
 Backend-Entwicklung
Python-Tutorial
Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit Flask eine ES-Suchmaschine erstellen (vorbereitender Teil)
Backend-Entwicklung
Python-Tutorial
Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit Flask eine ES-Suchmaschine erstellen (vorbereitender Teil)
Bringen Sie Ihnen Schritt für Schritt bei, wie Sie mit Flask eine ES-Suchmaschine erstellen (vorbereitender Teil)
/1 Vorwort/
Elasticsearch ist eine Open-Source-Suchmaschine, die auf einer Volltextsuchmaschinenbibliothek aufbaut Apache Lucene™ Basierend auf den Grundlagen.

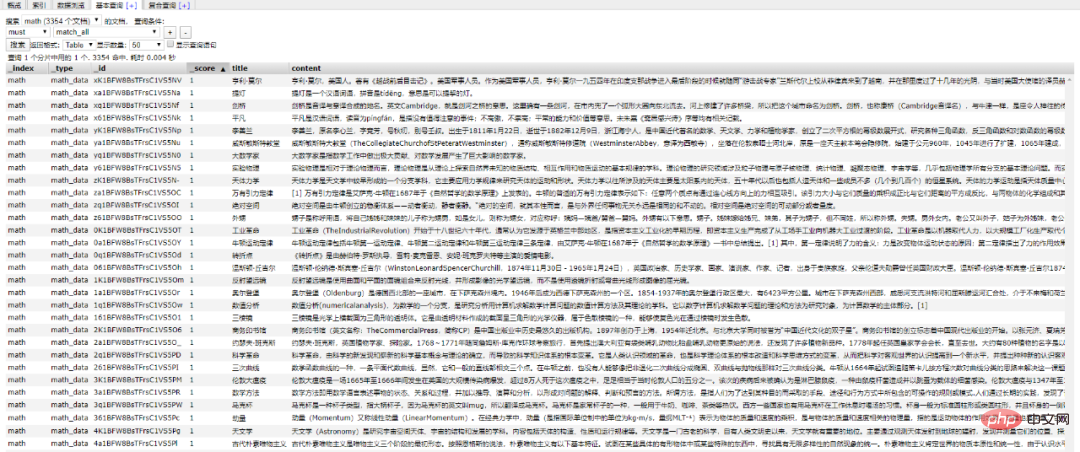
Elasticsearch und. Pyth am Das Andocken von ist für uns zu einem Problem geworden (warum haben wir das? um alles zu verbinden? Python bezogen). /2 Python-Interaktion/ Also, Python Es stellt außerdem Abhängigkeitsbibliotheken bereit, die mit Elasticsearch verbunden werden können . Initialisieren Sie eine Verbindung zu einem Elasticsearch Operationsobjekt. Der Standardport ist 9200 Bitte stellen Sie vor der Initialisierung sicher, dass die lokale Umgebung von Elasticsearch eingerichtet wurde. Dokumentdaten basierend auf der ID abrufen 插入文档数据 搜索文档数据 删除文档数据 好啊,封装 search 类也是为了方便调用,整体贴一下。 尝试一下把 Mongodb 中的数据插入到 ES 中。 到 ES 中查看一下,启动 elasticsearch-head 插件。 如果是 npm 安装的那么 cd 到根目录之后直接 npm run start 就跑起来了。 本地访问 http://localhost:9100/ 发现新加的 spider 数据文档确实已经进去了。 /3 爬虫入库/ 要想实现 ES 搜索,首先要有数据支持,而海量的数据往往来自爬虫。 为了节省时间,编写一个最简单的爬虫,抓取 百度百科。 简单粗暴一点,先 递归获取 很多很多的 url 链接 把全部 url 存到 url.txt 文件中之后,然后启动任务。 run.py 飞起来 黑窗口键入 哦豁 !! 你居然使用了 Celery 任务队列,gevent 模式,-c 就是10个线程刷刷刷就干起来了,速度杠杠的 !! 啥?分布式? 那就加多几台机器啦,直接把代码拷贝到目标服务器,通过 redis 共享队列协同多机抓取。 这里是先将数据存储到了 MongoDB 上(个人习惯),你也可以直接存到 ES 中,但是单条单条的插入速度堪忧(接下来会讲到优化,哈哈)。 使用前面的例子将 Mongo 中的数据批量导入到 ES 中,OK !!! 到这一个简单的数据抓取就已经完毕了。 好啦,现在 ES 中已经有了数据啦,接下来就应该是 Flask web 的操作啦,当然,Django,FastAPI 也很优秀。嘿嘿,你喜欢 !! 关于FastAPI 的文章可以看这个系列文章: 1、(入门篇)简析Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 2、(进阶篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 3、(完结篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架 /4 Flask 项目结构/ 这样一来前期工作就差不多了,接下来剩下的工作主要集中于 Flask 的实际开发中,蓄力中 !!pip install elasticsearch
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('username', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_namedef get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_data
def __search(self, query: dict, count: int = 20): # count: 返回的数据大小
results = []
params = {
'size': count
}
match_data = self.es.search(index=self.index_name, body=query, params=params)
for hit in match_data['hits']['hits']:
results.append(hit['_source'])
return resultsdef delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
passfrom elasticsearch import Elasticsearch
class elasticSearch():
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('elastic', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_name
def create_index(self):
if self.es.indices.exists(index=self.index_name) is True:
self.es.indices.delete(index=self.index_name)
self.es.indices.create(index=self.index_name, ignore=400)
def delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
pass
def get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)
def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_dataimport json
from datetime import datetime
import pymongo
from app.elasticsearchClass import elasticSearch
client = pymongo.MongoClient('127.0.0.1', 27017)
db = client['spider']
sheet = db.get_collection('Spider').find({}, {'_id': 0, })
es = elasticSearch(index_type="spider_data",index_name="spider")
es.create_index()
for i in sheet:
data = {
'title': i["title"],
'content':i["data"],
'link': i["link"],
'create_time':datetime.now()
}
es.insert_one(doc=data)
import requests
import re
import time
exist_urls = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
}
def get_link(url):
try:
response = requests.get(url=url, headers=headers)
response.encoding = 'UTF-8'
html = response.text
link_lists = re.findall('.*?<a target=_blank href="/item/([^:#=<>]*?)".*?</a>', html)
return link_lists
except Exception as e:
pass
finally:
exist_urls.append(url)
# 当爬取深度小于10层时,递归调用主函数,继续爬取第二层的所有链接
def main(start_url, depth=1):
link_lists = get_link(start_url)
if link_lists:
unique_lists = list(set(link_lists) - set(exist_urls))
for unique_url in unique_lists:
unique_url = 'https://baike.baidu.com/item/' + unique_url
with open('url.txt', 'a+') as f:
f.write(unique_url + '\n')
f.close()
if depth < 10:
main(unique_url, depth + 1)
if __name__ == '__main__':
start_url = 'https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E7%99%BE%E7%A7%91'
main(start_url)# parse.py
from celery import Celery
import requests
from lxml import etree
import pymongo
app = Celery('tasks', broker='redis://localhost:6379/2')
client = pymongo.MongoClient('localhost',27017)
db = client['baike']
@app.task
def get_url(link):
item = {}
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'}
res = requests.get(link,headers=headers)
res.encoding = 'UTF-8'
doc = etree.HTML(res.text)
content = doc.xpath("//div[@class='lemma-summary']/div[@class='para']//text()")
print(res.status_code)
print(link,'\t','++++++++++++++++++++')
item['link'] = link
data = ''.join(content).replace(' ', '').replace('\t', '').replace('\n', '').replace('\r', '')
item['data'] = data
if db['Baike'].insert(dict(item)):
print("is OK ...")
else:
print('Fail')from parse import get_url
def main(url):
result = get_url.delay(url)
return result
def run():
with open('./url.txt', 'r') as f:
for url in f.readlines():
main(url.strip('\n'))
if __name__ == '__main__':
run()celery -A parse worker -l info -P gevent -c 10

Das obige ist der detaillierte Inhalt vonBringen Sie Ihnen Schritt für Schritt bei, wie Sie mit Flask eine ES-Suchmaschine erstellen (vorbereitender Teil). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 So erstellen Sie einfache und benutzerfreundliche Webanwendungen mit React und Flask
Sep 27, 2023 am 11:09 AM
So erstellen Sie einfache und benutzerfreundliche Webanwendungen mit React und Flask
Sep 27, 2023 am 11:09 AM
So erstellen Sie mit React und Flask einfache und benutzerfreundliche Webanwendungen. Einführung: Mit der Entwicklung des Internets werden die Anforderungen an Webanwendungen immer vielfältiger und komplexer. Um den Anforderungen der Benutzer an Benutzerfreundlichkeit und Leistung gerecht zu werden, wird es immer wichtiger, moderne Technologie-Stacks zum Aufbau von Netzwerkanwendungen zu verwenden. React und Flask sind zwei sehr beliebte Frameworks für die Front-End- und Back-End-Entwicklung, und sie arbeiten gut zusammen, um einfache und benutzerfreundliche Webanwendungen zu erstellen. In diesem Artikel erfahren Sie, wie Sie React und Flask nutzen
 Django vs. Flask: Eine vergleichende Analyse von Python-Web-Frameworks
Jan 19, 2024 am 08:36 AM
Django vs. Flask: Eine vergleichende Analyse von Python-Web-Frameworks
Jan 19, 2024 am 08:36 AM
Django und Flask sind beide führend bei Python-Web-Frameworks und haben beide ihre eigenen Vorteile und anwendbaren Szenarien. In diesem Artikel wird eine vergleichende Analyse dieser beiden Frameworks durchgeführt und spezifische Codebeispiele bereitgestellt. Entwicklungseinführung Django ist ein Web-Framework mit vollem Funktionsumfang, dessen Hauptzweck darin besteht, schnell komplexe Webanwendungen zu entwickeln. Django bietet viele integrierte Funktionen wie ORM (Object Relational Mapping), Formulare, Authentifizierung, Verwaltungs-Backend usw. Diese Funktionen ermöglichen es Django, große Mengen zu verarbeiten
 Beginnen Sie bei Null und führen Sie Schritt für Schritt durch die Installation von Flask und die schnelle Einrichtung eines persönlichen Blogs
Feb 19, 2024 pm 04:01 PM
Beginnen Sie bei Null und führen Sie Schritt für Schritt durch die Installation von Flask und die schnelle Einrichtung eines persönlichen Blogs
Feb 19, 2024 pm 04:01 PM
Von Grund auf werde ich Ihnen Schritt für Schritt beibringen, wie Sie Flask installieren und schnell einen persönlichen Blog erstellen. Als Person, die gerne schreibt, ist es sehr wichtig, einen persönlichen Blog zu haben. Als leichtes Python-Web-Framework kann Flask uns dabei helfen, schnell ein einfaches und voll funktionsfähiges persönliches Blog zu erstellen. In diesem Artikel fange ich bei Null an und zeige Ihnen Schritt für Schritt, wie Sie Flask installieren und schnell einen persönlichen Blog erstellen. Schritt 1: Python und pip installieren Bevor wir beginnen, müssen wir zuerst Python und pi installieren
 Anleitung zur Installation des Flask-Frameworks: Detaillierte Schritte, die Ihnen bei der korrekten Installation von Flask helfen
Feb 18, 2024 pm 10:51 PM
Anleitung zur Installation des Flask-Frameworks: Detaillierte Schritte, die Ihnen bei der korrekten Installation von Flask helfen
Feb 18, 2024 pm 10:51 PM
Tutorial zur Installation des Flask-Frameworks: Bringen Sie Ihnen Schritt für Schritt bei, wie Sie das Flask-Framework korrekt installieren. Einführung: Flask ist ein einfaches und flexibles Python-Webentwicklungs-Framework. Es ist leicht zu erlernen, benutzerfreundlich und voller leistungsstarker Funktionen. Dieser Artikel führt Sie Schritt für Schritt durch die korrekte Installation des Flask-Frameworks und stellt detaillierte Codebeispiele als Referenz bereit. Schritt 1: Python installieren Bevor Sie das Flask-Framework installieren, müssen Sie zunächst sicherstellen, dass Python auf Ihrem Computer installiert ist. Sie können bei P beginnen
 Integration von Flask und Intellij IDEA: Tipps zur Entwicklung von Python-Webanwendungen (Teil 2)
Jun 17, 2023 pm 01:58 PM
Integration von Flask und Intellij IDEA: Tipps zur Entwicklung von Python-Webanwendungen (Teil 2)
Jun 17, 2023 pm 01:58 PM
Im ersten Teil werden die grundlegende Flask- und Intellij IDEA-Integration, Projekt- und virtuelle Umgebungseinstellungen, Abhängigkeitsinstallation usw. vorgestellt. Als Nächstes werden wir weitere Tipps zur Entwicklung von Python-Webanwendungen untersuchen, um eine effizientere Arbeitsumgebung aufzubauen: Mit FlaskBlueprints können Sie Ihren Anwendungscode für eine einfachere Verwaltung und Wartung organisieren. Blueprint ist ein Python-Modul, das Pakete erstellt
 Flask vs. FastAPI: Die beste Wahl für eine effiziente Web-API-Entwicklung
Sep 27, 2023 pm 09:01 PM
Flask vs. FastAPI: Die beste Wahl für eine effiziente Web-API-Entwicklung
Sep 27, 2023 pm 09:01 PM
FlaskvsFastAPI: Die beste Wahl für eine effiziente Entwicklung von WebAPI Einführung: In der modernen Softwareentwicklung ist WebAPI zu einem unverzichtbaren Bestandteil geworden. Sie stellen Daten und Dienste bereit, die die Kommunikation und Interoperabilität zwischen verschiedenen Anwendungen ermöglichen. Bei der Auswahl eines Frameworks für die Entwicklung von WebAPI haben Flask und FastAPI große Aufmerksamkeit erregt. Beide Frameworks erfreuen sich großer Beliebtheit und jedes hat seine eigenen Vorteile. In diesem Artikel werden wir uns Fl ansehen
 Vergleich der Leistung von Gunicorn und uWSGI für die Bereitstellung von Flask-Anwendungen
Jan 17, 2024 am 08:52 AM
Vergleich der Leistung von Gunicorn und uWSGI für die Bereitstellung von Flask-Anwendungen
Jan 17, 2024 am 08:52 AM
Flask-Anwendungsbereitstellung: Vergleich von Gunicorn und suWSGI Einführung: Flask ist als leichtes Python-Web-Framework bei vielen Entwicklern beliebt. Bei der Bereitstellung einer Flask-Anwendung in einer Produktionsumgebung ist die Auswahl der geeigneten Server Gateway Interface (SGI) eine entscheidende Entscheidung. Gunicorn und uWSGI sind zwei gängige SGI-Server. In diesem Artikel werden sie ausführlich beschrieben.
 Flask-RESTful und Swagger: Best Practices zum Erstellen von RESTful-APIs in Python-Webanwendungen (Teil 2)
Jun 17, 2023 am 10:39 AM
Flask-RESTful und Swagger: Best Practices zum Erstellen von RESTful-APIs in Python-Webanwendungen (Teil 2)
Jun 17, 2023 am 10:39 AM
Flask-RESTful und Swagger: Best Practices zum Erstellen von RESTful-APIs in Python-Webanwendungen (Teil 2) Im vorherigen Artikel haben wir die Best Practices zum Erstellen von RESTful-APIs mit Flask-RESTful und Swagger untersucht. Wir stellten die Grundlagen des Flask-RESTful-Frameworks vor und zeigten, wie man mit Swagger Dokumentation für eine RESTful-API erstellt. Buch
