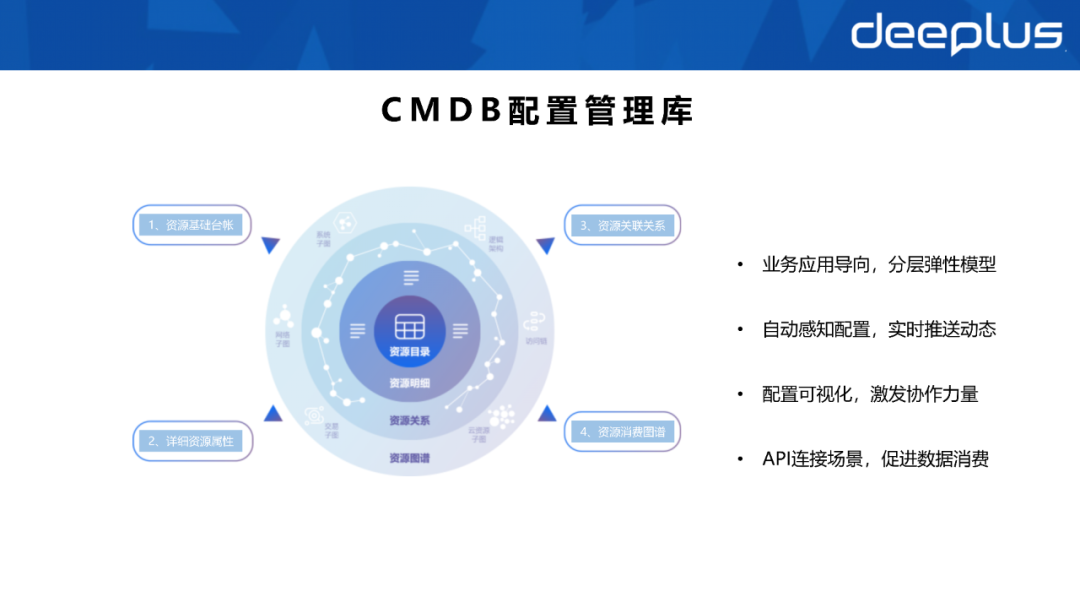
1. Datenbestände verstehen – IT-Wert für Unternehmen und Verbrauch Ohne Einheitlichkeit kann es leicht zu Dateninseln oder Nullnutzen kommen.
Nach dem Aufbau der Datenassetalisierung integrieren wir Daten aus verschiedenen Kanälen, erstellen eine einheitliche Datenquelle oder eine Prozessverknüpfung für die Datenerfassung, -speicherung und -analyse und vereinheitlichen dann die entsprechende Datenstruktur, Datenbeziehung und Verbrauchsquelle. Nachdem die Betriebsdaten gesammelt und zusammengestellt wurden, können sie den eigenen Entscheidungs- und Geschäftsprozessen dienen.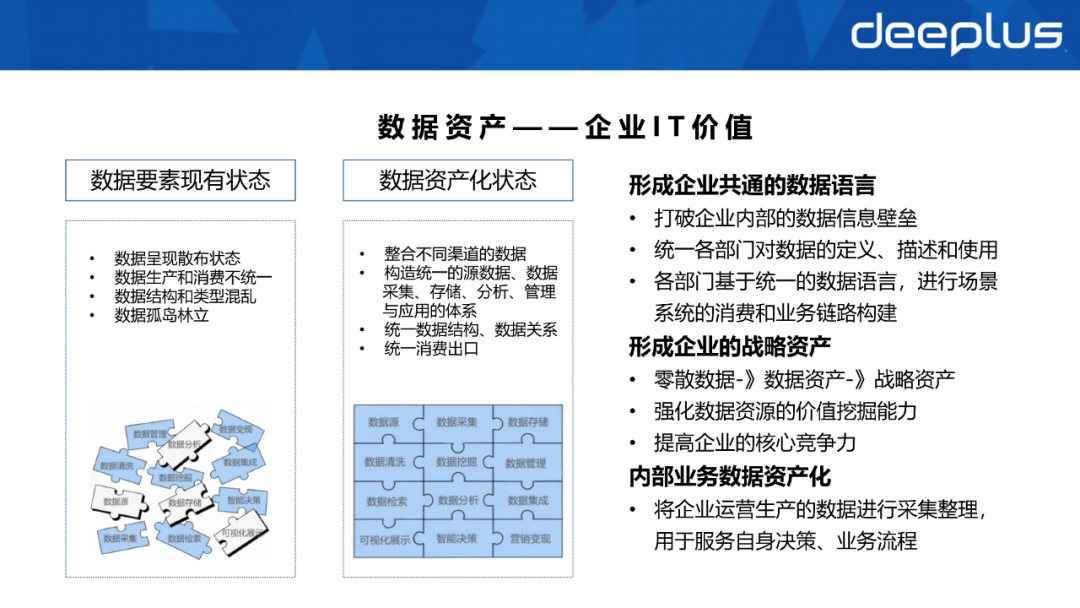 2. Datenbestände – am Beispiel von Betriebs- und Wartungsszenarien
2. Datenbestände – am Beispiel von Betriebs- und Wartungsszenarien
Bilder
Das obige Bild dient als Beispiel für die Klassifizierung von Datenbeständen. Um Datenbestände zu verstehen, müssen Sie die drei Elemente von Datenbeständen verstehen, nämlich die Entsprechung zwischen Datentyp, Datenform und Datenträger.Datentyp: Informationsbeschreibung der Betriebs- und Wartungsmerkmale
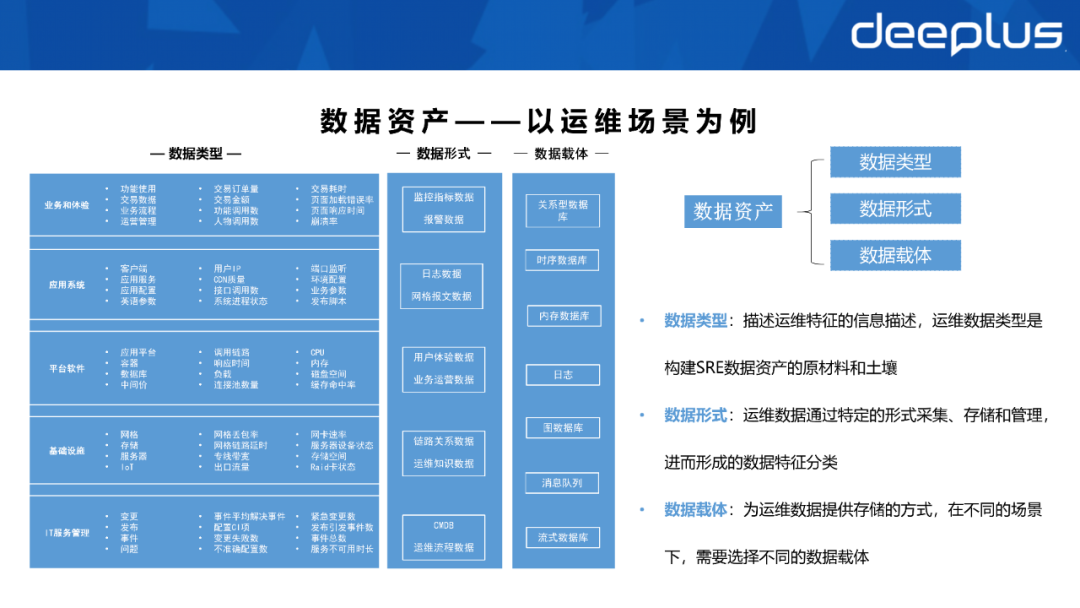 Auf der Ebene der Geschäftsindikatoren konzentriert sich SRE auf Transaktionszeit, Transaktionsauftragsvolumen und andere Informationen; auf der Ebene der Betriebssoftware konzentriert sich SRE auf Benutzer-IP und Schnittstellenaufrufstatus und andere Informationen; auf der Infrastrukturebene konzentriert sich SRE dann auf Informationen wie die entsprechende Netzwerkpaketverlustrate, die Speichernutzung oder die CPU-Auslastung. oder Notfalländerungen.
Auf der Ebene der Geschäftsindikatoren konzentriert sich SRE auf Transaktionszeit, Transaktionsauftragsvolumen und andere Informationen; auf der Ebene der Betriebssoftware konzentriert sich SRE auf Benutzer-IP und Schnittstellenaufrufstatus und andere Informationen; auf der Infrastrukturebene konzentriert sich SRE dann auf Informationen wie die entsprechende Netzwerkpaketverlustrate, die Speichernutzung oder die CPU-Auslastung. oder Notfalländerungen.
- Wir wählen die entsprechende Speichermethode basierend auf den unterschiedlichen Ausprägungen von Protokoll-, relationalen und Überwachungsdaten, wie relationale Datenbank, Persistenzdatenbank, Nachrichtenwarteschlange oder Logdateien usw.
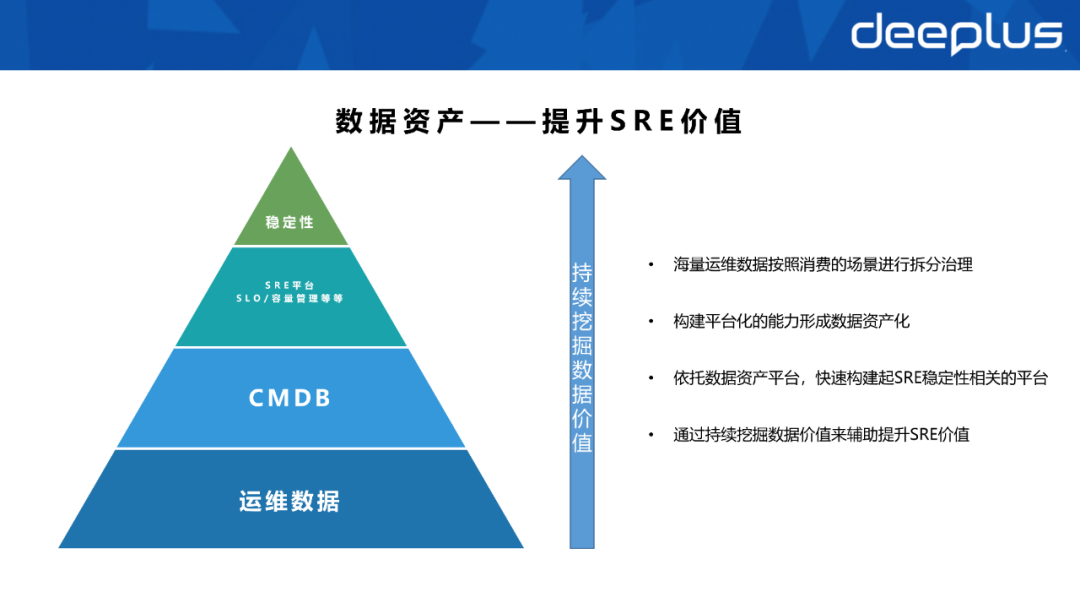
- 3. Datenbestände – steigern Sie den Wert von SRE
Bild
- Erstellen Sie zunächst ein Asset- basierte Plattform, wie z. B. After-Sales-Service Die im Artikel erwähnte CMDB. Verwenden Sie diese Plattformen, um eine große Menge an Betriebs- und Wartungsdaten entsprechend Verbrauchsszenarien zu zerlegen und zu verwalten und so eine Assetisierung zu realisieren.
 Betriebs- und Wartungsdaten sind von Natur aus nicht standardisiert. Beispielsweise sind die Datenspeichermethoden von Protokollen und Protokollüberwachung unterschiedlich. Und wir müssen die Ausarbeitung maximieren und die Standardisierung mit begrenzten Ressourcen abschließen. Für aktuelle, in der Branche beliebte Konzepte wie DataOps, AIOps und andere Modelle oder Szenarien fehlt uns noch eine ausgereifte und umfassende Datenmodellierungsmethodik.
Betriebs- und Wartungsdaten sind von Natur aus nicht standardisiert. Beispielsweise sind die Datenspeichermethoden von Protokollen und Protokollüberwachung unterschiedlich. Und wir müssen die Ausarbeitung maximieren und die Standardisierung mit begrenzten Ressourcen abschließen. Für aktuelle, in der Branche beliebte Konzepte wie DataOps, AIOps und andere Modelle oder Szenarien fehlt uns noch eine ausgereifte und umfassende Datenmodellierungsmethodik.
2. Etablieren Sie ein Betriebs- und Wartungsdaten-Governance-Modell. Die Förderung von Betriebs- und Wartungsdaten in Datenbestände muss sich auf drei Teile konzentrieren: Governance-Methoden, Governance-Prozesse und Technologieplattformen.
Bilder
1) Governance-Methoden Stammdatenverwaltung: Definieren und teilen Sie die Daten auf, auf die sich SRE konzentriert. Beispielsweise können Daten wie Hosts und CLP als Stammdaten verwendet werden, für die wir ein Lebenszyklusmanagement durchführen.
Stammdatenverwaltung: Definieren und teilen Sie die Daten auf, auf die sich SRE konzentriert. Beispielsweise können Daten wie Hosts und CLP als Stammdaten verwendet werden, für die wir ein Lebenszyklusmanagement durchführen.
2) Governance-Prozess
Der Governance-Prozess umfasst Strategie, Bau und Betrieb. Im Hinblick auf die Gesamtkonstruktion ist es notwendig, Plattformen und Werkzeuge zu bauen, um den eigenen Betrieb zu unterstützen.
3) Technologieplattform
Der Hauptzweck der Einrichtung einer Technologieplattform besteht darin, vorhandene und inkrementelle Daten durch Tools zu unterstützen.
3. Konzentrieren Sie sich auf die Schlüsselelemente der Datenverwaltung. Die Schlüsselelemente der Datenverwaltung konzentrieren sich hauptsächlich auf vier Aspekte: Organisationsgarantie, Systemaufbau, Projektimplementierung und Plattformunterstützung.
Organisatorische Garantie: Zur Lösung von Personalproblemen klären wir die Rollen und Aufgabenverteilung der Mitglieder. Ein dediziertes Data-Governance-Team besteht aus drei Rollen: Produkt, Betrieb und Forschung und Entwicklung.- Systemaufbau: Es ist notwendig, standardisierte Prozesse aufzubauen und deren ordnungsgemäße Umsetzung sicherzustellen, wie z. B. Ressourcenzugriff, Ressourcenentwicklung, Ressourcendatenmodell und andere Spezifikationen.
- Projektumsetzung: Beginnen Sie mit der umfassenden Sonderverwaltung. Datenverwaltung ist ein langfristiger Prozess, keine einfache Kampagne. Sollte die Datenqualität ernsthaft nicht dem Standard entsprechen, stellen wir ein spezielles Team zusammen und übernehmen einen mobilen Ansatz, um Datenqualitätsprobleme dringend zu beheben. Die Einrichtung langfristiger Governance-Mittel erfordert jedoch die Ausgabe entsprechender Governance-Methoden auf der Grundlage von Datenprodukten und deren Implementierung in produktive Plattformmittel, um Datenverantwortliche zur Durchführung von Daten-Governance zu bewegen.
- Plattformunterstützung: Der Plattformaufbau konzentriert sich hauptsächlich auf Feinmessung, Ausführung und Governance-Effizienz sowie andere Dimensionen. 3. Aufbau der CMDB-Plattform Wir müssen dem Unternehmen entsprechende Modelle in Schichten erstellen und dann die Konfigurationsdynamik in Echtzeit durch automatisierte Erfassung oder standardisierte Prozesse vorantreiben.
- Die entsprechende Konfiguration benötigt auch eine entsprechende visuelle Schnittstelle, um die Zusammenarbeit anzuregen. Letztendlich fördern diese Daten Datenverbrauchsszenarien über APP oder entsprechende Offline-Szenarien.
 3. Die Positionierung von CMBD im neuen Zeitalter – anwendungszentriert
3. Die Positionierung von CMBD im neuen Zeitalter – anwendungszentriert
,
Anwendungszentriert kann es die Organisation-Projekt-Personal-Beziehung realisieren und an die Anwendung binden. Verwenden Sie während des Anwendungsbetriebs entsprechende Ressourcen (Serverressourcen, Konfigurationscenter, Beobachtbarkeitsindikatoren usw.) und bilden Sie dann Zugehörigkeiten entsprechend der Organisationsstruktur des Unternehmens. Schließlich wird die Perspektive der Organisationsstruktur auf die Perspektive der Mikrodienste verwiesen, um Ressourcen zu bilden ihre Ressourcen Beziehung – Topologie, einschließlich Anwendungstopologie und physische Topologie. 4. Vorteile der anwendungszentrierten CMDB Bild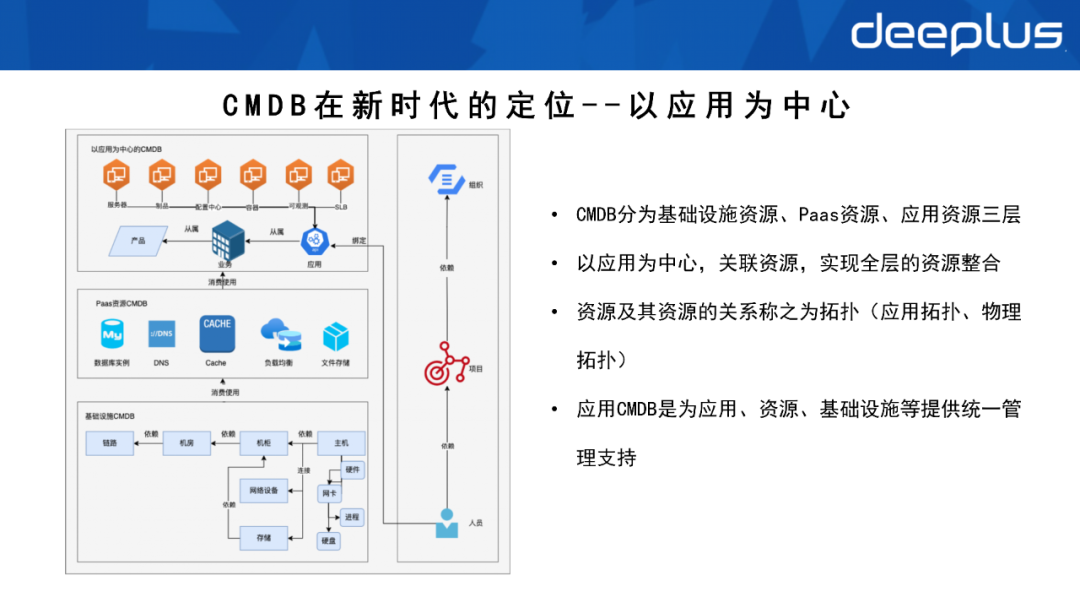
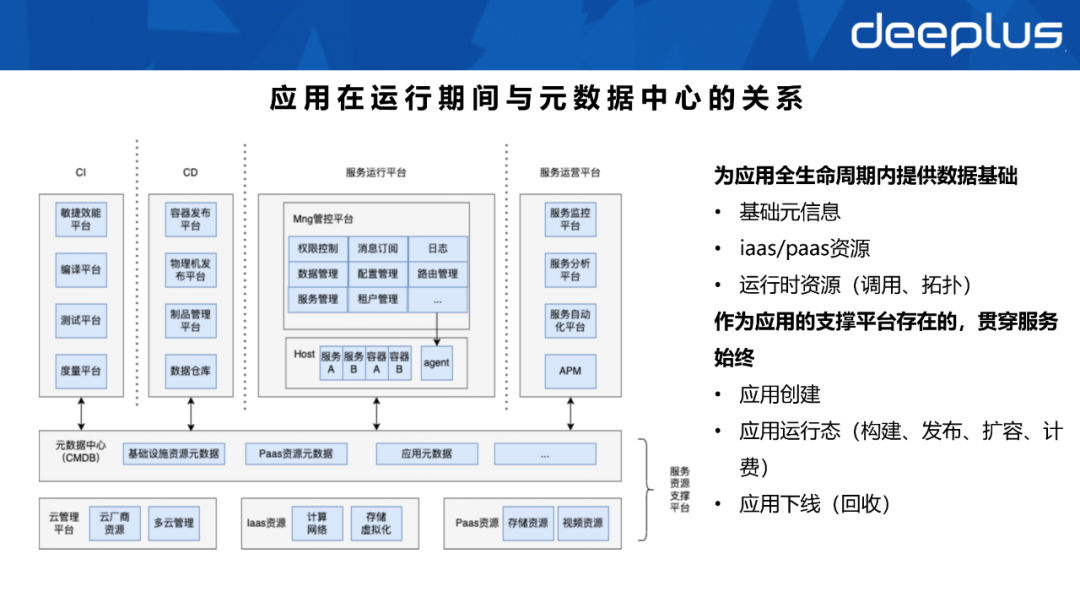
Das obige Bild zeigt die CMDB, die die speichert Die Metadaten, Paas-bezogenen Daten und Betriebsdaten der Testeinrichtungen werden der oberen Schicht (CI-Plattform, CD-Plattform, Service-Betriebsplattform und Service-Betriebsplattform) bereitgestellt. Die in der Abbildung dargestellte untere Plattform bildet die Service-Ressourcen-Unterstützungsplattform.  Der Vorteil einer solchen Konstruktion besteht darin, grundlegende Datenunterstützung für den gesamten Lebenszyklus der Anwendung bereitzustellen, einschließlich der Anwendungserstellung, der Anwendungslaufzeit (Build, Release, Erweiterung, Abrechnung) und der Wiederverwertung von Ressourcen, nachdem die Anwendung offline ist.
Der Vorteil einer solchen Konstruktion besteht darin, grundlegende Datenunterstützung für den gesamten Lebenszyklus der Anwendung bereitzustellen, einschließlich der Anwendungserstellung, der Anwendungslaufzeit (Build, Release, Erweiterung, Abrechnung) und der Wiederverwertung von Ressourcen, nachdem die Anwendung offline ist.
 Bilder
Bilder
Unabhängig davon, ob ein CMDB-System vorhanden ist oder nicht, besteht tatsächlich eine CMDB-Anforderung, und Konfigurationsinformationen werden von der Abteilung als Einheit verwaltet.
Informationen sind isoliert und nicht zeitnah und die Integrität und die Richtigkeit kann nicht garantiert werden. 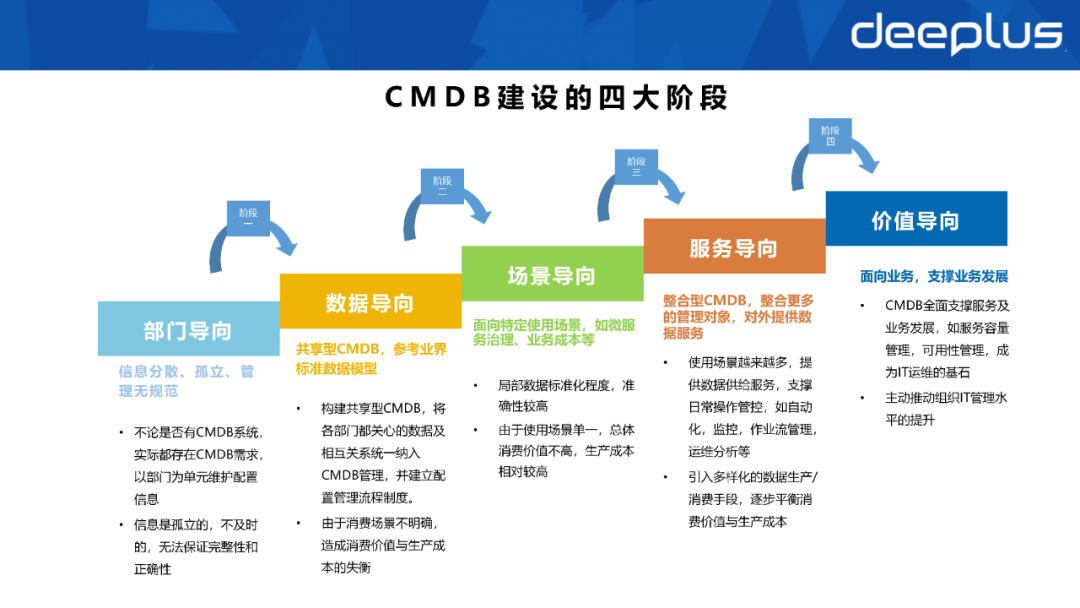 Datengesteuert:
Datengesteuert:
- Die Daten und Zusammenhänge, die alle Abteilungen betreffen, werden in das CMDB-Management integriert und ein Konfigurationsmanagement-Prozesssystem eingerichtet.
- Aufgrund unklarer Verbrauchsszenarien besteht ein Ungleichgewicht zwischen Verbrauchswert und Produktionskosten.
- Die Datenproduktionskosten von Station B sind nicht sehr hoch, aber es müssen viele Datenverbrauchsprodukte erstellt werden, oder die Geschäftsseite passt häufig die Szenenanforderungen an. CMDB muss angepasst und in die Entwicklung einbezogen werden, um die Geschäftsseite zu vervollständigen Forderungen. Dadurch wurde das Problem aufgedeckt. Die CMDB verfügt über mehr als 300 OKACIs, was unpraktisch zu warten ist.
Szenenorientiert:
- Der Grad der lokalen Datenstandardisierung und hohe Genauigkeit;
- Aufgrund des Einzelnutzungsszenarios ist der Gesamtverbrauchswert nicht hoch und die Produktionskosten relativ hoch.
Dienstleistungsorientierung:
- Datenbereitstellungsdienste unterstützen die tägliche Betriebsführung und -steuerung, wie Automatisierung, Überwachung, Workflow-Management, Betriebs- und Wartungsanalyse usw.;
- Einführung diversifizierter Datenproduktions-/-verbrauchsmethoden, um den Verbrauchswert schrittweise auszugleichen und Produktionskosten.
Wertorientierung:
- CMDB unterstützt die Service- und Geschäftsentwicklung wie Servicekapazitätsmanagement und Verfügbarkeitsmanagement vollständig und wird zum Eckpfeiler des IT-Betriebs und der IT-Wartung.
- Fördert aktiv die Verbesserung des IT-Managementniveaus der Organisation.
7. So erstellen Sie das CMDB-Modell
 Bilder
Bilder
- Definieren Sie Datentypen: einschließlich Hosts, Switches, Anwendungen und Anwendungskonfigurationsdateien, die dies nach Erhalt der Anfrage untersuchen.
- Datenkernattribute definieren: Am Beispiel des Hosts müssen Sie die Kernattribute von Ressourcen wie IP, Seriennummer, Computerraum und Cloud-Anbieter melden oder erfassen.
- Erstellen Sie direkte Beziehungen in Datenmodellen: Sortieren Sie die Korrespondenz zwischen Ressourcen, z. B. Einschlussbeziehungen, Abhängigkeitsbeziehungen, laufende Beziehungen usw., um die anschließende Erstellung der Ressourcentopologie zu erleichtern. Wenn beispielsweise die Anwendung einen Datentyp und der Host einen anderen Datentyp verwendet, ist die Anwendung beim Ausführen vom Host abhängig, und der Host kann wiederum die Anwendung bilden.
- Bestätigung des Verbrauchsszenarios: Die Bestätigung des Verbrauchsszenarios bedeutet die Bestätigung, für welche Phasen die Daten verwendet werden. Wenn es für die Clusterbereitstellung verwendet wird, müssen Sie möglicherweise eine entsprechende Bereitstellung in der Anwendungsdimension oder entsprechende Betriebs- und Wartungsaufgaben durchführen.
- Datenspezifikationen festlegen: Wie ist der Lebenszyklus (von der Erstellung über die Produktion bis zur Bereitstellung)? Wie erkennt die Plattform Änderungen im Datenstatus?
Zusammenfassend lässt sich sagen, dass wir den gesamten Lebenszyklus von Daten als Ausgangspunkt nehmen, Attribute bestimmen, Zusammenhänge klären, Verbrauchsszenarien klären und automatisierte Prozesse nutzen müssen, um die Echtzeitfähigkeit und Genauigkeit der Daten sicherzustellen.
1) Modellbeziehungsdefinition Wie etabliert ist diese Plattform? Welche Qualität haben diese Daten? Wie ist die Organisationsstruktur und technische Struktur? Wie ist der Status der Ressourcen, die während des zukünftigen Einführungsprozesses benötigt werden? Projektstart: Zu Beginn müssen das CI-Modell und die Beziehung zwischen Zugriffsressourcen, späteren Verbrauchsszenarien, Datenquellen und CI-Stakeholdern definiert werden. Dateninstanziierung: Bei der Dateninstanziierungserkennung wird eine Testumgebung erstellt und CI-Modelle oder instanziierte Daten werden importiert. Datenüberprüfung: Überprüfen Sie in der UG-Umgebung den Vergleich zwischen Datenberichten und tatsächlicher Ausgabe, um zu bestätigen, ob die Datenqualität den Standards entspricht. Nachdem die Datenqualität den Standard erreicht hat, muss eine Produktionsumgebung erstellt werden, um den Status der Daten in der Produktionsumgebung zu erkennen.
Dateninstanziierung: Bei der Dateninstanziierungserkennung wird eine Testumgebung erstellt und CI-Modelle oder instanziierte Daten werden importiert. Datenüberprüfung: Überprüfen Sie in der UG-Umgebung den Vergleich zwischen Datenberichten und tatsächlicher Ausgabe, um zu bestätigen, ob die Datenqualität den Standards entspricht. Nachdem die Datenqualität den Standard erreicht hat, muss eine Produktionsumgebung erstellt werden, um den Status der Daten in der Produktionsumgebung zu erkennen.
Datenverbrauchsszenario: Nachdem die Daten in die Produktionsumgebung gelangt sind, müssen wir das Datenverbrauchsszenario überprüfen. Wir müssen eine Verbindung mit der Betriebsplattform oder SRE-Plattform herstellen.
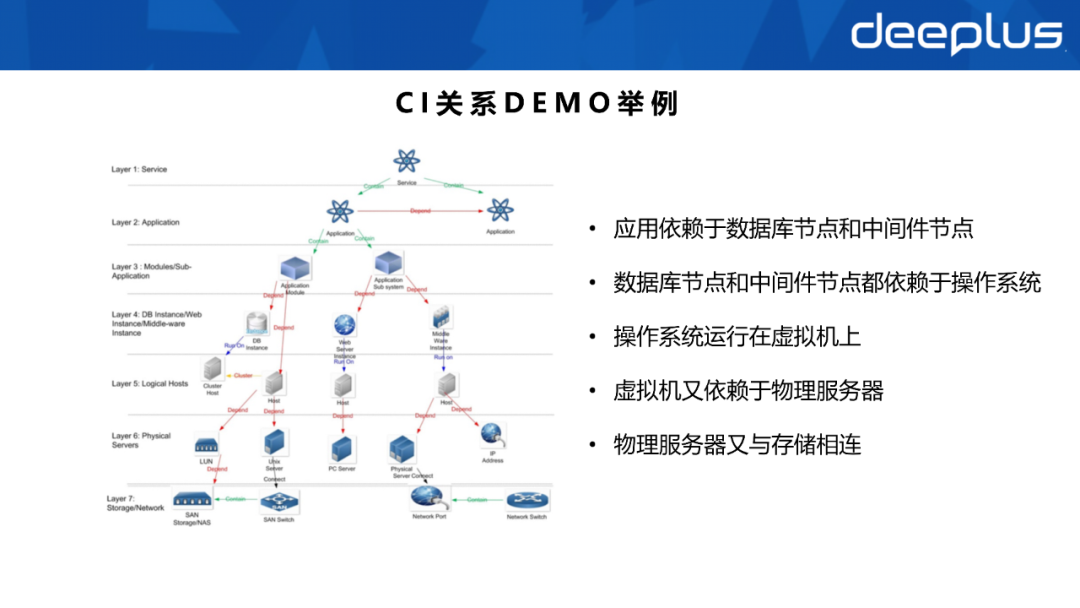 4) Standardisierung zuerstStandardisierung zuerst bedeutet, dass sich alle Angelegenheiten vor der Implementierung um die Standardisierung drehen. Dazu gehören einige strenge Anforderungen, wie z. B. Planungsanforderungen, Prozessanforderungen, organisatorische Anforderungen und Plattformanforderungen.
4) Standardisierung zuerstStandardisierung zuerst bedeutet, dass sich alle Angelegenheiten vor der Implementierung um die Standardisierung drehen. Dazu gehören einige strenge Anforderungen, wie z. B. Planungsanforderungen, Prozessanforderungen, organisatorische Anforderungen und Plattformanforderungen.
Spezifikationsanforderungen:
- Definieren Sie klar die Rolle der CMDB-Plattform und die Beziehung zwischen anderen Geschäftssystemen.
- Definieren Sie klar den Ressourcenmanagementprozess, die verantwortliche Person und die verantwortliche Plattform.
- Definieren Sie klar die grundlegenden Standards für Ressourcen und Abweichungen Managementmethoden;
- Planen und erstellen Sie Konfigurationsmanagementfunktionen aus der Perspektive von Service-Geschäftsszenarien.
- Prozessanforderungen:
- Es kann den Ressourcenstatus wirklich widerspiegeln;
- Es kann alle Ressourceninformationen und die Beziehungen zwischen Ressourcen vollständig enthalten;
- Daten können von Benutzern und Systemen bequem, zeitnah und effizient abgerufen werden.
- Organisatorische Anforderungen:
- Jedes Geschäftsteam ist klar für die Konfigurationsnutzung und -verbesserung verantwortlich;
- Bilden Sie einen Mechanismus für die Diskussion, Optimierung und Bedarfserfassung des Konfigurationsmanagements.
- Plattformanforderungen:
- Echtzeitverfolgung von Ressourcenstatus und Konfigurationsänderungen;
- Das Modell ist flexibel und kann in Echtzeit entsprechend den Geschäftsanforderungen erweitert und angepasst werden
- Konfigurationsvisualisierung kann die Analyse und schnelle Lokalisierung von Ressourcenproblemen unterstützen.
- 5) Erstellen Sie einen geschlossenen Datenlebenszyklus.
Bestimmen Sie zunächst die Anwendungsattribute. Zu den Attributen der Anwendung können der chinesische und englische Name der Anwendung, die Anwendungsebene, die eindeutige ID, das zugeordnete Unternehmen und die Geschäftsdomäne usw. gehören. Der Inhalt der Attribute hängt hauptsächlich von der persönlichen Definition ab. Nachdem die Anwendung definiert wurde, weist die Anwendung möglicherweise eine Beziehung zu anderen CIs auf und muss weiter geklärt werden.
Zweitens klären Sie, wer für die Eigenschaften der Anwendung verantwortlich ist. Für Anwendungen gibt es entsprechende Verantwortliche, F&E, SRE usw. Wir verfügen über entsprechende Prozesse für Anwendungskonstruktion, -freigabe, -änderungen und andere Aktionen rund um Benutzer, um die Anwendungskonfiguration und Änderungsprüfung sicherzustellen.
Führen Sie abschließend geplante Erfassungsaufgaben durch, um die endgültige Datengenauigkeit der Anwendung sicherzustellen.
6) Fördern Sie die automatische Erkennung und Aktualisierung von Konfigurationen
Die im obigen Bild erwähnten „Ressourcen“ sind immer noch Ressourcen im herkömmlichen Sinne, beispielsweise Serverressourcen. Diese Ressourcen werden über eine bestimmte Methode gesammelt und schließlich an die Ressourcenverwaltungsplattform gemeldet.
Erstellen Sie eine vollständige Konfigurationserfassungsfunktion, um manuelle Wartungsszenarien zu vermeiden.- Ermitteln Sie automatisch Konfigurationsinformationen von Ressourcen und Anwendungen.
- Verbinden Sie Prozesse, Verwaltungsplattformen und Geräte, um den Konfigurationsstatus in Echtzeit abzurufen und Verwendung von Spezifikationen und Durchführung von Compliance-Prüfungen über CMDB;
- Förderung der Realisierung eines geschlossenen Konfigurations- und Verbrauchskreislaufs und automatische Aufrechterhaltung der Datenzuverlässigkeit durch Verbrauchsfeedback.
Das obige ist der detaillierte Inhalt vonEin SRE, der kein Datenbeständesystem aufbauen kann, ist kein guter Wartungsmann.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
Wenn Sie wissen müssen, wie Sie die Filterung mit mehreren Kriterien in Excel verwenden, führt Sie das folgende Tutorial durch die Schritte, um sicherzustellen, dass Sie Ihre Daten effektiv filtern und sortieren können. Die Filterfunktion von Excel ist sehr leistungsstark und kann Ihnen dabei helfen, aus großen Datenmengen die benötigten Informationen zu extrahieren. Diese Funktion kann Daten entsprechend den von Ihnen festgelegten Bedingungen filtern und nur die Teile anzeigen, die die Bedingungen erfüllen, wodurch die Datenverwaltung effizienter wird. Mithilfe der Filterfunktion können Sie Zieldaten schnell finden und so Zeit beim Suchen und Organisieren von Daten sparen. Diese Funktion kann nicht nur auf einfache Datenlisten angewendet werden, sondern auch nach mehreren Bedingungen gefiltert werden, um Ihnen dabei zu helfen, die benötigten Informationen genauer zu finden. Insgesamt ist die Filterfunktion von Excel sehr praktisch
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Huawei wird nächstes Jahr innovative MED-Speicherprodukte auf den Markt bringen: Die Rack-Kapazität übersteigt 10 PB und der Stromverbrauch beträgt weniger als 2 kW
Mar 07, 2024 pm 10:43 PM
Huawei wird nächstes Jahr innovative MED-Speicherprodukte auf den Markt bringen: Die Rack-Kapazität übersteigt 10 PB und der Stromverbrauch beträgt weniger als 2 kW
Mar 07, 2024 pm 10:43 PM
Diese Website berichtete am 7. März, dass Dr. Zhou Yuefeng, Präsident der Datenspeicherproduktlinie von Huawei, kürzlich an der MWC2024-Konferenz teilgenommen und speziell die magnetoelektrische Speicherlösung OceanStorArctic der neuen Generation vorgestellt hat, die für warme Daten (WarmData) und kalte Daten (ColdData) entwickelt wurde. Zhou Yuefeng, Präsident der Datenspeicherproduktlinie von Huawei, hat eine Reihe innovativer Lösungen veröffentlicht: Die dieser Website beigefügte offizielle Pressemitteilung von Huawei lautet wie folgt: Die Kosten dieser Lösung sind 20 % niedriger als die von Magnetbändern Der Stromverbrauch ist 90 % niedriger als der von Festplatten. Laut Foreign Technology Media BlocksandFiles gab ein Huawei-Sprecher auch Informationen über die magnetoelektrische Speicherlösung preis: Huaweis magnetoelektronische Disk (MED) sei eine bedeutende Innovation bei magnetischen Speichermedien. ME der ersten Generation
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
