
 Backend-Entwicklung
Python-Tutorial
Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit dem Python-Webcrawler Anweisungen zur Ausrüstung von King of Glory-Helden erhalten und automatisch Markdown-Dateien generieren
Backend-Entwicklung
Python-Tutorial
Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit dem Python-Webcrawler Anweisungen zur Ausrüstung von King of Glory-Helden erhalten und automatisch Markdown-Dateien generieren
Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit dem Python-Webcrawler Anweisungen zur Ausrüstung von King of Glory-Helden erhalten und automatisch Markdown-Dateien generieren
1. Einführung
Freunde, die das Spiel „Honor of Kings“ gespielt haben, wissen alle, dass eine angemessene Ausrüstung, gepaart mit Inschriften, Sie unaufhaltsam machen kann unaufhaltsam auf dem Schlachtfeld der Könige!
Vor ein paar Tagen habe ich in der [Minglao]-Gruppe gesehen, dass er einen Python-Webcrawler geteilt hat, um die Ausrüstungsanweisungen des Helden „Honor of Kings“ zu erhalten, und den Thread-Pool verwendet hat, um die Ausrüstungsbilder herunterzuladen und dann automatisch einen Markdown zu generieren Es gibt viele nützliche Inhalte, die ich hier mit Ihnen teilen kann. Jeder ist herzlich eingeladen, ihn auszuprobieren.
2. Datenerfassung
Unsere Zielwebsite hier ist die offizielle Website von King of Glory, wie im Bild unten gezeigt. 
Klicken Sie dann auf die Schaltfläche [Mehr] von [Helden/Skins] auf der rechten Seite der Startseite, um die Detailseite aufzurufen, wie im Bild unten gezeigt. Klicken Sie auf [In-Game-Gegenstände], um die Ausrüstungsinformationen anzuzeigen Beinhaltet das Abrufen der gewünschten Zielinformationen. 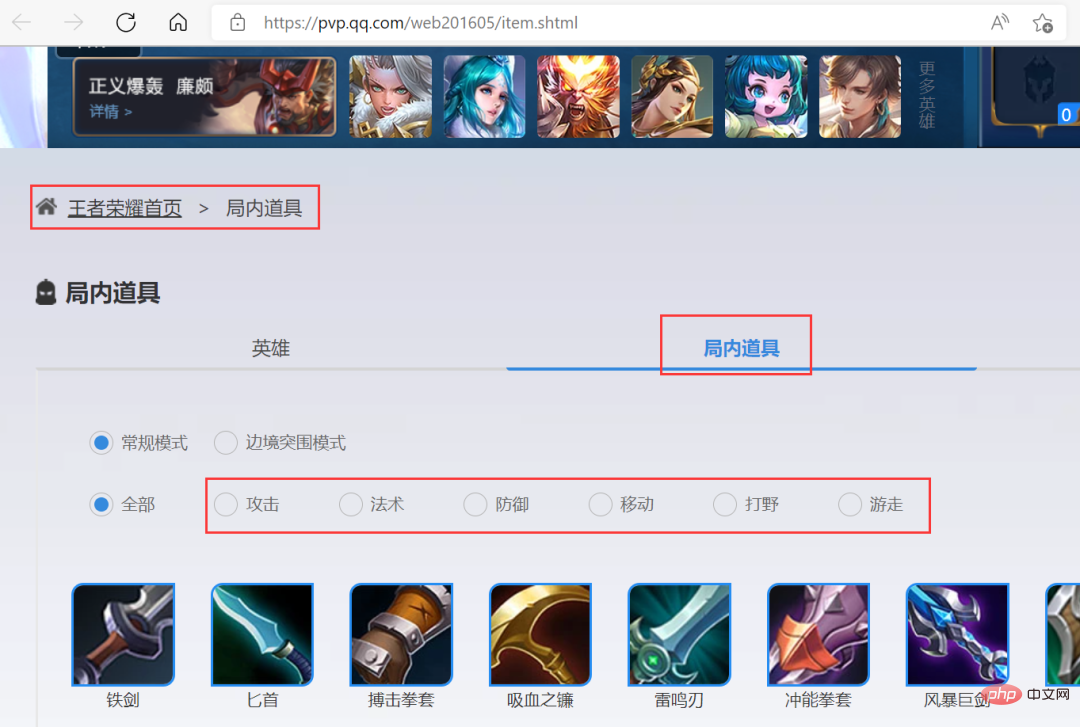
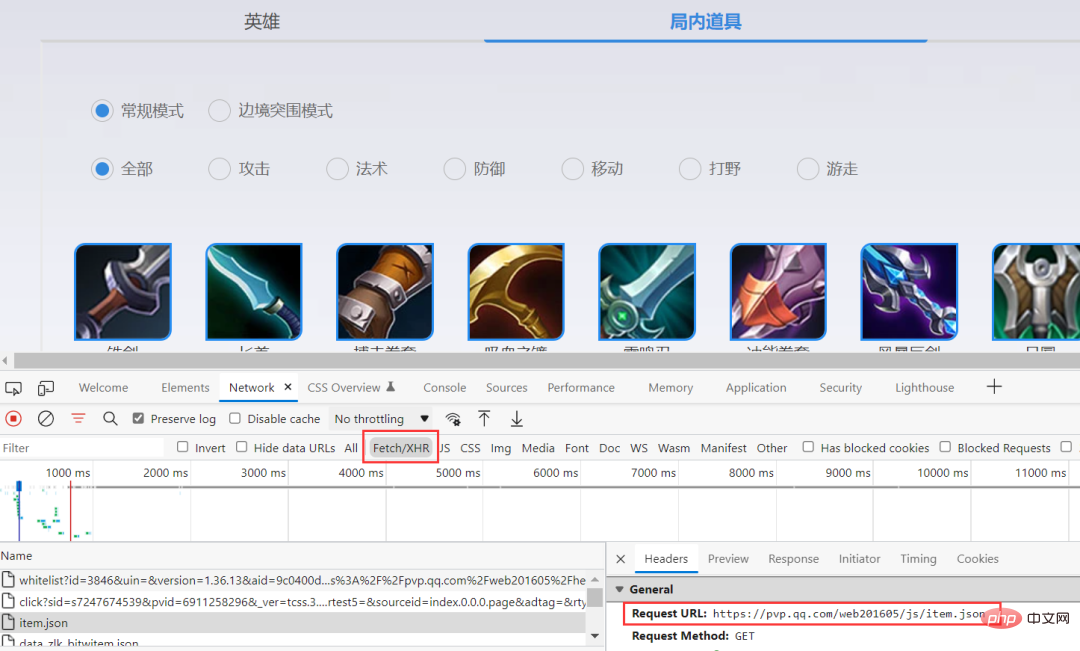
Durch die Erfassung von Paketen über den Browser können Sie spezifische Informationen abrufen und diese im json-Format gespeichert sehen.
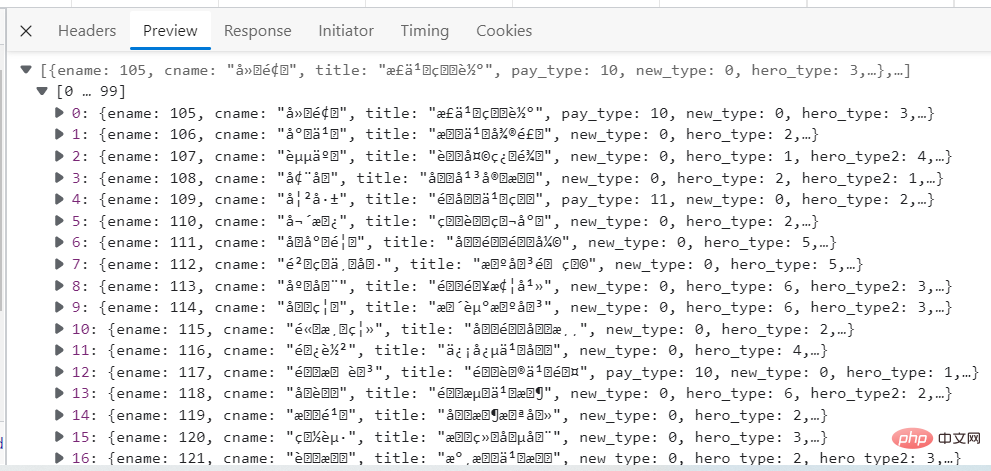
 Das Bild unten ist ein Screenshot der Datendetails. Sie können sehen, dass es chinesische verstümmelte Zeichen gibt. Dies hat zumindest keinen Einfluss auf die Daten.
Das Bild unten ist ein Screenshot der Datendetails. Sie können sehen, dass es chinesische verstümmelte Zeichen gibt. Dies hat zumindest keinen Einfluss auf die Daten.
Code-Implementierungsprozess
Nachdem wir die Datenquelle gefunden haben, besteht der nächste Schritt darin, den Code direkt anzuwenden und in jupyter notebook auszuführen.
Gerätedaten abrufen
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.104 Safari/537.36 '
}
target = 'https://pvp.qq.com/web201605/js/item.json'
item_list = requests.get(target, headers=headers).json()
item_df = pd.DataFrame(item_list)
item_df.sort_values(["item_type", "price", "item_id"], inplace=True)
item_df.fillna("", inplace=True)
item_df.des1 = item_df.des1.str.replace("</?p>", "", regex=True)
item_df.des2 = item_df.des2.str.replace("</?p>", "", regex=True)
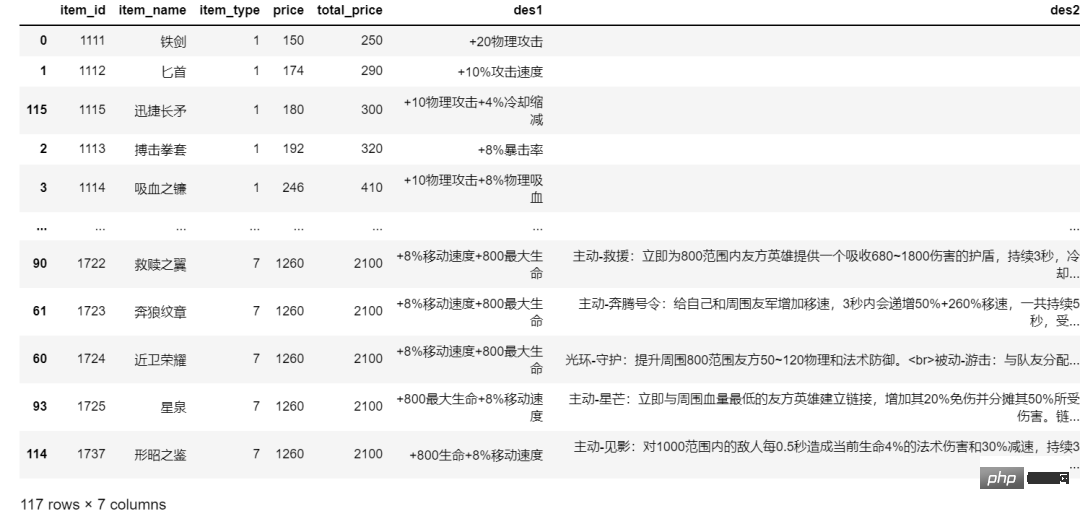
item_dfDas Ergebnis ist wie in der folgenden Abbildung dargestellt:
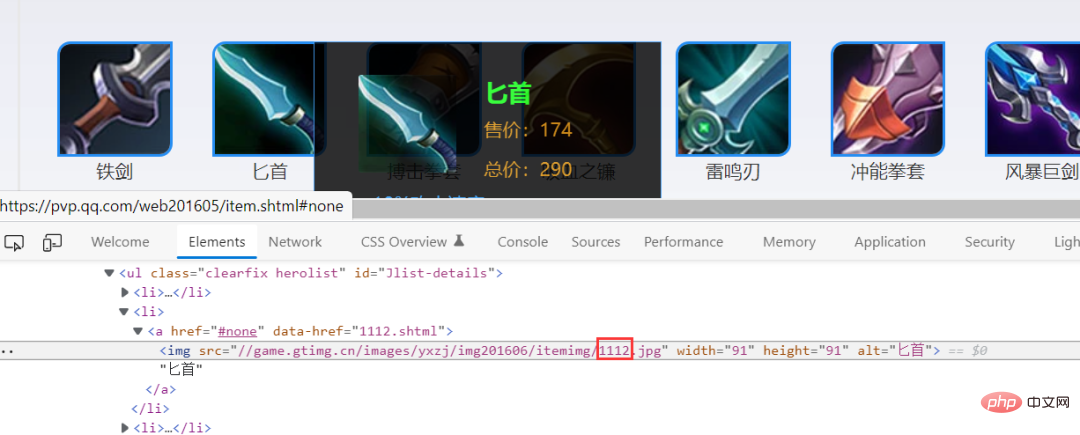
Multi-Thread-Download von Bildern
Als nächstes verwenden Sie die Thread-Pool-Methode, um Bilder herunterzuladen Das Zusammenfügen von Bildern ist ebenfalls sehr einfach, was auf den ersten Blick deutlich wird, wenn man sich das Bild unten ansieht.
 Das Folgende ist die Code-Implementierung:
Das Folgende ist die Code-Implementierung:
import os
from concurrent.futures import ThreadPoolExecutor
def download_img(item_id):
if os.path.exists(f"imgs/{item_id}.jpg"):
return
imgurl = f"http://game.gtimg.cn/images/yxzj/img201606/itemimg/{item_id}.jpg"
res = requests.get(imgurl)
with open(f"imgs/{item_id}.jpg", "wb") as f:
f.write(res.content)
os.makedirs("imgs", exist_ok=True)
with ThreadPoolExecutor(max_workers=8) as executor:
nums = executor.map(download_img, item_df.item_id)Die Download-Geschwindigkeit ist sehr schnell, nur wenige Sekunden, und das Ergebnis ist wie in der Abbildung unten dargestellt:
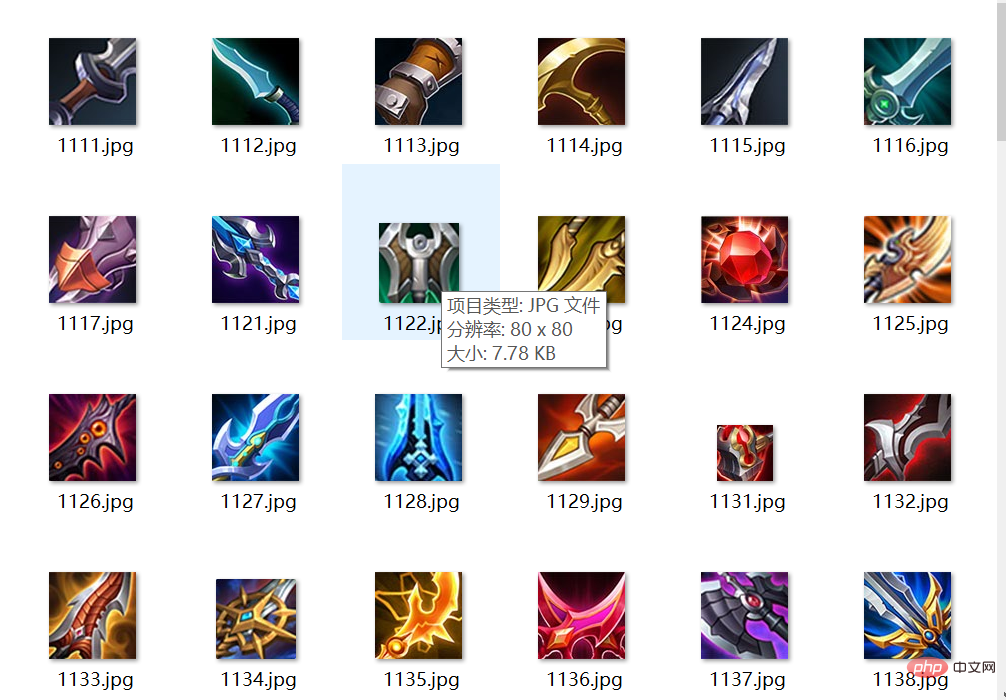
Als nächstes generieren wir automatisch das Markdown-Dokument Werfen wir anhand der Daten einen Blick darauf.
Markdown-Dokument generieren
Der erste Teil ist die Vorverarbeitung der Daten, gefolgt vom Schreiben der Datei:
item_type_dict = {1: '攻击', 2: '法术', 3: '防御', 4: '移动', 5: '打野', 7: '游走'}
item_ids = item_df.item_id.values
item_df.item_id = item_df.item_id.apply(
lambda item_id: f"")
item_df.item_type = item_df.item_type.map(item_type_dict)
item_df.columns = ["图片", "装备名称", "类型", "售价", "总价", "基础描述", "扩展描述"]
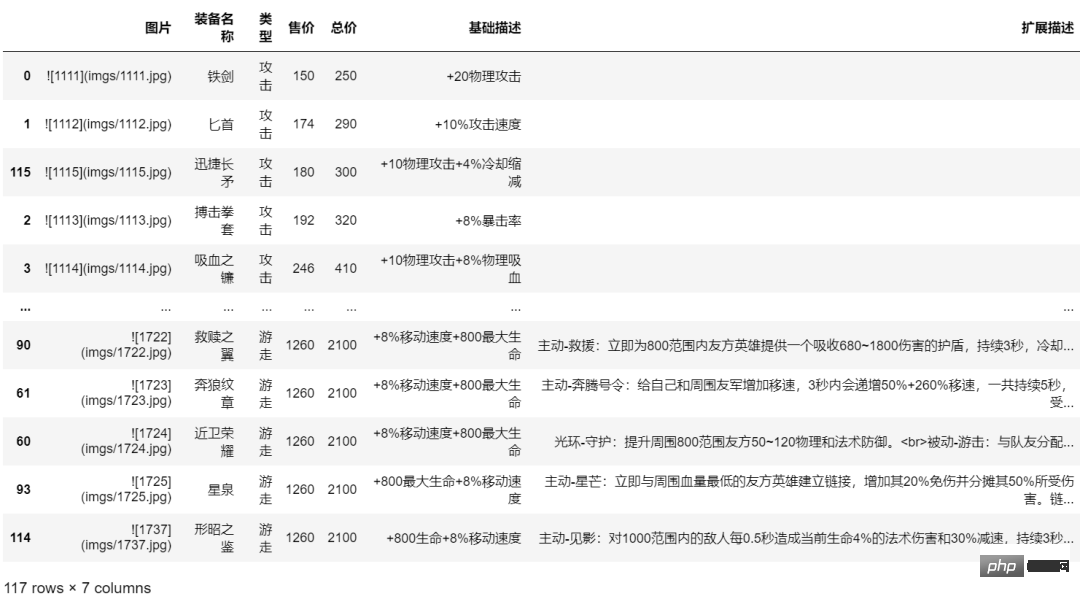
item_dfDer Code zum Schreiben der Datei und zum Generieren des Markdown-Dokuments:
with open("王者装备说明.md", "w") as f:
for item_type, item_split in item_df.groupby("类型", sort=False):
f.write(f"# {item_type}\n")
item_split.drop(columns="类型", inplace=True)
f.write(item_split.to_markdown(index=False))
f.write("\n\n")Das Ergebnis ist wie folgt:
Danach wird lokal ein Markdown-Dokument mit dem Namen [King Equipment Description.md] erstellt. Doppelklicken Sie auf die Datei, um sie zu öffnen:
 Was ein toller Kerl! Als ich diesen Schritt implementiert habe, ist ein Fehler aufgetreten, wie unten gezeigt:
Was ein toller Kerl! Als ich diesen Schritt implementiert habe, ist ein Fehler aufgetreten, wie unten gezeigt:
Missing optional dependency 'tabulate'. Use pip or conda to install tabulate.
提示却少依赖库,只需要在cmd下进行安装即可pip install tabulate,之后就可以正常运行了。
生成Excel表格
不过Markdown的表格无法任意调整,图片需要点击后才会放大,下面我们考虑生成Excel表格:首先需要整理数据,代码如下:
item_df.图片 = ""
item_df.基础描述 = item_df.基础描述.str.replace("<br>", "\n")
item_df.扩展描述 = item_df.扩展描述.str.replace("<br>", "\n")
item_df生成结果如下图所示:
 之后将结果写入到
之后将结果写入到Excel中去,代码如下所示:
# 写入Excel表格
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
with pd.ExcelWriter("王者装备说明.xlsx", engine='openpyxl') as writer:
item_df.to_excel(writer, sheet_name='装备说明', index=False)
worksheet = writer.sheets['装备说明']
worksheet.column_dimensions["A"].width = 11
for item_id, (cell,) in zip(item_ids, worksheet.iter_rows(2, None, 1, 1)):
worksheet.row_dimensions[cell.row].height = 67
worksheet.add_image(Image(f"imgs/{item_id}.jpg"), f'A{cell.row}')
worksheet.column_dimensions["F"].width = 15
worksheet.column_dimensions["G"].width = 35
writer.save()打开文件,效果图如下图所示:

当然了,大家也可以根据自己想要的效果生成HTML和Word等等。
三、总结
大家好,我是Python进阶者。这篇文章主要分享了一个使用Python网络爬虫获取王者荣耀英雄出装说明,并使用线程池的方式下载了出装图片,之后还自动化生成了markdown文件,干货内容很多,欢迎大家积极尝试,如果有遇到问题,请添加我好友,我帮助解决。
最后感谢粉丝【明佬】分享的代码喝王者荣耀出装攻略,真是太强了,上王者指日可待!
最后放上【明佬】的csdn链接:https://xxmdmst.blog.csdn.net/article/details/124035041,点击阅读原文可以直达噢!
Das obige ist der detaillierte Inhalt vonBringen Sie Ihnen Schritt für Schritt bei, wie Sie mit dem Python-Webcrawler Anweisungen zur Ausrüstung von King of Glory-Helden erhalten und automatisch Markdown-Dateien generieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python haben jeweils ihre eigenen Vorteile und wählen nach den Projektanforderungen. 1.PHP ist für die Webentwicklung geeignet, insbesondere für die schnelle Entwicklung und Wartung von Websites. 2. Python eignet sich für Datenwissenschaft, maschinelles Lernen und künstliche Intelligenz mit prägnanter Syntax und für Anfänger.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Das Konfigurieren eines HTTPS -Servers auf einem Debian -System umfasst mehrere Schritte, einschließlich der Installation der erforderlichen Software, der Generierung eines SSL -Zertifikats und der Konfiguration eines Webservers (z. B. Apache oder NGINX) für die Verwendung eines SSL -Zertifikats. Hier ist eine grundlegende Anleitung unter der Annahme, dass Sie einen Apacheweb -Server verwenden. 1. Installieren Sie zuerst die erforderliche Software, stellen Sie sicher, dass Ihr System auf dem neuesten Stand ist, und installieren Sie Apache und OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Die Entwicklung eines Gitlab -Plugins für Debian erfordert einige spezifische Schritte und Kenntnisse. Hier ist ein grundlegender Leitfaden, mit dem Sie mit diesem Prozess beginnen können. Wenn Sie zuerst GitLab installieren, müssen Sie GitLab in Ihrem Debian -System installieren. Sie können sich auf das offizielle Installationshandbuch von GitLab beziehen. Holen Sie sich API Access Token, bevor Sie die API -Integration durchführen. Öffnen Sie das GitLab -Dashboard, finden Sie die Option "AccessTokens" in den Benutzereinstellungen und generieren Sie ein neues Zugriffs -Token. Wird generiert
 Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Apache ist der Held hinter dem Internet. Es ist nicht nur ein Webserver, sondern auch eine leistungsstarke Plattform, die enormen Datenverkehr unterstützt und dynamische Inhalte bietet. Es bietet eine extrem hohe Flexibilität durch ein modulares Design und ermöglicht die Ausdehnung verschiedener Funktionen nach Bedarf. Modularität stellt jedoch auch Konfigurations- und Leistungsherausforderungen vor, die ein sorgfältiges Management erfordern. Apache eignet sich für Serverszenarien, die hoch anpassbare und entsprechende komplexe Anforderungen erfordern.
 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 In welcher Sprache wird Apache geschrieben?
Apr 13, 2025 pm 12:42 PM
In welcher Sprache wird Apache geschrieben?
Apr 13, 2025 pm 12:42 PM
Apache ist in C geschrieben. Die Sprache bietet Geschwindigkeit, Stabilität, Portabilität und direkten Zugriff auf Hardware, wodurch es für die Entwicklung von Webserver ideal ist.
