
 Technologie-Peripheriegeräte
KI
Microsofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token
Technologie-Peripheriegeräte
KI
Microsofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token
Microsofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token

Wenn jeder seine eigenen großen Modelle weiter aktualisiert und iteriert, ist die Fähigkeit des LLM (Large Language Model), Kontextfenster zu verarbeiten, auch zu einem wichtigen Bewertungsindikator geworden.
Zum Beispiel unterstützt das Promi-Großmodell GPT-4 32.000 Token, was 50 Textseiten entspricht. Das von einem ehemaligen Mitglied von OpenAI gegründete Unternehmen hat Claudes Token-Verarbeitungskapazitäten auf 100.000, etwa 75.000 Wörter, erhöht. was in etwa einer One-Click-Zusammenfassung von „Harry Potter“ Teil Eins entspricht.
In der neuesten Studie von Microsoft haben sie Transformer dieses Mal direkt auf 1 Milliarde Token erweitert. Dies eröffnet neue Möglichkeiten zur Modellierung sehr langer Sequenzen, beispielsweise die Behandlung eines gesamten Korpus oder sogar des gesamten Internets als eine Sequenz.
Zum Vergleich: Die durchschnittliche Person kann 100.000 Token in etwa 5 Stunden lesen und es kann länger dauern, diese Informationen zu verarbeiten, zu merken und zu analysieren. Claude schafft das in weniger als einer Minute. Würde man sie in diese Studie von Microsoft umrechnen, wäre das eine atemberaubende Zahl.
 Bilder
Bilder
- Papieradresse: https://arxiv.org/pdf/2307.02486.pdf
- Projektadresse: https://github.com/microsoft/unilm/tree/master
Konkret schlägt die Forschung LONGNET vor, eine Transformer-Variante, die die Sequenzlänge auf über 1 Milliarde Token erweitern kann, ohne die Leistung bei kürzeren Sequenzen zu beeinträchtigen. Der Artikel schlägt auch eine erweiterte Aufmerksamkeit vor, die den Wahrnehmungsbereich des Modells exponentiell erweitern kann.
LONGNET hat die folgenden Vorteile:
1) Es hat eine lineare Rechenkomplexität;
2) Es kann als verteilter Trainer für längere Sequenzen verwendet werden;
3) Die Aufmerksamkeit kann erweitert werden Die Verwendung ohne Seam ersetzt die Standardaufmerksamkeit und kann nahtlos in bestehende Transformer-basierte Optimierungsmethoden integriert werden.
Experimentelle Ergebnisse zeigen, dass LONGNET sowohl bei der Modellierung langer Sequenzen als auch bei allgemeinen Sprachaufgaben eine starke Leistung zeigt.
In Bezug auf die Forschungsmotivation heißt es in dem Papier, dass die Erweiterung neuronaler Netze in den letzten Jahren zu einem Trend geworden ist und viele Netze mit guter Leistung untersucht wurden. Unter diesen sollte die Sequenzlänge als Teil des neuronalen Netzwerks idealerweise unendlich sein. In der Realität ist jedoch oft das Gegenteil der Fall, sodass das Überschreiten der Sequenzlängenbeschränkung erhebliche Vorteile mit sich bringt:
- Erstens stellt es dem Modell ein großes Speicher- und Empfangsfeld zur Verfügung, sodass es effektiv mit Menschen und anderen kommunizieren kann Welt. Interaktion.
- Zweitens enthält ein längerer Kontext komplexere kausale Zusammenhänge und Argumentationspfade, die das Modell in den Trainingsdaten nutzen kann. Im Gegenteil führen kürzere Abhängigkeiten zu mehr falschen Korrelationen, was der Verallgemeinerung des Modells nicht förderlich ist.
- Drittens kann eine längere Sequenzlänge dem Modell helfen, längere Kontexte zu erkunden, und extrem lange Kontexte können dem Modell auch dabei helfen, das katastrophale Vergessensproblem zu lindern.
Die größte Herausforderung bei der Verlängerung der Sequenzlänge besteht jedoch darin, das richtige Gleichgewicht zwischen Rechenkomplexität und Modellausdruckskraft zu finden.
Modelle im RNN-Stil werden beispielsweise hauptsächlich verwendet, um die Sequenzlänge zu erhöhen. Allerdings schränkt seine sequentielle Natur die Parallelisierung während des Trainings ein, was bei der Modellierung langer Sequenzen von entscheidender Bedeutung ist.
In letzter Zeit sind Zustandsraummodelle für die Sequenzmodellierung sehr attraktiv geworden, die während des Trainings als CNN ausgeführt und zur Testzeit in ein effizientes RNN umgewandelt werden können. Bei normalen Längen ist die Leistung dieses Modelltyps jedoch nicht so gut wie bei Transformer.
Eine weitere Möglichkeit, die Sequenzlänge zu verlängern, besteht darin, die Komplexität des Transformers zu reduzieren, also die quadratische Komplexität der Selbstaufmerksamkeit. Zu diesem Zeitpunkt wurden einige effiziente transformatorbasierte Varianten vorgeschlagen, darunter niedrigrangige Aufmerksamkeitsmethoden, Kernel-basierte Methoden, Downsampling-Methoden und abrufbasierte Methoden. Diese Ansätze müssen Transformer jedoch noch auf die Größenordnung von 1 Milliarde Token skalieren (siehe Abbildung 1).
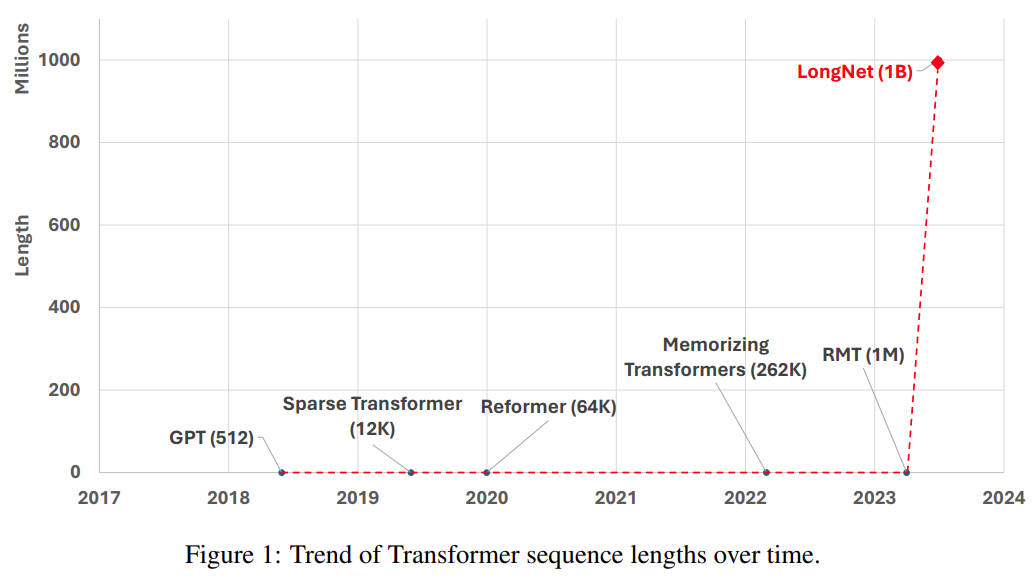 Bilder
Bilder
Die folgende Tabelle zeigt den Vergleich der Rechenkomplexität verschiedener Berechnungsmethoden. N ist die Sequenzlänge und d ist die verborgene Dimension.
 Bilder
Bilder
Methode
Die Forschungslösung LONGNET hat die Sequenzlänge erfolgreich auf 1 Milliarde Token erweitert. Konkret schlägt diese Forschung eine neue Komponente namens erweiterte Aufmerksamkeit vor und ersetzt den Aufmerksamkeitsmechanismus von Vanilla Transformer durch erweiterte Aufmerksamkeit. Ein allgemeines Designprinzip besteht darin, dass die Aufmerksamkeitsverteilung mit zunehmendem Abstand zwischen Token exponentiell abnimmt. Die Studie zeigt, dass dieser Entwurfsansatz eine lineare Rechenkomplexität und eine logarithmische Abhängigkeit zwischen Token erreicht. Dadurch wird der Konflikt zwischen begrenzten Aufmerksamkeitsressourcen und dem Zugriff auf jeden Token gelöst.
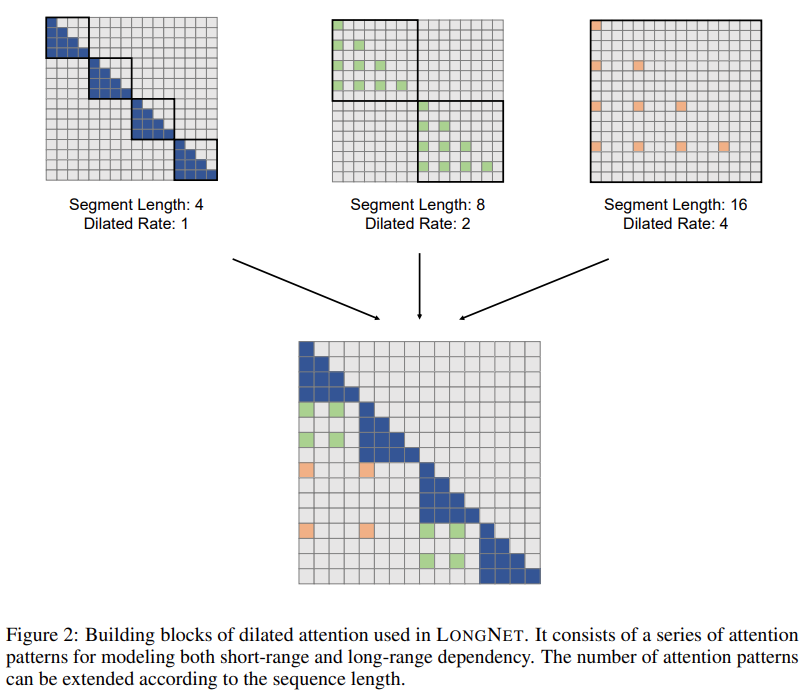 Bilder
Bilder
Während der Implementierung kann LONGNET in einen dichten Transformer umgewandelt werden, um vorhandene Optimierungsmethoden für Transformer (wie Kernelfusion, Quantisierung und verteiltes Training) nahtlos zu unterstützen. Unter Ausnutzung der linearen Komplexität kann LONGNET knotenübergreifend parallel trainiert werden, wobei verteilte Algorithmen verwendet werden, um Rechen- und Speicherbeschränkungen zu überwinden.
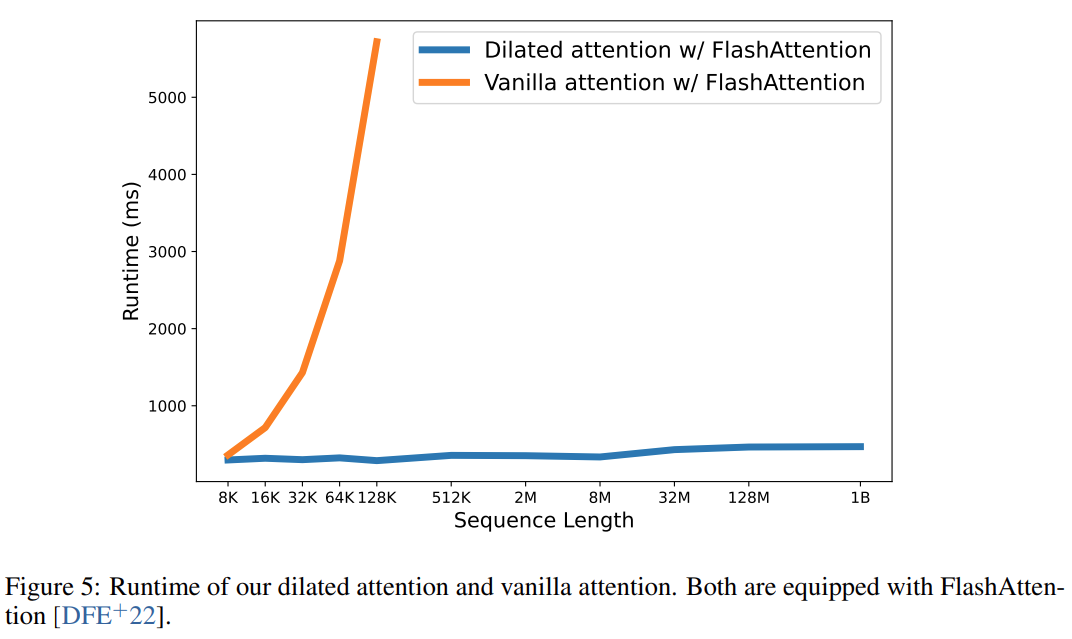
Letztendlich hat diese Forschung die Sequenzlänge effektiv auf 1B Token erweitert, und die Laufzeit war nahezu konstant, wie in der Abbildung unten gezeigt. Im Gegensatz dazu leidet die Laufzeit des Vanilla-Transformers unter quadratischer Komplexität.
Diese Forschung führt den Mehrkopf-Mechanismus der erweiterten Aufmerksamkeit weiter ein. Wie in Abbildung 3 unten dargestellt, führt diese Studie verschiedene Berechnungen über verschiedene Köpfe hinweg durch, indem verschiedene Teile von Abfrage-Schlüssel-Wert-Paaren sparsifiziert werden.
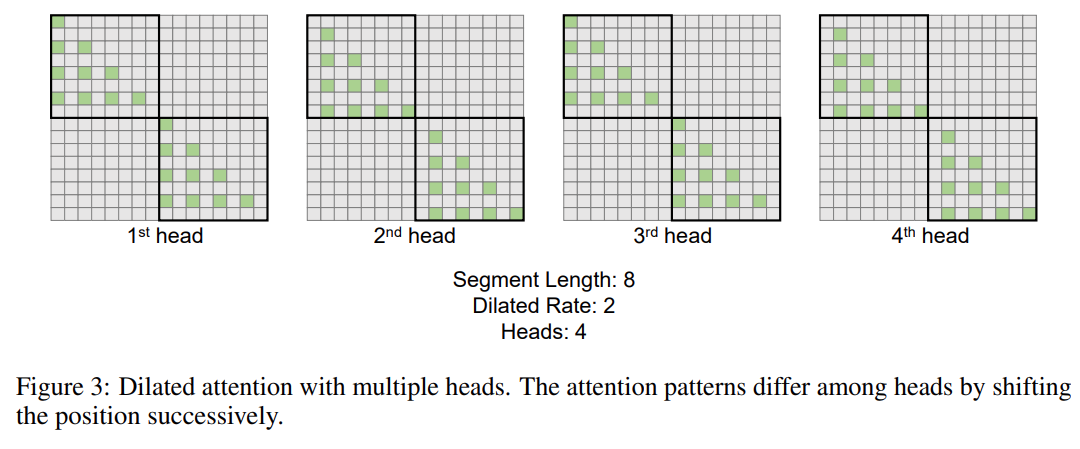 Bilder
Bilder
Verteiltes Training
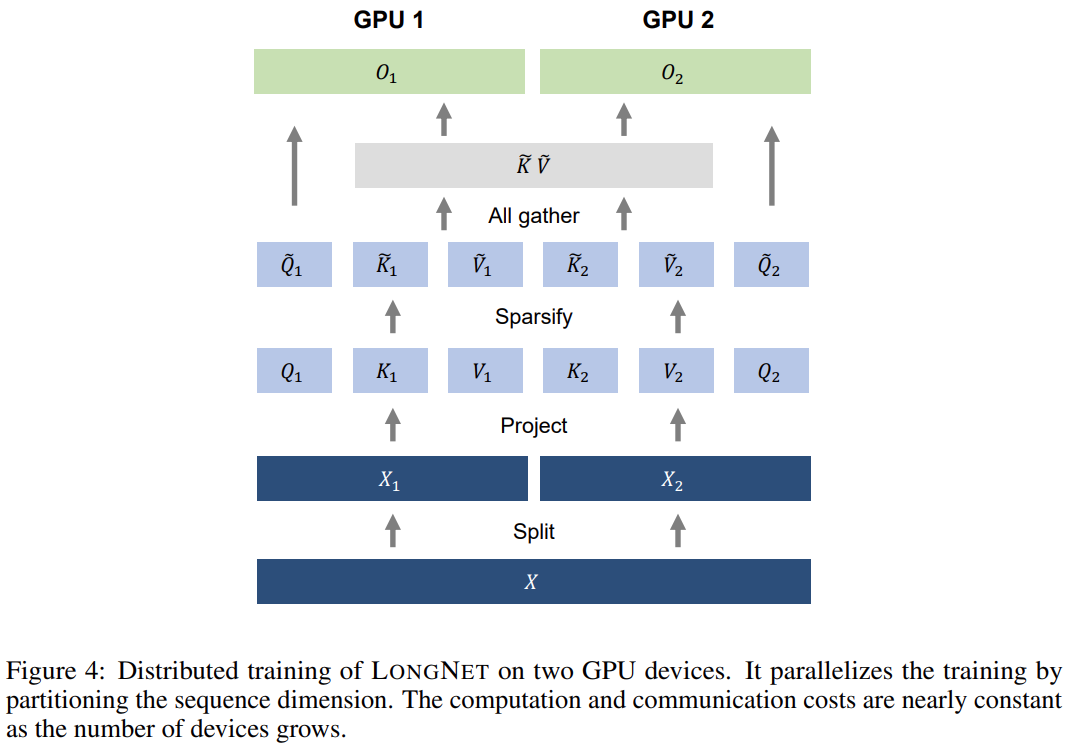
Obwohl die Rechenkomplexität der erweiterten Aufmerksamkeit aufgrund von Rechen- und Speicherbeschränkungen stark reduziert wurde, wird es auf einer einzigen sein GPU Gerät Eine Skalierung der Sequenzlänge auf Millionen ist nicht möglich. Es gibt einige verteilte Trainingsalgorithmen für das Training großer Modelle, wie z. B. Modellparallelität [SPP+19], Sequenzparallelität [LXLY21, KCL+22] und Pipeline-Parallelität [HCB+19]. Diese Methoden reichen jedoch für LONGNET nicht aus ., insbesondere wenn die Sequenzdimension sehr groß ist. 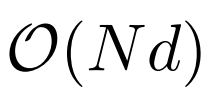 Diese Forschung nutzt die lineare Rechenkomplexität von LONGNET für das verteilte Training von Sequenzdimensionen. Abbildung 4 unten zeigt den verteilten Algorithmus auf zwei GPUs, der weiter auf eine beliebige Anzahl von Geräten skaliert werden kann.
Diese Forschung nutzt die lineare Rechenkomplexität von LONGNET für das verteilte Training von Sequenzdimensionen. Abbildung 4 unten zeigt den verteilten Algorithmus auf zwei GPUs, der weiter auf eine beliebige Anzahl von Geräten skaliert werden kann.
 Experimente
Experimente
Die Studie verglich LONGNET mit Vanilla Transformer und Sparse Transformer. Der Unterschied zwischen den Architekturen besteht in der Aufmerksamkeitsschicht, während die anderen Schichten unverändert bleiben. Die Forscher erweiterten die Sequenzlänge dieser Modelle von 2K auf 32K und reduzierten gleichzeitig die Stapelgröße, um sicherzustellen, dass die Anzahl der Token in jedem Stapel unverändert blieb.
Tabelle 2 fasst die Ergebnisse dieser Modelle für den Stack-Datensatz zusammen. Die Forschung verwendet Komplexität als Bewertungsmaßstab. Die Modelle wurden mit unterschiedlichen Sequenzlängen von 2k bis 32k getestet. Wenn die Eingabelänge die vom Modell unterstützte maximale Länge überschreitet, implementiert die Forschung blockweise kausale Aufmerksamkeit (BCA) [SDP+22], eine hochmoderne Extrapolationsmethode für die Inferenz von Sprachmodellen.
Darüber hinaus wurde in der Studie die absolute Positionskodierung entfernt. Erstens zeigen die Ergebnisse, dass eine Erhöhung der Sequenzlänge während des Trainings im Allgemeinen zu besseren Sprachmodellen führt. Zweitens ist die Methode zur Extrapolation der Sequenzlänge in der Inferenz nicht anwendbar, wenn die Länge viel größer ist, als das Modell unterstützt. Schließlich übertrifft LONGNET durchweg die Basismodelle und demonstriert damit seine Wirksamkeit bei der Sprachmodellierung.
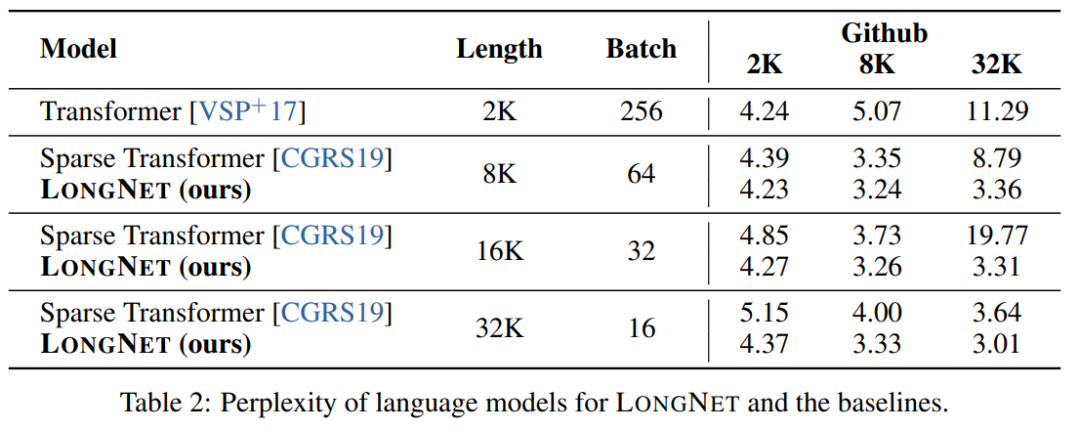
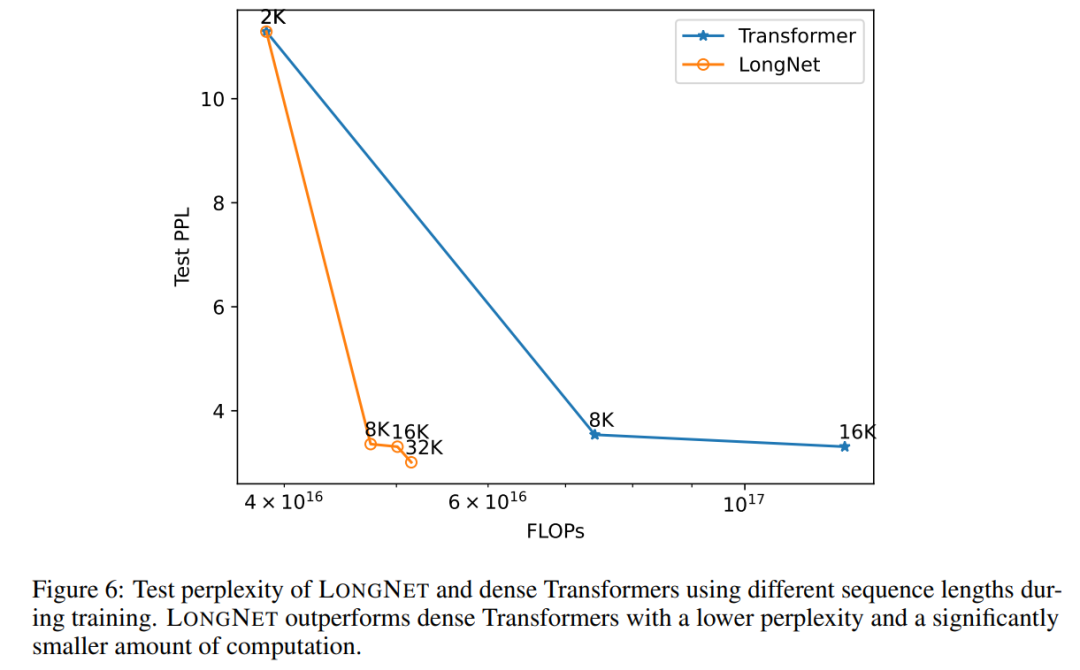
Abbildung 6 zeigt die Sequenzlängen-Erweiterungskurven von Vanilla Transformer und LONGNET. Diese Studie schätzt den Rechenaufwand durch Zählen der gesamten Flops von Matrixmultiplikationen. Die Ergebnisse zeigen, dass sowohl Vanilla Transformer als auch LONGNET durch das Training größere Kontextlängen erreichen. Allerdings kann LONGNET die Kontextlänge effizienter verlängern und so einen geringeren Testverlust mit weniger Rechenaufwand erzielen. Dies zeigt den Vorteil längerer Trainingseingaben gegenüber der Extrapolation. Experimente zeigen, dass LONGNET eine effizientere Möglichkeit ist, die Kontextlänge in Sprachmodellen zu verlängern. Dies liegt daran, dass LONGNET längere Abhängigkeiten effizienter lernen kann.
Modellgröße erweitern
Eine wichtige Eigenschaft großer Sprachmodelle ist, dass der Verlust in einem Potenzgesetz mit zunehmendem Rechenaufwand skaliert. Um zu überprüfen, ob LONGNET immer noch ähnlichen Skalierungsregeln folgt, trainierte die Studie eine Reihe von Modellen mit unterschiedlichen Modellgrößen (von 125 Millionen bis 2,7 Milliarden Parametern). 2,7 Milliarden Modelle wurden mit 300 Milliarden Token trainiert, während die übrigen Modelle etwa 400 Milliarden Token verwendeten. Abbildung 7 (a) zeigt die Expansionskurve von LONGNET im Hinblick auf die Berechnung. Die Studie berechnete die Komplexität mit demselben Testsatz. Dies beweist, dass LONGNET immer noch einem Potenzgesetz folgen kann. Dies bedeutet auch, dass Dense Transformer keine Voraussetzung für die Erweiterung von Sprachmodellen ist. Darüber hinaus werden mit LONGNET Skalierbarkeit und Effizienz gewonnen.
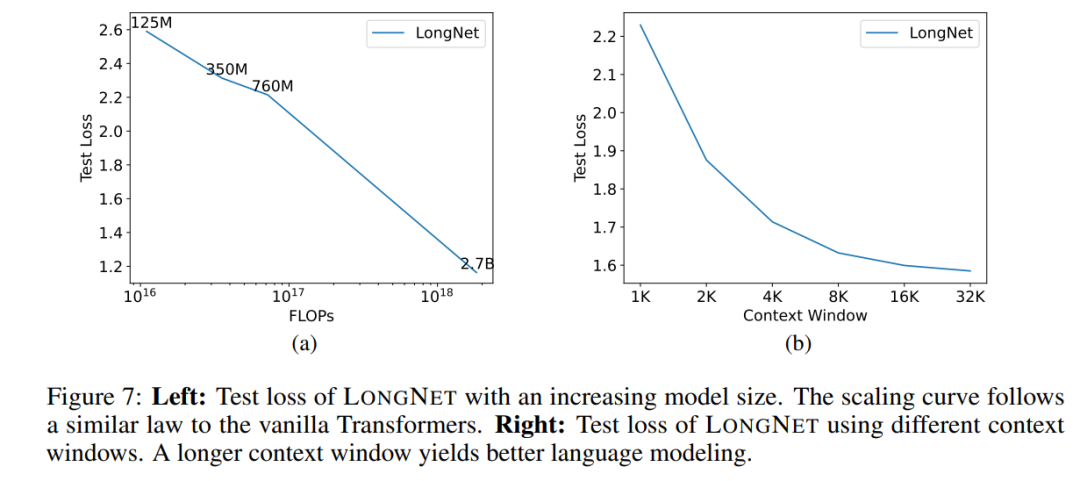
Lange Kontext-Eingabeaufforderung
Eingabeaufforderung ist eine wichtige Möglichkeit, das Sprachmodell zu führen und mit zusätzlichen Informationen zu versorgen. Diese Studie validiert experimentell, ob LONGNET von längeren Kontexthinweisfenstern profitieren kann.
Diese Studie behielt ein Präfix (Präfixe) als Aufforderung bei und testete die Verwirrung seiner Suffixe (Suffixe). Darüber hinaus wurde die Eingabeaufforderung während des Forschungsprozesses schrittweise von 2K auf 32K erweitert. Um einen fairen Vergleich zu ermöglichen, wird die Länge des Suffixes konstant gehalten, während die Länge des Präfixes auf die maximale Länge des Modells erhöht wird. Abbildung 7(b) zeigt die Ergebnisse des Testsatzes. Es zeigt, dass der Testverlust von LONGNET mit zunehmendem Kontextfenster allmählich abnimmt. Dies beweist die Überlegenheit von LONGNET bei der vollständigen Nutzung langer Kontexte zur Verbesserung von Sprachmodellen.
Das obige ist der detaillierte Inhalt vonMicrosofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

![So zeigen Sie die Internetgeschwindigkeit in der Taskleiste an [Einfache Schritte]](https://img.php.cn/upload/article/000/465/014/169088173253603.png?x-oss-process=image/resize,m_fill,h_207,w_330) So zeigen Sie die Internetgeschwindigkeit in der Taskleiste an [Einfache Schritte]
Aug 01, 2023 pm 05:22 PM
So zeigen Sie die Internetgeschwindigkeit in der Taskleiste an [Einfache Schritte]
Aug 01, 2023 pm 05:22 PM
Die Internetgeschwindigkeit ist ein wichtiger Parameter für das Ergebnis Ihres Online-Erlebnisses. Egal, ob Sie Dateien herunterladen oder hochladen oder einfach nur im Internet surfen, wir alle brauchen eine gute Internetverbindung. Aus diesem Grund suchen Benutzer nach Möglichkeiten, die Internetgeschwindigkeit in der Taskleiste anzuzeigen. Durch die Anzeige der Netzwerkgeschwindigkeit in der Taskleiste können Benutzer die Dinge schnell überwachen, unabhängig von der anstehenden Aufgabe. Die Taskleiste ist immer sichtbar, es sei denn, Sie befinden sich im Vollbildmodus. Allerdings bietet Windows keine native Option zur Anzeige der Internetgeschwindigkeit in der Taskleiste. Deshalb benötigen Sie Tools von Drittanbietern. Lesen Sie weiter, um alles über die besten Optionen zu erfahren! Wie führe ich einen Geschwindigkeitstest über die Windows-Befehlszeile aus? Drücken Sie +, um Ausführen zu öffnen, geben Sie Power Shell ein und drücken Sie ++. Fenster
 Fix: Netzwerkverbindungsproblem, das den Zugriff auf das Internet im abgesicherten Modus von Windows 11 verhindert
Sep 23, 2023 pm 01:13 PM
Fix: Netzwerkverbindungsproblem, das den Zugriff auf das Internet im abgesicherten Modus von Windows 11 verhindert
Sep 23, 2023 pm 01:13 PM
Im abgesicherten Modus mit Netzwerkbetrieb keine Internetverbindung auf Ihrem Windows 11-Computer zu haben, kann frustrierend sein, insbesondere bei der Diagnose und Behebung von Systemproblemen. In diesem Leitfaden besprechen wir die möglichen Ursachen des Problems und listen wirksame Lösungen auf, um sicherzustellen, dass Sie im abgesicherten Modus auf das Internet zugreifen können. Warum gibt es im abgesicherten Modus mit Netzwerk kein Internet? Der Netzwerkadapter ist inkompatibel oder wird nicht richtig geladen. Firewalls, Sicherheitssoftware oder Antivirensoftware von Drittanbietern können Netzwerkverbindungen im abgesicherten Modus stören. Der Netzwerkdienst wird nicht ausgeführt. Malware-Infektion Was soll ich tun, wenn das Internet im abgesicherten Modus unter Windows 11 nicht genutzt werden kann? Bevor Sie erweiterte Fehlerbehebungsschritte durchführen, sollten Sie die folgenden Prüfungen in Betracht ziehen: Stellen Sie sicher, dass Sie Folgendes verwenden
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 ICCV'23-Papierpreis „Fighting of Gods'! Meta Divide Everything und ControlNet wurden gemeinsam ausgewählt, und es gab einen weiteren Artikel, der die Jury überraschte
Oct 04, 2023 pm 08:37 PM
ICCV'23-Papierpreis „Fighting of Gods'! Meta Divide Everything und ControlNet wurden gemeinsam ausgewählt, und es gab einen weiteren Artikel, der die Jury überraschte
Oct 04, 2023 pm 08:37 PM
ICCV2023, die Top-Computer-Vision-Konferenz in Paris, Frankreich, ist gerade zu Ende gegangen! Der diesjährige Preis für das beste Papier ist einfach ein „Kampf zwischen Göttern“. Zu den beiden Arbeiten, die den Best Paper Award gewannen, gehörte beispielsweise ControlNet, eine Arbeit, die das Gebiet der vinzentinischen Graphen-KI untergrub. Seitdem ControlNet als Open-Source-Lösung verfügbar ist, hat es auf GitHub 24.000 Sterne erhalten. Ob es sich um Diffusionsmodelle oder den gesamten Bereich der Computer Vision handelt, die Auszeichnung für dieses Papier ist wohlverdient. Die lobende Erwähnung für die beste Arbeit ging an eine andere ebenso berühmte Arbeit, Metas „Separate Everything“ „Model SAM“. Seit seiner Einführung ist „Segment Everything“ zum „Benchmark“ für verschiedene Bildsegmentierungs-KI-Modelle geworden, auch für solche, die von hinten kamen.
 NeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!
Nov 14, 2023 pm 03:09 PM
NeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!
Nov 14, 2023 pm 03:09 PM
Seit Neural Radiance Fields im Jahr 2020 vorgeschlagen wurde, hat die Zahl verwandter Arbeiten exponentiell zugenommen. Es hat sich nicht nur zu einem wichtigen Zweig der dreidimensionalen Rekonstruktion entwickelt, sondern ist auch allmählich an der Forschungsgrenze als wichtiges Werkzeug für autonomes Fahren aktiv geworden . NeRF ist in den letzten zwei Jahren plötzlich aufgetaucht, hauptsächlich weil es die Merkmalspunktextraktion und -anpassung, die epipolare Geometrie und Triangulation, PnP plus Bündelanpassung und andere Schritte der traditionellen CV-Rekonstruktionspipeline und sogar die Netzrekonstruktion, Kartierung und Lichtverfolgung überspringt , direkt aus 2D Das Eingabebild wird verwendet, um ein Strahlungsfeld zu lernen, und dann wird aus dem Strahlungsfeld ein gerendertes Bild ausgegeben, das einem echten Foto nahekommt. Mit anderen Worten: Lassen Sie ein implizites dreidimensionales Modell, das auf einem neuronalen Netzwerk basiert, zur angegebenen Perspektive passen
 Auch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.
Jun 27, 2023 pm 05:46 PM
Auch Papierillustrationen können mithilfe des Diffusionsmodells automatisch generiert werden und werden auch vom ICLR akzeptiert.
Jun 27, 2023 pm 05:46 PM
Generative KI hat die Community der künstlichen Intelligenz im Sturm erobert. Sowohl Einzelpersonen als auch Unternehmen sind daran interessiert, entsprechende modale Konvertierungsanwendungen wie Vincent-Bilder, Vincent-Videos, Vincent-Musik usw. zu erstellen. In jüngster Zeit haben mehrere Forscher von wissenschaftlichen Forschungseinrichtungen wie ServiceNow Research und LIVIA versucht, Diagramme in Aufsätzen basierend auf Textbeschreibungen zu erstellen. Zu diesem Zweck schlugen sie eine neue Methode von FigGen vor, und das entsprechende Papier wurde auch als TinyPaper in ICLR2023 aufgenommen. Adresse des Bildpapiers: https://arxiv.org/pdf/2306.00800.pdf Manche Leute fragen sich vielleicht: Was ist so schwierig daran, die Diagramme im Papier zu erstellen? Wie hilft dies der wissenschaftlichen Forschung?
 Chat-Screenshots enthüllen versteckte Regeln für KI-Rezensenten! AAAI 3000 Yuan ist stark zu akzeptieren?
Apr 12, 2023 am 08:34 AM
Chat-Screenshots enthüllen versteckte Regeln für KI-Rezensenten! AAAI 3000 Yuan ist stark zu akzeptieren?
Apr 12, 2023 am 08:34 AM
Gerade als die Einreichungsfrist für AAAI 2023-Papiere näher rückte, erschien plötzlich ein Screenshot eines anonymen Chats in der AI-Einreichungsgruppe auf Zhihu. Einer von ihnen behauptete, er könne „3.000 Yuan pro starkem Akzept“ anbieten. Sobald die Nachricht bekannt wurde, erregte sie sofort öffentliche Empörung unter den Internetnutzern. Aber beeilen Sie sich noch nicht. Zhihu-Chef „Fine Tuning“ sagte, dass dies höchstwahrscheinlich nur ein „verbales Vergnügen“ sei. Laut „Fine Tuning“ sind Begrüßungen und Bandenkriminalität in jedem Bereich unvermeidbare Probleme. Mit dem Aufkommen von OpenReview werden die verschiedenen Nachteile von cmt immer deutlicher. Der Spielraum für kleine Kreise wird in Zukunft kleiner, aber es wird immer Platz geben. Denn es handelt sich um ein persönliches Problem und nicht um ein Problem mit dem Einreichungssystem und -mechanismus. Wir stellen Open R vor
 CVPR-Rangliste 2023 veröffentlicht, die Akzeptanzrate beträgt 25,78 %! 2.360 Beiträge wurden angenommen und die Zahl der Einreichungen stieg auf 9.155
Apr 13, 2023 am 09:37 AM
CVPR-Rangliste 2023 veröffentlicht, die Akzeptanzrate beträgt 25,78 %! 2.360 Beiträge wurden angenommen und die Zahl der Einreichungen stieg auf 9.155
Apr 13, 2023 am 09:37 AM
Gerade hat CVPR 2023 eine Erklärung herausgegeben, in der es heißt: In diesem Jahr haben wir eine Rekordzahl von 9.155 Beiträgen erhalten (ein Anstieg von 12 % gegenüber CVPR 2022) und 2.360 Beiträge angenommen, was einer Annahmequote von 25,78 % entspricht. Laut Statistik stieg die Zahl der Einreichungen beim CVPR in den sieben Jahren von 2010 bis 2016 lediglich von 1.724 auf 2.145. Nach 2017 stieg sie rasant an und trat in eine Phase rasanten Wachstums ein. Im Jahr 2019 überstieg sie erstmals die 5.000-Marke, und bis 2022 lag die Zahl der Einreichungen bei 8.161. Wie Sie sehen, wurden in diesem Jahr insgesamt 9.155 Beiträge eingereicht, was einen Rekord darstellt. Nachdem sich die Epidemie abgeschwächt hat, wird der diesjährige CVPR-Gipfel in Kanada stattfinden. In diesem Jahr wird das Format einer eingleisigen Konferenz übernommen und die traditionelle mündliche Auswahl entfällt. Google-Recherche
