
 Datenbank
MySQL-Tutorial
Heute habe ich endlich die MySQL-Unterdatenbank und die Untertabellen herausgefunden, sodass ich im Interview damit prahlen kann!
Datenbank
MySQL-Tutorial
Heute habe ich endlich die MySQL-Unterdatenbank und die Untertabellen herausgefunden, sodass ich im Interview damit prahlen kann!
Heute habe ich endlich die MySQL-Unterdatenbank und die Untertabellen herausgefunden, sodass ich im Interview damit prahlen kann!
Vorwort
Das Unternehmen hat in letzter Zeit an der Diensttrennung und Datensegmentierung gearbeitet, da die Datenmenge in einer einzelnen Pakettabelle wirklich zu groß ist und immer noch um 60 W pro Tag wächst.
Ich habe bereits etwas über die Unterdatenbank und die Untertabellen der Datenbank gelernt und einige Blog-Beiträge gelesen, aber ich kenne nur ein vages Konzept, und jetzt, wo ich darüber nachdenke, ist alles vage.
Ich habe den ganzen Nachmittag damit verbracht, Datenbank-Untertabellen zu lesen und viele Artikel zu lesen:
Teil 1: Probleme im eigentlichen Website-Entwicklungsprozess.
Teil 2: Welche verschiedenen Arten der Segmentierung gibt es, welche Unterschiede und anwendbaren Aspekte gibt es zwischen vertikal und horizontal?
Teil 3: Einige Open-Source-Produkte und -Technologien, die derzeit auf dem Markt sind, und welche Vor- und Nachteile sie haben.
Teil 4: Das Wichtigste ist vielleicht, warum es nicht empfohlen wird, die Datenbank horizontal aufzuteilen! ? Dies ermöglicht Ihnen, bereits in der frühen Planungsphase sorgfältig damit umzugehen und Probleme durch Segmentierung zu vermeiden.
Begriffserklärung
Bibliothek: Datenbank; Unterdatenbank und Untertabelle: Sharding
Entwicklung der Datenbankarchitektur Am Anfang verwendeten wir nur eine Einzelmaschinendatenbank und standen dann vor der Herausforderung Wir trennen immer mehr Schreibvorgänge und Lesevorgänge der Datenbank, verwenden mehrere Slave-Datenbankkopien (Slaver-Replikation), um für das Lesen verantwortlich zu sein, und verwenden die Master-Datenbank (Master), um für das Schreiben verantwortlich zu sein Daten synchron aus der Masterdatenbank, um die Datenkonsistenz zu gewährleisten. Architektonisch handelt es sich um eine Datenbank-Master-Slave-Synchronisation. Die Slave-Bibliothek ist horizontal skalierbar, sodass mehr Leseanfragen kein Problem darstellen.
Aber was sollen wir tun, wenn die Anzahl der Benutzer steigt und die Schreibanfragen zunehmen? Das Hinzufügen eines Masters kann das Problem nicht lösen, da die Daten konsistent sein müssen und der Schreibvorgang eine Synchronisierung zwischen den beiden Mastern erfordert, was einer Duplizierung entspricht und komplizierter ist.
Zu diesem Zeitpunkt müssen Sie Sharding verwenden, um die Schreibvorgänge zu segmentieren.
Probleme vor dem Sharding von Datenbanken und Tabellen
Jedes Problem ist zu groß oder zu klein. Das Problem, mit dem wir hier konfrontiert sind, ist, dass die Datenmenge zu groß ist.
Das Volumen der Benutzeranfragen ist zu groß
Da einzelne Server-TPS, Speicher und IO begrenzt sind.
Lösung: Verteilen Sie Anfragen an mehrere Server. Tatsächlich sind Benutzeranfragen und die Ausführung einer SQL-Abfrage im Wesentlichen gleich, beide fordern eine Ressource an, aber Benutzeranfragen werden auch über Gateways, Routing, http-Server usw. geleitet.
Die einzelne Datenbank ist zu groß.
Die Verarbeitungskapazität einer einzelnen Datenbank ist begrenzt.
Unzureichender Speicherplatz auf dem Server, auf dem sich die einzelne Datenbank befindet Lösung: Aufteilen in mehrere kleinere Bibliotheken
Wenn eine einzelne Tabelle zu groß istIndexerweiterung, Abfrage-TimeoutCRUD ist ein Problem;
Lösung: Aufteilen in mehrere Tabellen mit kleineren Datensätzen.
Die Methode zum Sharding von Datenbanken und Tabellen
ist im Allgemeinen eine vertikale Segmentierung und eine horizontale Segmentierung. Dies ist eine Segmentierungsmethode, die durch die Ergebnismenge beschrieben wird, bei der es sich um eine physische Raumsegmentierung handelt. Wir gehen von den Problemen aus, mit denen wir konfrontiert sind, und lösen sie.
Erklärung:
Erstens ist die Anzahl der Benutzeranfragen zu groß, daher stapeln wir Maschinen, um sie zu bearbeiten (dies ist nicht der Schwerpunkt dieses Artikels).Dann ist die einzelne Bibliothek zu diesem Zeitpunkt zu groß um zu sehen, ob aufgrund zu vieler Tabellen zu viele Daten vorhanden sind oder ob die Tabelle viele Daten enthält.
Wenn zu viele Tabellen und zu viele Daten vorhanden sind, verwenden Sie die vertikale Segmentierung und teilen Sie sie je nach Unternehmen in verschiedene Bibliotheken auf.Wenn die Datenmenge in einer einzelnen Tabelle zu groß ist, sollte eine horizontale Segmentierung verwendet werden, dh die Tabellendaten werden nach bestimmten Regeln in mehrere Tabellen oder sogar in mehrere Tabellen in mehreren Bibliotheken unterteilt.
. Denn die vertikale Unterteilung ist einfacher und entspricht besser der Art und Weise, wie wir mit realen Problemen umgehen.Vertikale Aufteilung
Vertikale Tabellenaufteilung
ist auch „eine große Tabelle in eine kleine Tabelle aufteilen“, die auf Spaltenfeldern basiert. Im Allgemeinen enthält die Tabelle viele Felder, und diejenigen, die nicht häufig verwendet werden, große Datenmengen enthalten und lang sind (z. B. Felder vom Typ Text), werden in „erweiterte Tabellen“ aufgeteilt. Es richtet sich im Allgemeinen an große Tabellen mit Hunderten von Spalten und vermeidet außerdem das „seitenübergreifende“ Problem, das durch zu viele Daten beim Abfragen verursacht wird.
Vertikale Unterbibliothek
Die vertikale Unterbibliothek zielt darauf ab, verschiedene Unternehmen in einem System aufzuteilen, z. B. eine Datenbank für Benutzer, eine Datenbank für Produkte und eine Datenbank für Bestellungen. Nach der Aufteilung sollte es auf mehreren Servern statt auf einem Server platziert werden. Warum? Stellen wir uns vor, dass eine Shopping-Website Dienste für die Außenwelt bereitstellt und über CRUD für Benutzer, Produkte, Bestellungen usw. verfügt. Vor der Aufteilung fiel alles in eine einzige Bibliothek, wodurch die Datenbank
Die Verarbeitungsfähigkeit einer einzelnen Datenbank ist zu einem Engpass geworden. Wenn die Datenbank nach der vertikalen Aufteilung immer noch auf einem Datenbankserver platziert wird, wird die Verarbeitungskapazität einer einzelnen Datenbank mit zunehmender Anzahl von Benutzern zu einem Engpass undDer Speicherplatz, der Speicher, die TPS usw. eines einzelnen Servers sind sehr knapp bemessen. Daher müssen wir es in mehrere Server aufteilen, damit die oben genannten Probleme gelöst werden und wir in Zukunft nicht mit Ressourcenproblemen einzelner Maschinen konfrontiert werden.单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。数据库业务层面的拆分,和服务的
Unterteilen Sie die Datenbank auf Geschäftsebene und Service rgba(27, 31, 35, 0,05);Schriftfamilie: „Operator Mono“, Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239 , 112, 96);">Governance ,治理,降级机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。数据库往往最容易成为应用系统的瓶颈,而数据库本身属于有状态的,相对于Web和应用服务器来讲,是比较难实现横向扩展Statefulist schwieriger zu implementieren als Web- und AnwendungsserverHorizontale Erweiterung. Datenbankverbindungsressourcen sind kostbar und die Verarbeitungsfähigkeiten einzelner Maschinen sind begrenzt. In Szenarien mit hoher Parallelität können vertikale Unterdatenbanken die Engpässe von E/A, Anzahl der Verbindungen und Hardwareressourcen einzelner Maschinen bis zu einem gewissen Grad überwinden. 🎜Horizontale Aufteilung
Horizontale Untertabelle
Für eine einzelne Tabelle mit einer großen Datenmenge (z. B. eine Bestelltabelle) nach bestimmten Regeln (
RANGE,HASH取模等),切分到多张表里面去。但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈. Dies wird nicht empfohlen.Horizontale Untertabelle Datenbank und Untertabelle
Die Daten einer einzelnen Tabelle werden auf mehrere Server aufgeteilt, aber die Datenerfassung in der Tabelle ist unterschiedlich und kann den Leistungsengpass und den Druck effektiv lindern eine einzelne Maschine und eine einzelne Datenbank und durchbricht Engpässe bei E/A, Anzahl der Verbindungen, Hardwareressourcen usw 20000;
- Geografische Regionen: Qiniu Cloud sollte beispielsweise die Daten von vor 6 Monaten ausschneiden noch vor einem Jahr und fügen Sie es in eine andere Tabelle ein. Mit der Zeit wird die Wahrscheinlichkeit, dass die Daten in diesen Tabellen abgefragt werden, geringer, sodass es nicht erforderlich ist, sie mit den „heißen Daten“ zusammenzustellen. Trennung heißer und kalter Daten“
Ein Einkaufszentrumsystem verwendet im Allgemeinen Benutzer und Bestellungen als Haupttabelle und verwendet dann die zugehörigen Tabellen als Zusatztabellen. Dies führt nicht zu Problemen wie datenbankübergreifenden Transaktionen Die Benutzer-ID wird erfasst und dann an verschiedene Datenbanken verteilt. - .
Probleme nach Unterdatenbank und Tabelle
Transaktionsunterstützung
Nach Unterdatenbank und Tabelle wird es zu
Verteilte Transaktion.分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
多库结果集合并(group by,order by)
类似于
Wenn Sie sich bei der Ausführung von Transaktionen auf die verteilte Transaktionsverwaltungsfunktion der Datenbank selbst verlassen, zahlen Sie einen hohen Leistungspreis. Wenn die Anwendung bei der Steuerung hilft, wird dies der Fall sein Bilden Sie eine Transaktion in der Programmlogik, was zu Programmieraufwand führt.group by,order byMehrere Datenbank-Ergebnissätze zusammenführen (gruppieren nach, sortieren nach)
🎜Ähnlich wieGruppierungs- und Sortieranweisungen wie Gruppieren nach, Sortieren nachkönnen nicht verwendet werden🎜🎜Datenbankübergreifende Verknüpfung🎜🎜Nachdem die Datenbank in Tabellen unterteilt ist, werden die Zuordnungsvorgänge zwischen den Tabellen eingeschränkt. und wir können die Tabellen nicht an verschiedenen Orten zusammenführen. Tabellen in Untertabellen können nicht mit Tabellen mit unterschiedlicher Untertabellengranularität verknüpft werden. Daher sind für den Abschluss des Geschäfts, das mit einer Abfrage abgeschlossen werden kann, möglicherweise mehrere Abfragen erforderlich. Grobe Lösung: globale Tabelle: Grunddaten, alle Bibliotheken haben eine Kopie. Feldredundanz: Auf diese Weise müssen einige Felder nicht per Join abgefragt werden. Zusammenbau der Systemschicht: Fragen Sie alles separat ab und bauen Sie es dann zusammen, was komplizierter ist. 🎜Sub-Datenbank- und Sub-Table-Lösungsprodukte
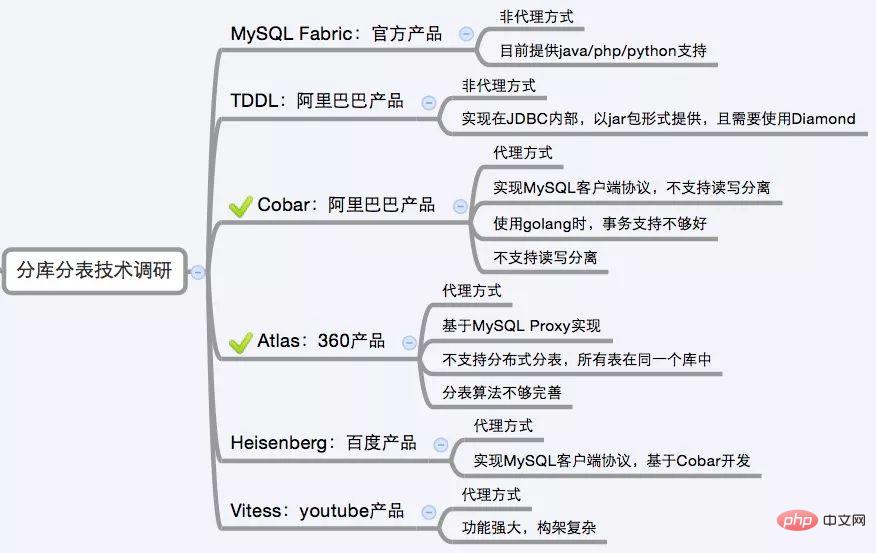
Es gibt relativ viele Sub-Datenbank- und Sub-Table-Middlewares auf dem Markt, zu denen auf Proxy basierende Middlewares gehören:
MySQL ProxyundAmoeba, basierend auf dem Hibernate-Framework, istHibernate Shards, basierend auf jdbc Standardsharding-jdbc, ein Maven-Plug-in basierend auf Mybatis, ähnlich wie MogujieTSharding, durch Umschreiben desCobar Client.MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。还有一些大公司的开源产品:
我是
程序员青戈,一个爱生活、爱分享的90后程序员。
本期关于Mysql分库分表的介绍和解决方案介绍到这里,希望能帮助到大家,后续更多Java面试类的文章请持续关注公众号Java学习指南Es gibt auch Open-Source-Produkte einiger großer Unternehmen:🎜 🎜Ich bin
Programmierer Qingge, ein Programmierer nach den 90ern, der das Leben und das Teilen liebt. 🎜
Diese Ausgabe stellt die MySQL-Unterdatenbank und -Untertabellen vor Die Lösung wird hier vorgestellt. Ich hoffe, sie kann allen helfen. Achten Sie weiterhin auf den offiziellen Account für weitere Java-Interview-Artikel.Java Study Guide🎜. 🎜🎜
Das obige ist der detaillierte Inhalt vonHeute habe ich endlich die MySQL-Unterdatenbank und die Untertabellen herausgefunden, sodass ich im Interview damit prahlen kann!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
